
Crawling, Indizierung und Python: Alles, was Sie wissen müssen
Veröffentlicht: 2021-05-31Ich möchte diesen Artikel mit einer sehr einfachen Gleichung beginnen: Wenn Ihre Seiten nicht gecrawlt werden, werden sie niemals indexiert und daher wird Ihre SEO-Leistung immer leiden (und stinken).
Infolgedessen müssen sich SEOs bemühen, den besten Weg zu finden, um ihre Websites crawlbar zu machen und Google ihre wichtigsten Seiten zur Verfügung zu stellen, damit sie indexiert werden und Traffic über sie generiert werden kann.
Zum Glück haben wir viele Ressourcen, die uns helfen können, die Crawlbarkeit unserer Website zu verbessern, wie z. B. Screaming Frog, Oncrawl oder Python. Ich zeige Ihnen, wie Python Ihnen helfen kann, Ihre Crawling-Freundlichkeit und Indizierungsindikatoren zu analysieren und zu verbessern. Meistens führen diese Art von Verbesserungen auch zu besseren Rankings, einer höheren Sichtbarkeit in den SERPs und schließlich dazu, dass mehr Benutzer auf Ihrer Website landen.
1. Anfordern der Indizierung mit Python
1.1. Für Google
Das Anfordern der Indexierung für Google kann auf verschiedene Arten erfolgen, obwohl ich leider von keiner davon sehr überzeugt bin. Ich werde Sie durch drei verschiedene Optionen mit ihren Vor- und Nachteilen führen:
- Selenium und Google Search Console: Aus meiner Sicht und nachdem ich es und die restlichen Optionen getestet habe, ist dies die effektivste Lösung. Nach einigen Versuchen ist es jedoch möglich, dass ein Captcha-Popup erscheint, das es kaputt macht.
- Pingen einer Sitemap: Es hilft auf jeden Fall, wenn die Sitemaps wie gewünscht gecrawlt werden, aber keine bestimmten URLs, z. B. wenn der Website neue Seiten hinzugefügt wurden.
- Google Indexing API: Es ist nicht sehr zuverlässig, außer für Sender und Jobplattform-Websites. Es hilft, die Crawling-Raten zu erhöhen, aber nicht, bestimmte URLs zu indizieren.
Lassen Sie uns nach diesem kurzen Überblick über jede Methode nacheinander in sie eintauchen.
1.1.1. Selenium und Google Search Console
Im Wesentlichen werden wir in dieser ersten Lösung über einen Browser mit Selenium auf die Google Search Console zugreifen und den gleichen Prozess replizieren, dem wir manuell folgen würden, um viele URLs für die Indexierung mit der Google Search Console einzureichen, jedoch auf automatisierte Weise.
Hinweis: Übertreiben Sie diese Methode nicht und reichen Sie eine Seite nur dann zur Indexierung ein, wenn ihr Inhalt aktualisiert wurde oder die Seite komplett neu ist.
Der Trick, um sich mit Selenium bei der Google Search Console anmelden zu können, besteht darin, zuerst auf den OUATH Playground zuzugreifen, wie ich in diesem Artikel über das Automatisieren des Herunterladens des GSC-Crawling-Statistikberichts erklärt habe.
#Wir importieren diese Module
Importzeit
von Selen Import Webdriver
aus webdriver_manager.chrome importieren Sie ChromeDriverManager
aus selenium.webdriver.common.keys importieren Schlüssel
#Wir installieren unseren Selenium-Treiber
Treiber = webdriver.Chrome(ChromeDriverManager().install())
#Wir greifen auf das OUATH Playground-Konto zu, um uns bei Google Services anzumelden
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent .com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
#Wir warten ein wenig, um sicherzustellen, dass das Rendern abgeschlossen ist, bevor wir Elemente mit Xpath auswählen und unsere E-Mail-Adresse eingeben.
time.sleep(10)
form1=driver.find_element_by_xpath('//*[@]')
form1.send_keys("<Ihre E-Mail-Adresse>")
form1.send_keys(Tasten.EINGABE)
#Auch hier, wir warten ein wenig und geben dann unser Passwort ein.
