
So beantworten Sie komplexe Datenfragen mit Oncrawl-Daten außerhalb von Oncrawl
Veröffentlicht: 2022-01-04Einer der Vorteile von Oncrawl für Unternehmens-SEO ist der volle Zugriff auf Ihre Rohdaten. Unabhängig davon, ob Sie Ihre SEO-Daten mit einem BI- oder einem Data-Science-Workflow verbinden, Ihre eigenen Analysen durchführen oder innerhalb der Datensicherheitsrichtlinien für Ihr Unternehmen arbeiten, rohe SEO- und Website-Audit-Daten können vielen Zwecken dienen.
Heute schauen wir uns an, wie man Oncrawl-Daten verwendet, um komplexe Datenfragen zu beantworten.
Was ist eine komplexe Datenfrage?
Komplexe Datenfragen sind Fragen, die nicht durch eine einfache Datenbanksuche beantwortet werden können, sondern eine Datenverarbeitung erfordern, um die Antwort zu erhalten.
Hier sind einige gängige Beispiele für „komplexe“ Datenfragen, die SEOs häufig haben:
- Erstellen einer Liste aller Links, die auf Seiten verweisen, die auf andere Seiten mit einem 404-Status weiterleiten
- Erstellen einer Liste aller Links und ihrer Ankertexte, die auf Seiten in einer Segmentierung basierend auf Nicht-URL-Metriken verweisen
So beantworten Sie komplexe Datenfragen in Oncrawl
Die Datenstruktur von Oncrawl ist so aufgebaut, dass fast alle Websites nahezu in Echtzeit nach Daten suchen können. Dabei werden verschiedene Arten von Daten in unterschiedlichen Datensätzen gespeichert, um sicherzustellen, dass die Suchzeiten in der Schnittstelle so gering wie möglich gehalten werden. Beispielsweise speichern wir alle mit URLs verbundenen Daten in einem Datensatz: Antwortcode, Anzahl der ausgehenden Links, Art der vorhandenen strukturierten Daten, Anzahl der Wörter, Anzahl der organischen Besuche… Und wir speichern alle Daten im Zusammenhang mit Links in einem separaten Datensatz: Linkziel, Linkursprung, Ankertext…
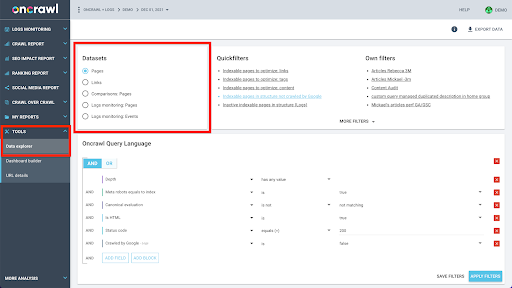
Das Zusammenführen dieser Datensätze ist rechnerisch komplex und wird in der Benutzeroberfläche der Oncrawl-Anwendung nicht immer unterstützt. Wenn Sie daran interessiert sind, etwas nachzuschlagen, was das Filtern eines Datensatzes erfordert, um etwas in einem anderen nachzuschlagen, empfehlen wir, die Rohdaten selbst zu bearbeiten.
Da Ihnen alle Oncrawl-Daten zur Verfügung stehen, gibt es viele Möglichkeiten, Datensätze zusammenzuführen und komplexe Abfragen auszudrücken.
In diesem Artikel betrachten wir eine davon mit Google Cloud und BigQuery, die für sehr große Datasets geeignet ist, wie sie viele unserer Kunden bei der Untersuchung von Daten für Websites mit vielen Seiten antreffen.
Was du brauchen wirst
Um der Methode zu folgen, die wir in diesem Artikel besprechen, benötigen Sie Zugriff auf die folgenden Tools:
- Oncrawl
- Die API von Oncrawl mit dem Big Data Export
- Google Cloud-Speicher
- BigQuery
- Ein Python-Skript zum Übertragen von Daten von Oncrawl nach BigQuery (Wir werden dies während des Artikels erstellen.)
Bevor Sie beginnen, benötigen Sie Zugriff auf einen abgeschlossenen Crawling-Bericht in Oncrawl.
So nutzen Sie Oncrawl-Daten in Google BigQuery
Der Plan für den heutigen Artikel sieht wie folgt aus:
- Zuerst stellen wir sicher, dass Google Cloud Storage für den Empfang von Daten von Oncrawl eingerichtet ist.
- Als Nächstes verwenden wir ein Python-Skript, um die Big Data-Exporte von Oncrawl auszuführen, um die Daten aus einem bestimmten Crawl in einen Google Cloud Storage-Bucket zu exportieren. Wir exportieren zwei Datensätze: Seiten und Links.
- Wenn dies erledigt ist, erstellen wir einen Datensatz in Google BigQuery. Anschließend erstellen wir aus jedem der beiden Exporte innerhalb des BigQuery-Datasets eine Tabelle.
- Schließlich werden wir mit der Abfrage der einzelnen Datensätze experimentieren und dann beide Datensätze zusammen, um die Antwort auf eine komplexe Frage zu finden.
Einrichtung in Google Cloud zum Empfangen von Oncrawl-Daten
Um diesen Leitfaden in einer dedizierten Sandbox-Umgebung auszuführen, empfehlen wir Ihnen, ein neues Google Cloud-Projekt zu erstellen, um es von Ihren bestehenden laufenden Projekten zu isolieren.
Beginnen wir am Standort von Google Cloud.
Von Ihrer Google Cloud-Startseite aus haben Sie neben dem Cloud-Speicher noch Zugriff auf viele andere Dinge. Wir interessieren uns für die Cloud Storage-Buckets, die innerhalb der Cloud Storage-Ebene der Google Cloud Platform verfügbar sind: 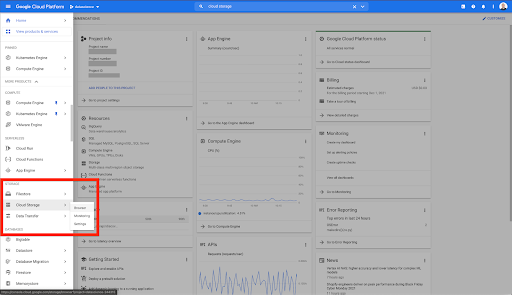
Sie können den Cloud Storage-Browser auch direkt unter https://console.cloud.google.com/storage/browser erreichen.
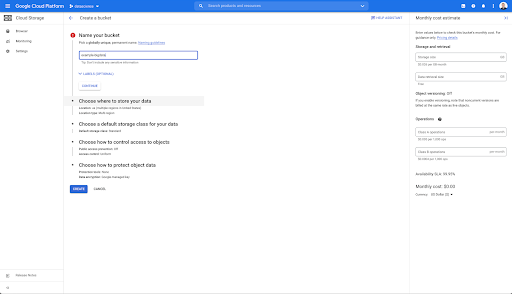
Anschließend müssen Sie einen Cloud Storage-Bucket erstellen und die richtigen Berechtigungen erteilen, damit das Dienstkonto von Oncrawl unter dem Präfix Ihrer Wahl darauf schreiben darf.
