
Business-orientierte Data Science
Veröffentlicht: 2018-12-13Sie sagen, Data Scientist sei der sexieste Job des 21. Jahrhunderts (und alle Data Scientists, die ich auf verschiedenen Konferenzen getroffen habe, wissen das). Aber wenn sie nur über den theoretischen Teil des maschinellen Lernens sprechen, frage ich mich manchmal, ob sie wissen, warum ihre Arbeit heiß ist. Der Grund dafür ist, dass ein Data Scientist weiß, wie man Daten, technische Fähigkeiten und statistisches Wissen kombiniert, um Geschäftsziele zu erreichen. Um Data Science gut zu machen, müssen Sie also zuerst an das Geschäft denken.
Ich kenne Fälle, in denen Unternehmen Analysetools hinzugefügt haben, um die Berührung jedes Benutzers zu verfolgen, ohne sich Gedanken darüber zu machen, was sie eigentlich erreichen wollen. Sie sammelten viele Daten, die sie nicht verstanden und die sie nicht nutzen konnten, um ihr Geschäft voranzutreiben.
Machen Sie solche Fehler nicht! Denken Sie bei jedem Schritt des Data-Science-Prozesses über Ihre Ziele und die Branchenspezifika nach. Je kreativer Sie sind, desto größer sind Ihre Erfolgschancen. Um das zu beweisen, zeige ich Ihnen einige inspirierende Beispiele für Data Science in den Anwendungen der Giganten…
So starten Sie Ihr Data-Science-Abenteuer
Sie haben gehört, dass viele Unternehmen ML verwenden, um ihr Einkommen zu steigern, aber Sie haben keine Ahnung, wie Sie anfangen sollen? Um am Ende nicht mit teurer Infrastruktur und nicht hilfreichen Daten (zur Erfüllung Ihrer Geschäftsanforderungen) zu enden, sollten Sie mit der Beantwortung der folgenden Fragen beginnen:
Was sind die Geschäftsziele des Kunden? Wie können wir Daten nutzen, um sie zu erreichen?
Dann können Sie mit der Planung beginnen, welche Daten nachverfolgt und verwendet werden können.
Datenerfassung
Welche Daten sollen wir sammeln? Die Antwort auf diese Frage könnte Sie tatsächlich überraschen. Laut Todd Yellin (VP of Product Innovation bei Netflix) gibt es zwei Arten von Daten, die verwendet werden können: explizite und implizite [1]. Im Fall von Netflix ist das explizit, wenn der Benutzer einen Film buchstäblich bewertet. Implizit sind dagegen Verhaltensdaten – basierend auf Nutzerklicks und Nutzung der App. Welche Art ist wertvoller?
Auf diese Frage gibt es keine allgemeingültige Antwort, aber in den meisten Fällen wären die impliziten Daten nützlicher . Und das liegt daran, dass … Menschen lügen.
Betrachten Sie das Beispiel des Mannes, der sagt, dass er Dokumentarfilme liebt und sie mit 5/5 bewertet. Aber wie die Daten zeigen, sieht er sich dieses Genre einmal im Jahr an. Gleichzeitig schaut er sich jeden Freitagabend beliebte Serien an. Und das liegt daran, dass er nach der Arbeit müde ist und einfach nur auf der Couch entspannen möchte. Welche Daten sollten also zur Erstellung eines solchen Empfehlungssystems herangezogen werden: Bewertung oder Nutzerverhalten?
Um diese Frage zu beantworten, müssen wir über das Geschäftsziel seiner Entwicklung nachdenken. Das Ziel von Netflix ist es, einen Benutzer zu ermutigen, mehr Filme anzusehen. Sie haben mit dem beliebten Fünf-Sterne-Bewertungssystem begonnen. Als sie erkannten, dass es wahrscheinlicher ist, dass die genannten Benutzer Friends anstelle eines Films über den Zweiten Weltkrieg sehen würden, haben sie das Empfehlungssystem basierend auf dem Benutzerverhalten entwickelt. Sie haben auch die Fünf-Sterne-Bewertung fallen gelassen und durch ein einfacheres, binäres Daumen-hoch-Daumen-runter-System ersetzt.