time.sleep(10)
form2=driver.find_element_by_xpath('//*[@]/div[1]/div/div[1]/input')
form2.send_keys("<Ihr Passwort>")
form2.send_keys(Tasten.EINGABE)
Danach können wir auf unsere URL der Google Search Console zugreifen:
driver.get('https://search.google.com/search-console?resource_id=your_domain”')
time.sleep(5)
box=driver.find_element_by_xpath('/html/body/div[7]/div[2]/header/div[2]/div[2]/div[2]/form/div/div/div/div/div /div[1]/eingabe[2]')
box.send_keys("Ihre_URL")
box.send_keys(Tasten.EINGABE)
time.sleep(5)
Indexierung = driver.find_element_by_xpath("/html/body/div[7]/c-wiz[2]/div/div[3]/span/div/div[2]/span/div[2]/div/div /div[1]/span/div[2]/div/c-wiz[2]/div[3]/span/div/span/span/div/span/span[1]")
indexierung.click()
time.sleep(120)
Leider scheint es, wie in der Einleitung erläutert, dass nach einer Reihe von Anfragen ein Puzzle-Captcha erforderlich ist, um mit der Indexierungsanfrage fortzufahren. Da die automatisierte Methode das Captcha nicht lösen kann, behindert dies diese Lösung.
1.1.2. Pingen einer Sitemap
Sitemap-URLs können mit der Ping-Methode an Google übermittelt werden. Im Grunde müssten Sie nur eine Anfrage an den folgenden Endpunkt stellen und Ihre Sitemap-URL als Parameter eingeben:
http://www.google.com/ping?sitemap=URL/of/file
Dies kann sehr einfach mit Python und Anfragen automatisiert werden, wie ich in diesem Artikel erklärt habe.
import urllib.request url = "http://www.google.com/ping?sitemap=https://www.example.com/sitemap.xml" Antwort = urllib.request.urlopen(url)
1.1.3. Google-Indexierungs-API
Die Google Indexing API kann eine gute Lösung sein, um Ihre Crawling-Raten zu verbessern, aber normalerweise ist es keine sehr effektive Methode, um Ihre Inhalte zu indizieren, da sie nur verwendet werden sollte, wenn Ihre Website entweder JobPosting oder BroadcastEvent in ein VideoObject eingebettet hat. Wenn Sie es jedoch ausprobieren und selbst testen möchten, können Sie die nächsten Schritte befolgen.
Um mit dieser API zu beginnen, müssen Sie zunächst zur Google Cloud Console gehen, ein Projekt und Anmeldedaten für ein Dienstkonto erstellen. Danach müssen Sie die Indizierungs-API aus der Bibliothek aktivieren und das E-Mail-Konto hinzufügen, das mit den Anmeldeinformationen des Dienstkontos als Eigentümer der Google Search Console angegeben ist. Möglicherweise müssen Sie die alte Version der Google Search Console verwenden, um diese E-Mail-Adresse als Property-Eigentümer hinzufügen zu können.
Sobald Sie die vorherigen Schritte befolgt haben, können Sie mit dieser API beginnen, die Indizierung und Deindizierung zu erfragen, indem Sie den nächsten Codeabschnitt verwenden:
aus oauth2client.service_account importieren Sie ServiceAccountCredentials
Importieren Sie httplib2
SCOPES = [ "https://www.googleapis.com/auth/indexing" ]
ENDPOINT = "https://indexing.googleapis.com/v3/urlNotifications:publish"
client_secrets = "path_to_your_credentials.json"
Anmeldeinformationen = ServiceAccountCredentials.from_json_keyfile_name(client_secrets, scopes=SCOPES)
wenn Anmeldeinformationen None oder Credentials.invalid sind:
Anmeldeinformationen = tools.run_flow (Fluss, Speicher)
http = Anmeldeinformationen.autorisieren (httplib2.Http())
list_urls = ["https://www.example.com", "https://www.example.com/test2/"]
für Iteration im Bereich (len(list_urls)):
Inhalt = '''{
'url': "'''+str(list_urls[iteration])+'''",
'Typ': "URL_UPDATED"
}'''
Antwort, Inhalt = http.request(ENDPOINT, method="POST", body=content)
drucken (Antwort)
Druck (Inhalt)Wenn Sie eine Deindexierung anfordern möchten, müssen Sie den Anfragetyp von „URL_UPDATED“ in „URL_DELETED“ ändern. Der vorherige Codeabschnitt druckt die Antworten von der API mit den Benachrichtigungszeiten und deren Status. Wenn der Status 200 ist, wurde die Anfrage erfolgreich gestellt.
1.2. Für Bing
Wenn wir über SEO sprechen, denken wir sehr oft nur an Google, aber wir können nicht vergessen, dass es in einigen Märkten andere vorherrschende Suchmaschinen und/oder andere Suchmaschinen gibt, die einen respektablen Marktanteil wie Bing haben.