Der Google Cloud Storage-Bucket dient als temporärer Speicher für die Big-Data-Exporte aus Oncrawl, bevor sie in Google BigQuery geladen werden.
In diesem Bucket habe ich auch zwei Ordner erstellt: „links“ und „pages“: 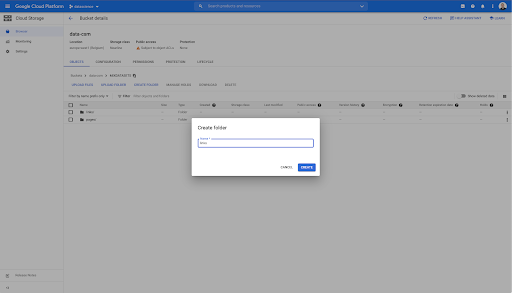
Exportieren von Datensätzen aus Oncrawl
Nachdem wir nun den Bereich eingerichtet haben, in dem wir die Daten speichern möchten, müssen wir sie aus Oncrawl exportieren. Der Export in einen Google Cloud Storage-Bucket mit Oncrawl ist besonders einfach, da wir Daten im richtigen Format exportieren und direkt im Bucket speichern können. Dadurch entfallen alle zusätzlichen Schritte.
Erstellen eines API-Schlüssels
Das Exportieren von Daten aus Oncrawl im Parquet-Format für BigQuery erfordert die Verwendung eines API-Schlüssels, um im Auftrag des Inhabers des Oncrawl-Kontos programmgesteuert auf die API einzuwirken. Mit der Oncrawl-Anwendung können Benutzer benannte API-Schlüssel erstellen, sodass Ihr Konto immer gut organisiert und sauber ist. API-Schlüssel sind auch mit verschiedenen Berechtigungen (Bereichen) verknüpft, sodass Sie die Schlüssel und ihre Zwecke verwalten können.
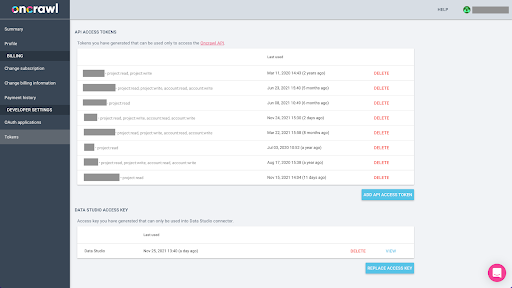
Nennen wir unseren neuen Schlüssel „Knowledge Session Key“. Die Big-Data-Exportfunktion erfordert Schreibberechtigungen im Konto, da wir die Datenexporte erstellen. Dazu benötigen wir Lesezugriff auf das Projekt und Lese- und Schreibzugriff auf das Konto.
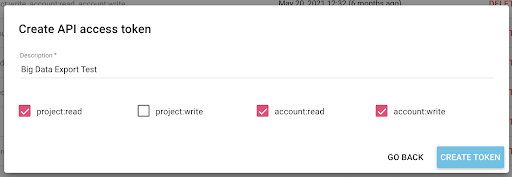
Jetzt haben wir einen neuen API-Schlüssel, den ich in meine Zwischenablage kopieren werde.
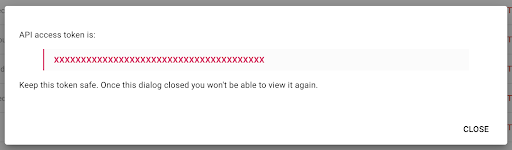
Beachten Sie, dass Sie den Schlüssel aus Sicherheitsgründen nur einmal kopieren können . Wenn Sie vergessen, den Schlüssel zu kopieren, müssen Sie den Schlüssel löschen und einen neuen erstellen.
Erstellen Sie Ihr Python-Skript
Ich habe dafür ein Google Colab-Notizbuch erstellt, aber ich werde den Code unten teilen, damit Sie Ihre eigenen Tools oder Ihr eigenes Notizbuch erstellen können.
1. Speichern Sie Ihren API-Schlüssel in einer globalen Variablen
Zuerst booten wir die Umgebung und deklarieren den API-Schlüssel in einer globalen Variablen namens „Oncrawl Token“. Dann bereiten wir uns auf den Rest des Experiments vor:
#@title Greifen Sie auf die Oncrawl-API zu
#@markdown Geben Sie unten Ihr API-Token an, damit dieses Notebook auf Ihre Oncrawl-Daten zugreifen kann:
# IHR TOKEN FÜR ONCRAWL-API
ONCRAWL_TOKEN = "" #@param {type:"string"}
!pip Gefängnis installieren
aus IPython.display import clear_output
clear_output()
print('Alle geladen.') 
2. Erstellen Sie eine Dropdown-Liste, um das Oncrawl-Projekt auszuwählen, mit dem Sie arbeiten möchten
Dann möchten wir mit dieser Taste in der Lage sein, das Projekt auszuwählen, mit dem wir spielen möchten, indem wir die Liste der Projekte abrufen und aus dieser Liste ein Dropdown-Widget erstellen. Führen Sie beim Ausführen des zweiten Codeblocks die folgenden Schritte aus:
- Wir rufen die Oncrawl-API auf, um die Liste der Projekte auf dem Konto mit dem soeben übermittelten API-Schlüssel abzurufen.
- Sobald wir die Liste des Projekts aus der API-Antwort haben, formatieren wir sie als Liste mit dem Namen des Projekts sowie der Start-URL des Projekts.
- Wir speichern die ID des Projekts, die in der Antwort angegeben wurde.
- Wir erstellen ein Dropdown-Menü und zeigen es unter dem Codeblock an.
