
Eine Einführung in die Analyse von SEO-Logdateien
Veröffentlicht: 2021-05-17Die Protokollanalyse ist die gründlichste Methode, um zu analysieren, wie Suchmaschinen unsere Websites lesen. Jeden Tag verwenden SEOs, digitale Vermarkter und Webanalyse-Spezialisten Tools, die Diagramme zu Traffic, Benutzerverhalten und Conversions anzeigen. SEOs versuchen normalerweise zu verstehen, wie Google ihre Website über die Google Search Console crawlt.
Also… warum sollte ein SEO andere Tools analysieren, um zu überprüfen, ob eine Suchmaschine die Seite richtig liest? Okay, fangen wir mit den Grundlagen an.
Was sind Protokolldateien?
Eine Protokolldatei ist eine Datei, in die das Server-Web eine Zeile für jede einzelne Ressource auf der Website schreibt, die von Bots oder Benutzern angefordert wird. Jede Zeile enthält Daten über die Anfrage, die Folgendes beinhalten können:
Anrufer-IP, Datum, benötigte Ressource (Seite, .css, .js, …), User-Agent, Antwortzeit, …
Eine Reihe sieht etwa so aus:
66.249.**.** - - [13/Apr/2021:00:07:31 +0200] "GET /***/x_*** HTTP/1.1" 200 40960 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" "www.***.it" "-"
Crawlbarkeit und Aktualisierbarkeit
Jede Seite hat drei grundlegende SEO-Status:
- kriechbar
- indexierbar
- rankbar
Aus Sicht der Protokollanalyse wissen wir, dass eine Seite, um indexiert zu werden, von einem Bot gelesen werden muss. Ebenso müssen Inhalte, die bereits von einer Suchmaschine indiziert wurden, erneut gecrawlt werden, um in den Indizes der Suchmaschine aktualisiert zu werden.
Leider haben wir in der Google Search Console diesen Detaillierungsgrad nicht: Wir können überprüfen, wie oft der Googlebot in den letzten drei Monaten eine Seite auf der Website gelesen hat und wie schnell der Webserver geantwortet hat.
Wie können wir überprüfen, ob ein Bot eine Seite gelesen hat? Natürlich durch die Verwendung von Logfiles und einem Logfile-Analyzer.
Warum müssen SEOs Logfiles analysieren?
Durch die Analyse von Protokolldateien können SEOs (und auch Systemadministratoren) Folgendes verstehen:
- Genau das, was ein Bot liest
- Wie oft der Bot es liest
- Wie viel Crawls kosten, gemessen an der aufgewendeten Zeit (ms)
Ein Protokollanalysetool ermöglicht die Analyse von Protokollen, indem Informationen nach „Pfad“, Dateityp oder Antwortzeit gruppiert werden. Ein großartiges Protokollanalysetool ermöglicht es uns auch, Informationen aus Protokolldateien mit anderen Datenquellen wie Google Search Console (Klicks, Impressionen, durchschnittliche Positionen) oder Google Analytics zu verknüpfen.
Oncrawl Log Analyzer
 Mehr erfahren
Mehr erfahrenWorauf ist in Protokolldateien zu achten?
Eine der wichtigsten Informationen in Protokolldateien ist, was nicht in Protokolldateien enthalten ist. Wirklich, ich scherze nicht. Der erste Schritt, um zu verstehen, warum eine Seite nicht indexiert oder nicht auf die neueste Version aktualisiert wurde, besteht darin, zu prüfen, ob der Bot (z. B. Googlebot) sie gelesen hat.
Wenn die Seite häufig aktualisiert wird, kann es danach wichtig sein, zu überprüfen, wie oft ein Bot die Seite oder den Website-Bereich liest.