Es ist wichtig, von Anfang an zu erwähnen, dass Bing in den Bing Webmaster Tools bereits eine sehr praktische Funktion hat, mit der Sie in den meisten Fällen die Einreichung von bis zu 10.000 URLs pro Tag anfordern können. Manchmal liegt Ihr tägliches Kontingent möglicherweise unter 10.000 URLs, aber Sie haben die Möglichkeit, eine Kontingenterhöhung anzufordern, wenn Sie der Meinung sind, dass Sie ein größeres Kontingent benötigen würden, um Ihre Anforderungen zu erfüllen. Mehr dazu können Sie auf dieser Seite lesen.
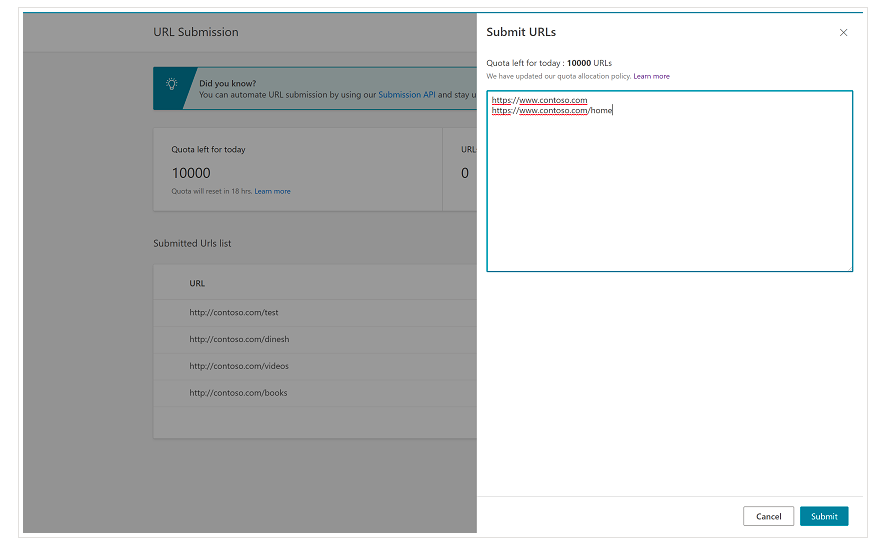
Diese Funktion ist in der Tat sehr praktisch für Massen-URL-Übermittlungen, da Sie Ihre URLs nur in verschiedenen Zeilen im URL-Übermittlungstool von der normalen Benutzeroberfläche von Bing Webmaster Tools eingeben müssen.
1.2.1. Bing-Indizierungs-API
Die Bing Indexing API kann mit einem API-Schlüssel verwendet werden, der als Parameter eingeführt werden muss. Diesen API-Schlüssel erhalten Sie in den Bing Webmaster Tools, indem Sie zum Abschnitt API-Zugriff gehen und danach den API-Schlüssel generieren.
Sobald der API-Schlüssel abgerufen wurde, können wir mit dem folgenden Codeabschnitt mit der API herumspielen (Sie müssten nur Ihren API-Schlüssel und Ihre Website-URL hinzufügen):
Anfragen importieren
list_urls = ["https://www.example.com", "https://www.example/test2/"]
für y in list_urls:
url = 'https://ssl.bing.com/webmaster/api.svc/json/SubmitUrlbatch?apikey=yourapikey'
myobj = '{"siteUrl":"https://www.example.com", "urlList":["'+ str(y) +'"]}'
headers = {'Content-type': 'application/json; Zeichensatz=utf-8'}
x = Anfragen.post (URL, Daten = myobj, Header = Header)
print(str(y) + ": " + str(x))Dadurch werden die URL und ihr Antwortcode bei jeder Iteration gedruckt. Im Gegensatz zur Google Indexing API kann diese API für jede Art von Website verwendet werden.
[Fallstudie] Erhöhen Sie die Sichtbarkeit, indem Sie die Website-Crawlbarkeit für den Googlebot verbessern
 Lesen Sie die Fallstudie
Lesen Sie die Fallstudie2. Analyse, Erstellung und Upload von Sitemaps
Wie wir alle wissen, sind Sitemaps sehr nützliche Elemente, um Suchmaschinen-Bots die URLs bereitzustellen, die sie crawlen sollen. Damit Suchmaschinen-Bots wissen, wo sich unsere Sitemaps befinden, sollen sie in die Google Search Console und Bing Webmaster Tools hochgeladen und in die robots.txt-Datei für den Rest der Bots aufgenommen werden.
