
Business-Intelligence-Pipeline basierend auf AWS-Services – Fallstudie
Veröffentlicht: 2019-05-16In den letzten Jahren haben wir ein verstärktes Interesse an Big-Data-Analysen festgestellt. Führungskräfte, Manager und andere Geschäftsbeteiligte nutzen Business Intelligence (BI), um fundierte Entscheidungen zu treffen. Es ermöglicht ihnen, wichtige Informationen sofort zu analysieren und Entscheidungen nicht nur auf der Grundlage ihrer Intuition zu treffen, sondern auf dem, was sie aus dem tatsächlichen Verhalten ihrer Kunden lernen können.
Wenn Sie sich entscheiden, eine effektive und informative BI-Lösung zu erstellen, muss Ihr Entwicklungsteam als allererster Schritt die Architektur der Datenpipeline planen. Es gibt mehrere Cloud-basierte Tools, die zum Aufbau einer solchen Pipeline eingesetzt werden können, und es gibt keine Lösung, die für alle Unternehmen die beste wäre. Bevor Sie sich für eine bestimmte Option entscheiden, sollten Sie Ihren aktuellen Tech-Stack, die Preise der Tools und die Fähigkeiten Ihrer Entwickler berücksichtigen. In diesem Artikel zeige ich eine mit AWS-Tools erstellte Architektur , die erfolgreich als Teil der Timesheets-Anwendung bereitgestellt wurde.
Architekturübersicht
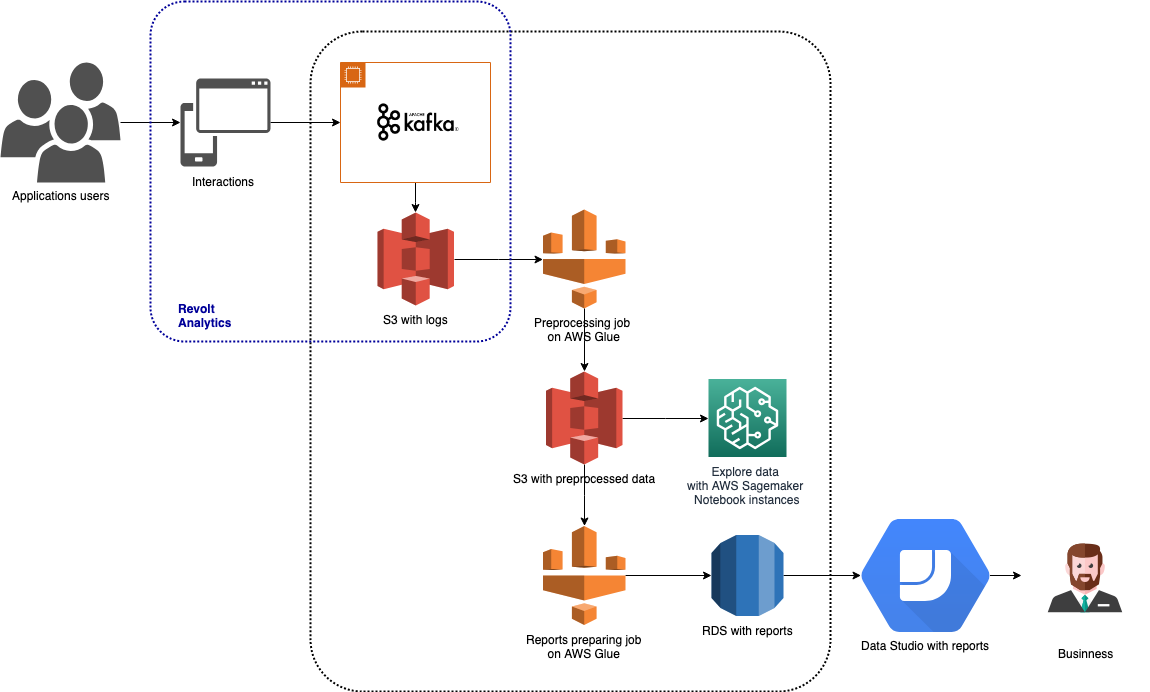
Timesheets ist ein Tool, um die Zeit der Mitarbeiter zu verfolgen und zu melden. Es kann über Web-, iOS-, Android- und Desktop-Anwendungen, einen in Hangouts und Slack integrierten Chatbot und Aktionen auf Google Assistant verwendet werden. Da viele Arten von Apps verfügbar sind, müssen auch viele verschiedene Daten verfolgt werden. Die Daten werden über Revolt Analytics gesammelt, in Amazon S3 gespeichert und mit AWS Glue und Amazon SageMaker verarbeitet. Die Ergebnisse der Analyse werden in Amazon RDS gespeichert und zur Erstellung visueller Berichte in Google Data Studio verwendet. Diese Architektur ist in der obigen Grafik dargestellt.
