
Breadcrumb SEO, Python 3 und Oncrawl: Auf dem Weg zur Automatisierung!
Veröffentlicht: 2021-04-14Lassen Sie uns lernen, wie Sie mit OnCrawl und Python 3 automatisch eine Breadcrumb-basierte Segmentierung erstellen.
Was ist Segmentierung in Oncrawl?
Oncrawl verwendet Segmentierungen, um eine Reihe von Seiten in Gruppen aufzuteilen. Dies macht es sehr einfach, Daten aus Crawling-Berichten, Protokollanalysen und anderen Cross-Analyse-Berichten zu analysieren, die Crawling-Daten mit Google Analytics, Google Search Console, AT Internet, Adobe Analytics oder Majestic für Backlinks kombinieren.
Warum ist es wichtig, Segmentierungen zu erstellen?
Sobald Ihr Crawl abgeschlossen ist, ist das Erstellen einer benutzerdefinierten Segmentierung das Wichtigste, was Sie tun müssen. So können Sie Analysen aus der Perspektive lesen, die am besten zu Ihrer Seite und ihrer Struktur passt.
Es gibt viele Möglichkeiten, die Seiten Ihrer Website zu segmentieren, und es gibt keinen richtigen oder falschen Weg, dies zu tun. Beispielsweise ist es möglich, die Struktur Ihrer Website anhand der URL-Struktur zu verfolgen.
Zum Beispiel könnte diese Art von URL „ https://www.mydomain.com/news/canada/politics “ leicht wie folgt segmentiert werden:
- Eine Gruppe zum Isolieren der Homepage
- Eine Gruppe für alle Neuigkeiten
- Eine Untergruppe für das Kanada-Verzeichnis
- Eine Untergruppe für das Politikverzeichnis
Wie Sie sehen können, ist es möglich, bis zu 3 Tiefenebenen für Ihre Segmentierungen zu erstellen. Auf diese Weise können Sie sich in Ihrer SEO-Analyse auf bestimmte Gruppen oder Untergruppen konzentrieren, ohne die Segmentierung wechseln zu müssen.
Wie erstelle ich eine grundlegende Segmentierung?
Sie sollten wissen, dass Oncrawl sich selbst um die Erstellung der ersten Segmentierung kümmert. Dies basiert auf dem „ersten Pfad“ oder dem ersten Verzeichnis, das in den URLs gefunden wird.
Auf diese Weise steht Ihnen eine Analyse zur Verfügung, sobald Ihr Crawl abgeschlossen ist.
Es kann sein, dass diese Segmentierung nicht die Struktur Ihrer Website widerspiegelt oder dass Sie die Dinge aus einem anderen Blickwinkel analysieren möchten.
Sie erstellen also eine neue Segmentierung mit dem, was wir OQL nennen, was für Oncrawl Query Language steht. Es ist ein bisschen wie SQL, nur viel einfacher und intuitiver: 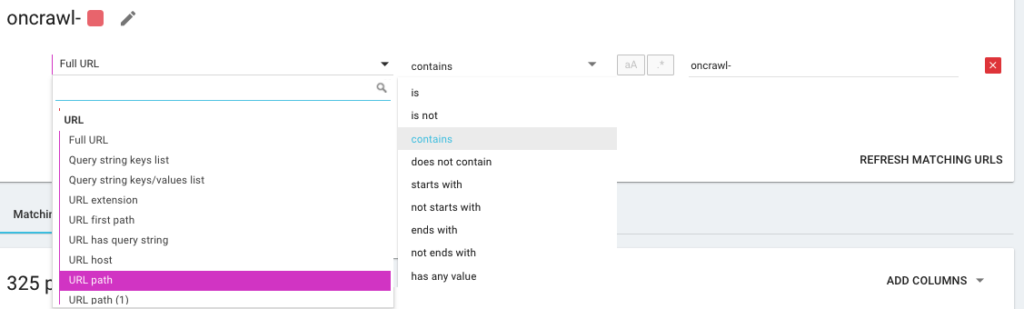
Es ist auch möglich, UND/ODER-Bedingungsoperatoren zu verwenden, um so genau wie möglich zu sein: 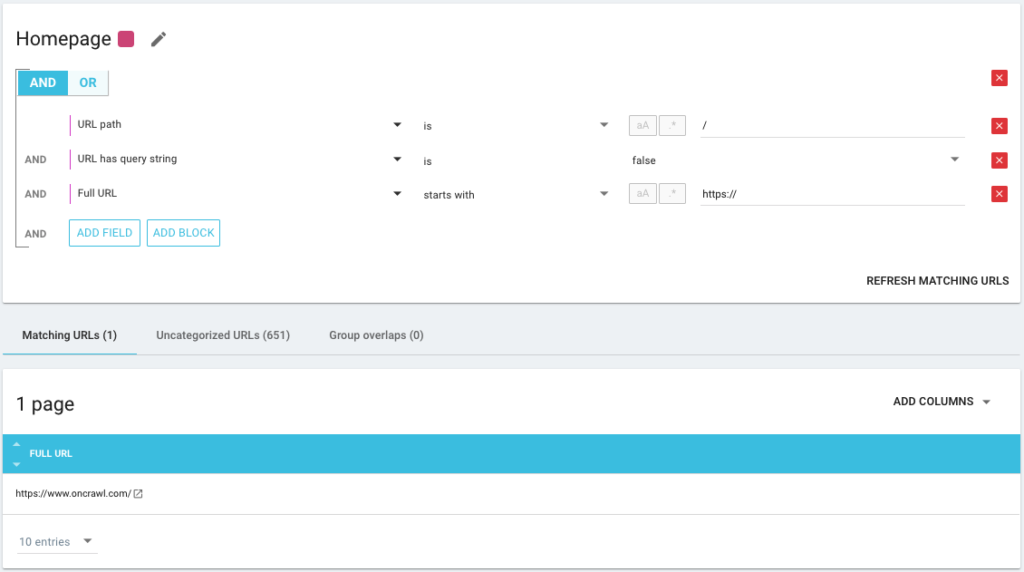
Segmentierung meiner Seiten mit verschiedenen Methoden
Verwendung anderer KPIs
