
Konzepte und Schlüsselwörter automatisch aus einem Text extrahieren (Teil I: Die traditionellen Methoden)
Veröffentlicht: 2022-02-22In der Forschungs- und Entwicklungsabteilung von Oncrawl versuchen wir zunehmend, den semantischen Inhalt Ihrer Webseiten zu verbessern. Mithilfe von Machine-Learning-Modellen zur Verarbeitung natürlicher Sprache (NLP) können wir die Inhalte Ihrer Seiten detailliert vergleichen, automatische Zusammenfassungen erstellen, die Tags Ihrer Artikel ergänzen oder korrigieren, die Inhalte gemäß Ihren Google Search Console -Daten optimieren usw.
In einem früheren Artikel haben wir über das Extrahieren von Textinhalten aus HTML-Seiten gesprochen. Dieses Mal möchten wir über die automatische Extraktion von Schlüsselwörtern aus einem Text sprechen. Dieses Thema wird in zwei Beiträge aufgeteilt:
- Die erste behandelt den Kontext und die sogenannten „traditionellen“ Methoden mit mehreren konkreten Beispielen
- die zweite, die in Kürze folgen wird, wird sich mit eher semantischen Ansätzen auf der Grundlage von Transformatoren und Bewertungsmethoden befassen, um diese verschiedenen Methoden zu vergleichen
Kontext
Abgesehen von einem Titel oder einem Abstract gibt es keinen besseren Weg, den Inhalt eines Textes, einer wissenschaftlichen Arbeit oder einer Webseite zu identifizieren, als mit ein paar Schlüsselwörtern. Es ist eine einfache und sehr effektive Möglichkeit, das Thema und die Konzepte eines viel längeren Textes zu identifizieren. Es kann auch eine gute Möglichkeit sein, eine Reihe von Texten zu kategorisieren: Identifizieren Sie sie und gruppieren Sie sie nach Schlüsselwörtern. Websites, die wissenschaftliche Artikel anbieten, wie PubMed oder arxiv.org, können Kategorien und Empfehlungen basierend auf diesen Schlüsselwörtern anbieten.
Schlüsselwörter sind auch sehr nützlich für die Indizierung sehr großer Dokumente und für die Informationssuche, ein Fachgebiet, das Suchmaschinen gut bekannt ist
Das Fehlen von Schlüsselwörtern ist ein immer wiederkehrendes Problem bei der automatischen Kategorisierung von wissenschaftlichen Artikeln [1]: Viele Artikel sind nicht mit Schlüsselwörtern versehen. Daher müssen Methoden gefunden werden, um Konzepte und Schlüsselwörter automatisch aus einem Text zu extrahieren. Um die Relevanz eines automatisch extrahierten Satzes von Schlüsselwörtern zu bewerten, vergleichen Datensätze häufig die von einem Algorithmus extrahierten Schlüsselwörter mit Schlüsselwörtern, die von mehreren Menschen extrahiert wurden.
Wie Sie sich vorstellen können, ist dies ein gemeinsames Problem von Suchmaschinen bei der Kategorisierung von Webseiten. Ein besseres Verständnis der automatisierten Prozesse der Schlüsselwortextraktion ermöglicht es, besser zu verstehen, warum eine Webseite für dieses oder jenes Schlüsselwort positioniert ist. Es kann auch semantische Lücken aufdecken, die verhindern, dass es für das von Ihnen angestrebte Keyword gut rankt.
Es gibt offensichtlich mehrere Möglichkeiten, Schlüsselwörter aus einem Text oder Absatz zu extrahieren. In diesem ersten Beitrag beschreiben wir die sogenannten „klassischen“ Ansätze.
[Ebook] Data SEO: Das nächste große Abenteuer
 Lesen Sie das E-Book
Lesen Sie das E-BookEinschränkungen
Dennoch haben wir einige Einschränkungen und Voraussetzungen bei der Wahl eines Algorithmus:
- Die Methode muss in der Lage sein, Schlüsselwörter aus einem einzelnen Dokument zu extrahieren. Einige Methoden erfordern einen vollständigen Korpus, dh mehrere hundert oder sogar tausend Dokumente. Obwohl diese Methoden von Suchmaschinen verwendet werden können, sind sie für ein einzelnes Dokument nicht nützlich.
- Wir befinden uns in einem Fall von unüberwachtem maschinellem Lernen. Wir haben keinen Datensatz in Französisch, Englisch oder anderen Sprachen mit annotierten Daten zur Hand. Mit anderen Worten, wir haben nicht Tausende von Dokumenten mit bereits extrahierten Schlüsselwörtern.
