
So fügen Sie Machine Learning-Lösungen mit AWS zu Ihrem Unternehmen hinzu
Veröffentlicht: 2020-05-13Maschinelles Lernen entwickelt sich ständig weiter und spielt eine große Rolle in der globalen Wirtschaft, da es eine schnelle und automatische Analyse großer Datenmengen ermöglicht.
Um Programmierern die Technologie des maschinellen Lernens noch näher zu bringen, bietet Amazon derzeit über 10 Dienste für maschinelles Lernen und künstliche Intelligenz auf seiner AWS-Plattform an. Mit diesen Services können Sie auf einfache Weise mit dem Erstellen von Modellen beginnen, die Ihr Unternehmen auf die nächste Stufe heben können.
Die meisten dieser Dienste werden vollständig verwaltet, was bedeutet, dass Sie keine Erfahrung mit maschinellem Lernen benötigen, um sie zu verwenden, da diese Tools vortrainierte Modelle für die Arbeit mit Daten nutzen. Abhängig von Ihrem Geschäftsproblem können Sie aus vortrainierten ML-Services in Bereichen wie Computer Vision, Verarbeitung natürlicher Sprache, Empfehlungen und Prognosen wählen. Die folgende Grafik zeigt einen Lösungsworkflow für maschinelles Lernen zusammen mit AWS-Tools, die Sie in jeder Phase verwenden können.
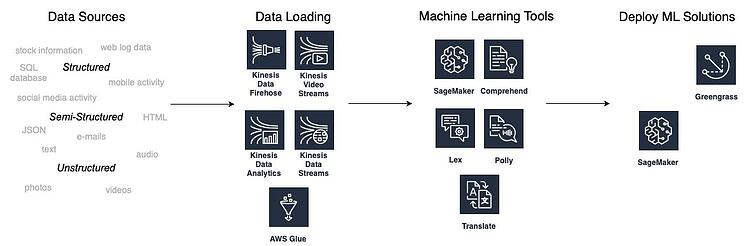
Wie man maschinelles Lernen mit AWS auf das Geschäft anwendet
Erstens: Sammeln der Daten
Das wichtigste Element beim Erstellen von ML-Lösungen sind Daten. Es gibt 3 Arten von Daten: strukturiert, halbstrukturiert und unstrukturiert.
- Die Elemente strukturierter Daten sind adressierbar und können in einer relationalen Datenbank gespeichert werden. Diese Art von Daten hat ein vordefiniertes Schema. Ein Beispiel für strukturierte Daten ist eine relationale Datenbank mit numerischen Daten und Zeichenfolgedaten (Text).
- Halbstrukturierte Datensätze befinden sich nicht in relationalen Datenbanken, haben aber dennoch einige vordefinierte Elemente (Schema), die ihre Analyse erleichtern. Beispiele für halbstrukturierte Datendateitypen sind XML, HTML, RDF oder JSON.
- Unstrukturierte Daten sind alles andere. Dieser Datentyp hat keine vordefinierte Struktur und wird normalerweise als Satz von Dateien gespeichert. Die beliebtesten Beispiele für unstrukturierte Daten sind Textdokumente, Fotos, Video- und Audiodateien sowie Anwendungsprotokolle.
Laden von Daten – was ist Kinesis?
Der AWS Kinesis -Service nimmt Daten auf, die kontinuierlich aus verschiedenen Quellen generiert werden können, z. B. Web- und Mobilanwendungen. Es ist ein Echtzeit-Daten-Streaming-Dienst, der sehr schnell Gigabytes an Daten erfassen kann. Kinesis bietet die folgenden Tools:
- Kinesis Video Streaming – ein Tool, mit dem Sie Videos von Geräten zu AWS streamen können
- Kinesis Data Streaming – ein Tool, mit dem Sie Daten wie IT-Protokolle, Website-Klicks oder Finanztransaktionen sammeln können
- Kinesis Data Firehose – ein Tool zum Laden von gestreamten Daten in Datenspeicher (z. B. S3, Redshift) oder Analysetools
- Kinesis Data Analytics – ein Tool, das gestreamte Daten in Echtzeit mit SQL oder Java verarbeitet
Laden von Daten – was ist Glue?
Ein weiterer AWS-Service, der beim Laden von Daten helfen kann, ist Glue , das von Apache Spark verwaltet wird . Es ist ein Tool zum Extrahieren, Transformieren und Laden (ETL), mit dem Daten vorbereitet werden können, bevor sie für Analysen verwendet werden. Glue kann sowohl mit strukturierten als auch mit halbstrukturierten Daten arbeiten.
Die Elemente von Glue sind Data Catalog, ETL-Engine und ein Scheduler. Der Glue Data Catalog ist der wichtigste Teil des Tools. Es speichert die Metadaten zu den angegebenen Daten, die automatisch von Crawlern entdeckt werden, die die Datenquellen durchsuchen und ihr Schema erkennen.
