
10 häufige technische SEO-Probleme – und wie man sie erkennt
Veröffentlicht: 2019-06-04Nachdem Sie SEO-Dienstleistungen in einer Reihe von Branchen durchgeführt haben, können Sie manchmal häufig auftretende Probleme aufgreifen, insbesondere wenn Sie an einem gängigen CMS wie WordPress, Shopify oder SquareSpace arbeiten.
Hier habe ich 10 ziemlich häufige technische SEO-Probleme skizziert, auf die Sie bei der Optimierung einer Website stoßen könnten.
Ich sage nicht, dass diese Probleme für Sie oder Ihren Kunden definitiv problematisch sein werden – sehr oft ist der Kontext immer noch sehr wichtig. Es gibt nicht immer eine Einheitslösung, aber es ist wahrscheinlich trotzdem gut, bei den unten beschriebenen Szenarien vorsichtig zu sein.
1 – Robots.txt-Datei, die den Zugriff auf den Googlebot blockiert
Dies ist für die meisten technischen SEOs nichts Neues, aber es ist immer noch sehr leicht, die Überprüfung der Roboterdatei zu vernachlässigen – und zwar nicht nur zum Zeitpunkt der Durchführung eines technischen Audits, sondern als wiederkehrende Überprüfung.
Sie können ein Tool wie die Search Console (die alte Version) verwenden, um zu überprüfen, ob Google Zugriffsprobleme hat, oder Sie können einfach versuchen, Ihre Website als Googlebot mit einem Tool wie OnCrawl zu crawlen (wählen Sie einfach ihren User Agent aus). OnCrawl befolgt die robots.txt, sofern Sie nichts anderes angeben.
Exportieren Sie die Crawling-Ergebnisse und vergleichen Sie sie mit einer bekannten Liste von Seiten auf Ihrer Website und prüfen Sie, ob es keine Crawler-Blindspots gibt.
Um zu zeigen, dass dies immer noch ziemlich oft vorkommt, und bei einigen ziemlich großen Websites, bemerkte ich vor ein paar Wochen, dass das Geschwindigkeitstest-Tool von Pingdom in Google blockiert wurde.
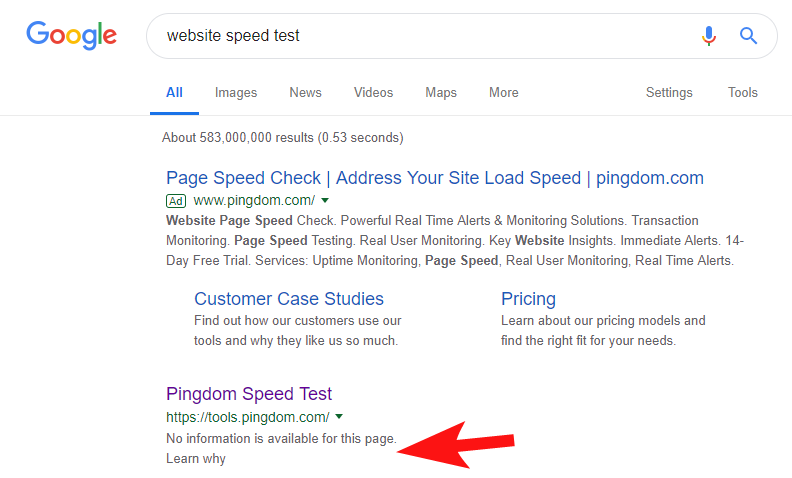
Ein Blick auf ihre Robots-Datei (und der anschließende Versuch, ihre Seite von OnCrawl als Googlebot zu crawlen) bestätigte meinen Verdacht, dass sie den Zugriff auf ihre Website blockierten.
Die schuldige robots.txt-Datei ist unten dargestellt:

Ich habe sie mit einem „FYI“ kontaktiert, aber keine Antwort erhalten, aber dann ein paar Tage später gesehen, dass alles wieder normal war. Puh – ich konnte wieder problemlos schlafen!
In ihrem Fall schien es, dass jedes Mal, wenn Sie Ihre Website im Rahmen ihres Geschwindigkeitsaudits scannen, eine URL erstellt wurde, die das in der Roboterdatei oben hervorgehobene Hash-Zeichen enthielt.
Vielleicht wurden diese irgendwie gecrawlt und sogar indiziert, und sie wollten das kontrollieren (was sehr verständlich wäre). In diesem Fall haben sie die potenziellen Auswirkungen wahrscheinlich nicht vollständig getestet – was am Ende wahrscheinlich minimal war.
Hier sind ihre aktuellen Roboter für alle Interessierten.

Es ist erwähnenswert, dass Sie in einigen Fällen mithilfe der Internet Wayback Machine auf historische Änderungen der robots.txt-Datei zugreifen können. Meiner Erfahrung nach funktioniert dies am besten auf größeren Websites, wie Sie sich vorstellen können – sie werden weitaus häufiger vom Archivierer der Wayback-Maschine gecrawlt.
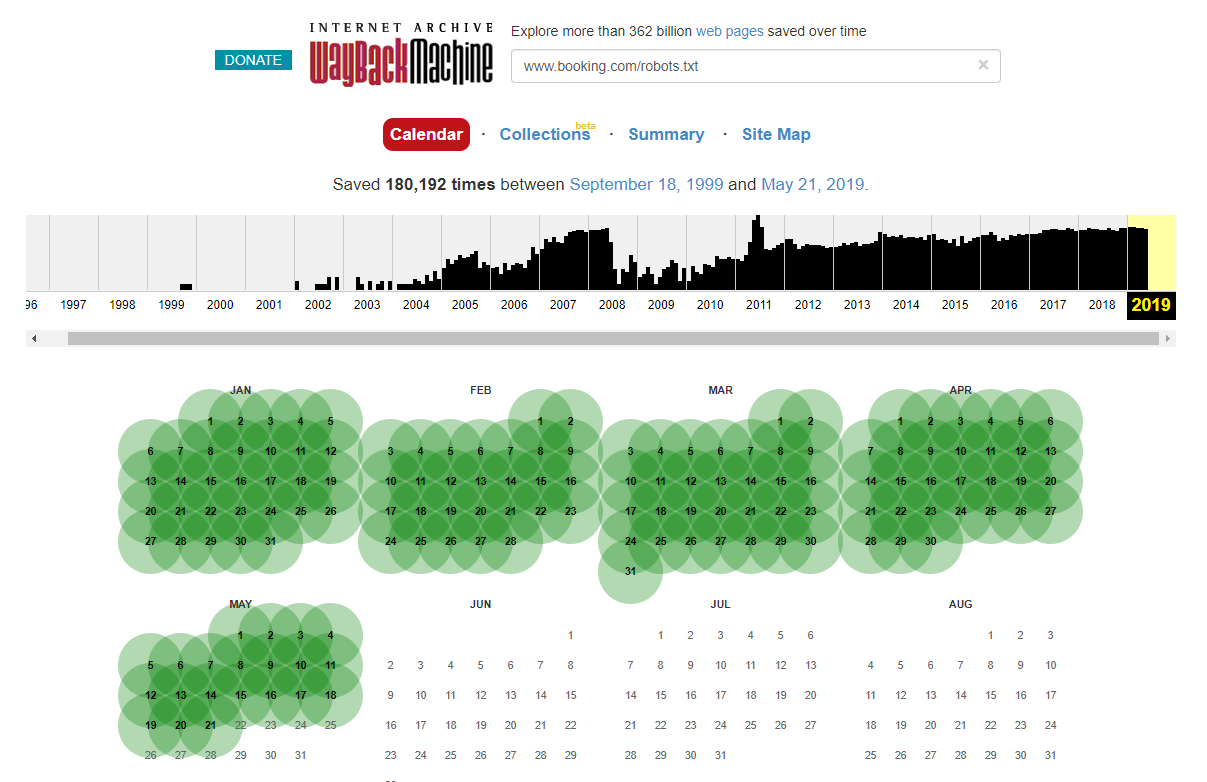
Es ist nicht das erste Mal, dass ich eine echte robots.txt-Datei in freier Wildbahn sehe, die ein bisschen Chaos in den SERPS verursacht. Und es wird definitiv nicht die letzte sein – es ist so einfach, es zu vernachlässigen (es ist schließlich buchstäblich eine Datei), aber die Überprüfung sollte Teil des laufenden Arbeitsplans eines jeden SEO sein.
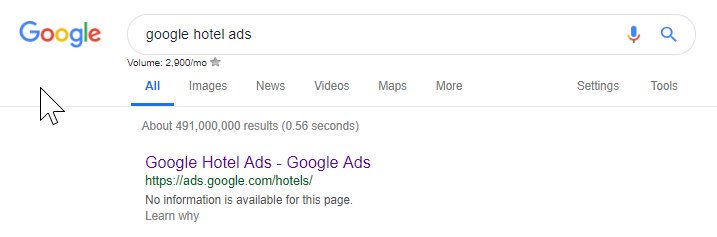
Aus dem Obigen können Sie ersehen, dass sogar Google manchmal seine Robots-Datei durcheinander bringt und sich selbst daran hindert, auf ihre Inhalte zuzugreifen. Dies könnte beabsichtigt gewesen sein, aber wenn ich mir die Sprache ihrer Roboterdatei unten ansehe, bezweifle ich es irgendwie.
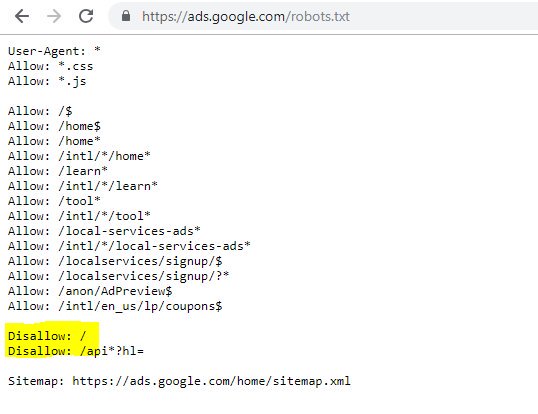
Das hervorgehobene Disallow: / verhinderte in diesem Fall den Zugriff auf URL-Pfade; Es wäre sicherer gewesen, stattdessen die spezifischen Abschnitte der Website aufzulisten, die nicht gecrawlt werden sollten.
2 – Probleme mit der Domänenkonfiguration auf DNS-Ebene
Dies ist ein überraschend häufiges Problem, aber normalerweise ist es eine schnelle Lösung. Dies ist eine dieser kostengünstigen, *potentiell* wirkungsvollen SEO-Änderungen, die technische SEOs lieben.