Im nächsten Schritt wird überprüft, welche Seiten am häufigsten von Bots gelesen werden. Indem Sie sie verfolgen, können Sie überprüfen, ob diese Seiten:
- verdienen es, so oft gelesen zu werden
- oder werden so oft gelesen, weil etwas auf der Seite ständige, außer Kontrolle geratene Änderungen verursacht
Zum Beispiel hatte eine Website, an der ich vor einigen Monaten arbeitete, eine sehr hohe Häufigkeit von Bot-Lesevorgängen auf einer seltsamen URL. Der Bot enthüllte, dass diese Seite von einer URL stammte, die von einem JS-Skript erstellt wurde, und dass diese Seite mit einigen Debugging-Werten versehen war, die sich jedes Mal änderten, wenn die Seite geladen wurde … Nach dieser Enthüllung kann ein guter SEO sicherlich die richtige Lösung finden, um dies zu beheben Budgetloch kriechen.
Crawl-Budget
Crawl-Budget? Was ist es? Jede Website hat ihr metaphorisches Budget in Bezug auf Suchmaschinen und ihren Bot. Ja: Google legt eine Art Budget für Ihre Website fest. Dies wird nirgendwo aufgezeichnet, aber Sie können es auf zwei Arten „berechnen“:
- Überprüfen Sie den Crawl-Statistikbericht der Google Search Console
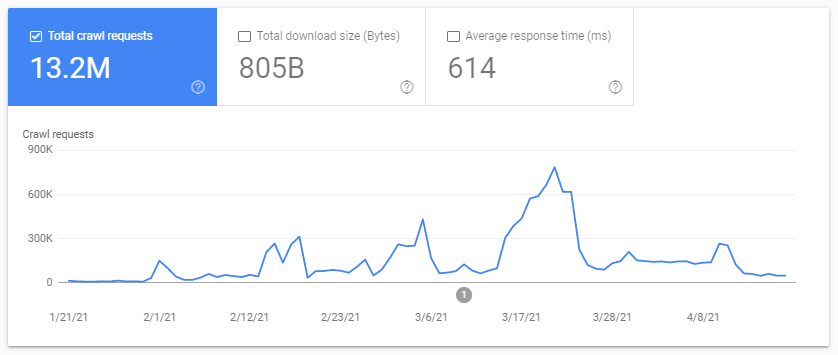
- Prüfen der Protokolldateien, gruppieren ( Filtern ) durch den User-Agent, der „Googlebot“ enthält ( Sie erhalten die besten Ergebnisse, wenn Sie sicherstellen, dass diese User-Agents mit den richtigen Google-IPs übereinstimmen… )
Das Crawl-Budget erhöht sich, wenn die Website mit interessanten Inhalten aktualisiert wird oder wenn sie regelmäßig Inhalte aktualisiert oder wenn die Website gute Backlinks erhält.
Wie das Crawl-Budget auf Ihrer Website ausgegeben wird, kann verwaltet werden durch:
- Interne Links (Follow / Nofollow auch!)
- noindex / kanonisch
- robots.txt (Achtung: das „blockt“ den User-Agent)
Zombieseiten
„Zombie-Seiten“ sind für mich alle Seiten, die über längere Zeit keinen organischen Traffic oder Bot-Besuche mehr hatten, aber interne Links auf sie verweisen.
Diese Art von Seite kann zu viel Crawl-Budget verbrauchen und aufgrund interner Links einen unnötigen Seitenrang erhalten. Diese Situation kann gelöst werden:
- Wenn diese Seiten für die Benutzer nützlich sind, die auf die Website kommen, können wir sie auf noindex und die internen Links zu ihnen auf nofollow setzen ( oder disallow robots.txt verwenden, aber seien Sie vorsichtig damit … )
- Wenn diese Seiten für die Benutzer, die auf die Website kommen, nicht nützlich sind, können wir sie entfernen (und einen Statuscode von 410 oder 404 zurückgeben) und alle internen Links entfernen.