In den folgenden Abschnitten werde ich jedes der in dieser Architektur verwendeten Big-Data-Tools kurz beschreiben.
Revolt Analytics
Revolt Analytics ist ein von Miquido entwickeltes Tool zum Verfolgen und Analysieren von Daten aus Anwendungen aller Art. Um die Revolt-Implementierung in Client-Systemen zu vereinfachen, wurden iOS-, Android-, JavaScript-, Go-, Python- und Java-SDKs erstellt. Eines der Hauptmerkmale von Revolt ist seine Leistung: Alle Ereignisse werden in eine Warteschlange gestellt, gespeichert und in Paketen gesendet, wodurch sichergestellt wird, dass sie sowohl schnell als auch effizient zugestellt werden. Revolt gibt dem Anwendungsbesitzer die Möglichkeit, Benutzer zu identifizieren und ihr Verhalten in der App zu verfolgen. Dies ermöglicht es uns, wertschöpfende Modelle für maschinelles Lernen zu erstellen, wie z. B. vollständig personalisierte Empfehlungssysteme und Abwanderungsvorhersagemodelle, sowie Kundenprofilerstellung auf der Grundlage des Benutzerverhaltens. Revolt bietet auch eine Sessionization-Funktion. Das Wissen über Benutzerpfade und -verhalten in den Anwendungen kann Ihnen helfen, die Ziele und Bedürfnisse Ihrer Kunden zu verstehen.
Revolt kann auf jeder beliebigen Infrastruktur installiert werden. Dieser Ansatz gibt Ihnen die vollständige Kontrolle über Kosten und nachverfolgte Ereignisse. In dem in diesem Artikel vorgestellten Fall von Timesheets wurde es auf der AWS-Infrastruktur aufgebaut. Dank des vollen Zugriffs auf den Datenspeicher können Produktbesitzer problemlos Einblicke in ihre Anwendung erhalten und diese Daten in anderen Systemen verwenden.
Revolt SDKs werden zu jeder Komponente des Timesheets-Systems hinzugefügt, das aus Folgendem besteht:
- Android- und iOS-Apps (mit Flutter erstellt)
- Desktop-App (mit Electron erstellt)
- Web-App (geschrieben in React)
- Backend (geschrieben in Golang)
- Hangouts und Slack-Online-Chats
- Aktion auf Google Assistant
Revolt gibt Timesheets-Administratoren Wissen über Geräte (z. B. Gerätemarke, Modell) und Systeme (z. B. Betriebssystemversion, Sprache, Zeitzone), die von den Kunden der App verwendet werden. Darüber hinaus sendet es verschiedene benutzerdefinierte Ereignisse, die mit den Aktivitäten der Benutzer in den Apps verbunden sind. Folglich können die Administratoren das Benutzerverhalten analysieren und ihre Ziele und Erwartungen besser verstehen. Sie können auch die Benutzerfreundlichkeit der implementierten Funktionen überprüfen und beurteilen, ob diese Funktionen den Annahmen des Product Owners hinsichtlich ihrer Verwendung entsprechen.

AWS-Kleber
AWS Glue ist ein ETL-Service (Extrahieren, Transformieren und Laden), der bei der Vorbereitung von Daten für analytische Aufgaben hilft. Es führt ETL-Jobs in einer serverlosen Apache Spark-Umgebung aus. Normalerweise besteht es aus den folgenden drei Elementen:
- Crawler-Definition – Ein Crawler wird verwendet, um Daten in allen Arten von Repositories und Quellen zu scannen, zu klassifizieren, Schemainformationen daraus zu extrahieren und die Metadaten darüber im Datenkatalog zu speichern. Es kann beispielsweise Protokolle scannen, die in JSON-Dateien auf Amazon S3 gespeichert sind, und ihre Schemainformationen im Datenkatalog speichern.