Bei SSL-Implementierungen sehe ich oft nicht, dass die Nicht-WWW-Domänenversion korrekt konfiguriert ist, z. B. 302-Umleitung zur nächsten URL und Bildung einer Kette oder im schlimmsten Fall gar kein Laden.
Ein gutes Beispiel dafür ist die Website von Hotel Football.
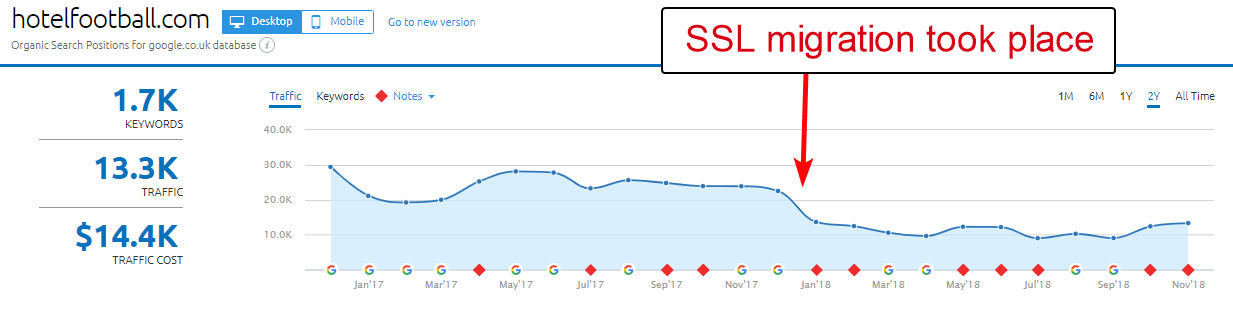
Sie haben sich Anfang letzten Jahres einer SSL-Migration unterzogen, die für sie nicht so gut ausgegangen ist, wie aus dem obigen Domain-Übersichtsbericht von SEMRush zu urteilen.
Das ist mir vor einiger Zeit aufgefallen, da ich viel in der Reise- und Gastgewerbebranche gearbeitet habe – und mit einer ausgeprägten Liebe zum Fußball war ich daran interessiert zu sehen, wie ihre Website aussieht (und natürlich, wie sie sich organisch entwickelt! ).
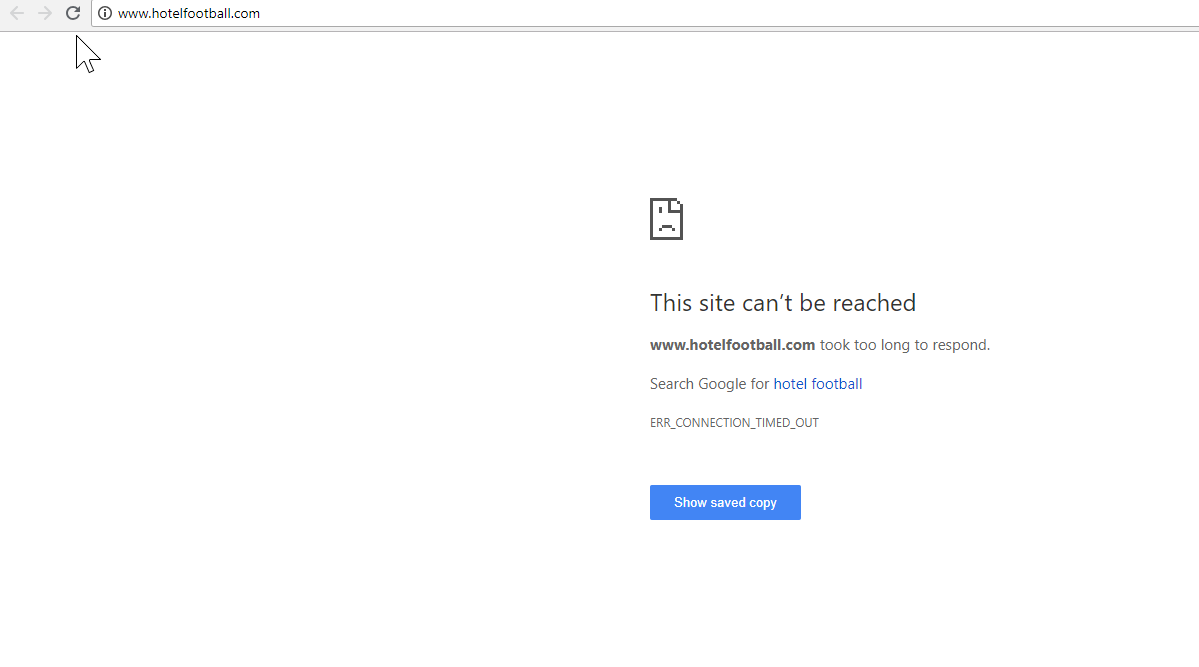
Dies war eigentlich sehr einfach zu diagnostizieren – die Website hatte eine Menge extrem guter Backlinks, die alle auf die Nicht-SSL-WWW-Domain unter http://www.hotelfootball.com/ verwiesen.
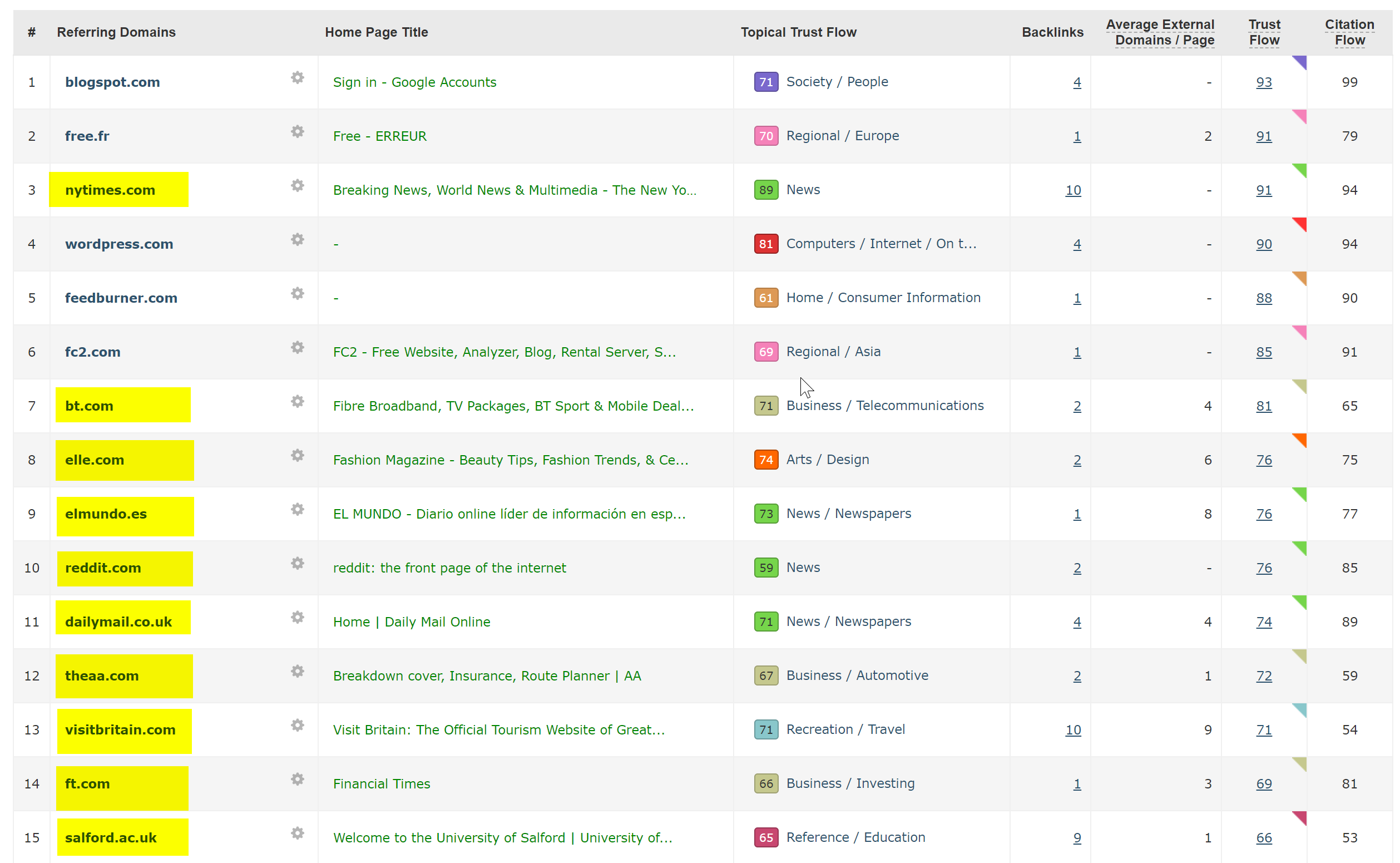
Wenn Sie jedoch versuchen, auf diese URL oben zuzugreifen, wird sie nicht geladen. Hoppla. Und das schon seit mindestens 18 Monaten. Ich habe mich über Twitter an die Agentur gewandt, die die Website verwaltet, um sie darüber zu informieren, hatte aber keine Antwort.
Mit diesem müssen sie nur sicherstellen, dass die DNS-Zoneneinstellungen korrekt sind, mit einem „A“-Eintrag für die „WWW“-Version der Domain, der auf die richtige IP-Adresse verweist (ein CNAME würde auch funktionieren). Dadurch wird verhindert, dass die Domäne nicht aufgelöst wird.
Der einzige Nachteil oder der Grund, warum die Lösung dieses Problems so lange dauert, ist, dass es schwierig sein kann, Zugriff auf das Domain-Verwaltungspanel einer Website zu erhalten, oder sogar, dass Passwörter verloren gegangen sind oder es nicht als hohe Priorität angesehen wird.
Es ist auch nicht immer eine gute Idee, Anweisungen zur Behebung an eine nicht technisch versierte Person zu senden, die die Schlüssel zum Domainnamen besitzt.
Ich wäre sehr gespannt auf die organischen Auswirkungen, wenn/wenn sie in der Lage sind, die oben genannte Anpassung vorzunehmen – insbesondere angesichts all der Backlinks, die die Nicht-WWW-Domain aufgebaut hat, seit das Hotel von den ehemaligen Fußballern von Manchester United, Gary Neville, Ryan Giggs, eröffnet wurde und Unternehmen.
