
Authentizität, Dalle-2 & Midjourney und unsere Faszination von KI-generierten Bildern & Kunst
Veröffentlicht: 2022-08-04In diesem Artikel geht es um die Technologie hinter Plattformen wie Dalle-2 und Midjourney und warum die Entwickler von Open AI Ihnen möglicherweise Geld zahlen sollten – und Ihnen keine Gebühren in Rechnung stellen …
Immer mehr Leute im Internet bezeichnen Dalle-2 und Open AI als Betrug. Der Grund dafür ist, dass Dalle-2 nun plötzlich zu einem monetarisierten Dienst wird, bei dem Sie Credits kaufen müssen, wenn Sie die Plattform über das Beta-Limit hinaus nutzen.
DALLE 2 ist nur eine von vielen neuen Plattformen, die Ihnen Zugang zu KI-generierten Inhalten bieten und behaupten, dass Sie diese für kommerzielle Zwecke nutzen können. Andere Plattformen sind Midjourney, Jasper Art, Nightcafe, Starry AI und Craiyon. Wir werden uns in diesem Blogbeitrag auf Dalle 2 konzentrieren, aber sie sind fast identisch, wenn es um die rechtlichen Herausforderungen und Probleme geht.
Betrug ist unserer Meinung nach eine ziemlich harte Aussage, aber es gibt ein offensichtliches Problem darin, Daten zu verwenden, die andere Personen erstellt haben (Fotos, Videos, Anmerkungen, Personen auf den Bildern usw.) und dann damit zu beginnen, sie an dieselben Personen zurückzuverkaufen.
Dieses Problem wird von vielen von uns vielleicht übersehen, weil wir einfach von der neuen Technologie fasziniert sind. Etwas, das absolut verständlich ist.
Obwohl DALL-E 2 letztendlich nur eine fortschrittliche Mustererkennungsmaschine ist, ist seine Ausgabe nicht neutral und die Muster kommen nicht aus der frischen Luft.
Sie basieren auf Tonnen von Daten, bei denen mehrere rechtliche Fragen zu stellen sind. Fragen, die für Sie als potentieller Nutzer der von Ihnen generierten Bilder wichtig sind.
 Bild erstellt von DALLE-2
Bild erstellt von DALLE-2
KI-Modelle sind nicht mit Menschen zu vergleichen
Sie sollten damit beginnen, diesen brillanten Artikel in Engadget zu lesen, bevor Sie anfangen, DALL-E 2-Bilder für kommerzielle Zwecke zu verwenden.
Im Engadget-Artikel weisen sie auf eine andere sehr wichtige Sache hin. Nämlich die Tatsache, dass DALL-E 2 und OpenAI NICHT ihr eigenes Recht aufgeben, Bilder zu kommerzialisieren, die Benutzer mit DALL-E erstellen. Das bedeutet im Grunde, dass Sie Bilder generieren können, die sie dann kommerziell an andere verkaufen.
Dies zeigt, dass die Absichten ganz anders sind als die manchmal verwendete Analogie, wo DALLE-2-Promoter es mit einem Studenten vergleichen, der die Arbeit eines etablierten Autors liest. In diesem Beispiel kann der Schüler die Stile und Muster des Autors lernen und diese später in anderen Kontexten anwendbar finden und sie dort wiederverwenden.
Hier geht es jedoch nicht um ein menschliches Gehirn, das kreatives Gedächtnis nutzt, um neue kreative Werke zu schaffen. Hier geht es um eine Mustererkennungsmaschine, die Trainingsdaten wiederverwendet und in einigen Fällen in Bildern reproduziert, die dann verwendet oder sogar kommerziell verkauft werden. Es sind einfach zwei verschiedene Welten – sowohl im übertragenen als auch im wörtlichen Sinne.
 Echtes Foto aus der realen Welt
Echtes Foto aus der realen Welt
Das Authentizitätsversprechen von JumpStory
Dieser Artikel richtet sich an Personen, die auf einer tieferen Ebene verstehen möchten, wie diese neue KI-Bilderzeugungstechnologie funktioniert. Aber bevor wir anfangen, nur ein paar Worte darüber, warum JumpStory derzeit keine ähnliche Maschine baut.
Diese Frage wurde uns natürlich mehrfach gestellt. Nicht zuletzt, wenn man bedenkt, dass wir in unserem Unternehmen bereits KI einsetzen und Zugriff auf Millionen authentischer Bilder haben.
Allerdings ist das für uns keine technologische Diskussion, sondern eine ethische. Eine Diskussion, die zu unserem Echtheitsversprechen geführt hat.