#@title Wählen Sie die zu analysierende Website aus, indem Sie das entsprechende Oncrawl-Projekt auswählen
Anfragen importieren
Gefängnis importieren
Importieren Sie ipywidgets als Widgets
json importieren
# Holen Sie sich eine Liste der Projekte
Antwort = Anfragen.get("https://app.oncrawl.com/api/v2/projects?limit={limit}&sort={sort}".format(
Grenze=1000,
sort='name:asc'
),
headers={ 'Autorisierung': 'Bearer '+ONCRAWL_TOKEN }
)
json_res = Antwort.json()
#prepare Dropdown, damit Benutzer ein Projekt auswählen können
Projekte = []
für Artikel in json_res['projects']:
projects.append(('{} - {}'.format(item['name'], item['start_url']), item['id']))
Ausgabe = Widgets.Ausgabe()
dropdown_purpose = widgets.Dropdown(options = projects, description="Project: ")
def dropdown_project_eventhandler(ändern):
ausgabe.clear_output()
mit Ausgang:
Anzeige (Projekte)
dropdown_purpose.observe(dropdown_project_eventhandler, names='value')
Anzeige (Dropdown-Zweck) Aus dem Dropdown-Menü, das dadurch erstellt wird, können Sie die vollständige Liste des Projekts sehen, auf das der API-Schlüssel Zugriff hat. 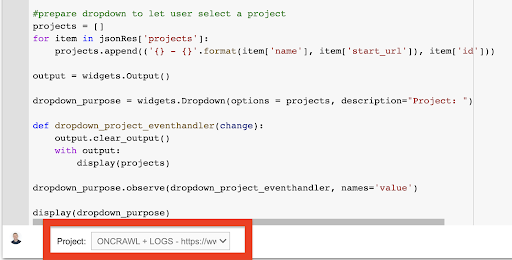
Für die heutige Demonstration verwenden wir ein Demoprojekt, das auf der Oncrawl-Website basiert.
3. Erstellen Sie eine Dropdown-Liste, um das Crawling-Profil innerhalb des Projekts auszuwählen, mit dem Sie arbeiten möchten
Als Nächstes entscheiden wir, welches Crawling-Profil verwendet werden soll. Wir möchten innerhalb dieses Projekts ein Crawl-Profil auswählen. Das Demoprojekt hat viele verschiedene Crawl-Konfigurationen: 
In diesem Fall betrachten wir ein Projekt, das die Oncrawl-Teams häufig für Experimente verwenden, also wähle ich das Crawling-Profil aus, das vom Marketingteam verwendet wird, um die Leistung der Oncrawl-Website zu überwachen. Da dies das stabilste Crawl-Profil sein soll, ist es für das heutige Experiment eine gute Wahl.
Um das Crawling-Profil abzurufen, verwenden wir die Oncrawl-API, um in jedem einzelnen Crawling-Profil im Projekt nach dem letzten Crawling zu fragen:
- Wir bereiten die Abfrage der Oncrawl-API für das jeweilige Projekt vor.
- Wir fragen nach allen zurückgegebenen Crawls in absteigender Reihenfolge nach ihrem Erstellungsdatum.
Anfragen importieren
json importieren
Importieren Sie ipywidgets als Widgets
project_id = dropdown_purpose.value
# Projektdetails abrufen (alle Crawls im Projekt einbeziehen)
Projekt = Requests.get("https://app.oncrawl.com/api/v2/projects/{}".format(project_id),
params=dict(include_nested_resources=True, sort="created_at:desc"),
headers={ 'Authorization': 'Bearer '+ONCRAWL_TOKEN }).json()
# Crawls nach Crawl-Profil gruppieren (Crawl-Name)
crawls_by_config = {}
Versuchen:
für crawl in project['crawls']:
if crawl['status'] in ["done"]:
wenn crawl['crawl_config']['name'] nicht in crawls_by_config.keys():
crawls_by_config[crawl['crawl_config']['name']] = {'crawl_ids' : [], 'is_crawl_archived' : False}
if len(crawls_by_config[crawl['crawl_config']['name']]['crawl_ids']) == 0:
crawls_by_config[crawl['crawl_config']['name']]['crawl_ids'].append(crawl['id'])
if crawl['status'] == "archiviert":
crawls_by_config[crawl['crawl_config']['name']]['is_crawl_archived'] = True
außer Ausnahme wie z. B.:
Exception auslösen ("error {} , {}".format(e, project))
# Erstellen Sie die Liste für die Dropdown-Auswahl
list = [("{} ({})".format(k, len(v['crawl_ids'])), k) für k, v in crawls_by_config.items()]
dropdown_crawl_configs = Widgets.Dropdown (Optionen = Liste, Beschreibung = "Crawl-Konfigurationen: ")
def dropdown_cc_eventhandler(ändern):
ausgabe.clear_output()
mit Ausgang:
Anzeige (crawls_by_config)
if len(crawls_by_config.values()) == 0:
print('Kein Live-Crawl in diesem Projekt gefunden')
dropdown_crawl_configs.observe(dropdown_cc_eventhandler, names='value')
display(dropdown_crawl_configs)Wenn dieser Code ausgeführt wird, antwortet uns die Oncrawl-API mit der Liste der Crawls durch absteigende „erstellt bei“-Eigenschaft.
Da wir uns nur auf abgeschlossene Crawls konzentrieren wollen, gehen wir dann die Liste der Crawls durch. Für jeden einzelnen Crawl mit dem Status „erledigt“ speichern wir den Namen des Crawl-Profils und wir speichern die Crawl-ID.
Wir werden höchstens ein Crawl-by-Crawl-Profil behalten, damit wir nicht zu viele Crawls preisgeben möchten.
Das Ergebnis ist dieses neue Dropdown-Menü, das aus der Liste der Crawling-Profile im Projekt erstellt wurde. Wir wählen den, den wir wollen. Dies erfordert den letzten Crawl-Durchlauf des Marketingteams: 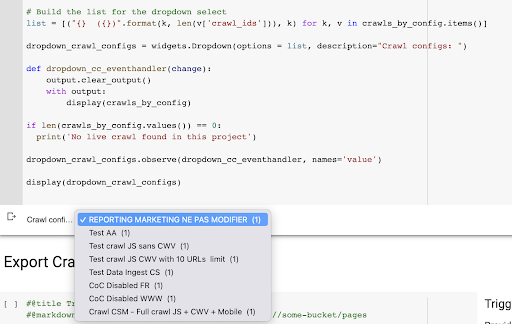
4. Identifizieren Sie den letzten Crawl mit dem Profil, das wir verwenden möchten
Wir haben bereits die Crawl-ID, die dem letzten Crawl im ausgewählten Profil zugeordnet ist. Es ist im Objektverzeichnis „crawl_by_config“ versteckt. 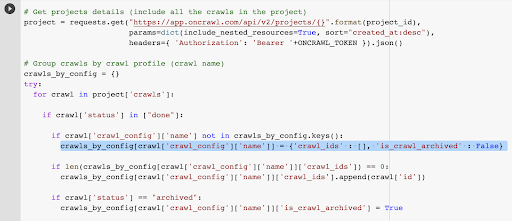
Sie können dies ganz einfach in der Oberfläche überprüfen: Finden Sie den letzten abgeschlossenen Crawl in dieser Profilanalyse. 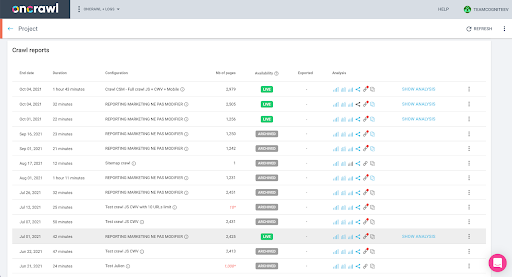
Wenn wir auf klicken, um die Analyse anzuzeigen, sehen wir, dass die Crawl-ID mit E617 endet. 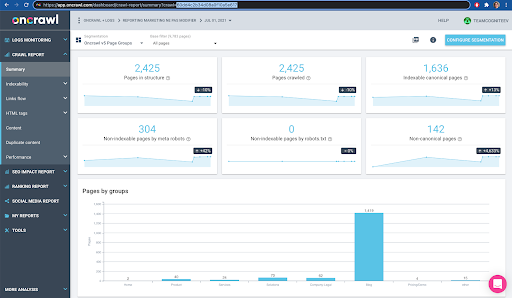
Notieren wir uns für die heutige Demonstration einfach die Crawl-ID.