Während sie bei Google für ihren Hotelnamen auf Platz 1 rangieren (wie Sie sich vorstellen können), scheinen sie überhaupt keine starken Rankings für ihre wettbewerbsfähigeren Nicht-Marken-Suchbegriffe zu haben (sie sind derzeit auf Position 10 bei Google nach „Hotel in der Nähe von Old Trafford“).
Sie haben damit ein kleines Eigentor erzielt – aber die Behebung dieses Problems könnte zumindest einen Teil dazu beitragen, das Problem zu lösen.
Oncrawl SEO-Crawler
 Mehr erfahren
Mehr erfahren3 – Rogue Pages innerhalb der XML-Sitemap
Auch dies ist ziemlich einfach, aber es ist seltsam üblich – beim Überprüfen einer XML-Sitemap einer Website (die sich fast immer entweder unter domain.com/sitemap.xml oder domain.com/sitemap_index.xml befindet, können hier Seiten aufgeführt sein, die wirklich nicht müssen nicht indiziert werden.
Typische Übeltäter sind versteckte Dankesseiten (danke für das Absenden eines Kontaktformulars), PPC-Zielseiten, die möglicherweise Probleme mit doppelten Inhalten verursachen, oder andere Formen von Seiten/Beiträgen/Taxonomien, die Sie bereits an anderer Stelle noindexiert haben.
Sie erneut in die XML-Sitemap aufzunehmen, kann widersprüchliche Signale an Suchmaschinen senden – Sie sollten wirklich nur die Seiten auflisten, die sie finden und indizieren sollen, was hauptsächlich der Sinn der Sitemap ist.
Sie können jetzt den praktischen Bericht in der Search Console verwenden, um herauszufinden, ob Seiten in die XML-Sitemap einer Website über die Option „URL prüfen“ aufgenommen wurden oder nicht.
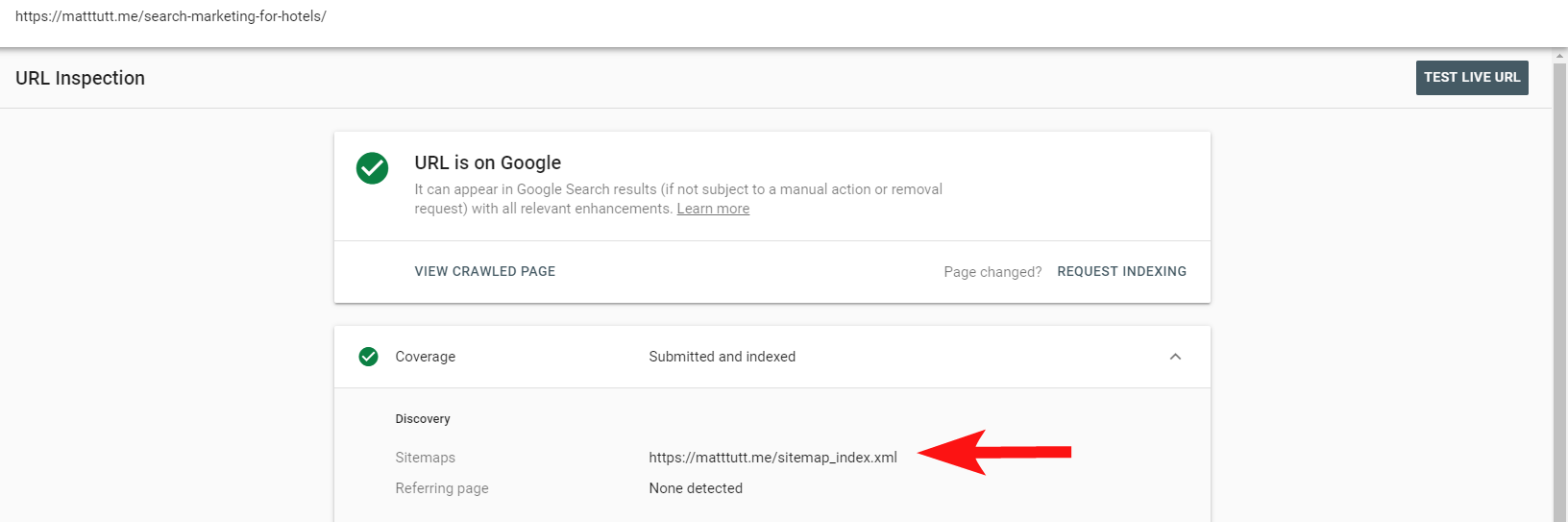
Wenn Sie eine relativ kleine Website haben, können Sie Ihre XML-Sitemap wahrscheinlich einfach manuell in Ihrem Browser überprüfen – andernfalls laden Sie sie herunter und vergleichen Sie sie mit einem vollständigen Crawl Ihrer indexierbaren URLs.
Oft können Sie diese Art von minderwertigem, unschätzbarem Inhalt abfangen, indem Sie eine site:domain.com-Suche in Google durchführen, um alle indexierten Inhalte anzuzeigen.
An dieser Stelle sei darauf hingewiesen, dass dies alte Inhalte enthalten kann und man sich nicht darauf verlassen sollte, dass es zu 100 % auf dem neuesten Stand ist, aber es ist eine einfache Überprüfung, um sicherzustellen, dass es keine Schiffsladungen an Inhalten gibt, die Ihre SEO-Bemühungen aufblähen und Crawl-Budgets auffressen.
4 – Probleme mit dem Rendern Ihres Inhalts durch den Googlebot
Dieser ist einen ganzen Artikel wert, der ihm gewidmet ist, und ich persönlich habe das Gefühl, dass ich ein Leben lang mit dem Abruf- und Rendering-Tool von Google gespielt habe.
Darüber (und über JavaScript) wurde bereits viel von einigen sehr fähigen SEOs gesagt, daher werde ich nicht zu tief darauf eingehen, aber zu überprüfen, wie der Googlebot Ihre Website darstellt, wird Ihre Zeit immer wert sein.
Das Ausführen einiger Überprüfungen über Online-Tools kann helfen, Googlebot-Blindspots (Bereiche auf der Website, auf die sie nicht zugreifen können), Probleme mit Ihrer Hosting-Umgebung, problematisches JavaScript, das Ressourcen verbraucht, und sogar Probleme mit der Bildschirmskalierung aufzudecken.
Normalerweise sind diese Tools von Drittanbietern sehr hilfreich bei der Diagnose des Problems (Google sagt Ihnen sogar, wenn eine Ressource beispielsweise aufgrund Ihrer Robots-Datei blockiert ist), aber manchmal drehen Sie sich möglicherweise im Kreis.
Um ein Live-Beispiel einer problematischen Website zu zeigen, werde ich mir selbst ins Knie schießen und auf meine eigene persönliche Website verweisen – und auf ein besonders frustrierendes WordPress-Theme, das ich verwende.
Manchmal, wenn ich eine URL-Prüfung von der Search Console aus durchführe, erhalte ich die Warnung „Seite ist nicht für Mobilgeräte optimiert“ (siehe unten).
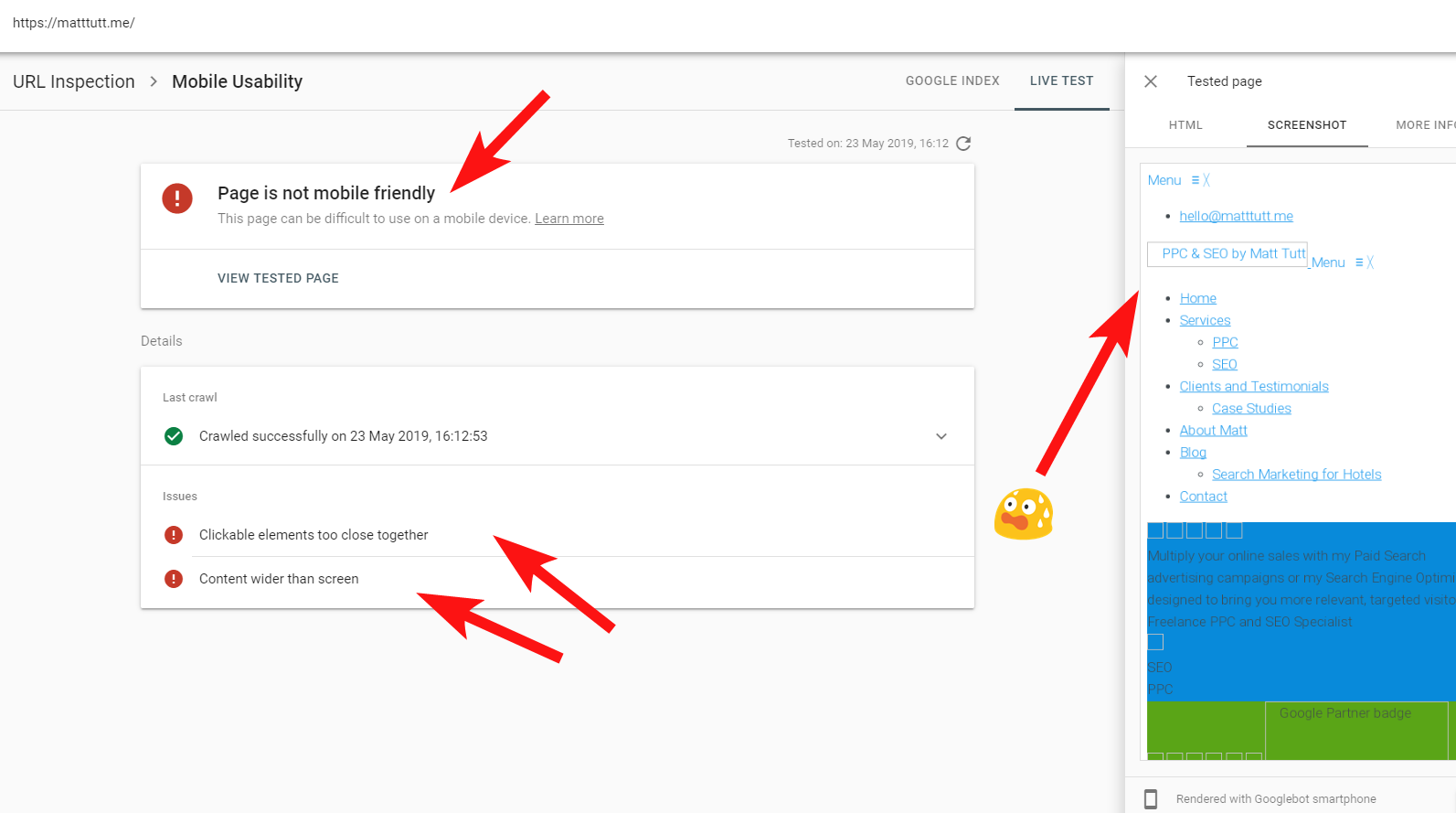
Wenn Sie auf die Registerkarte „Weitere Informationen“ (oben rechts) klicken, erhalten Sie eine Liste von Ressourcen, auf die der Googlebot damals nicht zugreifen konnte, hauptsächlich CSS- und Bilddateien.