- Die Methode muss unabhängig von der Domäne / dem lexikalischen Feld des Dokuments sein. Wir möchten in der Lage sein, Schlüsselwörter aus jeder Art von Dokument zu extrahieren: Nachrichtenartikel, Webseiten usw. Beachten Sie, dass einige Datensätze, die bereits Schlüsselwörter für jedes Dokument extrahiert haben, häufig domänenspezifische Medizin, Informatik usw. sind.
- Einige Methoden basieren auf POS-Tagging-Modellen, dh der Fähigkeit eines NLP-Modells, Wörter in einem Satz anhand ihres grammatikalischen Typs zu identifizieren: ein Verb, ein Substantiv, ein Bestimmungswort. Die Bestimmung der Wichtigkeit eines Schlüsselworts, das eher ein Substantiv als ein Determinator ist, ist eindeutig relevant. Je nach Sprache sind POS-Tagging-Modelle jedoch teilweise von sehr unterschiedlicher Qualität.
Über traditionelle Methoden
Wir unterscheiden zwischen den sogenannten „traditionellen“ Methoden und den neueren, die NLP – Natural Language Processing – Techniken wie Word Embeddings und Contextual Embeddings verwenden. Dieses Thema wird in einem zukünftigen Beitrag behandelt. Doch kehren wir zunächst zu den klassischen Ansätzen zurück, wir unterscheiden zwei davon:
- der statistische Ansatz
- der Graphenansatz
Der statistische Ansatz stützt sich hauptsächlich auf Worthäufigkeiten und deren gemeinsames Auftreten. Wir beginnen mit einfachen Hypothesen, um Heuristiken zu erstellen und wichtige Wörter zu extrahieren: ein sehr häufiges Wort, eine Reihe aufeinanderfolgender Wörter, die mehrmals vorkommen usw. Die graphbasierten Methoden erstellen einen Graphen, in dem jeder Knoten einem Wort oder einer Wortgruppe entsprechen kann Wörter oder Satz. Dann kann jeder Bogen die Wahrscheinlichkeit (oder Häufigkeit) darstellen, diese Wörter zusammen zu beobachten.
Hier sind ein paar Methoden:
- Statistikbasiert
- TF-IDF
- RECHEN
- YAKE
- Graphbasiert
- TextRank
- Themenrang
- SingleRank
Alle angeführten Beispiele verwenden Text von dieser Webseite: Jazz au Tresor : John Coltrane – Impressions Graz 1962.
Statistischer Ansatz
Wir stellen Ihnen die beiden Methoden Rake und Yake vor. Im SEO-Kontext haben Sie vielleicht schon von der TF-IDF-Methode gehört. Aber da es einen Korpus von Dokumenten erfordert, werden wir uns hier nicht damit befassen.
RECHEN
RAKE steht für Rapid Automatic Keyword Extraction. Es gibt mehrere Implementierungen dieser Methode in Python, einschließlich rake-nltk. Der Score jedes Keywords, das auch Keyphrase genannt wird, weil es mehrere Wörter enthält, basiert auf zwei Elementen: der Häufigkeit der Wörter und der Summe ihrer gemeinsamen Vorkommen. Die Zusammensetzung jeder Schlüsselphrase ist sehr einfach, sie besteht aus:
- schneide den Text in Sätze
- schneide jeden Satz in Schlüsselphrasen
Im folgenden Satz nehmen wir alle Wortgruppen getrennt durch Satzzeichen oder Stoppwörter:
Kurz zuvor leitete Coltrane ein Quintett mit Eric Dolphy an seiner Seite und Reggie Workman am Kontrabass.
Dies könnte zu folgenden Schlüsselwörtern führen:
"Just before", "Coltrane", "head", "quintet", "Eric Dolphy", "sides", "Reggie Workman", "double bass" .
Beachten Sie, dass Stoppwörter eine Reihe von sehr häufig vorkommenden Wörtern wie „ the “, „ in “, „and“ or „ it “ sind. Da klassische Methoden oft auf der Berechnung der Häufigkeit von Wörtern basieren, ist es wichtig, dass Sie Ihre Stoppwörter sorgfältig auswählen. Meistens möchten wir keine Wörter wie >"to" , "the" or "of" in unseren Keyphrase-Vorschlägen haben. Tatsächlich sind diese Stoppwörter keinem bestimmten lexikalischen Bereich zugeordnet und daher viel weniger relevant als beispielsweise die Wörter „ jazz “ oder „ saxophone “.

Sobald wir mehrere Kandidaten-Keyphrases isoliert haben, geben wir ihnen eine Punktzahl entsprechend der Häufigkeit der Wörter und der gemeinsamen Vorkommen. Je höher die Punktzahl, desto relevanter sollen die Keywords sein.
Versuchen wir es schnell mit dem Text aus dem Artikel über John Coltrane.