Auf URLs basierende Segmentierungen sind gut, aber es wäre perfekt, wenn wir auch andere KPIs kombinieren könnten, z. B. die Gruppierung von URLs, die mit /car-rental/ beginnen und deren H1 den Ausdruck „ Autovermietungsagenturen “ hat, und einer anderen Gruppe, in der das H1 wäre „ Nutzungsvermieter “, geht das?
Ja es ist möglich! Bei der Erstellung Ihrer Segmentierungen stehen Ihnen alle KPIs zur Verfügung, die wir verwenden, und zwar nicht nur die aus dem Crawler, sondern auch aus Konnektoren. Dies macht die Erstellung von Segmentierungen sehr leistungsfähig und ermöglicht Ihnen völlig unterschiedliche Analysewinkel!
Ich liebe es zum Beispiel, dank des Google Search Console-Konnektors eine Segmentierung anhand der durchschnittlichen Position von URLs zu erstellen.
Auf diese Weise kann ich URLs tief in meiner Struktur, die noch funktionieren, oder URLs in der Nähe meiner Homepage, die auf Seite 2 von Google sind, leicht identifizieren.
Ich kann sehen, ob diese Seiten Duplicate Content haben, ein leeres Title-Tag, ob sie genügend Links erhalten … Ich kann auch sehen, wie sich der Googlebot auf diesen Seiten verhält. Ist die Crawl-Frequenz gut oder schlecht? Kurz gesagt, es hilft mir, Prioritäten zu setzen und Entscheidungen zu treffen, die sich wirklich auf meine SEO und meinen ROI auswirken.
Oncrawl-Daten³
 Mehr erfahren
Mehr erfahrenDatenaufnahme verwenden
Wenn Sie mit unserer Data Ingest-Funktion nicht vertraut sind, lade ich Sie ein, zuerst diesen Artikel zu diesem Thema zu lesen. Dies ist ein weiteres sehr leistungsstarkes Tool, mit dem Sie externe Datenquellen zu Oncrawl hinzufügen können.
Sie können beispielsweise Daten von SEMrush, Ahrefs, Babbar.tech… hinzufügen. Der Vorteil ist, dass Sie Ihre Seiten nach Metriken aus diesen Tools gruppieren und Ihre Analyse auf der Grundlage der Daten durchführen können, die Sie interessieren, auch wenn dies nicht der Fall ist nativ in Oncrawl.
Kürzlich habe ich bei einer globalen Hotelgruppe gearbeitet. Sie verwenden eine interne Bewertungsmethode, um festzustellen, ob die Hoteldatensätze korrekt ausgefüllt sind, ob sie Bilder, Videos, Inhalte usw. enthalten. Sie bestimmen einen Prozentsatz der Fertigstellung, den wir zur Kreuzanalyse der Crawl- und Protokolldateidaten verwendet haben.
Das Ergebnis zeigt uns, ob der Googlebot mehr Zeit auf Seiten verbringt, die korrekt gefüllt sind, ob einige Seiten mit einer Punktzahl von mehr als 90 % zu tief sind, nicht genügend Links erhalten … Je höher die Score, je mehr Besuche die Seiten erhalten, desto mehr werden sie von Google erkundet und desto besser ist ihre Position in den Google SERPs. Ein unaufhaltsames Argument, um Hoteliers zu ermutigen, ihre Hotelliste auszufüllen!