Dies liegt wahrscheinlich daran, dass der Googlebot nicht immer seine volle „Energie“ in das Rendern der Seite stecken kann – manchmal liegt es daran, dass Google vorsichtig ist, meine Website zum Absturz zu bringen (was nett von ihnen ist), und manchmal bin ich möglicherweise eingeschränkt, da sie es verwendet haben viele Ressourcen, um meine Website bereits abzurufen und zu rendern.
Manchmal lohnt es sich aus den oben genannten Gründen, diese Tests einige Male in verteilten Intervallen durchzuführen, um eine wahrere Geschichte zu erhalten. Ich empfehle außerdem, nach Möglichkeit die Serverprotokolle zu überprüfen, um zu überprüfen, wie der Googlebot auf Ihre Websiteinhalte zugegriffen (oder nicht zugegriffen) hat.
404- oder andere schlechte Status für diese Ressourcen wären eindeutig ein schlechtes Zeichen, insbesondere wenn sie konsistent sind.
In meinem Fall weist Google die Seite darauf hin, dass sie nicht für Mobilgeräte geeignet ist, was hauptsächlich darauf zurückzuführen ist, dass bestimmte CSS-Stildateien während des Renderns fehlschlagen, was zu Recht Alarmglocken läuten kann.
Um die Sache noch verwirrender zu machen, werden beim Ausführen des Mobile Friendly Tests von Google oder bei Verwendung eines anderen Tools von Drittanbietern keine Probleme erkannt: Die Website ist für Mobilgeräte optimiert.
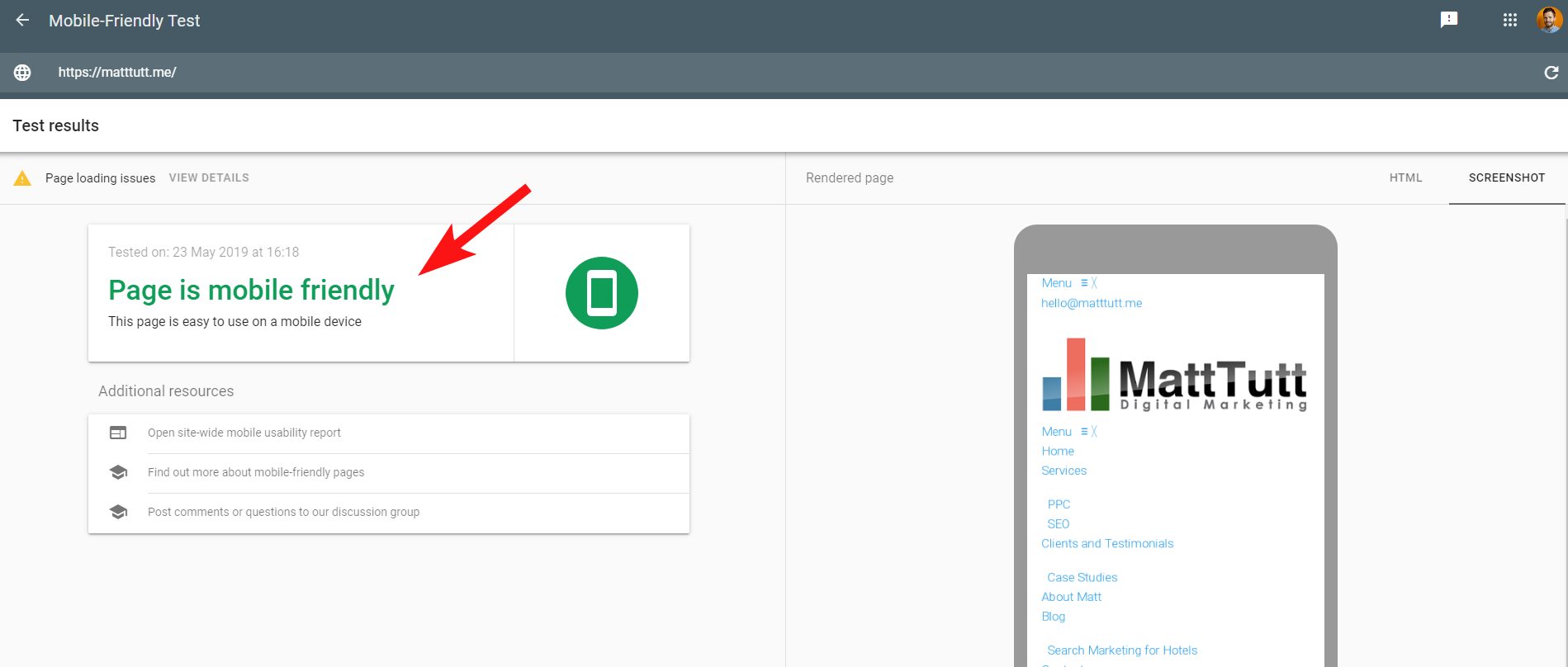
Diese widersprüchlichen Nachrichten von Google können für SEOs und Webentwickler schwierig zu entschlüsseln sein. Um weiter zu verstehen, habe ich mich an John Mueller gewandt, der vorschlug, meinen Webhost zu überprüfen (keine Probleme) und dass die CSS-Datei tatsächlich von Google zwischengespeichert werden kann.
Die Search Console verwendet im Vergleich zum Mobile-Friendly Tool einen älteren Web Rendering Service (WRS), daher tendiere ich heutzutage dazu, Letzteres stärker zu gewichten.
Da Google einen neueren Googlebot mit den neuesten Rendering-Funktionen ankündigt, könnte sich dies alles ändern, sodass es sich lohnt, auf dem Laufenden zu bleiben, welche Tools für Rendering-Prüfungen am besten geeignet sind.
Ein weiterer Tipp hier – wenn Sie ein vollständig scrollbares Rendering einer Seite sehen möchten, können Sie vom mobilen Testtool von Google zum HTML-Tab wechseln, STRG+A drücken, um den gesamten gerenderten HTML-Code hervorzuheben, dann kopieren und in einen Texteditor einfügen und als HTML-Datei speichern.
Wenn Sie das in Ihrem Browser öffnen (Daumen drücken, manchmal hängt es vom verwendeten CMS ab!), erhalten Sie ein scrollbares Rendering. Und der Vorteil davon ist, dass Sie überprüfen können, wie jede Website gerendert wird – Sie benötigen keinen Zugriff auf die Search Console.
5 – Gehackte Seiten und Spam-Backlinks
Das macht Spaß und kann sich oft auf Websites einschleichen, die auf älteren Versionen von WordPress oder anderen CMS-Plattformen laufen, die regelmäßige Sicherheitsupdates erfordern.
Bei diesem Kunden (einem Beauty-Spa) sind mir einige seltsame Suchbegriffe in der Search Console aufgefallen.
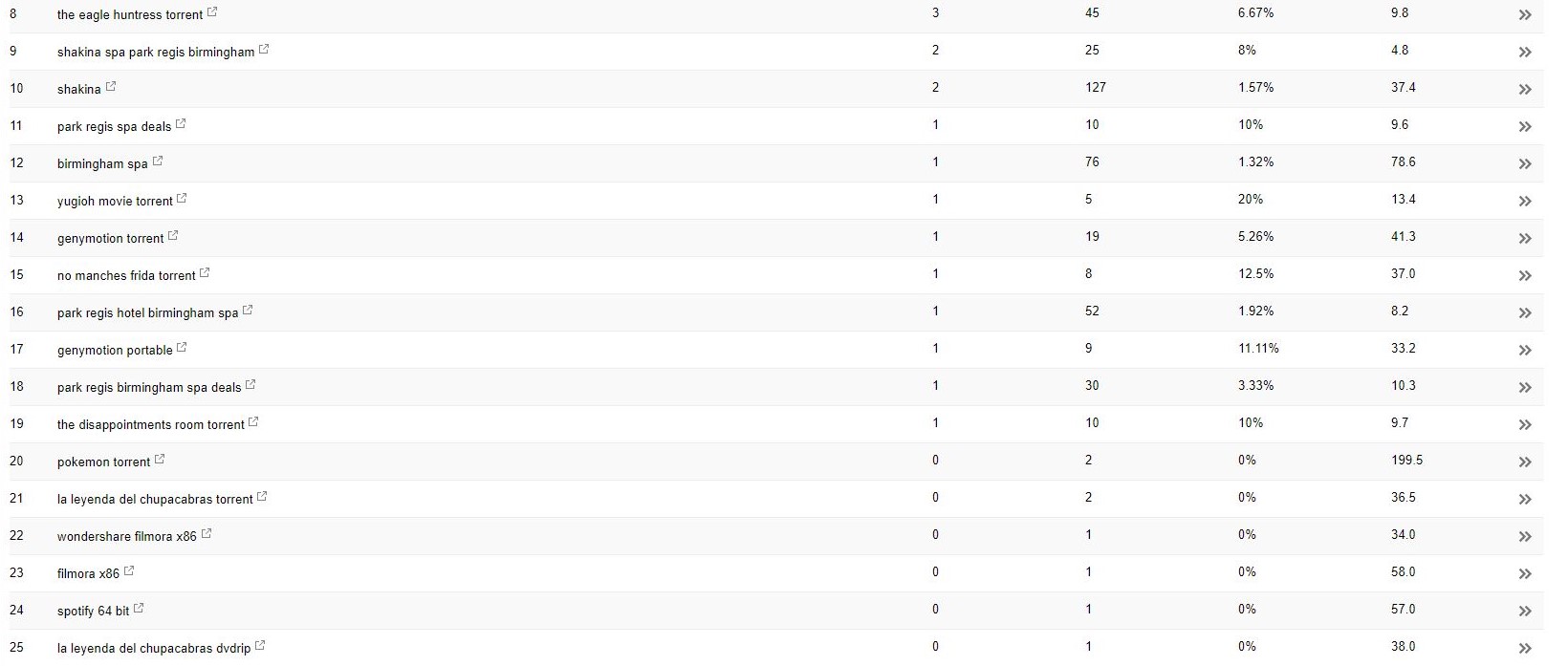
Überraschenderweise hatten sie nicht nur Impressionen in der Search Console, sondern auch Klicks – was bedeutet, dass etwas auf der Domain indiziert worden sein muss.