# Python-Snippet für Rake von rake_nltk importiert Rake # Angenommen, Sie haben den Artikel bereits in der 'Text'-Variablen rake = rake(stopwords=FRENCH_STOPWORDS, max_length=4) rake.extract_keywords_from_text(text) rake_keyphrases = rake.get_ranked_phrases_with_scores()[:TOP]
Hier sind die ersten 5 Schlüsselsätze:
„österreichisches öffentlich-rechtliches radio“, „lyrical peaks himmlischer“, „graz hat zwei eigenheiten“, „john coltrane tenorsaxophon“, „nur aufgenommene version“
Diese Methode hat einige Nachteile. Der erste ist die Bedeutung der Wahl von Stoppwörtern, da sie verwendet werden, um einen Satz in mögliche Schlüsselphrasen aufzuteilen. Die zweite ist, dass wenn die Schlüsselphrasen zu lang sind, sie aufgrund des gleichzeitigen Vorkommens der vorhandenen Wörter oft eine höhere Punktzahl haben. Um die Länge der Keyphrases zu begrenzen, haben wir die Methode mit max_length=4 gesetzt.
YAKE
YAKE steht für Yet Another Keyword Extractor. Diese Methode basiert auf dem folgenden Artikel YAKE! Schlüsselwortextraktion aus einzelnen Dokumenten unter Verwendung mehrerer lokaler Funktionen aus dem Jahr 2020. Es ist eine neuere Methode als RAKE, deren Autoren eine Python-Implementierung vorgeschlagen haben, die auf Github verfügbar ist.
Wir werden uns, wie bei RAKE, auf die Worthäufigkeit und das gemeinsame Vorkommen verlassen. Die Autoren werden auch einige interessante Heuristiken hinzufügen:
- Wir werden zwischen Wörtern in Kleinbuchstaben und Wörtern in Großbuchstaben unterscheiden (entweder den ersten Buchstaben oder das ganze Wort). Wir gehen hier davon aus, dass Wörter, die mit einem Großbuchstaben beginnen (außer am Satzanfang), relevanter sind als andere: Namen von Personen, Städten, Ländern, Marken. Das gleiche Prinzip gilt für alle großgeschriebenen Wörter.
- Die Punktzahl jedes Kandidatenschlüsselsatzes hängt von seiner Position im Text ab. Wenn die Kandidaten-Keyphrases am Anfang des Textes erscheinen, haben sie eine höhere Punktzahl, als wenn sie am Ende erscheinen. Beispielsweise erwähnen Nachrichtenartikel oft wichtige Konzepte am Anfang des Artikels.
# Python-Snippet für Yake aus Yake importieren Sie KeywordExtractor als Yake yake = Yake(lan="fr", stopwords=FRENCH_STOPWORDS) yake_keyphrases = yake.extract_keywords(text)
Wie RAKE, hier sind die Top 5 Ergebnisse:
„Treasure Jazz“, „John Coltrane“, „Impressionen Graz“, „Graz“, „Coltrane“
Trotz einiger Wiederholungen bestimmter Wörter in einigen Schlüsselsätzen scheint diese Methode recht interessant zu sein.
Graphischer Ansatz
Diese Art von Ansatz ist insofern nicht allzu weit vom statistischen Ansatz entfernt, als wir auch Wort-Kookkurenzen berechnen werden. Das Rank-Suffix, das einigen Methodennamen wie TextRank zugeordnet ist, basiert auf dem Prinzip des PageRank -Algorithmus, um die Popularität jeder Seite basierend auf ihren eingehenden und ausgehenden Links zu berechnen.
[Ebook] Automatisierung von SEO mit Oncrawl
 Lesen Sie das E-Book
Lesen Sie das E-BookTextRank
Dieser Algorithmus stammt aus dem Paper TextRank: Bringing Order into Texts aus dem Jahr 2004 und basiert auf den gleichen Prinzipien wie der PageRank- Algorithmus. Anstatt jedoch ein Diagramm mit Seiten und Links zu erstellen, erstellen wir ein Diagramm mit Wörtern. Jedes Wort wird entsprechend seinem gemeinsamen Vorkommen mit anderen Wörtern verknüpft.
Es gibt mehrere Implementierungen in Python. In diesem Artikel werde ich pytextrank vorstellen. Wir werden eine unserer Beschränkungen bezüglich POS-Tagging aufheben. Tatsächlich werden wir beim Erstellen des Diagramms nicht alle Wörter als Knoten einbeziehen. Es werden nur Verben und Substantive berücksichtigt. Wie frühere Methoden, die Stoppwörter verwenden, um irrelevante Kandidaten herauszufiltern, verwendet der TextRank-Algorithmus den grammatikalischen Worttyp.