Erstellen Sie eine Segmentierung basierend auf dem SEO-Breadcrumb-Trail
Dies ist das Thema dieses Artikels, also kommen wir zum Kern der Sache. Es ist manchmal schwierig, die Seiten Ihrer Website zu segmentieren, wenn die Struktur der URLs Seiten nicht an ein bestimmtes Verzeichnis anhängt. Dies ist häufig bei E-Commerce-Websites der Fall, bei denen die Produktseiten alle an der Wurzel liegen. Aus der URL ist daher nicht ersichtlich, zu welcher Gruppe eine Seite gehört.
Um Seiten zusammenzufassen, müssen wir einen Weg finden, die Gruppe zu identifizieren, zu der sie gehören. Wir hatten daher die Idee, den Breadcrumb-SEO-Trail jeder URL abzurufen und sie basierend auf den Werten im Breadcrumb-SEO zu kategorisieren, indem wir die von Oncrawl angebotene Scraper-Funktion verwenden.
SEO Breadcrumb Scraping mit Oncrawl
Wie wir oben gesehen haben, werden wir eine Scraping-Regel einrichten, um den Breadcrumb-Trail abzurufen. Meistens ist es ziemlich einfach, weil wir die Informationen in einem div abrufen können, dann sind die Felder jeder Ebene drin
ul und li Listen: 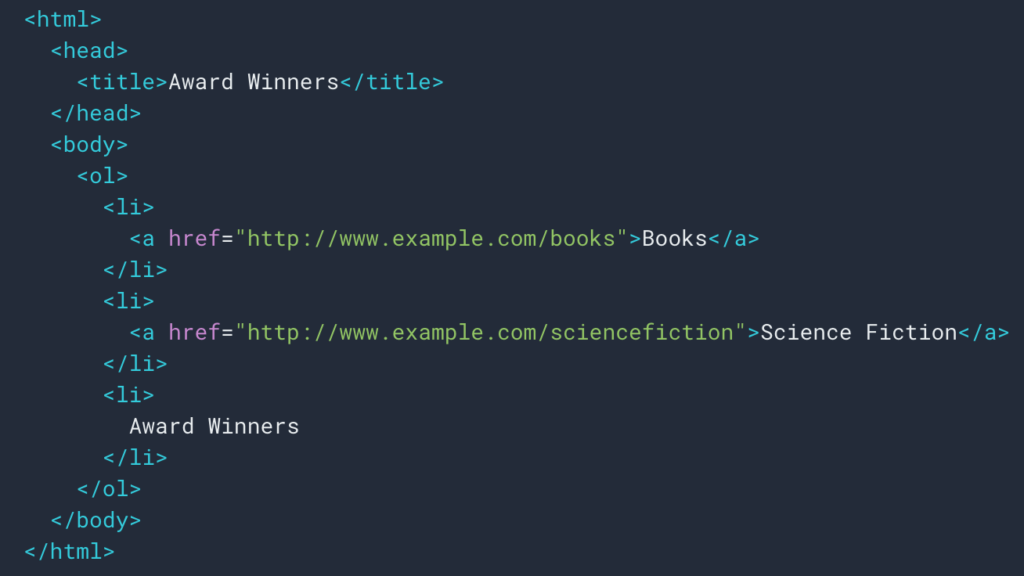