Wenn Sie bereits wissen, was Sie tun, können Sie natürlich die gerade behandelten Schritte überspringen, um die Oncrawl-API aufzurufen, um die Liste der Projekte und die Liste der Crawls nach Crawl-Profil zu erhalten: Sie haben bereits die Crawl-ID von Schnittstelle, und diese ID ist alles, was Sie brauchen, um den Export auszuführen.
Die Schritte, die wir bisher ausgeführt haben, dienen lediglich dazu, den Prozess des Abrufens des letzten Crawls des angegebenen Crawl-Profils des angegebenen Projekts zu vereinfachen, je nachdem, worauf der API-Schlüssel Zugriff hat. Dies kann nützlich sein, wenn Sie diese Lösung anderen Benutzern zur Verfügung stellen oder wenn Sie sie automatisieren möchten.
5. Crawl-Ergebnisse exportieren
Nun schauen wir uns den Exportbefehl an:
#@title Bigdata-Export auslösen
#@markdown Geben Sie Ihren GCS-Bucket und das Präfix gs://some-bucket/pages an
# IHR GCS-EIMER
gcs_bucket = #@param {type:"string"}
gcs_prefix = #@param {type:"string"}
# Holen Sie sich die letzte Crawl-ID aus dem angegebenen Projekt / Crawl-Profil
list_crawl_ids = crawls_by_config[dropdown_crawl_configs.value]['crawl_ids']
last_crawl_id = list_crawl_ids[0]
# Vorlagennutzlast für Datenexportabfrage
Nutzlast = {
"data_export": {
"data_type": 'Seite',
"resource_id": last_crawl_id,
"output_format": 'Parkett',
„Ziel“: „gcs“,
"Zielparameter": {
"gcs_bucket": gcs_bucket,
„gcs_prefix“: gcs_prefix
}
}
}
# Export auslösen
export = request.post("https://app.oncrawl.com/api/v2/account/data_exports", json=payload, headers={ 'Authorization': 'Bearer '+ONCRAWL_TOKEN }).json()
# API-Antwort anzeigen
anzeigen (exportieren)
# Speichern Sie die Export-ID für die zukünftige Verwendung
export_id = export['data_export']['id']Wir möchten in den Cloud Storage-Bucket exportieren, den wir zuvor eingerichtet haben.
Darin exportieren wir die Seiten für die letzte Crawl-ID:
- Die letzte Crawl-ID wird aus der Liste der Crawl-IDs ermittelt, die irgendwo im Wörterbuch „crawls_by_config“ gespeichert ist, das in Schritt 3 erstellt wurde.
- Wir möchten denjenigen auswählen, der dem Dropdown-Menü in Schritt 4 entspricht, also verwenden wir das Wertattribut des Dropdown-Menüs.
- Dann extrahieren wir das crawl_ID-Attribut. Dies ist eine Liste. Wir behalten die Top 50 Artikel in der Liste. Wir müssen dies tun, weil wir, wie Sie sich erinnern werden, in Schritt 2 bei der Erstellung des Wörterbuchs crawls_by_config nur eine Crawl-ID pro Konfigurationsname gespeichert haben.
Ich habe Eingabefelder eingerichtet, um das Bereitstellen des Google Cloud Storage-Buckets und -Präfixes oder -Ordners zu erleichtern, an den wir den Export senden möchten. 
Zum Zwecke der Demonstration werden wir heute in den Ordner „mixed dataset“ schreiben, in einen der Ordner, die ich bereits eingerichtet habe. Als wir unseren Bucket in Google Cloud Storage eingerichtet haben, werden Sie sich daran erinnern, dass ich Ordner für den „Links“-Export und für den „Seiten“-Export vorbereitet habe.
Für den ersten Export möchten wir die Seiten im Parquet-Dateiformat in den Ordner „pages“ für die letzte Crawl-ID exportieren. 
In den Ergebnissen unten sehen Sie die Nutzlast, die an den Datenexport-Endpunkt gesendet werden soll, der der Endpunkt ist, um einen Big Data-Export mit einem API-Schlüssel anzufordern:
# Vorlagennutzlast für Datenexportabfrage
Nutzlast = {
"data_export": {
"data_type": 'Seite',
"resource_id": last_crawl_id,
"output_format": 'Parkett',
„Ziel“: „gcs“,
"Zielparameter": {
"gcs_bucket": gcs_bucket,
„gcs_prefix“: gcs_prefix
}
}
}
Diese enthält mehrere Elemente, einschließlich des Typs des Datensatzes, den Sie exportieren möchten. Sie können den Seiten-Datensatz, den Link-Datensatz, den Cluster-Datensatz oder den Datensatz mit strukturierten Daten exportieren. Wenn Sie nicht wissen, was zu tun ist, können Sie hier einen Fehler eingeben, und wenn Sie die API aufrufen, erhalten Sie eine Meldung, dass die Auswahl für den Datentyp entweder Seite oder Link oder Cluster oder strukturierte Daten sein muss. Die Nachricht sieht so aus:

{'fields': [{'message': 'Keine gültige Auswahl. Muss entweder „Seite“, „Link“, „Cluster“, „Strukturierte_Daten“ sein.',
'Name': 'Datentyp',
'type': 'invalid_choice'}],
'type': 'invalid_request_parameters'}
Für das heutige Experiment exportieren wir den Seiten-Datensatz und den Link-Datensatz in getrennten Exporten.