Wie dieses Beispiel zeigt, sollten die gesammelten Daten unter Berücksichtigung der Branchenspezifika ausgewählt werden und genügend Informationen liefern, um die Entscheidungen und Bedürfnisse der Benutzer zu verstehen. Aber hier stoßen wir auf ein anderes Problem: Verhaltensdaten, Texte und andere unstrukturierte Daten sind schwieriger zu analysieren und in Modellen des maschinellen Lernens zu verwenden als strukturierte. Jetzt ist es an der Zeit, über Feature Engineering zu sprechen.
Feature-Engineering
Um zu zeigen, wie wichtig Feature Engineering in Data Science ist, möchte ich Andrew Ng – Mitbegründer von Google Brain und Gründer von deeplearning.ai – zitieren:
Die Entwicklung von Funktionen ist schwierig, zeitaufwändig und erfordert Expertenwissen. Angewandtes maschinelles Lernen ist im Grunde Feature Engineering. [2].
https://forum.stanford.edu/events/2011/2011slides/plenary/2011plenaryNg.pdf
Ein interessantes Beispiel für einen zweckorientierten Ansatz bei der Datenverarbeitung ist Booking.com, wo Benutzer Hotels von 0 bis 10 bewerten können. Aber wenn ein Partylöwe das Hotel hoch bewertet, ist es dann eine gute Wahl für Familien mit Kindern? Nicht unbedingt.

Glücklicherweise gibt es auch Benutzerkommentare, die weitere Informationen enthalten, die wir benötigen. Booking.com verwendet Sentimentanalyse und Themenmodellierung, um die Stärken und Schwächen des kommentierten Hotels und die Vorlieben der Nutzer in Bezug auf die Unterkunft zu extrahieren.
Betrachten wir dieses Beispiel:
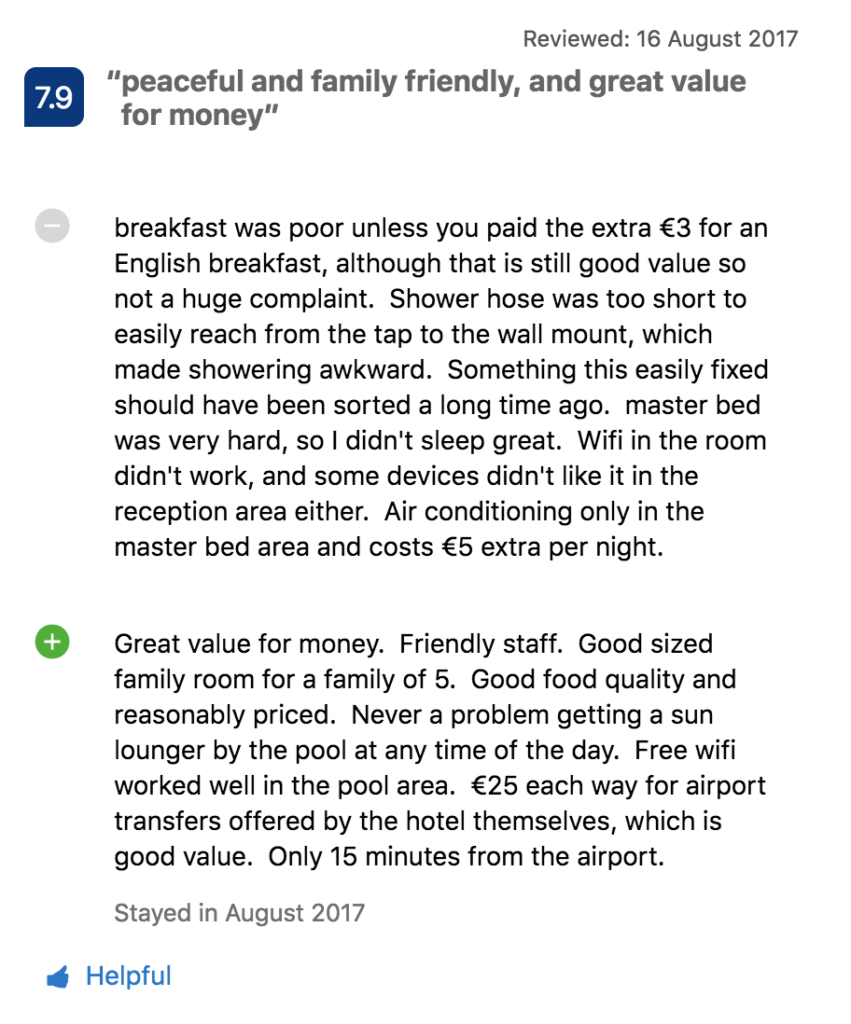
Ein Thema Zimmerausstattung hat negative Stimmung (der Benutzer beschwert sich über Dusche, Bett, WLAN und Klimaanlage). Gleichzeitig lobt dieser Nutzer das Preis-Leistungs-Verhältnis von Hotel, Personal und Essen. Das System analysiert auch, was im Kommentar nicht erwähnt wurde und daher für den Benutzer wahrscheinlich nicht wichtig ist – in unserem Beispiel kann das das Nachtleben sein.