Manchmal können wir die Informationen auch dank des strukturierten Datentyps Breadcrumb leicht abrufen. So ist es einfach, den Wert des Felds „Name“ für jede Position abzurufen. 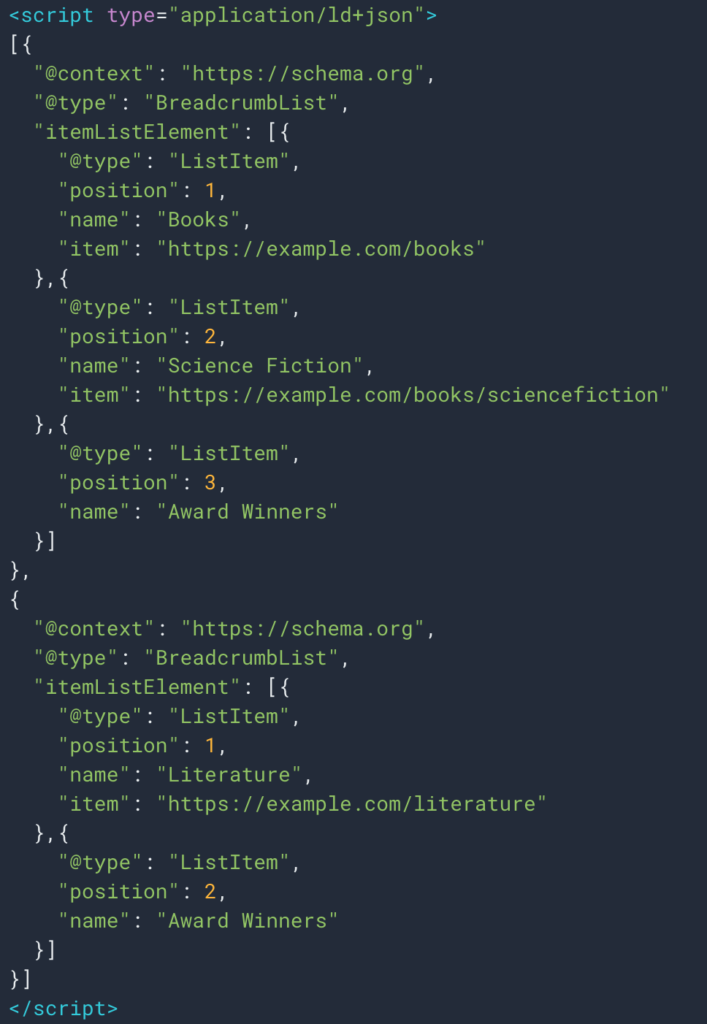
Hier ist ein Beispiel für eine Scraping-Regel, die ich verwende: 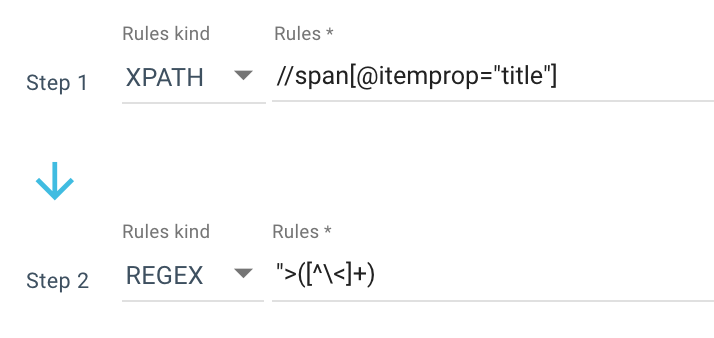
Oder diese Regel: //li[contains(@class, "current-menu-ancestor") or contains(@class, "current-menu-parent") or contains(@class, "current-menu-item")]/a/text()

Also erhalte ich alle span itemprop=”title” mit dem Xpath und verwende dann einen regulären Ausdruck, um alles nach “> zu extrahieren, das kein > Zeichen ist. Wenn Sie mehr über Regex erfahren möchten, empfehle ich Ihnen, diesen Artikel zu diesem Thema und unseren Cheat-Sheet zu Regex zu lesen.
Ich bekomme mehrere Werte wie diese als Ausgabe: 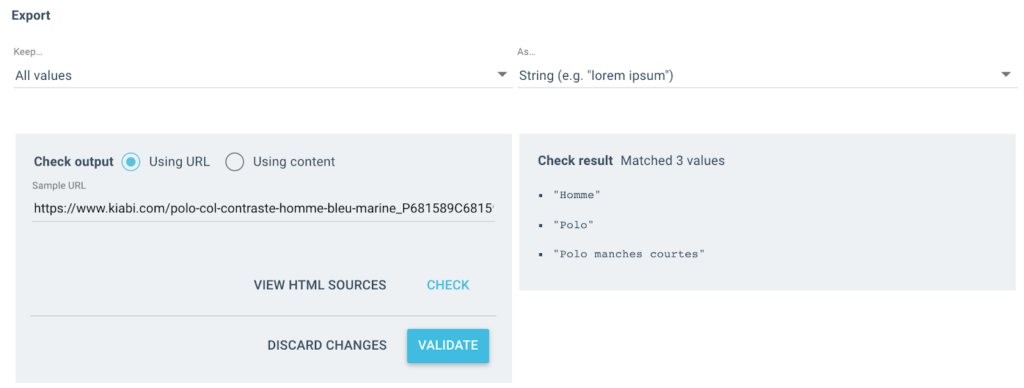
Für die getestete URL habe ich ein „Breadcrumb“-Feld mit 3 Werten:
- Mann
- Polo Hemd
- Kurzarm-Polo
json importieren
willkürlich importieren
Anfragen importieren
# Authent
# Zwei Möglichkeiten, mit x-oncrawl-token, als Sie Anfrage-Header vom Browser erhalten können
# oder mit API-Token hier: https://app.oncrawl.com/account/tokens
API_ACCESS_TOKEN = ' '