Mit Oncrawl können wir einen „Zombie-Bericht“ erstellen, basierend auf:
- GSC-Impressionen
- GSC klickt
- GA-Sitzungen
Wir können auch Protokollereignisse verwenden, um Zombieseiten aufzudecken: Wir können beispielsweise einen 0-Ereignisfilter definieren. Eine der einfachsten Möglichkeiten, dies zu tun, ist das Erstellen einer Segmentierung. Im Beispiel unten filtere ich alle Seiten nach folgenden Kriterien: keine Googlebot-Treffer, aber mit einem Inrank (das bedeutet, dass diese Seiten interne Links haben, die auf sie verweisen). 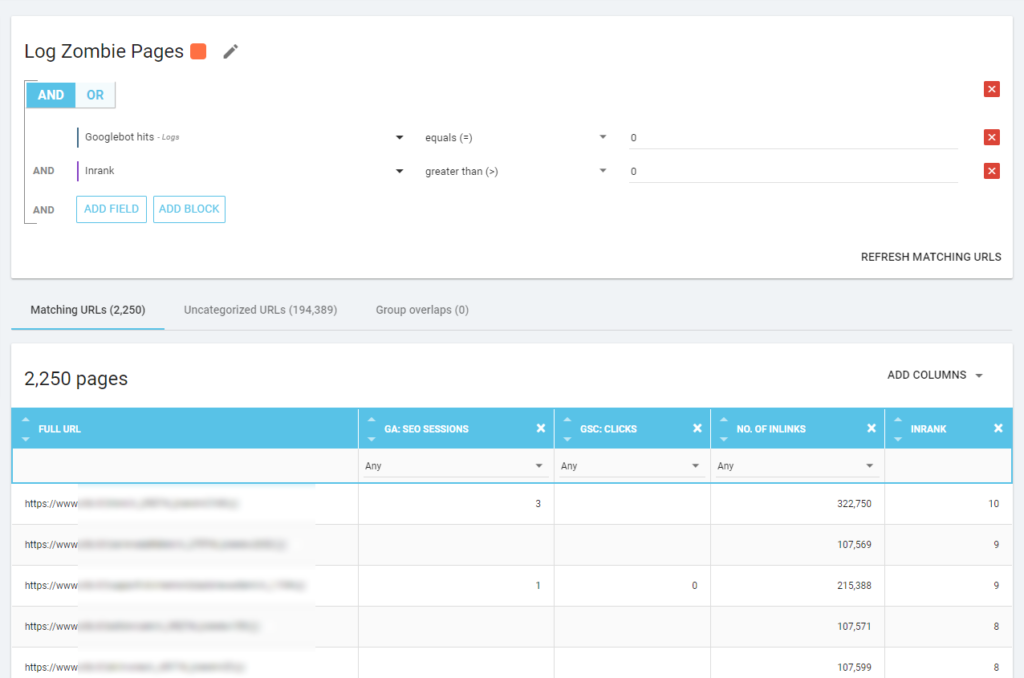
Jetzt können wir diese Segmentierung in allen Oncrawl-Berichten verwenden. Auf diese Weise können wir aus jeder Grafik Erkenntnisse gewinnen, zum Beispiel: Wie viele „Log-Zombie-Seiten“ geben einen 200-Statuscode zurück? 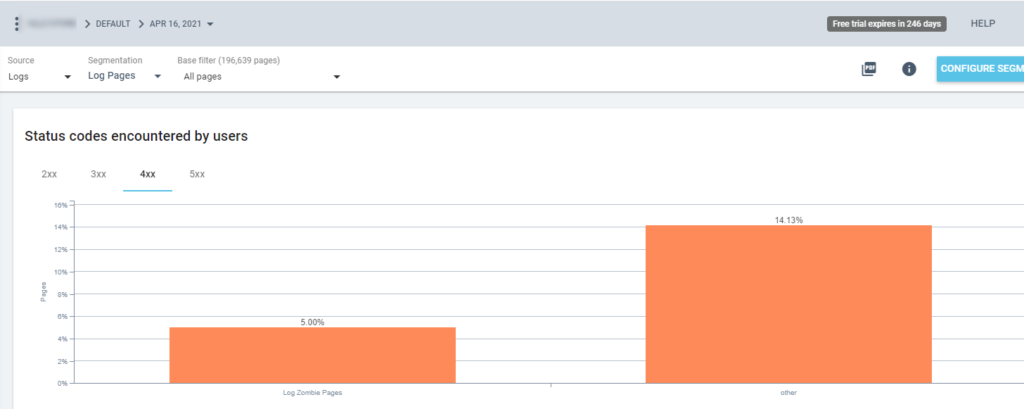
Verwaiste Seiten
Für mich sind die „verwaisten Seiten“, die es wert sind, genau betrachtet zu werden, all die Seiten, die einen hohen Wert für wichtige Metriken haben (GA-Sitzung, GSC-Impression, Protokolltreffer, …), die keine internen Links haben, die auf sie verweisen, um den Seitenrang zu teilen und geben Sie die Wichtigkeit der Seite an.