Den Anfragen nach zu urteilen, war es eindeutig sehr spammy und nichts, womit der Kunde sein Geschäft in Verbindung bringen möchte.
Eine einfache „site:domain.com“-Suche in Google brachte Hunderte von Seiten mit vermeintlichen Torrents zutage, die der Kunde angeblich auf seiner Website gehostet hatte.
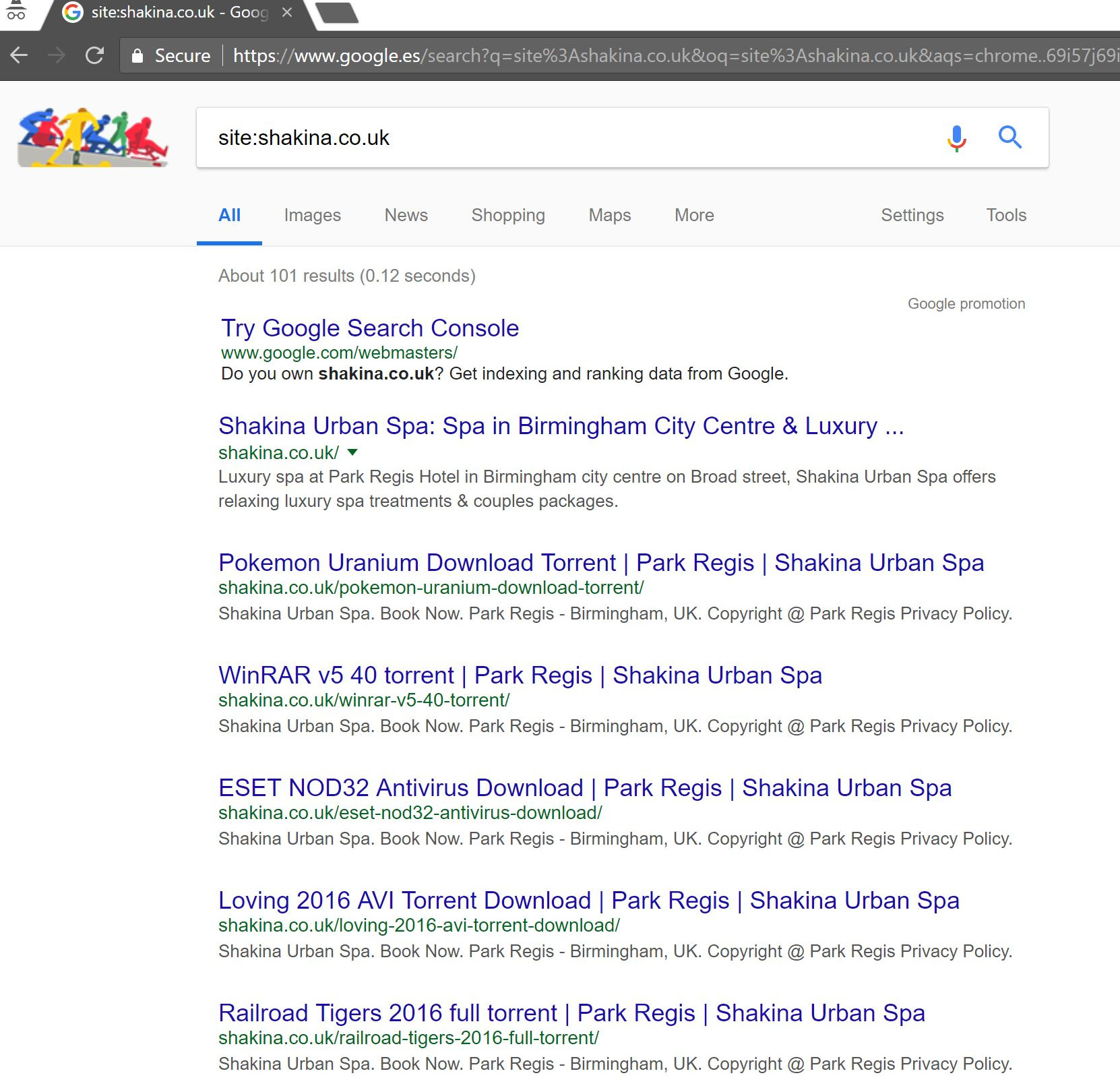
Der Besuch einer dieser URLs führte tatsächlich zu einem 404-Fehler – sie waren jedoch immer noch indexiert (ich habe auch verschiedene User Agents überprüft und sie alle erhielten denselben 404-Fehler).
Als nächstes ließ ich die Domain durch den Backlink-Checker von Majestic laufen und es gab eine lange Liste von Backlinks von sehr geringer Qualität, die auf diese Seiten auf den Kundenseiten verweisen – was wahrscheinlich dazu beitrug, dass sie indexiert wurden.
Ein Blick auf Majestics Anchor Cloud der Backlinks zeigte wirklich das Ausmaß des Problems.


Die einzige Lösung hier war, all diese Backlinks nach Domain zu disavowen und dann einen sauberen Durchlauf der WordPress-Installation durchzuführen, in der Hoffnung, alle Code-Injektionen zu beseitigen, oder eine neue Kopie von WordPress zu installieren.
Wenn Sie in Fällen wie dem obigen wirklich über indexierte Inhalte besorgt sind, können Sie auch einen 410-Statuscode bereitstellen, um die Dinge mit den Such-Crawlern wirklich zu klären.
Das Obige würde für Websites passen, denen aufgrund von Urheberrechtsansprüchen von Filmproduzenten rechtliche Warnungen zugestellt wurden – was in Situationen wie dieser manchmal vorkommen kann, wenn das Problem nicht schnell gelöst wird.
6 – Schlechte internationale SEO-Setups
Da ich in Spanien ansässig bin, aber in meiner Muttersprache Englisch im Internet surfe, werde ich oft automatisch auf eine spanische Version einer Website weitergeleitet.
Obwohl ich die Logik verstehe (ich wohne in Spanien, daher möchte ich die Website auf Spanisch durchsuchen), ist es aus Sicht der Benutzererfahrung ziemlich ärgerlich und kann, wenn es nicht richtig gemacht wird, auch ein bisschen Chaos bei Ihrer internationalen SEO verursachen.
Websites wie Google Ads bringen dies auf eine andere Ebene – indem sie Angular JavaScript verwenden, um Inhalte basierend auf meinem Standort dynamisch zu generieren, nicht einmal eine Seitenumleitung jeglicher Art durchlaufen und den Inhalt direkt in das DOM laden.
Meine bevorzugte Methode der Wahl, wenn mehrere Sprachen verfügbar sind, ist die 302-Umleitung eines Benutzers zu einer Sprache, die auf seinen Internetbrowser-Einstellungen basiert.
Wenn also jemand Deutsch als Standardsprache in Google Chrome hat, liest er die Website wahrscheinlich problemlos auf Deutsch, unabhängig von seinem physischen Standort.
Dies hilft auch, Schwierigkeiten zu bewältigen, wenn jemand in einer Region lebt, in der verschiedene Sprachen gesprochen werden, wie in der Schweiz, wo Französisch, Italienisch, Deutsch und Rätoromanisch verwendet werden.
Es ist auch aus Gründen der Benutzerfreundlichkeit wichtig, sicherzustellen, dass es eine Option gibt, die Sprache nach Ihren Wünschen zu wechseln – nur für den Fall, dass sie wechseln möchten.
In einem Fall habe ich mit einem Hotel in Barcelona zusammengearbeitet, wo ein Umleitungsskript in JavaScript-Sprache zu einer Website hinzugefügt wurde, ohne die SEO-Auswirkungen zu berücksichtigen.
Dieses Skript leitete Benutzer basierend auf ihrer Browser-Spracheinstellung (was an sich nicht allzu schlecht ist) über eine clientseitige JavaScript-Umleitung um.
Leider war das Skript in diesem Fall aufgrund einer seltsamen Konfiguration der Seiten-Permalinks nicht korrekt eingerichtet, und in Kombination mit der Tatsache, dass das HTML-lang-Tag auf allen Seiten der Website fehlte, drehte der Googlebot ein bisschen durch…
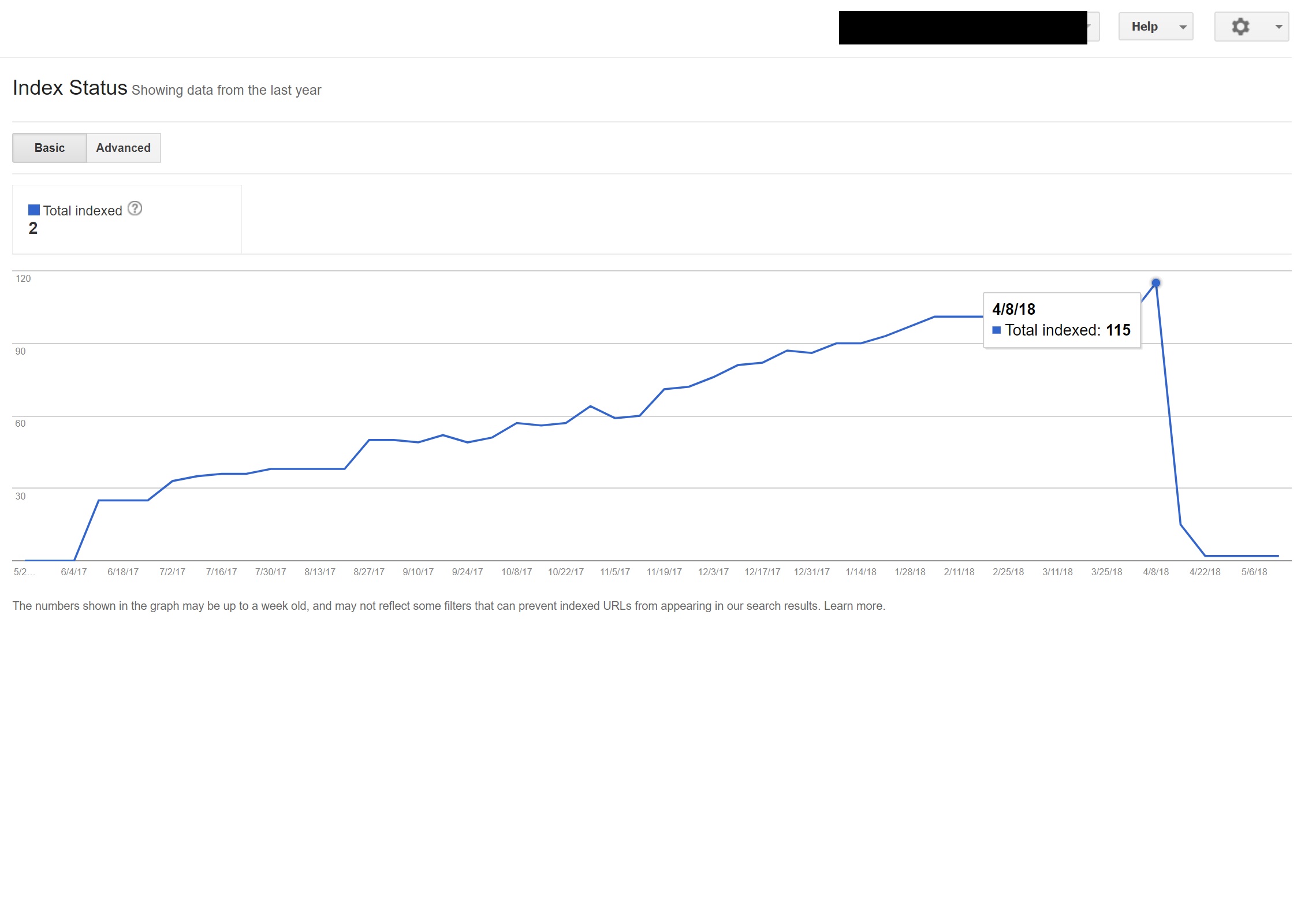
In diesem Beispiel wurden fast alle nicht-englischen Inhalte auf der Website von Google de-indexiert, da sie auf Seiten umgeleitet wurden, die nicht existierten, wodurch mehrere 404-Fehler geliefert wurden.