Beginnen wir mit dem Seitendatensatz. Wenn ich diesen Codeblock ausführe, habe ich die Ausgabe des API-Aufrufs gedruckt, die so aussieht:
{'data_export': {'data_type': 'page',
'export_failure_reason': Keine,
'id': 'XXXXXXXXXXXXX',
'output_format': 'parkett',
'output_format_parameters': Keine,
'output_row_count': Keine,
'output_size_in_bytes: 1634460016000,
'resource_id': '60dd4c2b34d08a0f10a5e617',
'status': 'ANGEFORDERT',
'Ziel': 'gcs',
'target_parameters': {'gcs_bucket': 'data-cms',
'gcs_prefix': 'MIXDATASETS/pages/'}}}
Dadurch kann ich sehen, dass der Export angefordert wurde.
Wenn wir den Status des Exports überprüfen möchten, ist das sehr einfach. Anhand der Export-ID, die wir am Ende dieses Codeblocks gespeichert haben, können wir den Status des Exports jederzeit mit folgendem API-Aufruf abfragen:
# AUSFUHRSTATUS
export_status = request.get("https://app.oncrawl.com/api/v2/account/data_exports/{}".format(export_id), headers={ 'Authorization': 'Bearer '+ONCRAWL_TOKEN }).json ()
display(export_status)
Dies zeigt einen Status als Teil des zurückgegebenen JSON-Objekts an:
{'data_export': {'data_type': 'page',
'export_failure_reason': Keine,
'id': 'XXXXXXXXXXXXX',
'output_format': 'parkett',
'output_format_parameters': Keine,
'output_row_count': Keine,
'output_size_in_bytes': Keine,
'requested_at': 1638350549000,
'resource_id': '60dd4c2b34d08a0f10a5e617',
'status': 'EXPORTIEREN',
'Ziel': 'gcs',
'target_parameters': {'gcs_bucket': 'data-csm',
'gcs_prefix': 'MIXDATASETS/pages/'}}} Wenn der Export abgeschlossen ist ( 'status': 'DONE' ), können wir zu Google Cloud Storage zurückkehren.
Wenn wir in unseren Bucket schauen und in den Ordner „Links“ gehen, gibt es hier noch nichts, weil wir die Seiten exportiert haben. 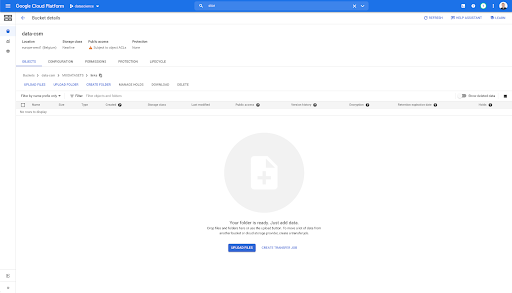
Wenn wir jedoch in den Ordner „Seiten“ schauen, können wir sehen, dass der Export erfolgreich war. Wir haben eine Parquet-Datei: 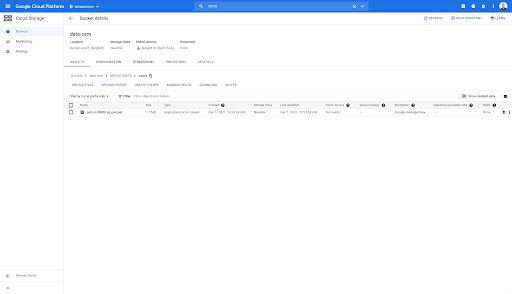
In diesem Stadium ist das Seiten-Dataset für den Import in BigQuery bereit, aber zuerst wiederholen wir die obigen Schritte, um die Parquet-Datei für die Links zu erhalten:
- Stellen Sie sicher, dass Sie das Link-Präfix festlegen.
- Wählen Sie den Datentyp „Link“.
- Führen Sie diesen Codeblock erneut aus, um den zweiten Export anzufordern.

Dadurch wird eine Parquet-Datei im Ordner „Links“ erstellt.
Erstellen von BigQuery-Datasets
Während der Export ausgeführt wird, können wir fortfahren und mit der Erstellung von Datasets in BigQuery beginnen und die Parquet-Dateien in separate Tabellen importieren. Dann werden wir die Tische zusammenfügen.
Was wir jetzt tun wollen, ist, mit Google Big Query zu spielen, das als Teil der Google Cloud Platform verfügbar ist. Sie können die Suchleiste oben auf dem Bildschirm verwenden oder direkt zu https://console.cloud.google.com/bigquery gehen.
Erstellen eines Datensatzes für Ihre Arbeit
Wir müssen ein Dataset in Google BigQuery erstellen: 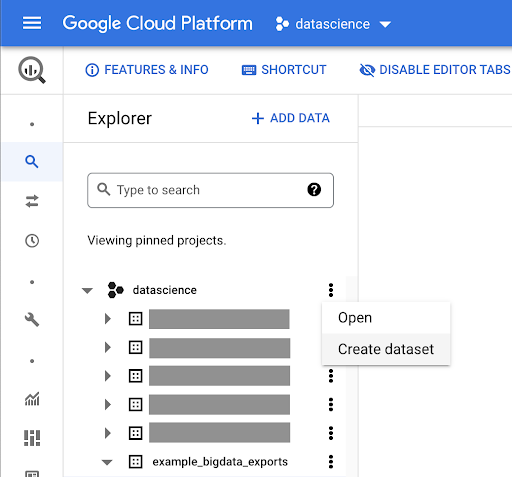
Sie müssen dem Dataset einen Namen geben und den Speicherort auswählen, an dem die Daten gespeichert werden. Dies ist wichtig, da es bestimmt, wo die Daten verarbeitet werden, und nicht geändert werden kann. Dies kann Auswirkungen haben, wenn Ihre Daten Informationen enthalten, die unter die DSGVO oder andere Datenschutzgesetze fallen. 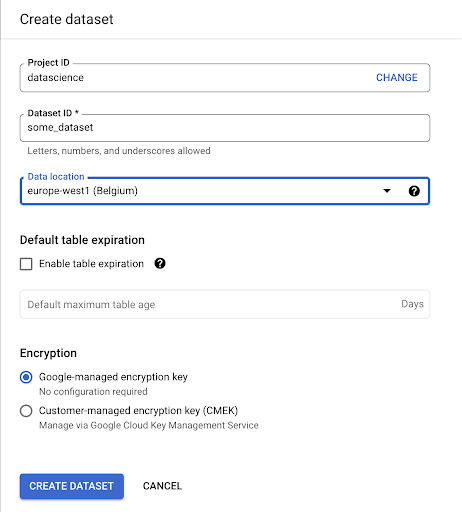
Dieser Datensatz ist zunächst leer. Wenn Sie es öffnen, können Sie eine Tabelle erstellen, den Datensatz freigeben, kopieren, löschen und so weiter.