Wir sind grundsätzlich gegen eine Zukunft, in der KI-generierte Bilder eher zur Norm als zur Ausnahme werden. Nennen Sie uns altmodisch, aber wir glauben, dass die WIRKLICHE Welt schön ist.
Wir sind stolz darauf, dass unsere Fotos und Videos echte Menschen in verschiedenen Formen und Größen darstellen. Wir sind nicht gegen den Einsatz von KI, aber wir glauben nicht, dass sie dazu verwendet werden sollte, falsche Menschen oder Realitäten zu erzeugen.
Technologien wie synthetische Medien und DALL-E 2 mögen an der Oberfläche faszinierend sein, aber sie stellen auch ein echtes Risiko dar. Sie riskieren, die Grenzen zwischen echt und falsch zu verwischen, was eine grundlegende Bedrohung für das Vertrauen zwischen Menschen darstellt.
Aus diesem Grund verwendet JumpStory keine künstliche Intelligenz, um gefälschte Bilder zu generieren, sondern verwendet KI, um zu identifizieren, welche Bilder original, authentisch und – natürlich – legal für kommerzielle Zwecke sind.

Dies sind die Bilder, die Sie bei der Nutzung unseres Dienstes finden, und wir haben unseren Ansatz „Authentic Intelligence“ genannt.
Verstehen, wie KI-Bilder generiert werden
Genug über JumpStory und die rechtlichen Probleme mit DALL-E 2 für jetzt. Schauen wir uns an, wie KI-Bilder auf Plattformen wie DALLE-2, Imagen, Crayion (ehemals Dall-E Mini), Midjourney usw. generiert werden … Am Beispiel von DALLE-2 als dem derzeit am meisten gehypten Beispiel.
Zunächst kann DALLE-2 verschiedene Arten von Aufgaben ausführen, aber wir werden uns in diesem Blogpost auf die Aufgabe der Bilderzeugung konzentrieren.
Wie es funktioniert ist, dass ein Text-Prompt in einen Text-Encoder eingegeben wird. Dieser Codierer ist darauf trainiert, die Eingabeaufforderung einem Repräsentationsraum zuzuordnen. Anschließend bildet ein sogenanntes Prior-Modell den codierten Text auf eine entsprechende Bildcodierung ab, die die semantischen Informationen des Textcodierungs-Prompts erfasst.
(Wenn das jetzt schon ein bisschen geeky wird, tut es mir sehr leid, aber es wird noch schlimmer )
Der letzte Schritt für den Bildcodierer besteht darin, ein Bild zu generieren, das die semantischen Informationen visualisiert, die der Codierer erhalten hat. Das sind die Grundlagen von Maschinen wie Open AI.
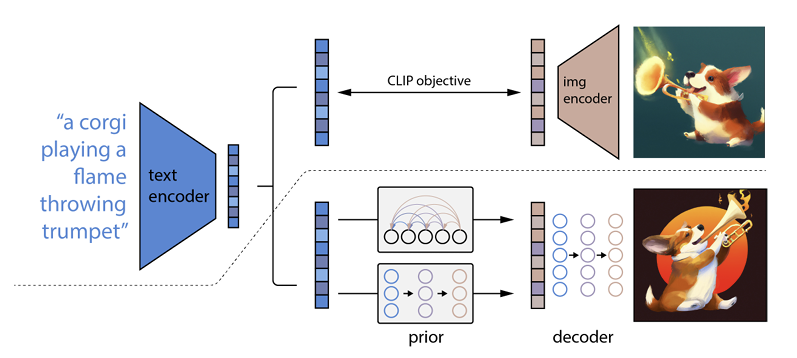
Die Beziehung zwischen Text und Bild
DALL-E 2 und ähnliche Technologien werden oft als Text-zu-Bild-Generatoren bezeichnet. Der Grund ist ihre Fähigkeit, eine Texteingabe zu empfangen und eine Bildausgabe zu liefern.
Um Ihnen ein Beispiel zu geben: „Ein Astronaut auf einem Pferd im Stil von Andy Warhol:

Quelle: DALLE-2
Was hier passiert, basiert auf dem CLIP-Modell von Open AI. CLIP steht für „Contrastive Language-Image Pre-training“ und ist ein sehr komplexes Modell, das mit Millionen von Bildern und Bildunterschriften trainiert wurde.
Was CLIP besonders gut kann, ist zu verstehen, wie sehr sich ein bestimmter Text auf ein bestimmtes Bild bezieht. Der Schlüssel liegt hier nicht in der Bildunterschrift, sondern in welcher Beziehung eine bestimmte Bildunterschrift zu einem bestimmten Bild steht.