# Legen Sie die Crawl-ID dort fest, wo sich ein benutzerdefiniertes Breadcrumb-Feld befindet
KRIECHEN_
# Aktualisieren Sie die verbotenen Breadcrumb-Elemente, die Sie nicht in die Segmentierung aufnehmen möchten
FORBIDDEN_BREADCRUMB_ITEMS = ('Accueil',)
FORBIDDEN_BREADCRUMB_ITEMS_LIST = [
v.strip()
für v in FORBIDDEN_BREADCRUMB_ITEMS.split(',')
]
def random_color():
random_number = random.randint(0, 16777215)
hex_zahl = str(hex(zufallszahl))
hex_zahl = hex_zahl[2:].ljust(6, '0')
gib f'#{hex_number}' zurück
def value_to_group(Wert):
Rückkehr {
'Farbe': random_color(),
'Name': Wert,
'oql': {'or': [{'field': ['custom_Breadcrumb', 'equals', value]}]}
}
def walk_dict(Wörterbuch, Ebene=0):
ret = {
"icon": "Dashboard",
"übertragbar": falsch,
"name": "Breadcrumb"
}Jetzt, da die Regel definiert ist, kann ich meinen Crawl starten und Oncrawl ruft automatisch die Breadcrumb-Werte ab und ordnet sie jeder gecrawlten URL zu.
Automatisieren Sie die Erstellung der mehrstufigen Segmentierung mit Python