Mit Python können wir hauptsächlich an drei verschiedenen Aspekten im Zusammenhang mit den Sitemaps arbeiten: deren Analyse, Erstellung und Hochladen und Löschen aus der Google Search Console.
2.1. Sitemap-Import und -Analyse mit Python
Advertools ist eine großartige Bibliothek, die von Elias Dabbas erstellt wurde und für den Import von Sitemaps sowie für viele andere SEO-Aufgaben verwendet werden kann. Sie können Sitemaps einfach in Dataframes importieren, indem Sie Folgendes verwenden:
sitemap_to_df('https://example.com/robots.txt', recursive=False)
Diese Bibliothek unterstützt normale XML-Sitemaps, News-Sitemaps und Video-Sitemaps.
Wenn Sie dagegen nur daran interessiert sind, die URLs aus der Sitemap zu importieren, können Sie auch die Bibliotheksanfragen und BeautifulSoup verwenden.
Anfragen importieren
aus bs4 importieren BeautifulSoup
r = Anfragen.get("https://www.example.com/ihre_sitemap.xml")
xml = r.text
Suppe = BeautifulSoup(xml)
urls = soup.find_all("loc")
urls = [[x.text] für x in URLs]
Sobald die Sitemap importiert wurde, können Sie mit den extrahierten URLs herumspielen und eine Inhaltsanalyse durchführen, wie von Koray Tugberk in diesem Artikel erklärt.
2.2. Sitemap-Erstellung mit Python
Sie können auch Python verwenden, um Sitemaps.xml aus einer Liste von URLs zu erstellen, wie JC Chouinard in diesem Artikel erklärt. Dies kann besonders für sehr dynamische Websites nützlich sein, deren URLs sich schnell ändern, und zusammen mit der oben erläuterten Ping-Methode kann es eine großartige Lösung sein, um Google die neuen URLs bereitzustellen und sie schnell zu crawlen und zu indizieren.
Kürzlich hat Greg Bernhardt auch eine APP mit Streamlit und Python erstellt, um Sitemaps zu generieren.
2.3. Sitemaps aus der Google Search Console hochladen und löschen
Die Google Search Console verfügt über eine API, die hauptsächlich auf zwei verschiedene Arten verwendet werden kann: zum Extrahieren von Daten über die Webleistung und zum Verwalten von Sitemaps. In diesem Beitrag konzentrieren wir uns auf die Möglichkeit, Sitemaps hochzuladen und zu löschen.
Zunächst ist es wichtig, ein vorhandenes Projekt aus der Google Cloud Console zu erstellen oder zu verwenden, um eine OUATH-Berechtigung zu erhalten und den Google Search Console-Dienst zu aktivieren. JC Chouinard erklärt in diesem Artikel sehr gut die Schritte, die Sie befolgen müssen, um mit Python auf die Google Search Console API zuzugreifen, und wie Sie Ihre erste Anfrage stellen. Grundsätzlich können wir seinen Code vollständig nutzen, aber nur durch eine Änderung, in den Bereichen werden wir „https://www.googleapis.com/auth/webmasters“ anstelle von „https://www.googleapis.com“ hinzufügen /auth/webmasters.readonly“, da wir die API nicht nur zum Lesen, sondern auch zum Hochladen und Löschen von Sitemaps verwenden werden.

Sobald wir uns mit der API verbunden haben, können wir anfangen, damit zu spielen und alle Sitemaps aus unseren Google Search Console-Eigenschaften mit dem nächsten Codestück aufzulisten:
für site_url in verifizierte_sites_urls:
drucken (site_url)
# Abrufen der Liste der eingereichten Sitemaps
Sitemaps = webmasters_service.sitemaps().list(siteUrl=site_url).execute()
if 'sitemap' in Sitemaps:
sitemap_urls = [s['Pfad'] für s in Sitemaps['Sitemap']]
print (" " + "\n ".join(sitemap_urls))
Wenn es um spezifische Sitemaps geht, können wir drei Aufgaben erledigen, die wir in den nächsten Abschnitten erläutern werden: Hochladen, Löschen und Anfordern von Informationen.
2.3.1. Hochladen einer Sitemap
Um eine Sitemap mit Python hochzuladen, müssen wir nur die Site-URL und den Sitemap-Pfad angeben und diesen Code ausführen:
WEBSITE = 'yourGSCproperty' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().submit(siteUrl=WEBSITE, Feedpath=SITEMAP_PATH).execute()
2.3.2. Löschen einer Sitemap
Die andere Seite der Medaille ist, wenn wir eine Sitemap löschen möchten. Wir können Sitemaps auch mit Python aus der Google Search Console löschen, indem wir die Methode „delete“ anstelle von „submit“ verwenden.