Wie bei den „Zombie-Seiten“ ist es am besten, eine neue Segmentierung zu erstellen, um einen protokollbasierten Bericht zu erstellen. 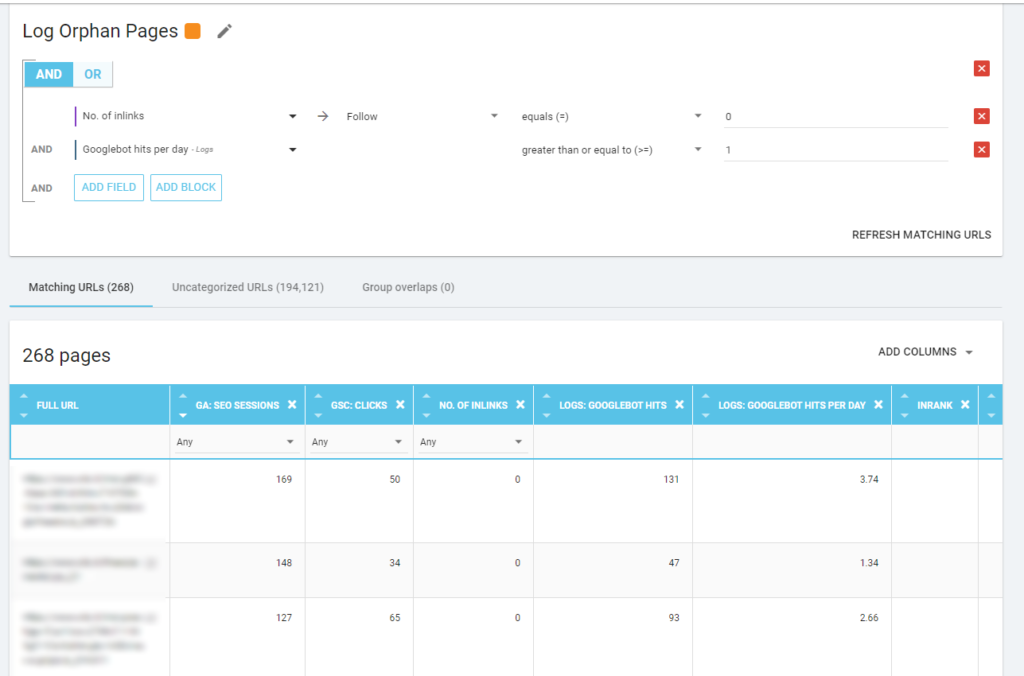
WOW, was für viele Seiten mit Sessions und Hits und ohne Inlinks!