Jetzt, da ich alle SEO-Breadcrumb-Werte für jede URL habe, werden wir ein SEO -Automatisierungs-Python- Skript in einem Google Colab verwenden, um automatisch eine Segmentierung zu erstellen, die mit Oncrawl kompatibel ist.
Für das Skript selbst verwenden wir 3 Bibliotheken:
- json (Um unsere in Json geschriebene Segmentierung zu generieren)
- csv
- zufällig (Um hexadezimale Farbcodes für jede Gruppe zu generieren)
Sobald das Skript gestartet wird, kümmert es sich automatisch um die Erstellung der Segmentierung in Ihrem Projekt! 
Datenvorschau in den Analysen
Nachdem unsere Segmentierung erstellt wurde, ist es möglich, auf die verschiedenen Analysen mit einer segmentierten Ansicht basierend auf meinem Breadcrumb-Trail zuzugreifen. 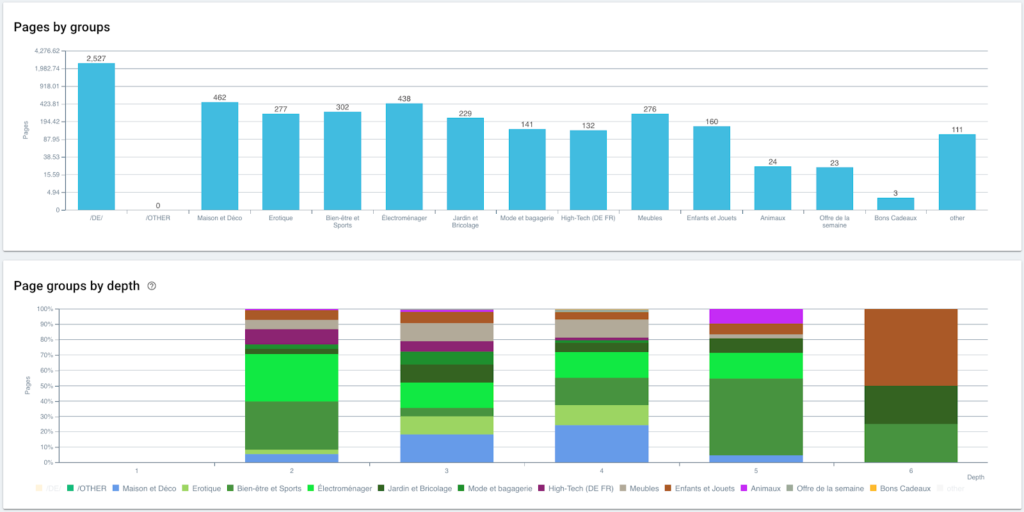
Verteilung der Seiten nach Gruppe und Tiefe
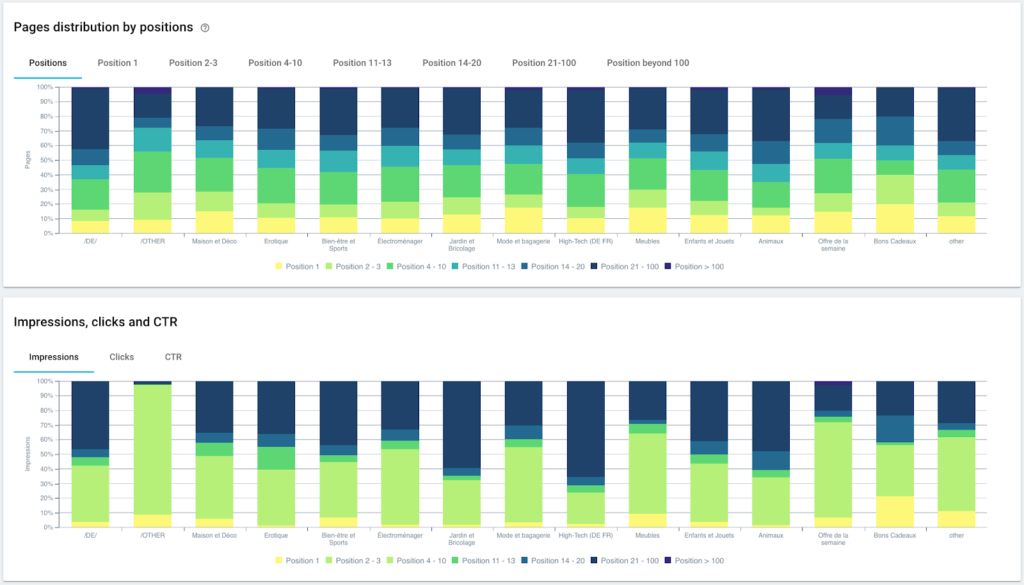
Ranking-Performance (GSC)
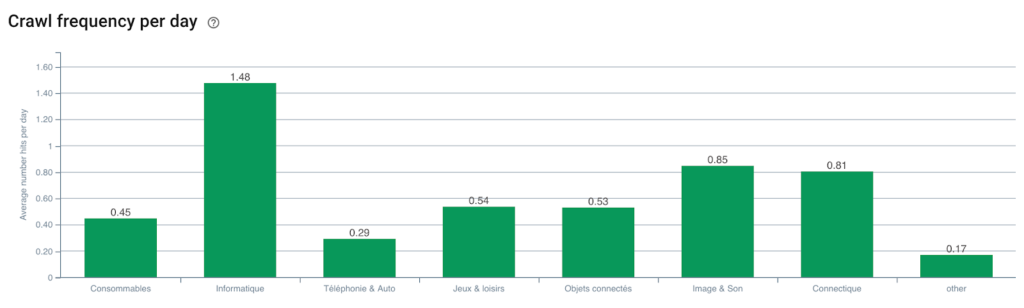
Googlebot-Crawling-Frequenz
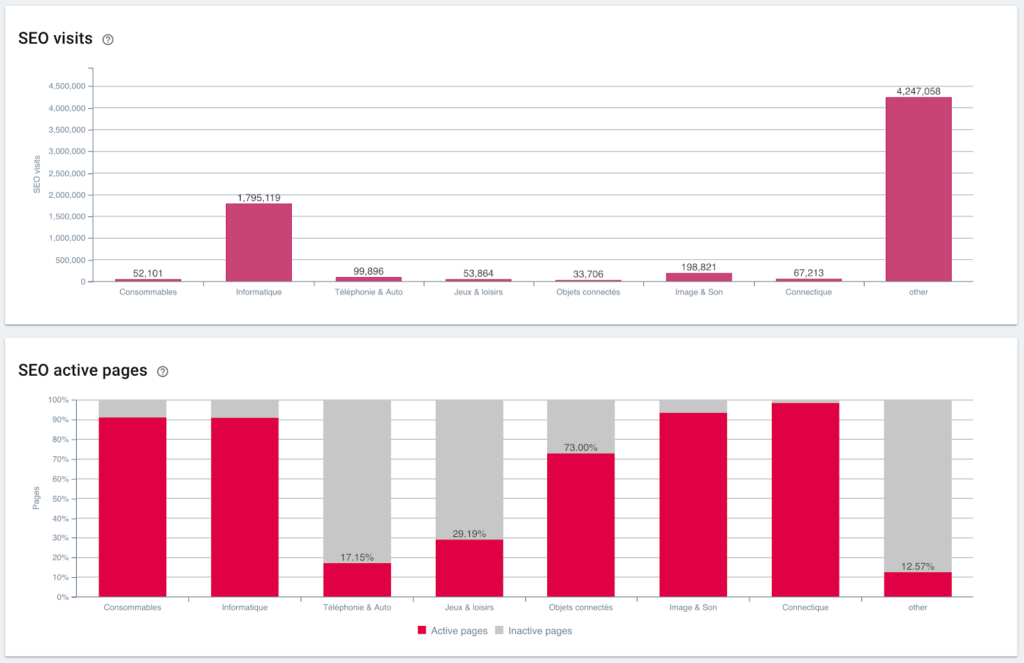
SEO-Besuche und aktives Seitenverhältnis
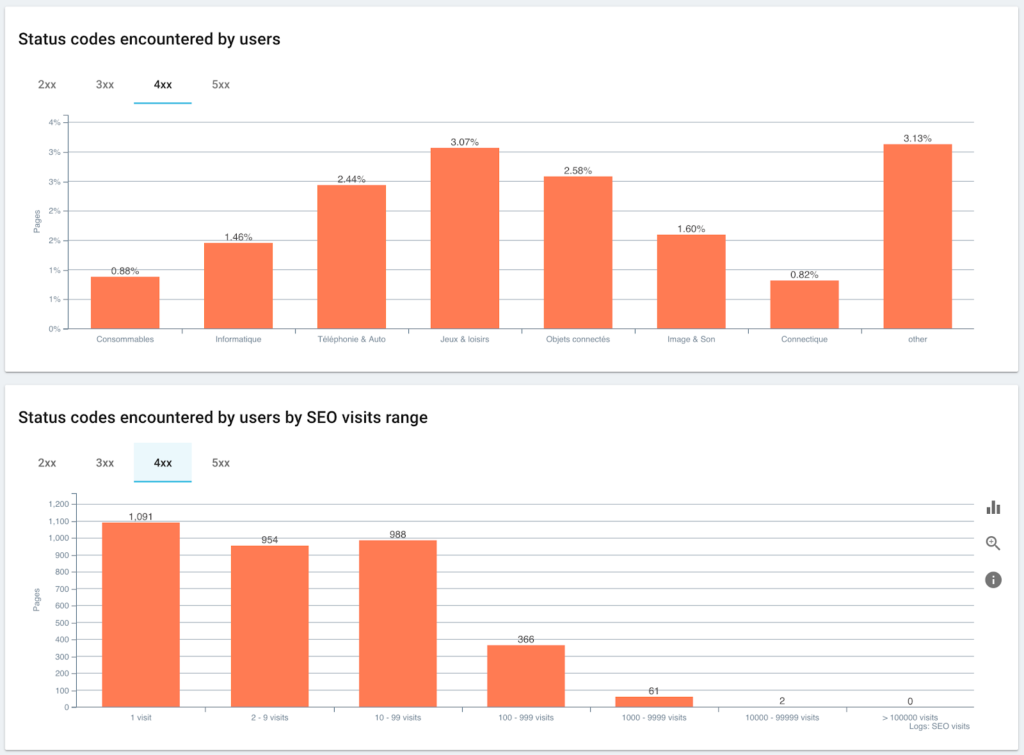
Von Benutzern angetroffene Statuscodes im Vergleich zu SEO-Sitzungen
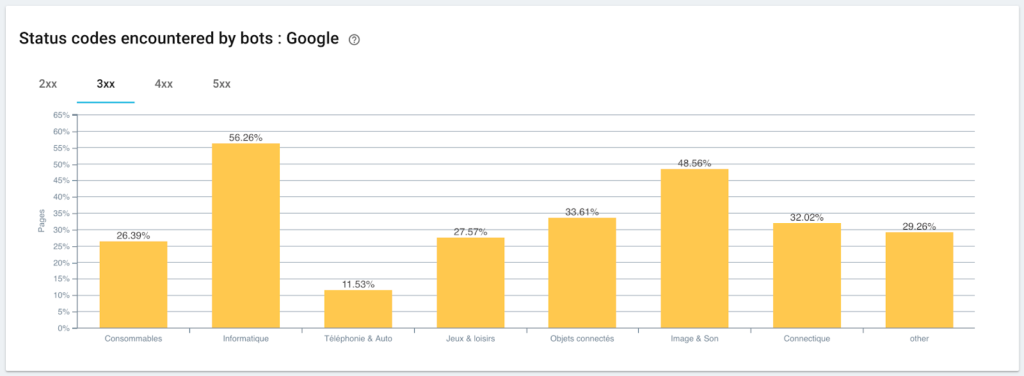
Überwachung von Statuscodes, auf die der Googlebot stößt