ETL-Engines können Python- und Scala-Code zur Verwendung im ETL-Prozess für nicht programmierende Benutzer generieren. Es kann auch Daten mit einem vom Benutzer bereitgestellten Code verarbeiten. Der Planer kann Jobs überwachen, Aufgaben ausführen und sie basierend auf bestimmten Ereignissen auslösen (z. B. jeden Montag zu einer bestimmten Zeit oder wenn eine andere Aufgabe abgeschlossen wird oder fehlschlägt).
Zweitens: Die Auswahl der richtigen Tools für maschinelles Lernen
Nachdem wir die benötigten Daten gesammelt haben, können wir mit dem Aufbau unserer ML-Lösungen beginnen. AWS bietet einige Machine Learning Tools an, die Daten verschiedener Art verarbeiten können.
Werfen wir nun einen Blick auf jedes dieser Tools und stellen ihre wichtigsten Einsatzmöglichkeiten in der Wirtschaft vor .
Was ist SageMaker?
SageMaker ist am nützlichsten für Entwickler von maschinellem Lernen und Datenwissenschaftler. Dieser Service ist eine Komplettlösung, die dabei hilft, maschinelle Lernmodelle mit minimalem Aufwand vom Konzept bis zur Produktion zu bringen. Amazon SageMaker verfügt über eine Vielzahl von Tools (Ground Truth, Notebooks, Experiments, Debugger, Model Monitor, Neo), die beim Kennzeichnen von Daten, Erstellen, Optimieren, Trainieren, Testen und Bereitstellen von Modellen helfen können.
Das manuelle Finden des richtigen Algorithmus für ein bestimmtes Problem erfordert oft stundenlanges Training und Tests. SageMaker verfügt über eine AutoPilot-Option, die 50 verschiedene vortrainierte ML-Modelle verwendet, um automatisch das beste ML-Modell für den jeweiligen Fall zu finden. Entwickler können diese Lösung verwenden, um schnell ein Basismodell zu finden.
Was ist Personalisieren?
Personalize ist ein Dienst für maschinelles Lernen, der beim Aufbau von Empfehlungssystemen hilft. Personalize kann Aktivitätsströme von Anwendungen verarbeiten, z. B. Klicks, Seitenaufrufe, Käufe, und daraus personalisierte Empfehlungen erstellen. Sie können auch zusätzliche Informationen über Ihre Benutzer verwenden, z. B. Alter oder geografischen Standort. Das Anzeigen von Empfehlungsergebnissen in Ihrer Anwendung kann mit kurzen API-Aufrufen vereinfacht werden. Die maschinelle Lerntechnologie in Personalize wurde für die jahrelange Nutzung durch Amazon.com verbessert.

Was ist Verstehen?
Comprehend ist ein Natural Language Processing (NLP)-Dienst, der maschinelles Lernen nutzt, um wertvolle Erkenntnisse aus unstrukturierten Textdaten zu extrahieren. Dieser Dienst wendet Stimmungsanalyse, Wortartextraktion und Tokenisierung an, um Schlüsselmerkmale des Textes zu erkennen. Verstehen kann hilfreich sein, um zu verstehen, wie positiv oder negativ ein bestimmter Text ist.
Comprehend hat ein zusätzliches Tool: Amazon Comprehend Medical, speziell für die Medizinbranche. Amazon Comprehend Medical kann medizinische Unterlagen (wie Krankenakten von Patienten, klinische Notizen) analysieren und Informationen über Medikamente, Dosierungen und Häufigkeiten extrahieren. Comprehend ist ein vollständig verwalteter Dienst.
Was ist Prognose?
Forecast verwendet maschinelles Lernen, um Zeitreihenvorhersagemodelle zu erstellen. Es kann historische Zeitreihendaten mit zusätzlichen Variablen (von denen Sie glauben, dass sie Prognosen beeinflussen können) kombinieren, um Vorhersagemodelle zu erstellen. Diese Amazon-Lösung gilt für die Vorhersage von Werten wie Aktienkursen oder der Produktnachfrage von Kunden. Forecast ist auch ein vollständig verwalteter Dienst und kann entsprechend den Geschäftsanforderungen skaliert werden.
Was ist Lex?
Lex verwendet automatische Spracherkennung (ASR), um Sprache in Text umzuwandeln, und Natural Language Understanding (NLU), um die Absicht des Textes zu erkennen. Diese Lösung ermöglicht es dem Benutzer, dialogorientierte Bots zu erstellen.
Beispielsweise können Sie Lex als Ersatz für den manuellen Kundensupport verwenden, der Kundenanfragen automatisch beantwortet. Amazon Lex verwendet dieselbe Deep-Learning-Technologie wie Amazon Alexa (Amazons virtuelle Assistenten-KI).
Was ist Polly?