WEBSITE = 'yourGSCproperty' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().delete(siteUrl=WEBSITE, Feedpath=SITEMAP_PATH).execute()
2.3.3. Anfordern von Informationen aus den Sitemaps
Schließlich können wir mit der Methode „get“ auch Informationen aus der Sitemap anfordern.
WEBSITE = 'yourGSCproperty' SITEMAP_PATH = 'https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps().get(siteUrl=WEBSITE, Feedpath=SITEMAP_PATH).execute()
Dies gibt eine Antwort im JSON-Format wie folgt zurück: 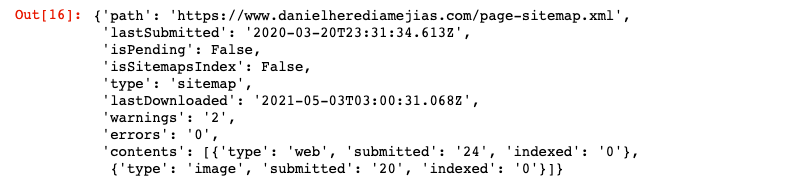
3. Analyse der internen Verlinkung und Möglichkeiten
Eine ordnungsgemäße interne Verlinkungsstruktur ist sehr hilfreich, um Suchmaschinen-Bots das Crawlen Ihrer Website zu erleichtern. Einige der Hauptprobleme, auf die ich bei der Prüfung einer Reihe von Websites mit sehr ausgefeilten technischen Setups gestoßen bin, sind:
- Links, die mit On-Click-Ereignissen eingeführt werden: Kurz gesagt, der Googlebot klickt nicht auf Schaltflächen. Wenn Ihre Links also mit einem On-Click-Ereignis eingefügt werden, kann der Googlebot ihnen nicht folgen.
- Clientseitig gerenderte Links: Obwohl der Googlebot und andere Suchmaschinen viel besser darin werden, JavaScript auszuführen, ist es immer noch eine ziemliche Herausforderung für sie, daher ist es viel besser, diese Links serverseitig zu rendern und sie in das rohe HTML zu liefern Suchmaschinen-Bots, als dass sie erwarten, dass sie JavaScript-Skripte ausführen.
- Login- und/oder Age-Gate-Pop-ups: Login-Pop-ups und Age-Gates können Suchmaschinen-Bots daran hindern, den Inhalt hinter diesen „Hindernissen“ zu crawlen.
- Überbeanspruchung von Nofollow-Attributen: Die Verwendung vieler Nofollow-Attribute, die auf wertvolle interne Seiten verweisen, verhindert, dass Suchmaschinen-Bots sie durchsuchen.
- Noindex und follow: Technisch gesehen sollte die Kombination von noindex- und follow-Anweisungen Suchmaschinen-Bots die Links auf dieser Seite crawlen lassen. Es scheint jedoch, dass der Googlebot nach einer Weile aufhört, diese Seiten mit noindex-Anweisungen zu crawlen.
Mit Python können wir unsere interne Verlinkungsstruktur analysieren und im Bulk-Modus neue interne Verlinkungsmöglichkeiten finden.