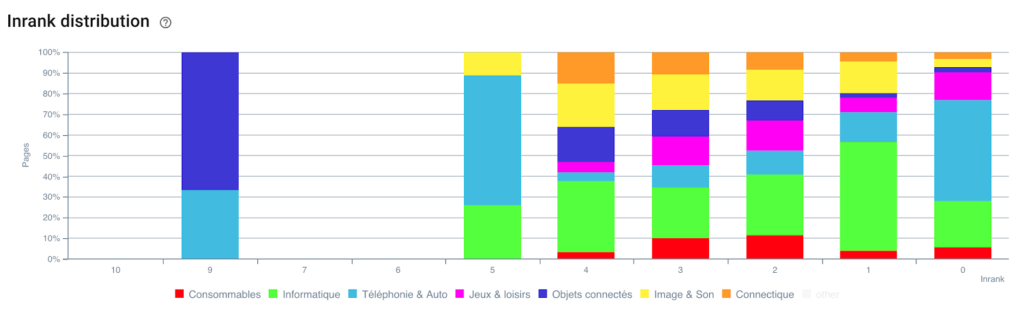
Verteilung des Inranks
Und hier sind wir, wir haben gerade dank eines Skripts mit Python und OnCrawl automatisch eine Segmentierung erstellt. Alle Seiten sind nun nach dem Brotkrümelpfad gruppiert und dies auf 3 Tiefenebenen: 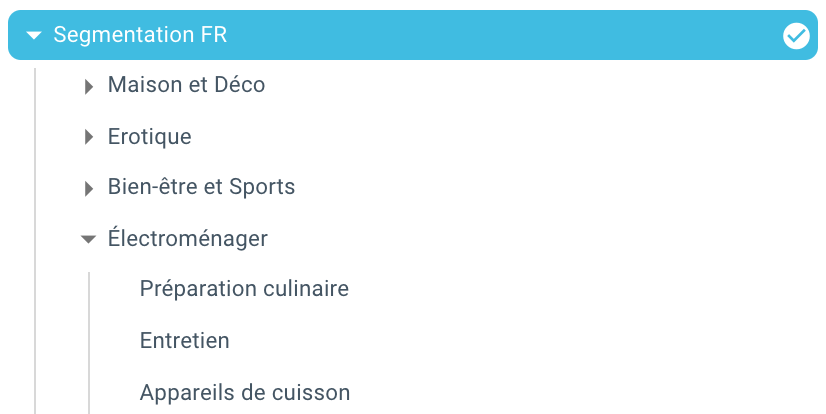
Der Vorteil ist, dass wir jetzt die verschiedenen KPIs (Crawl, Tiefe, interne Links, Crawl-Budget, SEO-Sitzungen, SEO-Besuche, Ranking-Leistungen, Ladezeit) für jede Gruppe und Untergruppe von Seiten überwachen können.
Die Zukunft von SEO mit Oncrawl
Sie denken wahrscheinlich, dass es großartig ist, diese sofort einsatzbereite Funktion zu haben, aber Sie haben nicht unbedingt die Zeit, alles zu tun. Die gute Nachricht ist, dass wir daran arbeiten, diese Funktion in naher Zukunft direkt zu integrieren.
Das bedeutet, dass Sie bald in der Lage sein werden, mit einem einfachen Klick automatisch eine Segmentierung für jedes verschrottete Feld oder Feld aus Data Ingest zu erstellen. Und das wird Ihnen eine Menge Zeit sparen, während Sie gleichzeitig unglaubliche Querschnitts-SEO-Analysen durchführen können.