Diese Art von Technologie wird als „kontrastiv“ bezeichnet, und CLIP ist in der Lage, Semantik aus natürlicher Sprache zu lernen. CLIP hat dies durch einen Prozess gelernt, dessen Ziel es ist (unter Bezugnahme auf die technologische Dokumentation): „gleichzeitig die Kosinusähnlichkeit zwischen Nkorrekt codierten Bild-/Beschriftungspaaren zu maximieren und die Kosinusähnlichkeit zwischen N 2 – N falsch codierten Bildern zu minimieren /Beschriftungspaare.“
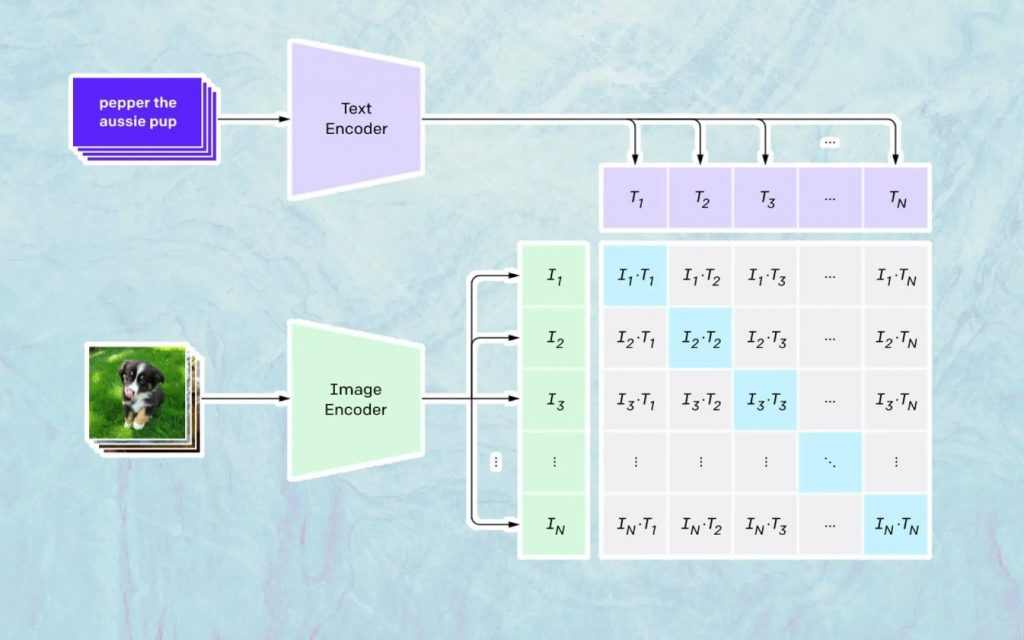
Generieren der Bilder
Wie oben beschrieben lernt das CLIP-Modell einen Repräsentationsraum, in dem es bestimmen kann, wie die Kodierungen von Bildern und Texten zusammenhängen.
Die nächste Aufgabe besteht darin, diesen Raum zum Generieren von Bildern zu verwenden. Zu diesem Zweck hat Open AI ein weiteres Modell namens GLIDE entwickelt, das in der Lage ist, den Input von CLIP zu verwenden und – unter Verwendung eines Diffusionsmodells – die Bilderzeugung durchzuführen.
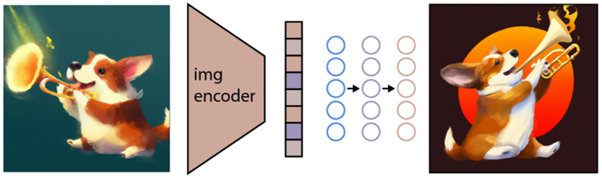
Um kurz zu erklären, was ein Diffusionsmodell ist, ist es im Grunde ein Modell, das lernt, Daten zu generieren, indem es einen allmählichen Rauschprozess umkehrt. Entschuldigen Sie, dass dies jetzt sehr technisch wird, um eine Beschreibung aus der Open AI-Dokumentation zu zitieren:
„Der Rauschprozess wird als parametrisierte Markov-Kette betrachtet, die einem Bild allmählich Rauschen hinzufügt, um es zu verfälschen, was schließlich (asymptotisch) zu reinem Gaußschen Rauschen führt. Das Diffusionsmodell lernt, entlang dieser Kette rückwärts zu navigieren, indem es das Rauschen schrittweise über eine Reihe von Zeitschritten entfernt, um diesen Prozess umzukehren.“

Wenn Sie noch tiefer in die Technologie einsteigen möchten, empfehlen wir die Lektüre dieses hervorragenden Artikels von Ryan O'Connor.