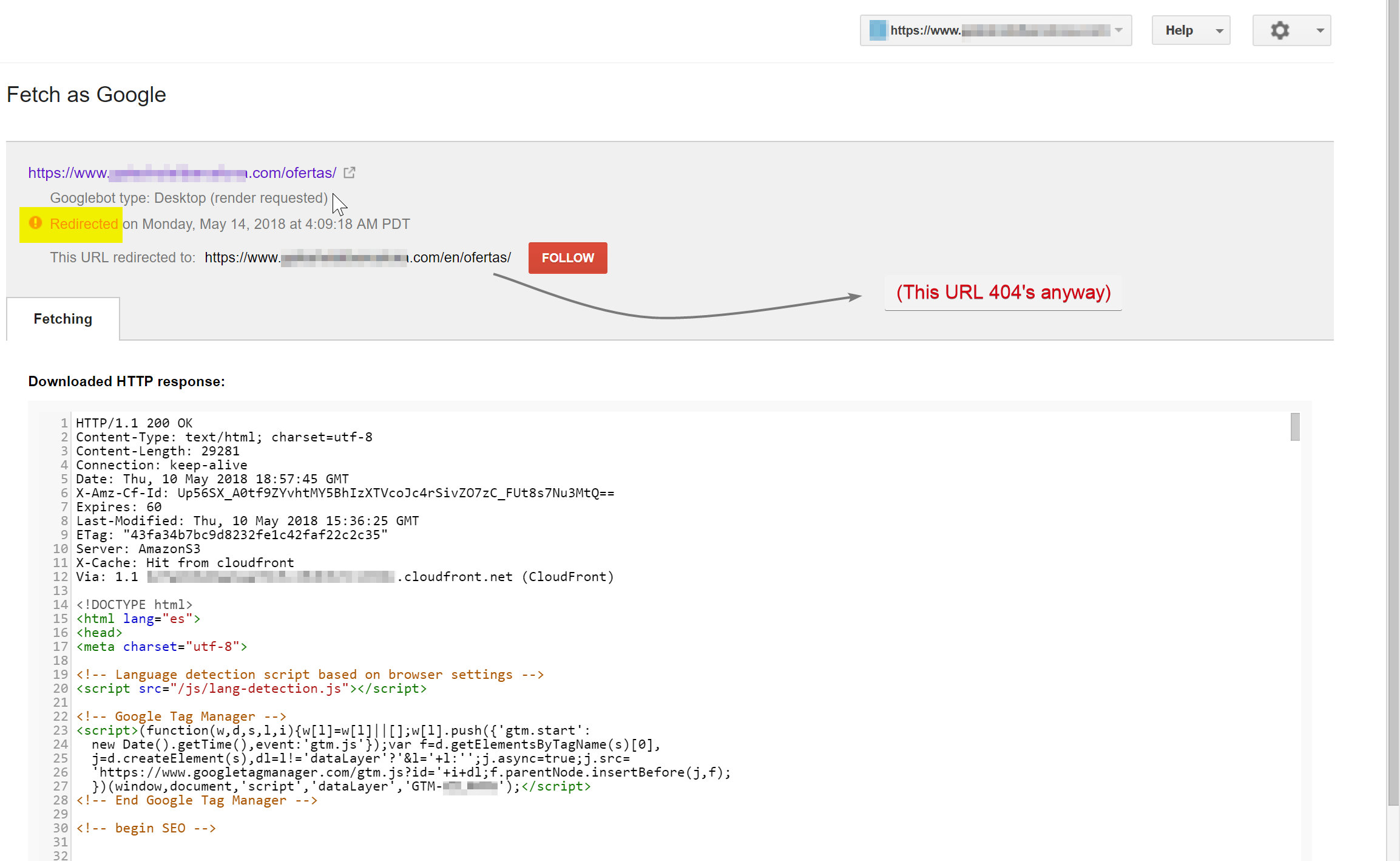
Der Googlebot versuchte, den spanischen Inhalt zu crawlen (der unter hotelname.com/ofertas existierte) und wurde zu hotelname.com/en/ofertas umgeleitet – eine nicht vorhandene URL.
Überraschenderweise folgte der Googlebot in diesem Fall all diesen JavaScript-Weiterleitungen, und da er diese URLs nicht finden konnte, war er gezwungen, sie aus seinem Index zu entfernen.
Im obigen Fall konnte ich dies bestätigen, indem ich auf die Serverprotokolle der Website zugegriffen, nach Googlebot gefiltert und überprüft habe, wo 404-Fehler angezeigt wurden.
Durch das Entfernen des fehlerhaften JavaScript-Umleitungsskripts wurde das Problem behoben, und glücklicherweise wurden die übersetzten Seiten nicht lange de-indexiert.
Es ist immer eine gute Idee, die Dinge vollständig zu testen – die Investition in ein VPN kann helfen, diese Art von Szenarien zu diagnostizieren oder sogar Ihren Standort und/oder Ihre Sprache im Chrome-Browser zu ändern.
[Fallstudie] Umgang mit Audits an mehreren Standorten
 Lesen Sie die Fallstudie
Lesen Sie die Fallstudie7 – Doppelte Inhalte
Doppelte Inhalte sind ein weit verbreitetes und viel diskutiertes Problem, und es gibt viele Möglichkeiten, wie Sie auf Ihrer Website nach doppelten Inhalten suchen können – Richard Baxter hat kürzlich einen großartigen Artikel zu diesem Thema geschrieben.
In meinem Fall ist das Problem wahrscheinlich ein bisschen einfacher. Ich habe regelmäßig Websites gesehen, die großartige Inhalte veröffentlicht haben, oft als Blog-Beitrag, aber dann fast sofort einige Inhalte auf einer Website eines Drittanbieters wie Medium.com geteilt haben.
Medium ist eine großartige Website, um vorhandene Inhalte umzufunktionieren, um ein breiteres Publikum zu erreichen, aber es sollte darauf geachtet werden, wie dies angegangen wird.
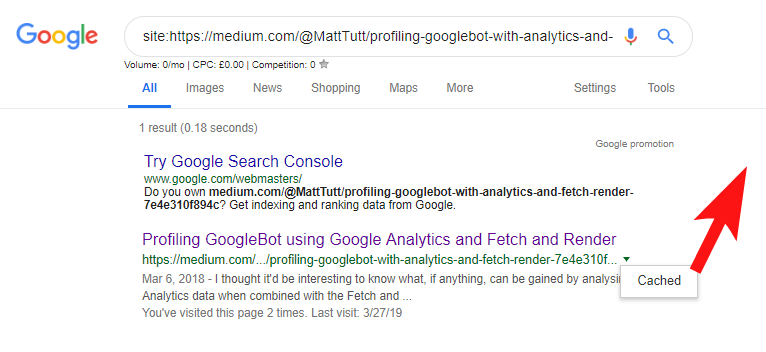
Beim Importieren von Inhalten von WordPress auf Medium verwendet Medium während dieses Vorgangs Ihre Website-URL als kanonisches Tag. Theoretisch sollte es also helfen, Ihrer Website den Inhalt als Originalquelle zu nennen.
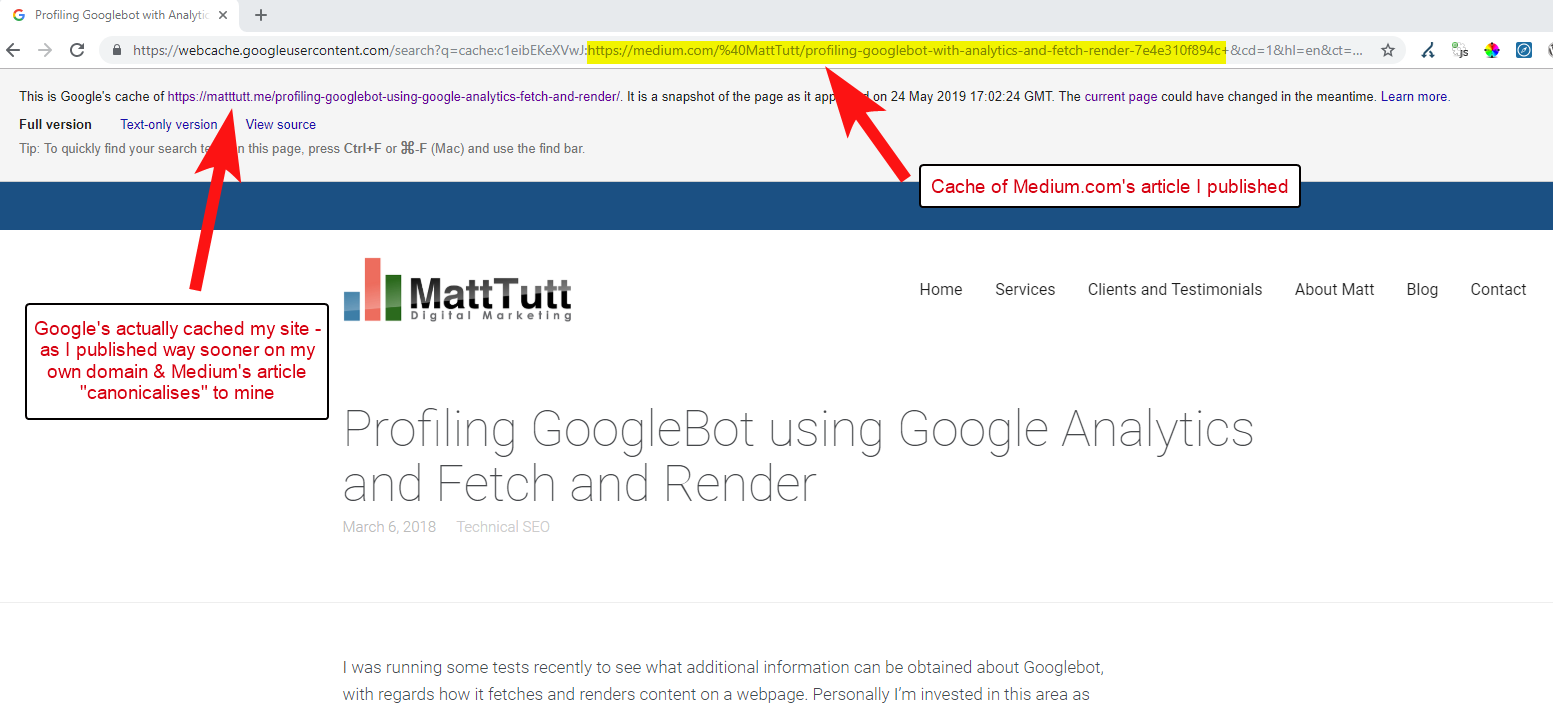
Aus einigen meiner Analysen geht hervor, dass es nicht immer so funktioniert.