Achten Sie bei der Überprüfung eines Berichts auf Basis von „Zero Follow Inlinks“ bitte auf den Crawling-Status: Konnte Oncrawl die gesamte Website crawlen oder nur wenige Seiten? Sie können dies auf der Hauptseite des Projekts sehen: 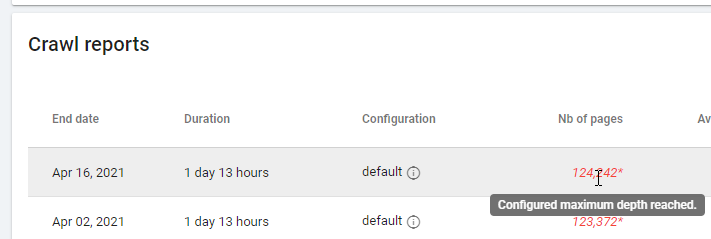
Wenn die maximale Tiefe erreicht ist:

- Überprüfen Sie Ihre Crawling-Konfiguration
- Überprüfen Sie Ihre Seitenstruktur
Protokolldateien und Oncrawl
Was bietet Oncrawl in seinen Standard-Dashboards?
Live-Protokoll
Dieses Dashboard ist nützlich, um wichtige Informationen darüber zu überprüfen, wie Bots Ihre Websites lesen, sobald die Bots die Website besuchen und bevor die Informationen aus den Protokolldateien vollständig verarbeitet sind. Um das Beste daraus zu machen, empfehle ich, Protokolldateien häufig hochzuladen: Sie können dies über FTP, über Konnektoren wie den für Amazon S3 oder manuell über die Weboberfläche tun.
Das erste Diagramm zeigt, wie oft Ihre Website gelesen wird und von welchem Bot. In dem Beispiel, das Sie unten sehen können, können wir Desktop- und mobile Zugriffe überprüfen. In diesem Fall haben wir die nur für Googlebot gefilterten Protokolldateien an Oncrawl gesendet: 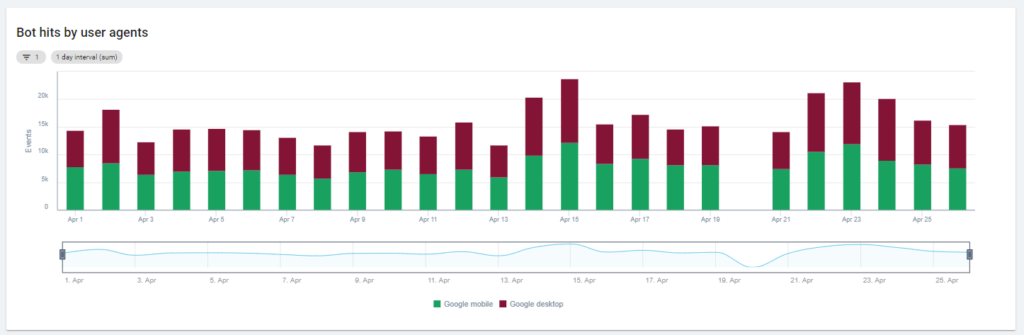
Es ist interessant zu sehen, dass die Anzahl der mobilen Lesevorgänge immer noch sehr hoch ist: Ist das normal? Das kommt darauf an… Die Website, die wir analysieren, befindet sich immer noch im „Mobile-First-Index“, aber es ist keine vollständig responsive Website: Es ist eine Website mit dynamischer Bereitstellung (wie Google sie nennt) und Google überprüft immer noch beide Versionen!
Ein weiteres interessantes Diagramm ist „Bot-Treffer nach Seitengruppe“. Standardmäßig erstellt Oncrawl Gruppen basierend auf URL-Pfaden. Aber wir können Gruppen manuell festlegen, um die URLs zu gruppieren, die für eine gemeinsame Analyse am sinnvollsten sind. 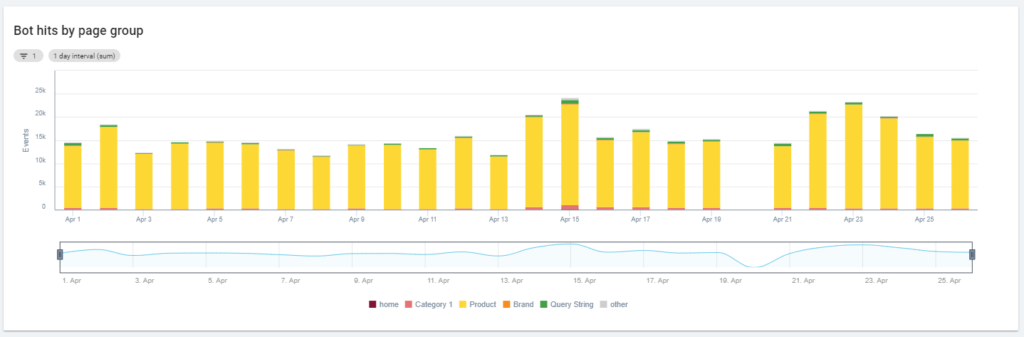
Wie Sie sehen können, gewinnt das Gelb! Es stellt URLs mit einem Produktpfad dar, daher ist es normal, dass es eine so große Wirkung hat, insbesondere da wir bezahlte Google-Shopping-Kampagnen haben.