3.1. Interne Linkanalyse mit Python
Vor einigen Monaten habe ich einen Artikel darüber geschrieben, wie man Python und die Bibliothek Networkx verwendet, um Diagramme zu erstellen, um die interne Linkstruktur auf sehr visuelle Weise darzustellen:
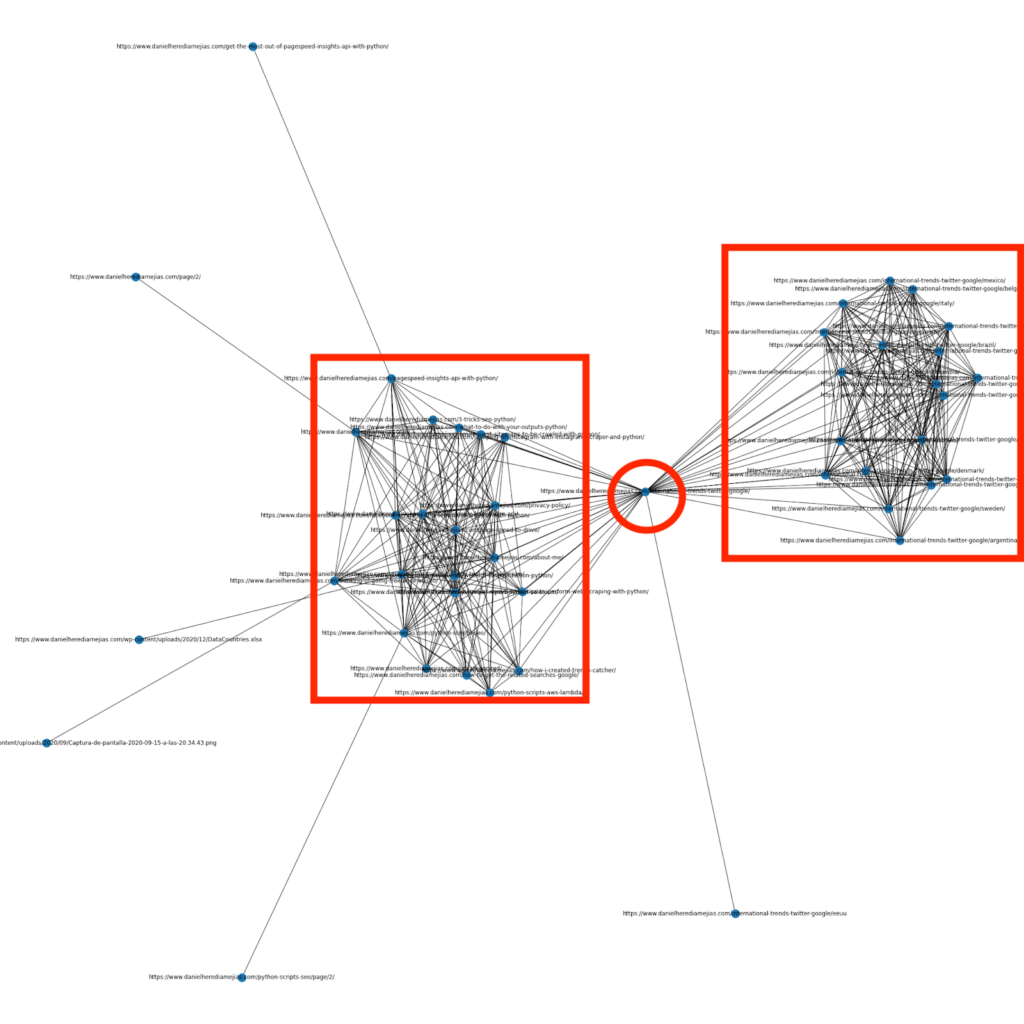
Dies ist etwas sehr ähnliches, was Sie von Screaming Frog erhalten können, aber der Vorteil der Verwendung von Python für diese Art von Analysen besteht darin, dass Sie im Grunde die Daten auswählen können, die Sie in diese Diagramme aufnehmen möchten, und die meisten Diagrammelemente wie z B. Farben, Knotengrößen oder sogar die Seiten, die Sie hinzufügen möchten.
3.2. Mit Python neue interne Verlinkungsmöglichkeiten finden
Abgesehen von der Analyse von Site-Strukturen können Sie Python auch verwenden, um neue interne Verlinkungsmöglichkeiten zu finden, indem Sie eine Reihe von Schlüsselwörtern und URLs bereitstellen und diese URLs durchlaufen, um nach den bereitgestellten Begriffen in ihren Inhalten zu suchen.
Dies kann sehr gut mit Semrush- oder Ahrefs-Exporten funktionieren, um leistungsstarke kontextbezogene interne Links von einigen Seiten zu finden, die bereits für Schlüsselwörter ranken und daher bereits über eine gewisse Autorität verfügen.
Sie können hier mehr über diese Methode lesen.
4. Website-Geschwindigkeit, 5xx- und Soft-Error-Seiten
Wie von Google auf dieser Seite darüber angegeben, was das Crawling-Budget für Google bedeutet, verbessert die Beschleunigung Ihrer Website die Benutzererfahrung und erhöht die Crawling-Rate. Auf der anderen Seite gibt es auch andere Faktoren, die sich auf das Crawl-Budget auswirken können, wie z. B. Soft-Error-Seiten, Inhalte von geringer Qualität und doppelte Inhalte auf der Website.
4.1. Seitengeschwindigkeit und Python
4.2.1 Analysieren Sie die Geschwindigkeit Ihrer Website mit Python
Page Speed Insights API ist sehr nützlich, um zu analysieren, wie Ihre Website in Bezug auf die Seitengeschwindigkeit abschneidet, und um viele Daten über viele verschiedene Seitengeschwindigkeitsmetriken (fast 50) plus Core Web Vitals zu erhalten.