Ich glaube, dass dies der Fall ist, denn wenn ein Artikel auf Medium veröffentlicht wird, ohne Google zuerst Zeit zu geben, den Artikel auf Ihrer Domain zu crawlen und zu indexieren, wenn der Artikel auf Medium gut ankommt (was ein bisschen Erfolg oder Misserfolg ist), erhält Ihr Inhalt trotz ihres kanonischen Verweises auf Ihre Website indiziert und mit der Website von Medium verknüpft.
Sobald Inhalte zu Medium hinzugefügt werden (und insbesondere, wenn sie beliebt sind), können Sie ziemlich sicher sein, dass das Stück fast sofort an anderer Stelle abgekratzt und erneut im Internet veröffentlicht wird – also wird Ihr Inhalt erneut an anderer Stelle dupliziert.
Während dies alles vor sich geht, besteht die Möglichkeit, dass Google bei einer recht kleinen Domain in Bezug auf die Autorität möglicherweise nicht einmal die Möglichkeit hatte, die von Ihnen veröffentlichten Inhalte zu crawlen und zu indizieren – und es könnte sogar der Fall sein, dass das Rendering-Element der Crawl/Index wurde noch nicht abgeschlossen, oder es gibt viel JavaScript, das eine große Zeitverzögerung zwischen dem Crawlen, Rendern und Indexieren dieses Inhalts verursacht.
Ich habe Situationen erlebt, in denen ein großes Unternehmen einen großartigen Artikel veröffentlichte, ihn aber am nächsten Tag als Gedankenbeitrag in einem riesigen Branchennachrichtenblog veröffentlichte. Darüber hinaus hatte ihre Website ein Problem, bei dem Inhalte unter https://domain.com und https://www.domain.com dupliziert (und indiziert) wurden.
Wenige Tage nach der Veröffentlichung war bei der Suche nach einer genauen Wortgruppe des Artikels in Anführungszeichen bei Google die Unternehmenswebsite nirgendwo zu finden. Stattdessen lag der maßgebliche Branchenblog auf Platz eins, und andere Re-Publisher nahmen die nächsten Positionen ein.
In diesem Fall wurde der Inhalt mit dem Branchenblog verknüpft, sodass alle Links, die das Stück erhält, dieser Website zugute kommen – nicht dem ursprünglichen Herausgeber.
Wenn Sie Inhalte irgendwo im Web wiederverwenden möchten, werden sie wahrscheinlich indexiert. Sie sollten wirklich warten, bis Sie absolut sicher sind, dass sie von Google auf Ihrer eigenen Domain indexiert wurden.
Sie arbeiten wahrscheinlich hart, um Ihre Inhalte zu erstellen und zu gestalten – werfen Sie das nicht alles weg, indem Sie zu erpicht darauf sind, es woanders erneut zu veröffentlichen!
8 – Schlechte AMP-Konfiguration (fehlende AMP-URL-Deklaration)
Nur eine Handvoll der Kunden, denen ich geholfen habe, haben sich dafür entschieden, AMP auszuprobieren, vielleicht basierend auf einigen der vielen von Google finanzierten Fallstudien zu seiner Verwendung.
Manchmal war mir nicht einmal bewusst, dass ein Kunde überhaupt eine AMP-Version seiner Website hatte – es gab einige seltsame Zugriffe, die in den Analytics-Verweisberichten auftauchten – wo die AMP-Version der Website auf die Version der Nicht-AMP-Website zurückverlinkte.
In diesem Fall wurden die AMP-Seitenversionen nicht richtig konfiguriert, da es keine URL-Referenz vom Kopf der Nicht-AMP-Seiten gab.

Ohne den Suchmaschinen mitzuteilen, dass eine AMP-Seite unter einer bestimmten URL vorhanden ist, macht es nicht viel Sinn, überhaupt AMP einzurichten – der Punkt ist, dass sie indexiert und in den SERPS für mobile Benutzer zurückgegeben wird.
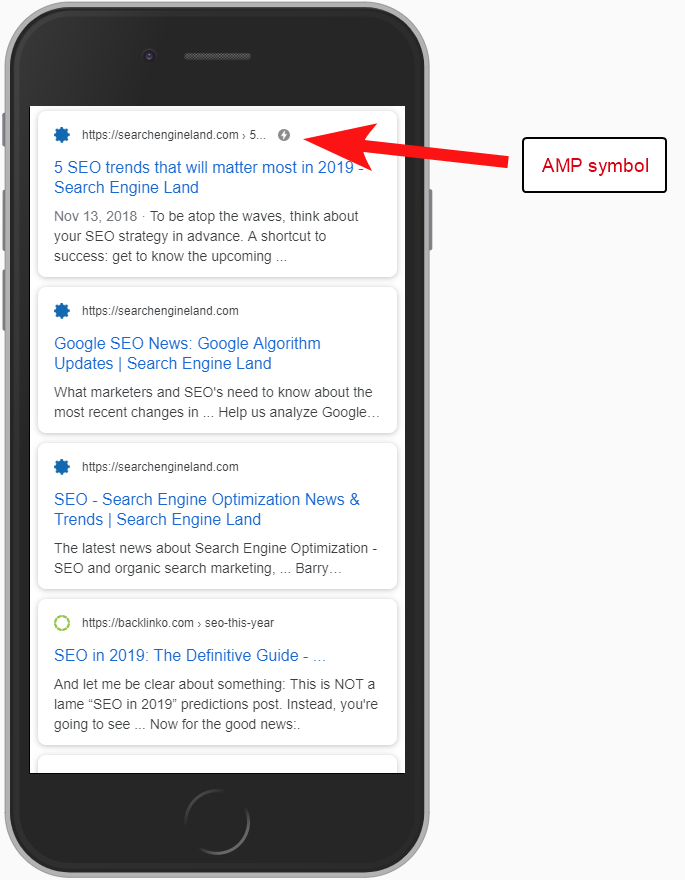
Das Hinzufügen des Verweises auf Ihre Nicht-AMP-Seite ist eine wichtige Möglichkeit, Google über die AMP-Seite zu informieren, und es ist wichtig, daran zu denken, dass kanonische Tags auf AMP-Seiten nicht selbstreferenzierend sein sollten: Sie verlinken zurück auf die Nicht-AMP-Seite.
Und obwohl es nicht wirklich eine technische SEO-Überlegung ist, ist es erwähnenswert, dass Sie dennoch Tracking-Code auf AMP-Seiten einfügen müssen, wenn Sie in der Lage sein möchten, über Datenverkehr und Benutzerverhalten zu berichten.
Typischerweise führe ich im Rahmen meiner SEO-Audits auch gerne einige grundlegende Überprüfungen der Analytics-Implementierung durch – andernfalls sind die Ihnen bereitgestellten Daten möglicherweise nicht wirklich hilfreich, insbesondere wenn eine fehlerhafte Analytics-Einrichtung vorliegt.
9 – Legacy-Domains, die 302 weiterleiten oder eine Kette von Weiterleitungen bilden
Wenn Sie mit einer großen unabhängigen Hotelmarke in den USA zusammenarbeiten, die in den letzten Jahren mehrere Rebrandings durchlaufen hatte (in der Hotellerie durchaus üblich), ist es wichtig, zu überwachen, wie sich frühere Anfragen nach Domainnamen verhalten.
Dies ist leicht zu vergessen, aber es könnte sich um eine einfache halbjährliche Überprüfung handeln, bei der versucht wird, ihre alte Website mit einem Tool wie OnCrawl zu crawlen, oder sogar um eine Website eines Drittanbieters, die nach Statuscodes und Weiterleitungen sucht.
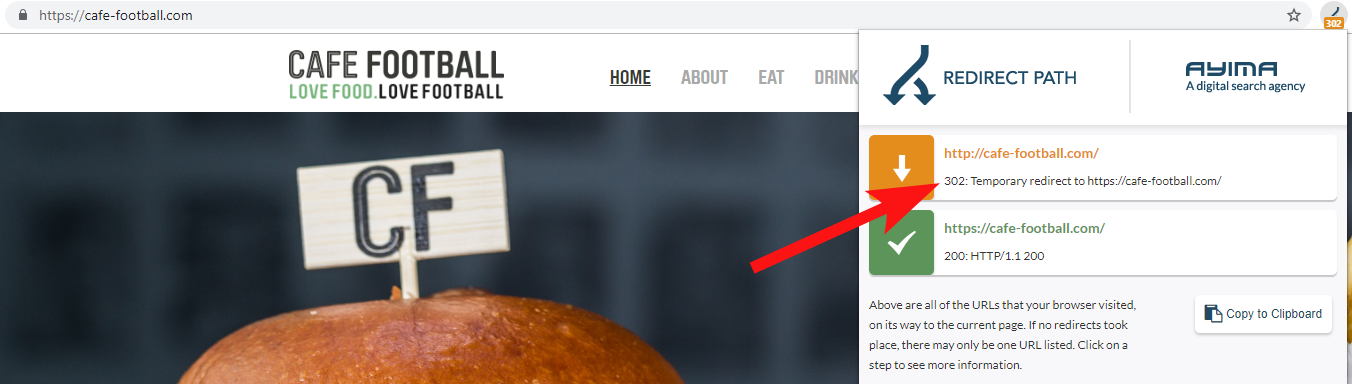
In den meisten Fällen werden Sie feststellen, dass die Domain 302 zum endgültigen Ziel weiterleitet (301 ist hier immer die beste Wahl) oder zu einer Nicht-WWW-Version der URL, bevor Sie durch mehrere weitere Weiterleitungen springen, bevor Sie die endgültige URL erreichen.