Stellen Sie sich vor, Sie könnten beliebige Daten aus dem Quellcode Ihrer Seiten entfernen oder beliebige KPIs für jede URL integrieren. Die einzige Grenze ist Ihre Vorstellungskraft!
Sie können beispielsweise den Verkaufspreis von Produkten abrufen und sehen die Tiefe, den Inrank, die Backlinks, das Crawl-Budget nach dem Preis.
Aber wir können auch die Namen der Autoren Ihrer Medienartikel abrufen und sehen, wer am besten abschneidet, und die am besten funktionierenden Schreibmethoden anwenden.
Wir können die Rezensionen und Bewertungen Ihrer Produkte abrufen und sehen, ob die besten Produkte mit einem Minimum an Klicks zugänglich sind, genügend Links erhalten, Backlinks haben, vom Googlebot gut gecrawlt werden usw.
Wir können Ihre Geschäftsdaten wie Umsatz, Marge, Konversionsrate, Ihre Google Ads-Ausgaben integrieren.
Jetzt liegt es an Ihnen, sich vorzustellen, wie Sie die Daten mit Querverweisen versehen können, um Ihre Analyse zu erweitern und die richtigen SEO-Entscheidungen zu treffen.
Sie wollen die Autosegmentierung auf dem Breadcrumb Trail testen? Kontaktieren Sie uns über die Chatbox direkt aus Oncrawl heraus.
Viel Spaß beim Krabbeln!