Polly ist ein Cloud-Dienst, der Deep-Learning-Algorithmen verwendet, um Text in lebensechte Sprache umzuwandeln. Es unterstützt derzeit 60 männliche und weibliche Stimmen in 29 Sprachen, darunter Japanisch, Chinesisch, Koreanisch und Arabisch. Polly kann auch Zeit, Daten, Einheiten, Brüche und Abkürzungen verarbeiten. Diese Lösung ermöglicht es dem Benutzer, Anwendungen zu erstellen, die sprechen können.
Was ist ein Betrugsdetektor?
Fraud Detector ist ein AWS-Service, der dabei helfen kann, betrügerische Online-Aktivitäten wie Zahlungsbetrug oder gefälschte Konten zu identifizieren. Dieser Service wird vollständig verwaltet, sodass mit nur wenigen Klicks ein Betrugserkennungsmodell erstellt werden kann.
Was ist Textract?
Textract ist ein Dienst, der automatisch Daten aus gescannten Dokumenten lesen kann. Textract kann Millionen von Seiten in wenigen Stunden verarbeiten und bei der Automatisierung von Dokumenten-Workflows helfen. Dieser Service ist nützlich bei der Bearbeitung von Dokumenten wie Kreditanträgen oder medizinischen Unterlagen.
Was ist Übersetzen?
Translate ist ein AWS-Service für maschinelles Lernen, mit dem Textübersetzungen von Sprache zu Sprache durchgeführt werden können. Es verwendet Deep-Learning-Modelle, um im Vergleich zu herkömmlichen statistischen Algorithmen genauere und natürlicher klingende Übersetzungen zu liefern. Translate unterstützt 54 Sprachen (darunter zB Afrikaans, Bulgarisch, Estnisch) und 2.804 Sprachpaare.
Was ist Anerkennung?
Rekognition ist ein Computer-Vision-Dienst, der Objekte, Personen und Text aus Bildern und Filmen erkennen kann. Rekognition ist in der Lage, Gesichter zu identifizieren und zu vergleichen, sie zu analysieren und einige Gesichtsmerkmale wie Mund, Nase oder Augen zu identifizieren.
Rekognition verfügt über ein Modul zur automatischen Erkennung von Emotionen wie Glück, Traurigkeit oder Überraschung in Gesichtsbildern. Es kann auch eine Benutzergesichtsüberprüfung durchführen, die die Identität des Benutzers bestätigt, indem das Echtzeitbild mit dem gespeicherten Referenzbild verglichen wird.
Drittens: Bereitstellung von Lösungen für maschinelles Lernen
Die am weitesten verbreitete Methode zum Bereitstellen von Modellen ist der SageMaker-Dienst, den Sie auf zwei Arten verwenden können:
- Verwenden des SageMaker Hosting Service zum Einrichten von HTTPS-Endpunkten. In dieser Lösung senden Clientanwendungen Anforderungen an HTTPS-Endpunkte, um Vorhersagen von bereitgestellten Modellen zu erhalten. Um diese Lösung zu verwenden, müssen Sie sie mit Ihrem Docker-Image bereitstellen. Wenn Sie mehrere Modelle bereitstellen müssen, können Sie auch Endpunkte mit mehreren Modellen verwenden.
- Verwenden von SageMaker Batch Transform , das Ihnen hilft, Vorhersagen für einen gesamten Datensatz zu erhalten. Um ein Modell mithilfe von Batch Transform bereitzustellen, benötigen Sie einen S3-Bucket zum Speichern des Modells, der Datasets und der Vorhersagen.
Die Bereitstellungsalternative ist die Verwendung von AWS IoT Greengrass . Dieser Service erweitert AWS auf Geräte des Internets der Dinge (IoT). Mit diesem Dienst können Geräte Daten sammeln, filtern, verarbeiten und auch ohne Cloud-Verbindung Lambda-Funktionen, Docker-Container und Vorhersagen auf der Grundlage von ML-Modellen ausführen. Bei Verbindung mit dem Internet synchronisiert Greengrass alle Daten mit Cloud-Diensten.
Zusammenfassung
Wie Sie sehen können, bietet Amazon Web Service eine große Auswahl an Tools, mit denen Sie wirkungsvolle Lösungen für maschinelles Lernen für Ihr Unternehmen erstellen können. Mit ML-AWS-Tools können Sie Ihren Anwendungen neue Funktionen hinzufügen, z. B. Gesichtserkennung, Chatbots, Spracherkennung, Stimmungsanalyse von Social-Media-Inhalten. AWS fügt alle paar Monate neue ML-Services basierend auf neuen Anwendungsfällen hinzu, was es zu einer der am schnellsten wachsenden Plattformen für die Erstellung von KI-Lösungen macht.
Entwickeln Sie mit Miquido eine zukunftssichere Lösung für maschinelles Lernen!