Erstellen von Tabellen für Ihre Daten
Wir erstellen eine Tabelle in diesem Dataset. 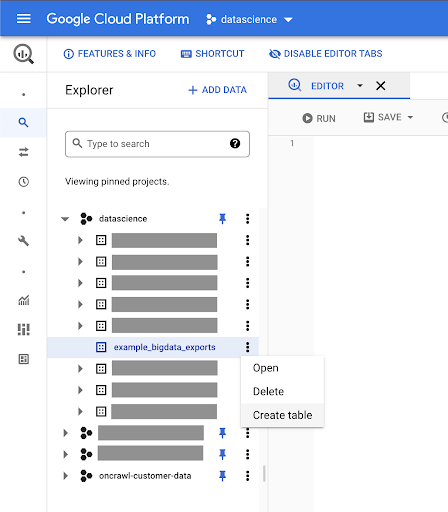
Sie können entweder eine leere Tabelle erstellen und dann das Schema bereitstellen. Das Schema ist die Definition der Spalten in der Tabelle. Sie können entweder Ihr eigenes definieren oder Google Cloud Storage durchsuchen, um ein Schema aus einer Datei auszuwählen.
Wir verwenden diese letzte Option. Wir navigieren zu unserem Bucket und dann zum Ordner „pages“. Lassen Sie uns die Seitendatei auswählen. Es gibt nur eine Datei, also können wir nur eine auswählen, aber wenn der Export mehrere Dateien erzeugt hätte, hätten wir alle auswählen können. 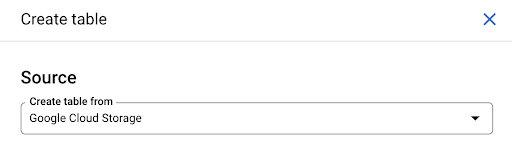
Wenn wir die Datei auswählen, erkennt sie automatisch, dass sie im Parquet-Dateiformat vorliegt. Wir wollen eine Tabelle namens „pages“ erstellen und das Schema wird durch die Quelldatei definiert. 
Wenn wir eine Parquet-Datei laden, bettet sie ein Schema ein. Mit anderen Worten, die Definition der Spalten der Tabelle, die wir erstellen, wird aus dem Schema abgeleitet, das bereits in der Parquet-Datei vorhanden ist. Hier passiert tatsächlich ein Teil der Magie.
Lassen Sie uns einfach weitermachen und die Tabelle einfach aus der Parquet-Datei erstellen. 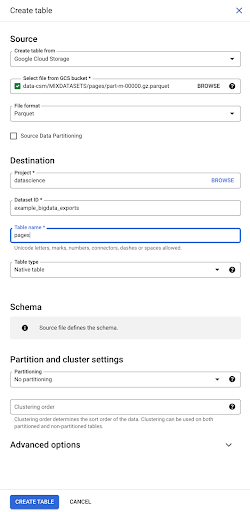
In der linken Seitenleiste können wir jetzt sehen, dass eine Tabelle in unserem Datensatz erschienen ist, was genau das ist, was wir wollen:
Wir haben jetzt also das Schema der Seitentabelle mit allen Feldern, die automatisch aus der Parquet-Datei abgeleitet wurden. Wir haben den Inrank, die Tiefe der Seite, ob die Seite eine Weiterleitung ist und so weiter und so fort: 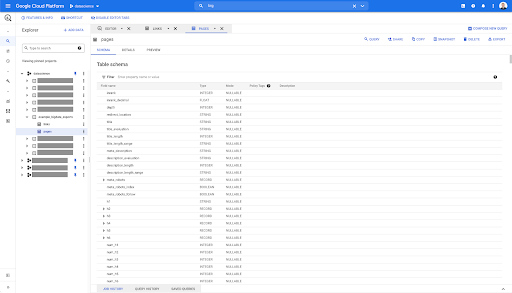
Die meisten dieser Felder sind mit denen identisch, die in Data Studio über den Oncrawl Data Studio-Konnektor zur Verfügung gestellt werden, und mit denen, die Sie im Daten-Explorer in der Oncrawl-Oberfläche sehen. 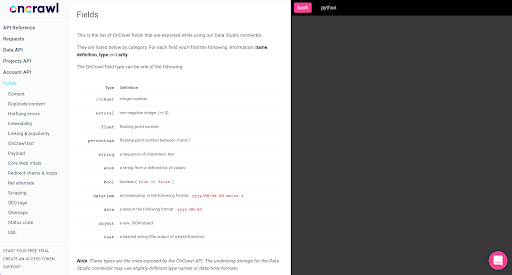
Es gibt jedoch einige Unterschiede. Wenn wir mit dem Big-Data-Rohdatenexport spielen, haben Sie alle Rohdaten.
- In Data Studio werden einige Felder umbenannt, einige Felder ausgeblendet und einige Felder hinzugefügt, z. B. der Status.
- Im Daten-Explorer werden einige Felder als „virtuelle Felder“ bezeichnet, was bedeutet, dass sie eine Art Verknüpfung zu einem zugrunde liegenden Feld darstellen können. Diese im Daten-Explorer verfügbaren virtuellen Felder werden nicht im Schema aufgeführt, können aber basierend auf dem, was in der Parquet-Datei verfügbar ist, neu erstellt werden.
Lassen Sie uns nun diese Tabelle schließen und es für die Links noch einmal tun.
Für die Links-Tabelle ist das Schema etwas kleiner. 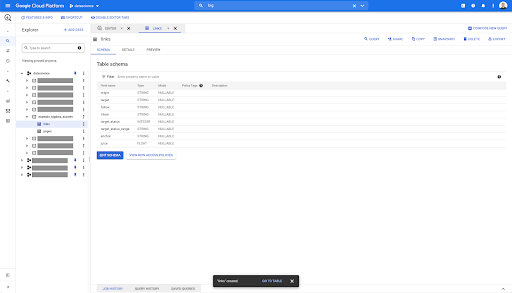
Es enthält nur die folgenden Felder:
- Die Herkunft des Links,
- Das Ziel des Links,
- Die folgende Eigenschaft,
- Das innere Eigentum,
- Der Zielzustand,
- Die Reichweite des Zielzustands,
- Der Ankertext und
- Der Saft oder das Eigenkapital, das über den Link gekauft wurde.
Wenn Sie in einer beliebigen Tabelle in BigQuery auf den Vorschau-Tab klicken, erhalten Sie eine Vorschau der Tabelle, ohne die Datenbank abzufragen: 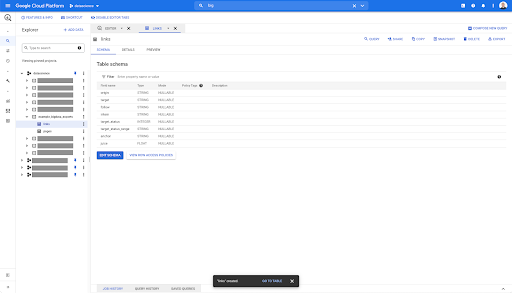
Dies gibt Ihnen einen schnellen Überblick darüber, was darin verfügbar ist. In der Vorschau für die obige Verknüpfungstabelle haben Sie eine Vorschau jeder einzelnen Zeile und aller Spalten.