Hier ist ein Beispiel für einen Teil des Diagramms, das vom Algo erstellt wird: 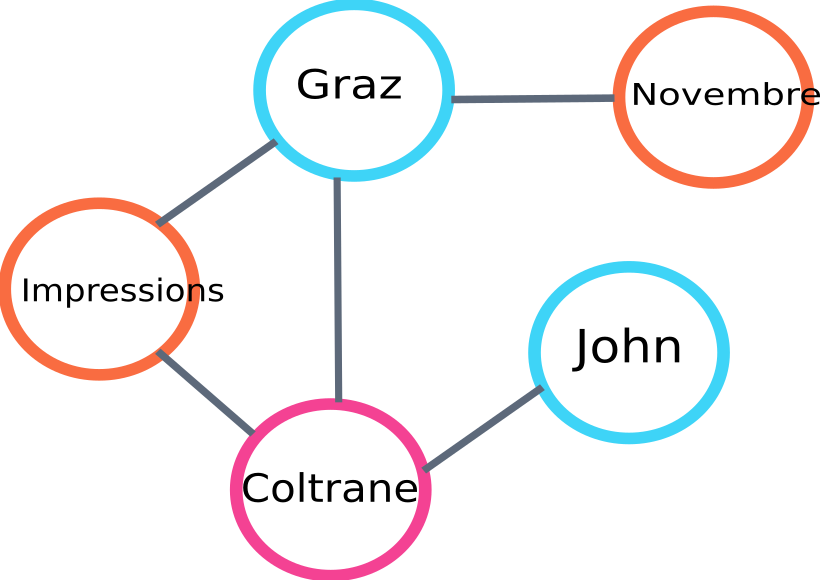
Beispiel für ein Text-Rank-Diagramm
Hier ist ein Beispiel für die Verwendung in Python. Beachten Sie, dass diese Implementierung den Pipeline-Mechanismus der spaCy-Bibliothek verwendet. Diese Bibliothek ist in der Lage, POS-Tagging durchzuführen.
# Python-Snippet für pytextrank
spacy importieren
pytextrank importieren
# Lade ein französisches Modell
nlp = spacy.load("fr_core_news_sm")
# pytextrank zur Pipe hinzufügen
nlp.add_pipe("textrank")
doc = nlp(text)
textrank_keyphrases = doc._.phrases
Hier sind die 5 besten Ergebnisse:
„Kopenhaag“, „November“, „Impressionen Graz“, „Graz“, „John Coltrane“
Zusätzlich zum Extrahieren von Schlüsselphrasen extrahiert TextRank auch Sätze. Dies kann sehr nützlich sein, um sogenannte „extraktive Zusammenfassungen“ zu erstellen – dieser Aspekt wird in diesem Artikel nicht behandelt.
Schlussfolgerungen
Von den drei hier getesteten Methoden scheinen uns die letzten beiden für das Thema des Textes ziemlich relevant zu sein. Um diese Ansätze besser vergleichen zu können, müssten wir diese unterschiedlichen Modelle natürlich an einer größeren Anzahl von Beispielen evaluieren. Es gibt tatsächlich Metriken, um die Relevanz dieser Keyword-Extraktionsmodelle zu messen.
Die von diesen sogenannten traditionellen Modellen erstellten Keyword-Listen bieten eine hervorragende Grundlage, um zu überprüfen, ob Ihre Seiten zielgerichtet sind. Darüber hinaus geben sie eine erste Annäherung, wie eine Suchmaschine den Inhalt verstehen und einordnen könnte.
Andererseits können auch andere Methoden, die vortrainierte NLP-Modelle wie BERT verwenden, verwendet werden, um Konzepte aus einem Dokument zu extrahieren. Im Gegensatz zum sogenannten klassischen Ansatz erlauben diese Methoden in der Regel eine bessere Erfassung der Semantik.
Die unterschiedlichen Auswertungsmethoden, kontextuellen Einbettungen und Transformer werden in einem zweiten Artikel zum Thema vorgestellt!
Hier ist die Liste der Schlüsselwörter, die aus diesem Artikel mit einer der drei genannten Methoden extrahiert wurden:
„Methoden“, „Keywords“, „Keyphrases“, „Text“, „extrahierte Keywords“, „Natural Language Processing“
Bibliographische Referenzen
- [1] Verbesserte automatische Schlüsselwortextraktion bei mehr sprachlichem Wissen, Anette Hulth, 2003
- [2] Automatische Schlüsselwortextraktion aus einzelnen Dokumenten, Stuart Rose et. al, 2010
- [3] YAKE! Schlüsselwortextraktion aus einzelnen Dokumenten unter Verwendung mehrerer lokaler Merkmale, Ricardo Campos et. Al, 2020
- [4] TextRank: Ordnung in Texte bringen, Rada Mihalcea et. al, 2004
Starten Sie Ihre kostenlose 14-Tage-Testversion
 Starten Sie Ihre Testversion
Starten Sie Ihre Testversion