Und… ja, wir haben gerade bestätigt, dass Google den Standard-Googlebot verwendet, um den Produktstatus im Zusammenhang mit dem Händler-Feed zu überprüfen!
Kriechverhalten
Dieses Dashboard zeigt ähnliche Informationen wie „Live-Protokoll“, aber diese Informationen wurden vollständig verarbeitet und nach Tag, Woche oder Monat aggregiert. Hier können Sie einen Datumszeitraum (Beginn/Ende) festlegen, der beliebig weit zurückgehen kann. Es gibt zwei neue Diagramme zur weiteren Protokollanalyse:
- Crawl-Verhalten: um das Verhältnis zwischen gecrawlten Seiten und neu gecrawlten Seiten zu überprüfen
- Crawling-Frequenz pro Tag
Am besten lesen Sie diese Diagramme, indem Sie die Ergebnisse mit Site-Aktionen verbinden:
- Hast du Seiten verschoben?
- Haben Sie einige Abschnitte aktualisiert?
- Haben Sie neue Inhalte veröffentlicht?
SEO-Auswirkung
Für SEO ist es wichtig zu überwachen, ob optimierte Seiten von Bots gelesen werden oder nicht. Wie wir über „verwaiste Seiten“ geschrieben haben, ist es wichtig sicherzustellen, dass die wichtigsten/aktualisiertesten Seiten von Bots gelesen werden, damit die aktuellsten Informationen für Suchmaschinen verfügbar sind, um ein Ranking zu erzielen.
Oncrawl verwendet das Konzept der „aktiven Seiten“, um die Seiten anzugeben, die organischen Traffic von den Suchmaschinen erhalten. Ausgehend von diesem Konzept zeigt es einige grundlegende Zahlen, wie zum Beispiel:
- SEO-Besuche
- SEO-aktive Seiten
- SEO-Aktivverhältnis (der Anteil aktiver Seiten an allen gecrawlten Seiten)
- Fresh Rank (die durchschnittliche Zeit, die zwischen dem ersten Lesen der Seite durch den Bot und dem ersten organischen Besuch vergeht)
- Aktive Seiten nicht gecrawlt
- Neu aktive Seiten
- Crawling-Frequenz pro Tag aktiver Seiten
Gemäß der Philosophie von Oncrawl können wir mit einem einzigen Klick tief in den Informationssee eintauchen, gefiltert nach der Metrik, auf die wir geklickt haben! Zum Beispiel: Welche aktiven Seiten werden nicht gecrawlt? Ein Klick… 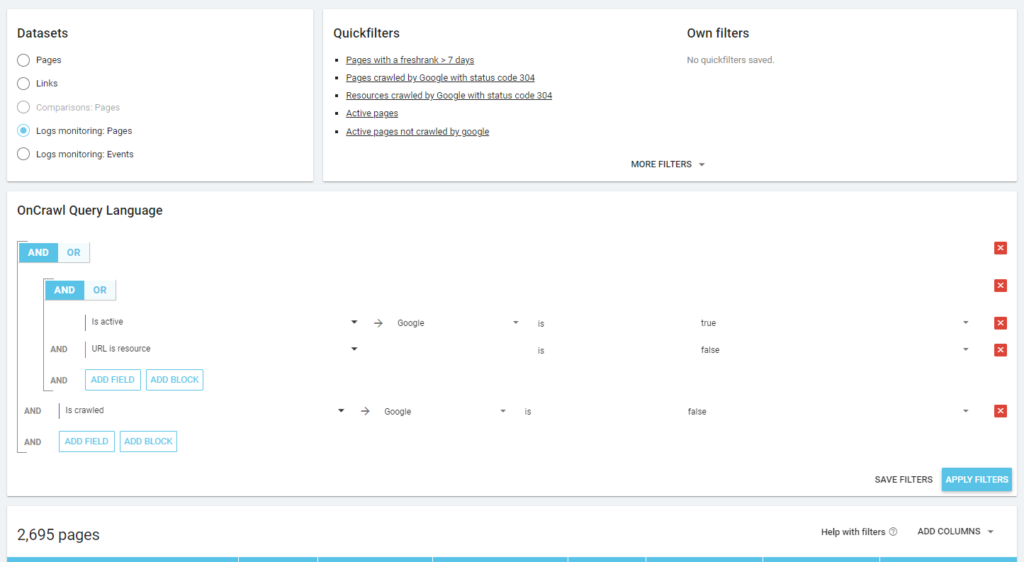
Erforschung Vernunft