Mit diesen Erkenntnissen kann die Plattform Hotels anbieten, die besser für Benutzer mit ähnlichem Profil geeignet sind, in diesem Fall eine Familie mit Kindern, die einen Ort suchen, an dem sie ihren Urlaub in einem ruhigen Hotel zu einem vernünftigen Preis verbringen können. Darüber hinaus sortiert Booking.com die Kommentare so, dass die interessantesten Informationen für den Betrachter ganz oben angezeigt werden.
Dies führt zu einer Win-Win-Situation: Nutzer finden schneller und einfacher Angebote, die auf ihre spezifischen Bedürfnisse zugeschnitten sind, und die Plattform erzielt einen Gewinn, da diese Angebote von den Nutzern mit größerer Wahrscheinlichkeit gekauft werden.

Neugierig auf Data Science?
Mehr erfahrenDatenprodukt
Sie haben ein Datenprodukt mit zufriedenstellenden Ergebnissen bereitgestellt? Es ist nicht die Zeit, selbstzufrieden zu sein. Wie das Beispiel Netflix zeigt [3] , kann die kontinuierliche Arbeit an der Verbesserung des Systems erhebliche Gewinne bringen. Reicht eine richtige Filmempfehlung? Was könnten wir noch tun?
Einer der Out-of-the-Box-Ansätze von Netflix besteht darin, Filme nicht nur zu empfehlen, sondern sie auch mit einem Bild zu illustrieren, das für einen bestimmten Benutzer am ansprechendsten wäre. Nehmen wir an, sie empfehlen Ihnen Good Will Hunting . Wenn Sie in der Vergangenheit viele Romcoms gesehen haben, sehen Sie vielleicht ein Bild eines sich küssenden Paares, während Sie als Comedy-Fan höchstwahrscheinlich eine Aufnahme eines beliebten amerikanischen Komikers bekommen:

Mit diesem Ansatz ist es viel wahrscheinlicher, dass ein Benutzer, der durch eine Vielzahl von Auswahlmöglichkeiten scrollt, einen Film entdeckt, der seine Aufmerksamkeit erregt.
Diese und andere Empfehlungsstrategien haben erstaunliche Ergebnisse – mehr als 80 % der Inhalte der Plattform basieren auf algorithmischen Empfehlungen . Es bedeutet, dass es für einen Benutzer schwierig ist, keine Dinge mehr zum Ansehen zu haben. Wenn eine Show vorbei ist, ist Netflix da, um die nächste vorzuschlagen.
In ihrem Geschäft verschafft das einen Wettbewerbsvorteil, da die Wahrscheinlichkeit, dass Benutzer ihre Abonnements kündigen, viel geringer ist. Diese äußerst erfolgreiche Anwendung von Data Science wurde hauptsächlich durch das gute Verständnis ihres Geschäfts und der Benutzer der App erreicht.
Die Zusammenfassung
Auf einer der diesjährigen Data Science-Konferenzen sagte ein Redner, der sich mit Kreditrisikovorhersagen beschäftigt:
Wenn Leute mich fragen, was im Grunde mein Job ist, antworte ich: Ich bringe Geschäftswerte, die auf Daten basieren.
Für mich ist dies eine der besten Definitionen von Data Science. Sie sollte sich nicht nur an ihren theoretischen Grundlagen, sondern vor allem an der Wirtschaft orientieren. Wenn Sie eine gute Anwendung für maschinelles Lernen erstellen möchten, müssen Sie darüber nachdenken, wie sich Benutzer in Ihrem System verhalten und was sie benötigen. So erreichen Sie Ihre Unternehmensziele erfolgreich.