- Jobskript – AWS Glue-Jobs wandeln Daten in das gewünschte Format um. AWS Glue kann automatisch ein Skript generieren, um Ihre Daten zu laden, zu bereinigen und umzuwandeln. Sie können auch Ihr eigenes in Python oder Scala geschriebenes Apache Spark-Skript bereitstellen, das die gewünschten Transformationen ausführt. Sie könnten Aufgaben wie den Umgang mit Nullwerten, Sessionisierung, Aggregationen usw. umfassen.
- Trigger – Crawler und Jobs können bei Bedarf ausgeführt oder so eingerichtet werden, dass sie starten, wenn ein bestimmter Trigger eintritt. Ein Auslöser kann ein zeitbasierter Zeitplan oder ein Ereignis sein (z. B. eine erfolgreiche Ausführung eines bestimmten Jobs). Diese Option gibt Ihnen die Möglichkeit, die Datenaktualität in Ihren Berichten mühelos zu verwalten.
In unserer Timesheets-Architektur stellt sich dieser Teil der Pipeline wie folgt dar:
- Ein zeitbasierter Trigger startet einen Vorverarbeitungsjob, der die Datenbereinigung durchführt, den Sitzungen entsprechende Ereignisprotokolle zuordnet und anfängliche Aggregationen berechnet. Die resultierenden Daten dieses Jobs werden auf AWS S3 gespeichert.
- Der zweite Trigger wird so eingerichtet, dass er nach der vollständigen und erfolgreichen Ausführung des Vorverarbeitungsjobs ausgeführt wird. Dieser Trigger startet einen Job, der Daten aufbereitet, die direkt in den von den Product Ownern analysierten Berichten verwendet werden.
- Die Ergebnisse des zweiten Jobs werden in einer AWS RDS-Datenbank gespeichert. Dadurch sind sie in Business-Intelligence-Tools wie Google Data Studio, PowerBI oder Tableau leicht zugänglich und nutzbar.
AWS SageMaker
Amazon SageMaker bietet Module zum Erstellen, Trainieren und Bereitstellen von Modellen für maschinelles Lernen.
Es ermöglicht das Training und Tuning von Modellen in jeder Größenordnung und ermöglicht die Verwendung von Hochleistungsalgorithmen, die von AWS bereitgestellt werden. Sie können jedoch auch benutzerdefinierte Algorithmen verwenden, nachdem Sie ein ordnungsgemäßes Docker-Image bereitgestellt haben. AWS SageMaker vereinfacht auch die Hyperparameter-Abstimmung mit konfigurierbaren Jobs, die Metriken für verschiedene Sätze von Modellparametern vergleichen.
In Timesheets helfen uns SageMaker Notebook-Instanzen dabei, die Daten zu untersuchen, ETL-Skripte zu testen und Prototypen von Visualisierungsdiagrammen vorzubereiten, die in einem BI-Tool zur Berichterstellung verwendet werden sollen. Diese Lösung unterstützt und verbessert die Zusammenarbeit von Data Scientists, da sie sicherstellt, dass sie in derselben Entwicklungsumgebung arbeiten. Darüber hinaus trägt dies dazu bei sicherzustellen, dass keine sensiblen Daten (die Teil der Ausgabe der Notebook-Zellen sein können) außerhalb der AWS-Infrastruktur gespeichert werden, da Notebooks nur in AWS S3-Buckets gespeichert werden und kein Git-Repository erforderlich ist, um die Arbeit zwischen Kollegen zu teilen .
Einpacken
Die Entscheidung, welche Big Data- und Machine Learning-Tools verwendet werden sollen, ist entscheidend beim Entwerfen einer Pipeline-Architektur für eine Business-Intelligence-Lösung. Diese Wahl kann erhebliche Auswirkungen auf die Systemfähigkeiten, Kosten und die Leichtigkeit haben, in der Zukunft neue Funktionen hinzuzufügen. AWS-Tools sind sicherlich eine Überlegung wert, aber Sie sollten eine Technologie auswählen, die zu Ihrem aktuellen Tech-Stack und den Fähigkeiten Ihres Entwicklungsteams passt.
Profitieren Sie von unserer Erfahrung im Bau zukunftsweisender Lösungen und kontaktieren Sie uns!