Die Arbeit mit Page Speed Insights mit Python ist sehr einfach, es sind nur ein API-Schlüssel und Anfragen erforderlich, um es zu nutzen. Zum Beispiel:
Importieren Sie urllib.request, json url = "https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url=your_URL&strategy=mobile&locale=en&key=yourAPIKey" #Beachten Sie, dass Sie Ihre URL mit dem Parameter URL einfügen und auch den Geräteparameter ändern können, wenn Sie die Daten für den Desktop erhalten möchten. Antwort = urllib.request.urlopen(url) data = json.loads(response.read())
Darüber hinaus können Sie mit dem Python- und Lighthouse-Scoring-Rechner prognostizieren, wie stark sich Ihre Gesamtleistung verbessern würde, wenn Sie die angeforderten Änderungen vornehmen, um Ihre Seitengeschwindigkeit zu verbessern, wie in diesem Artikel erläutert.
4.2.2 Bildoptimierung und Größenänderung mit Python
In Bezug auf die Website-Geschwindigkeit kann Python auch zum Optimieren, Komprimieren und Ändern der Größe von Bildern verwendet werden, wie in diesen Artikeln von Koray Tugberk und Greg Bernhardt erläutert:
- Automatisieren Sie die Bildkomprimierung mit Python über FTP.
- Ändern Sie die Größe von Bildern mit Python in großen Mengen.
- Optimieren Sie Bilder über Python für SEO und UX.
4.2. Extraktion von 5xx- und anderen Antwortcodefehlern mit Python
5xx-Antwortcodefehler können darauf hindeuten, dass Ihr Server nicht schnell genug ist, um alle empfangenen Anforderungen zu bewältigen. Dies kann sich sehr negativ auf Ihre Crawling-Rate auswirken und auch die Benutzererfahrung beeinträchtigen.
Um sicherzustellen, dass Ihre Website wie erwartet funktioniert, können Sie das Herunterladen des Crawl-Statistikberichts mit Python und Selenium automatisieren und Ihre Protokolldateien genau im Auge behalten.
4.3. Extrahieren von Soft-Error-Pages mit Python
Kürzlich veröffentlichte Jose Luis Hernando zu Ehren von Hamlet Batista einen Artikel darüber, wie Sie die Extraktion von Abdeckungsberichten mit Node.js automatisieren können. Dies kann eine erstaunliche Lösung sein, um die Soft-Error-Seiten und sogar die 5xx-Antwortfehler zu extrahieren, die sich negativ auf Ihre Crawling-Rate auswirken könnten.
Wir können den gleichen Prozess auch mit Python replizieren, um in nur einem Excel-Tab alle URLs zusammenzustellen, die von der Google Search Console als fehlerhaft, gültig mit Warnungen, gültig und ausgeschlossen bereitgestellt werden.
Zuerst müssen wir uns bei der Google Search Console anmelden, wie zuvor in diesem Artikel mit Python mit Selen erklärt. Danach wählen wir alle URL-Statusfelder aus, fügen bis zu 100 Zeilen pro Seite hinzu und beginnen mit der Iteration über alle von GSC gemeldeten URL-Typen und laden jede einzelne Excel-Datei herunter.