In einigen Oncrawl-Datensätzen sehen Sie möglicherweise einige Zeilen, die sich über mehrere Zeilen erstrecken. Ich habe kein Beispiel für Sie, aber wenn dies der Fall ist, liegt es daran, dass einige Felder eine Liste von Werten enthalten. Beispielsweise erstreckt sich in der Liste der h2-Überschriften auf einer Seite eine einzelne Zeile über mehrere Zeilen in Big Query. Wir werden uns das später ansehen, wenn wir ein Beispiel sehen.
Erstellung Ihrer Abfrage
Wenn Sie noch nie eine Abfrage in BigQuery erstellt haben, ist es jetzt an der Zeit, damit herumzuspielen, um sich mit der Funktionsweise vertraut zu machen. BigQuery verwendet SQL, um Daten zu suchen.
So funktionieren Abfragen
Schauen wir uns als Beispiel alle URLs und ihren Rang an…
URL WÄHLEN, Rang ...
aus dem Seitendatensatz…
URL AUSWÄHLEN, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` ...
wobei der Statuscode der Seite 200 ist…
URL AUSWÄHLEN, inrank FROM „datascience-oncrawl.example_bigdata_exports.pages“, WO status_code = 200 ...
und nur die ersten 10 Ergebnisse behalten:
URL AUSWÄHLEN, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 10
Wenn wir diese Abfrage ausführen, erhalten wir die ersten 10 Zeilen der Liste der Seiten mit dem Statuscode 200.
Jede dieser Eigenschaften kann geändert werden. Wenn ich 1000 Zeilen statt 10 möchte, kann ich 1000 Zeilen festlegen:
URL AUSWÄHLEN, inrank FROM `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 1000
Wenn ich sortieren möchte, kann ich das mit „order-by“ tun: Dies gibt mir alle Zeilen, die nach absteigender Inrank-Reihenfolge geordnet sind.
SELECT url, inrank FROM `datascience-oncrawl.example_bigdata_exports.links` ORDER BY inrank DESC LIMIT 1000
Dies ist meine erste Anfrage. Ich kann es speichern, wenn ich möchte, was mir die Möglichkeit gibt, diese Abfrage später wiederzuverwenden, wenn ich möchte: 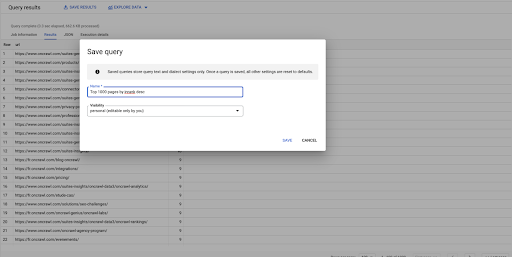
Verwenden von Abfragen zum Beantworten einfacher Fragen: Auflisten aller internen Links zu Seiten mit einem 301-Status
Nachdem wir nun wissen, wie man eine Abfrage erstellt, kehren wir zu unserem ursprünglichen Problem zurück.
Wir wollten Datenfragen beantworten, ob einfach oder komplex. Beginnen wir mit einer einfachen Frage wie „Was sind all die internen Links, die auf Seiten mit dem Status 301 (umgeleitet) verweisen, und wo kann ich sie finden?“
Erstellen einer neuen Abfrage
Wir beginnen damit, zu untersuchen, wie dies funktioniert.
Ich möchte Spalten für die folgenden Elemente aus der „Links“-Datenbank:
- Herkunft
- Ziel
- Zielstatuscode
WÄHLEN Sie Ursprung, Ziel, Zielstatus AUS „datascience-oncrawl.example_bigdata_exports.links“.
Ich möchte diese nur auf interne Links beschränken, aber stellen wir uns vor, ich erinnere mich nicht an den Namen der Spalte oder den Wert, der angibt, ob der Link intern oder extern ist. Ich kann zum Schema gehen, um es nachzuschlagen, und die Vorschau verwenden, um den Wert anzuzeigen: 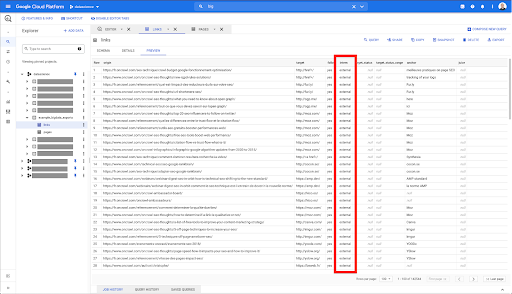
Dies sagt mir, dass die Spalte „intern“ heißt und der mögliche Wertebereich „extern“ oder „intern“ ist.
In meiner Abfrage möchte ich „where intern is internal“ angeben und die Ergebnisse vorerst auf die ersten 100 beschränken:
SELECT origin, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links` WHERE intern LIKE 'internal' LIMIT 100
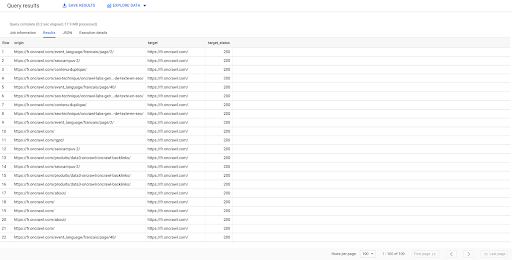
Das obige Ergebnis zeigt die Liste der Links mit ihrem Zielstatus. Wir haben nur interne Links, und wir haben 100 davon, wie in der Abfrage angegeben.
Wenn wir nur interne Links zu diesem Punkt zu umgeleiteten Seiten haben möchten, könnten wir sagen "wobei intern wie intern und der Zielstatus gleich 301 ist":
SELECT origin, target, target_status FROM `datascience-oncrawl.example_bigdata_exports.links` WHERE intern LIKE 'internal' AND target_status = 301
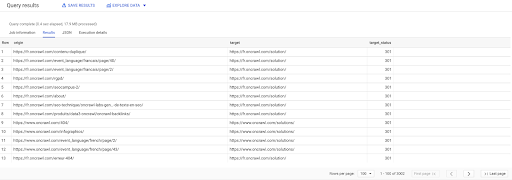
Wenn wir nicht wissen, wie viele davon existieren, können wir diese neue Abfrage ausführen und sehen, dass es 3002 interne Links mit einem Zielstatus von 301 gibt.
Joining the tables: Suche nach endgültigen Statuscodes von Links, die auf umgeleitete Seiten verweisen
Auf einer Website haben Sie oft Links zu Seiten, die umgeleitet werden. Wir möchten den Statuscode der Seite wissen, auf die sie umgeleitet werden (oder die endgültige Ziel-URL).