John Mueller von Google hatte zuvor erklärt, dass sie nur 5 Weiterleitungen folgen, bevor sie aufgeben, während es auch bekannt ist, dass für jede weitergeleitete Weiterleitung ein Teil des Linkwerts verloren geht. Aus diesen Gründen halte ich mich lieber an 301-Weiterleitungen, die so sauber wie möglich sind.
Redirect Path von Ayima ist eine großartige Chrome-Browsererweiterung, die Ihnen den Umleitungsstatus anzeigt, während Sie im Internet surfen.
Eine andere Möglichkeit, alte Domainnamen eines Kunden zu finden, besteht darin, bei Google nach seiner Telefonnummer zu suchen, indem ich exakt passende Anführungszeichen oder Teile seiner Adresse verwende.
Ein Unternehmen wie ein Hotel ändert nicht oft die Adresse (zumindest teilweise) und Sie finden möglicherweise alte Verzeichnisse/Unternehmensprofile, die auf eine alte Domain verlinken.
Die Verwendung eines Backlink-Tools wie Majestic oder Ahrefs zeigt möglicherweise auch einige alte Links von früheren Domains an, daher ist dies auch eine gute Anlaufstelle – insbesondere, wenn Sie nicht direkt mit dem Kunden in Kontakt stehen.
10 – Schlechter Umgang mit internen Suchinhalten
Dies ist eigentlich ein Thema, über das ich schon einmal hier bei OnCrawl geschrieben habe – aber ich nehme es wieder auf, weil ich immer noch sehr oft sehe, dass problematische interne Inhalte „in freier Wildbahn“ vorkommen.
Ich begann diesen Artikel, indem ich über das Problem mit der robots.txt-Anweisung von Pingdom sprach, das von außen wie eine Lösung aussah, um zu verhindern, dass von ihnen ausgegebene Inhalte gecrawlt und indiziert wurden.
Jede Website, die interne Suchergebnisse für Google als Inhalt bereitstellt oder viele nutzergenerierte Inhalte ausgibt, muss sehr vorsichtig sein, wie sie dies tut.
Wenn eine Website interne Suchergebnisse auf sehr direkte Weise an Google liefert, kann dies zu einer Art manueller Strafe führen. Google würde das wahrscheinlich als schlechte Benutzererfahrung ansehen – sie suchen nach X und landen dann auf einer Website, wo sie dann manuell nach dem filtern müssen, was sie wollen.
In einigen Fällen glaube ich, dass es in Ordnung sein kann, interne Inhalte bereitzustellen, es hängt nur vom Kontext und den Umständen ab. Eine Jobbörse möchte beispielsweise die neuesten Jobergebnisse liefern, die fast täglich aktualisiert werden – also müssen sie sich fast damit auseinandersetzen.
Indeed ist ein berühmtes Beispiel für eine Jobseite, die vielleicht zu weit geht und alle Arten von Inhalten basierend auf beliebten Suchanfragen generiert (siehe unten, was passieren kann, wenn Sie diese Taktik anwenden).
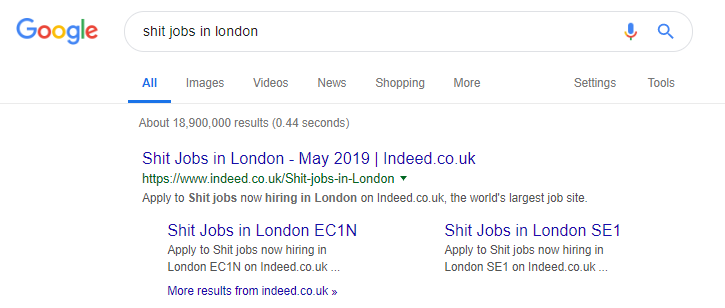
Trotzdem läuft ihr organischer Traffic laut SEMRush-Daten großartig – aber das sind schmale Grate, und wenn Sie sich so verhalten, setzen Sie sich einem hohen Risiko einer Google-Abstrafung aus.
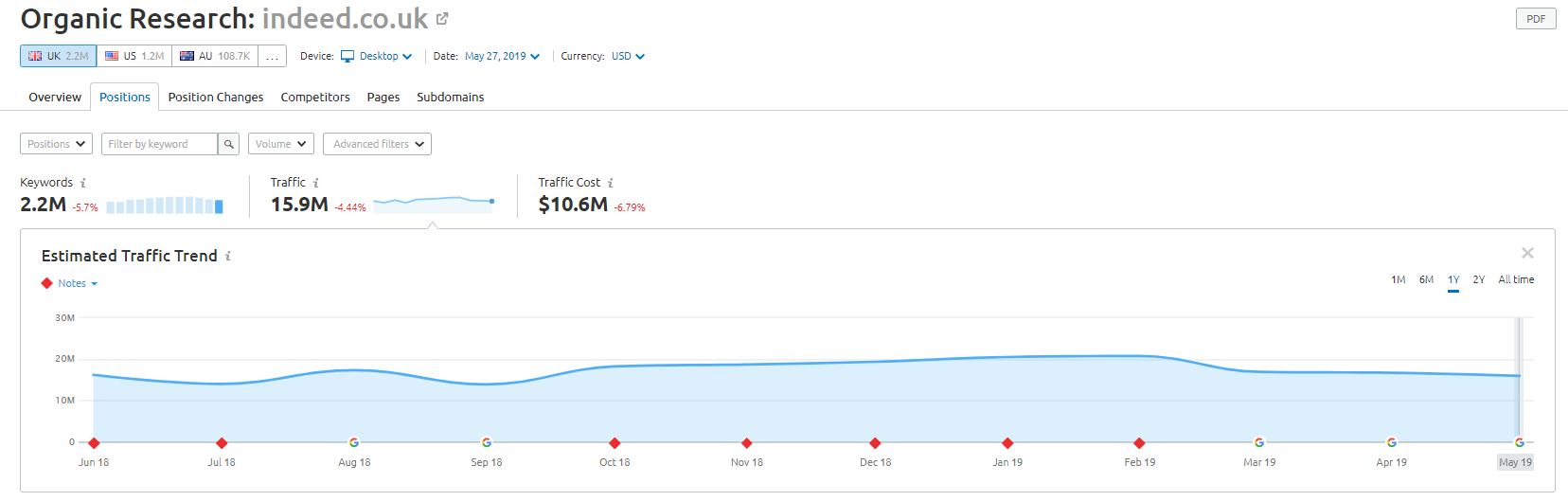
Der Online-Händler Wayfair.com ist eine weitere Marke, die gerne hart am Wind segelt. Mit Millionen von indizierten URLs (und vielen automatisch generierten Keyword-URLs) schneiden sie in Bezug auf den organischen Traffic hervorragend ab – aber sie laufen Gefahr, dafür bestraft zu werden, dass sie den Suchmaschinen Inhalte auf diese Weise zur Verfügung stellen.
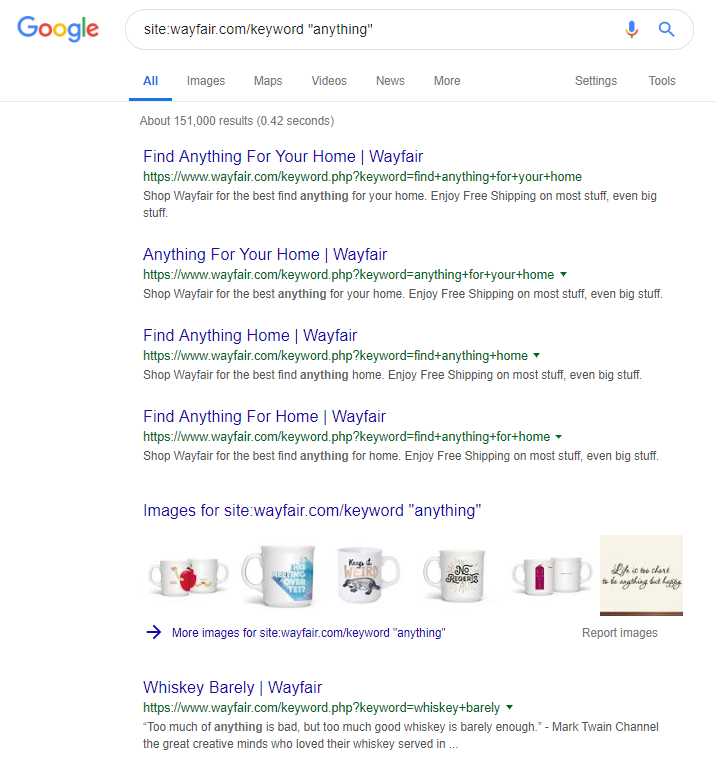
Durch die Implementierung einer ordnungsgemäßen Websitestruktur, die die Kategorisierung aller Inhalte, den Aufbau der verschiedenen Eltern-/Kind-Hierarchien und sogar die Verwendung von Tags oder anderen benutzerdefinierten Taxonomien umfasst, können Sie die Navigation von Kunden und Such-Crawlern unterstützen.
Die Verwendung von Tricks wie den oben genannten kann kurzfristig gewinnen, aber es ist unwahrscheinlich, dass sie langfristig viel für Sie tun. Daher ist es wichtig, die Website von Anfang an richtig zu strukturieren oder zumindest im Voraus richtig zu planen.
Einpacken
Die 10 in diesem Artikel besprochenen Fehler sind einige der häufigsten technischen Probleme, auf die ich bei Site-Audits stoße.
Das Korrigieren dieser Fehler auf Ihrer Website ist ein erster Schritt, um sicherzustellen, dass Ihre Website technisch einwandfrei ist. Sobald diese Probleme behoben sind, können sich technische Audits auf Probleme konzentrieren, die für Ihre Site spezifisch sind.