Importzeit
von Selen Import Webdriver
aus webdriver_manager.chrome importieren Sie ChromeDriverManager
aus selenium.webdriver.common.keys importieren Schlüssel
Treiber = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent .com&scope=email&access_type=offline&flowName=GeneralOAuthFlow')
time.sleep(5)
searchBox=driver.find_element_by_xpath('//*[@]')
searchBox.send_keys("<ihremailadresse>")
searchBox.send_keys(Tasten.EINGABE)
time.sleep(5)
searchBox=driver.find_element_by_xpath('//*[@]/div[1]/div/div[1]/input')
searchBox.send_keys("<IhrPasswort>")
searchBox.send_keys(Tasten.EINGABE)
time.sleep(5)
yourdomain = str(input("Fügen Sie hier Ihre HTTP-Property oder Domain ein. Wenn es sich um eine Domain handelt, schließen Sie ein: 'sc-domain':"))
driver.get('https://search.google.com/search-console/index?resource_https://search.google.com/search-console/index?resource_Tabla')
listvalues = [list_problems[x] for i in range(len(df1["URL"]))]
df1['Typ'] = Listenwerte
list_results = df1.values.tolist()
anders:
df2 = pd.read_excel(yourdomain.replace("sc-domain:","").replace("/","_").replace(":","_") + "-Coverage-Drilldown-" + heute + " (" + str(x) + ").xlsx", 'Tabla')
listvalues = [list_problems[x] for i in range(len(df2["URL"]))]
df2['Typ'] = Listenwerte
list_results = list_results + df2.values.tolist()
df = pd.DataFrame(list_results, column= ["URL","TimeStamp", "Type"])
df.to_csv('<Dateiname>.csv', Header=Wahr, Index=Falsch, Kodierung = "utf-8")
Die endgültige Ausgabe sieht so aus: 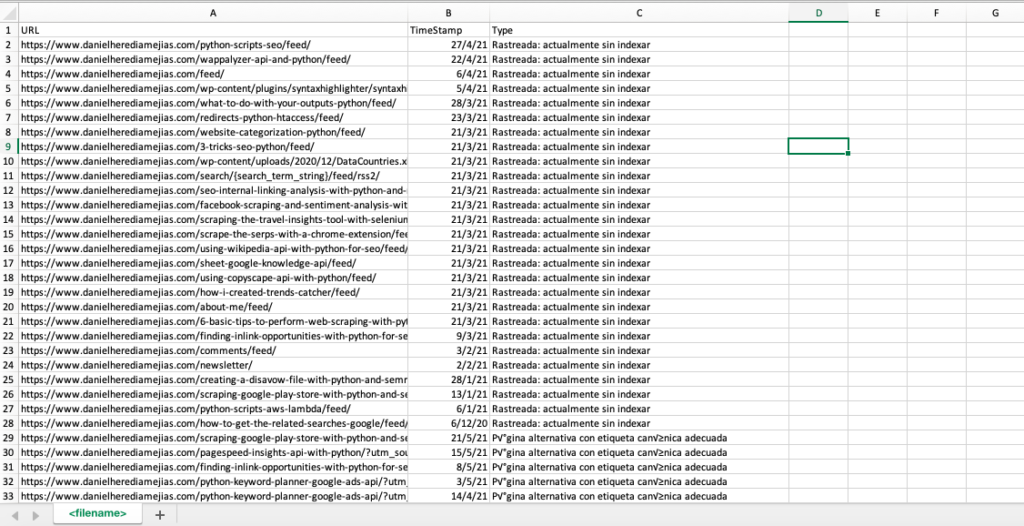
4.4. Logdateianalyse mit Python
Neben den Daten, die im Crawling-Statistikbericht der Google Search Console verfügbar sind, können Sie auch Ihre eigenen Dateien analysieren, indem Sie Python verwenden, um viel mehr Informationen darüber zu erhalten, wie die Suchmaschinen-Bots Ihre Website crawlen. Wenn Sie noch keinen Log-Analyzer für SEO verwenden, können Sie diesen Artikel von SEO Garden lesen, in dem die Log-Analyse mit Python erklärt wird.
[Ebook] Vier Anwendungsfälle zur Nutzung der SEO-Protokollanalyse
Kostenlos herunterladen5. Abschließende Schlussfolgerungen
Wir haben gesehen, dass Python eine große Bereicherung sein kann, um das Crawling und die Indexierung unserer Websites auf viele verschiedene Arten zu analysieren und zu verbessern. Wir haben auch gesehen, wie Sie das Leben viel einfacher machen können, indem Sie die meisten der mühsamen und manuellen Aufgaben automatisieren, die Tausende von Stunden Ihrer Zeit in Anspruch nehmen würden.
Ich muss sagen, dass ich leider nicht ganz von den Lösungen überzeugt bin, die Google derzeit anbietet, um eine Indexierung für eine große Anzahl von URLs anzufordern, obwohl ich seine Angst, eine bessere Lösung anzubieten, einigermaßen verstehen kann: Viele SEOs könnten dazu neigen es zu überbeanspruchen.
Im Gegensatz dazu gibt es Bing, das außergewöhnliche und bequeme Lösungen bietet, um die URL-Indexierung über die API und sogar über die normale Schnittstelle der Bing-Webmaster-Tools anzufordern.
Aufgrund der Tatsache, dass die Google-Indexierungs-API verbesserungswürdig ist, werden andere Elemente wie eine zugängliche und aktualisierte Sitemap, Ihre interne Verlinkung, Ihre Seitengeschwindigkeit, Ihre Soft-Error-Seiten und Ihre doppelten und qualitativ minderwertigen Inhalte noch wichtiger dass Ihre Website richtig gecrawlt und Ihre wichtigsten Seiten indexiert werden.