In einem Datensatz haben Sie die Informationen zu den Links: die Ursprungsseite, die Zielseite und ihren Statuscode (wie 301), aber nicht die URL, auf die eine umgeleitete Seite verweist. Und im anderen haben Sie die Informationen zu den Weiterleitungen und ihren endgültigen Zielen, aber nicht die ursprüngliche Seite, auf der der Link zu ihnen gefunden wurde.
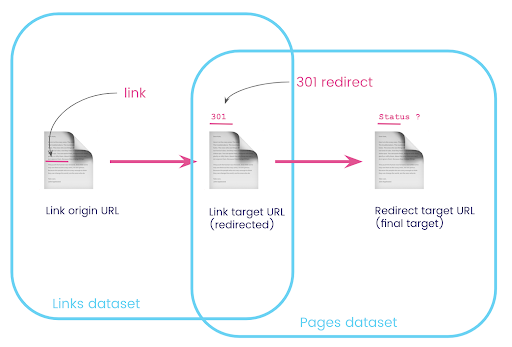
Lassen Sie uns das aufschlüsseln:
Zuerst wollen wir Links zu Weiterleitungen. Schreiben wir das auf. Wir wollen:
- Der Ursprung.
- Das Ziel. Das Ziel muss einen 301-Statuscode haben.
- Das endgültige Ziel der Weiterleitung.
Mit anderen Worten, wir wollen im Link-Datensatz:
- Der Ursprung des Links
- Das Ziel des Links
Im Seitendatensatz wollen wir:
- Alle Ziele, die umgeleitet werden
- Das endgültige Ziel der Weiterleitung
Dies gibt uns eine Abfrage wie:
SELECT url, final_redirect_location, final_redirect_status FROM `datascience-oncrawl.example_bigdata_exports.pages` AS pages WHERE status_code = 301 ODER status_code = 302
Dies sollte mir den ersten Teil der Gleichung geben.
Jetzt brauche ich alle Links, die auf die Seite verlinken, die das Ergebnis der gerade erstellten Abfrage sind, Aliase für meine Datensätze verwenden und sie auf der Link-Ziel-URL und der Seiten-URL verbinden. Dies entspricht dem Überlappungsbereich der beiden Datensätze in der Grafik am Anfang dieses Abschnitts.
AUSWÄHLEN links.ursprung, seiten.url, pages.final_redirect_location, pages.final_redirect_status AUS `datascience-oncrawl.example_bigdata_exports.pages` AS-Seiten BEITRETEN `datascience-oncrawl.example_bigdata_exports.links` AS-Links AN links.target = seiten.url WO seiten.status_code = 301 ODER Seiten.Status_Code = 302 SORTIEREN NACH Herkunft ASC
In den Query-Ergebnissen kann ich die Spalten zur Verdeutlichung umbenennen, sehe aber bereits, dass ich von einer Seite in der ersten Spalte einen Link habe, der auf die Seite in der zweiten Spalte führt, auf die wiederum umgeleitet wird die Seite in der dritten Spalte. In der vierten Spalte habe ich den Statuscode des endgültigen Ziels: 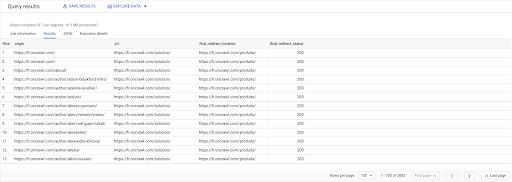
Jetzt kann ich erkennen, welche Links auf umgeleitete Seiten verweisen, die nicht zu 200 Seiten aufgelöst werden. Vielleicht sind es zum Beispiel 404-Fehler, die mir eine Prioritätenliste der zu korrigierenden Links geben.
Wir haben bereits gesehen, wie man eine Abfrage speichert. Wir können die Ergebnisse auch speichern, für bis zu 16000 Ergebniszeilen: 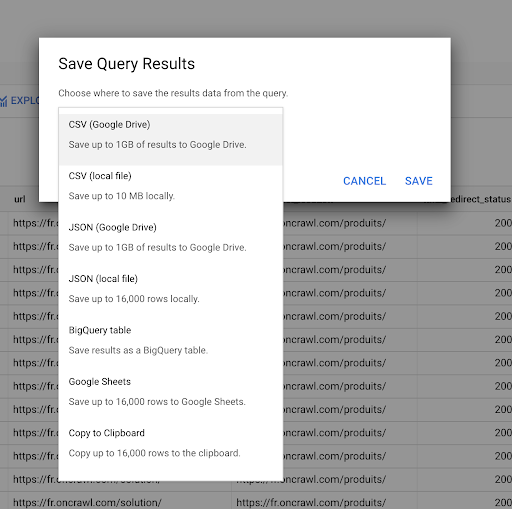
Diese Ergebnisse können wir dann auf vielfältige Weise nutzen. Hier sind ein paar Beispiele:
- Wir können dies als CSV- oder JSON-Datei lokal speichern.
- Wir können es als Google Sheets-Tabelle speichern und mit dem Rest des Teams teilen.
- Wir können es auch direkt nach Data Studio exportieren.
Daten als strategischer Vorteil
Mit all diesen Möglichkeiten ist es einfach, die Antworten auf Ihre komplexen Fragen strategisch zu nutzen. Möglicherweise haben Sie bereits Erfahrung darin, BigQuery-Ergebnisse mit Data Studio oder anderen Datenvisualisierungsplattformen zu verbinden, oder Sie haben möglicherweise bereits einen Prozess eingerichtet, der Informationen an ein Engineering-Team oder sogar an einen Business-Intelligence- oder Datenanalyse-Workflow weiterleitet.
Wenn Sie die Schritte in diesem Artikel in einen Prozess eingebunden haben, denken Sie daran, dass Sie alle Schritte in BigQuery automatisieren können: Alle Aktionen, die wir in diesem Artikel durchgeführt haben, sind auch über die BigQuery-API zugänglich. Das bedeutet, dass sie programmgesteuert als Teil eines Skripts oder benutzerdefinierten Tools ausgeführt werden können.
Was auch immer Ihre nächsten Schritte sind, der erste Schritt ist immer der Zugriff auf rohe SEO- und Website-Daten. Wir glauben, dass dieser Zugriff auf Daten einer der wichtigsten Teile der technischen Analyse ist: Mit Oncrawl haben Sie immer vollen Zugriff auf Ihre Rohdaten.
Der Zugriff auf Daten bedeutet auch, dass Sie über die Möglichkeiten der Oncrawl-Oberfläche hinausgehen und alle Beziehungen zwischen Ihren Daten untersuchen können, egal wie komplex die Fragen sind, die Sie stellen.