Dieses letzte Dashboard ermöglicht es uns, die Qualität des Bo-Crawlings zu überprüfen, oder genauer gesagt, wie gut sich die Website den Suchmaschinen präsentiert:
- Statuscodeanalyse
- Statuscodeanalyse pro Tag
- Statuscodeanalyse nach Seitengruppe
- Reaktionszeitanalyse
Für gute SEO-Arbeit ist es zwingend erforderlich:
- Reduzieren Sie die Anzahl der 301-Antworten von internen Links
- Entfernen Sie die 404/410-Antworten von internen Links
- Optimieren Sie die Antwortzeit, da die Crawling-Qualität des Googlebots direkt mit der Antwortzeit zusammenhängt: Versuchen Sie, die Antwortzeit auf Ihrer Website um die Hälfte zu reduzieren, und Sie werden sehen (in wenigen Tagen), dass sich die Anzahl der gecrawlten Seiten verdoppelt.
Die Wissenschaft der Protokollanalyse und der Datenexplorer von Oncrawl
Bisher haben wir die standardmäßigen Oncrawl-Berichte gesehen und wie man sie verwendet, um benutzerdefinierte Informationen über Segmentierungen und Seitengruppen zu erhalten.
Aber der Kern der Protokollanalyse besteht darin, zu verstehen, wie man einen Fehler findet. Normalerweise ist der Ausgangspunkt der Analyse, Peaks zu überprüfen und sie mit dem Verkehr und mit Ihren Zielen zu vergleichen:
- am häufigsten gecrawlte Seiten
- am wenigsten gecrawlte Seiten
- am häufigsten gecrawlte Ressourcen (nicht Seiten)
- Crawling-Frequenzen nach Dateityp
- Auswirkungen der Statuscodes 3xx / 4xx
- Auswirkungen von 5xx-Statuscodes
- langsamer gecrawlte Seiten
- …
Willst du tiefer gehen? Gut … Sie müssen Daten hinzufügen. Und Oncrawl bietet ein wirklich leistungsstarkes Tool wie den Data Explorer.
Wie Sie in einem vorherigen Screenshot sehen können (aktive Seiten nicht gecrawlt), können Sie alle gewünschten Berichte basierend auf Ihrem Analyse-Framework erstellen.
Zum Beispiel:
- schlechteste organische Traffic-Seiten mit viel Crawling durch Bots
- beste organische Traffic-Seiten mit zu viel Crawling durch Bots
- langsamere Seiten mit vielen SERP-Impressionen
- …
Unten sehen Sie, wie ich überprüft habe, welche Seiten am häufigsten gecrawlt werden, bezogen auf die Anzahl der SEO-Sitzungen: 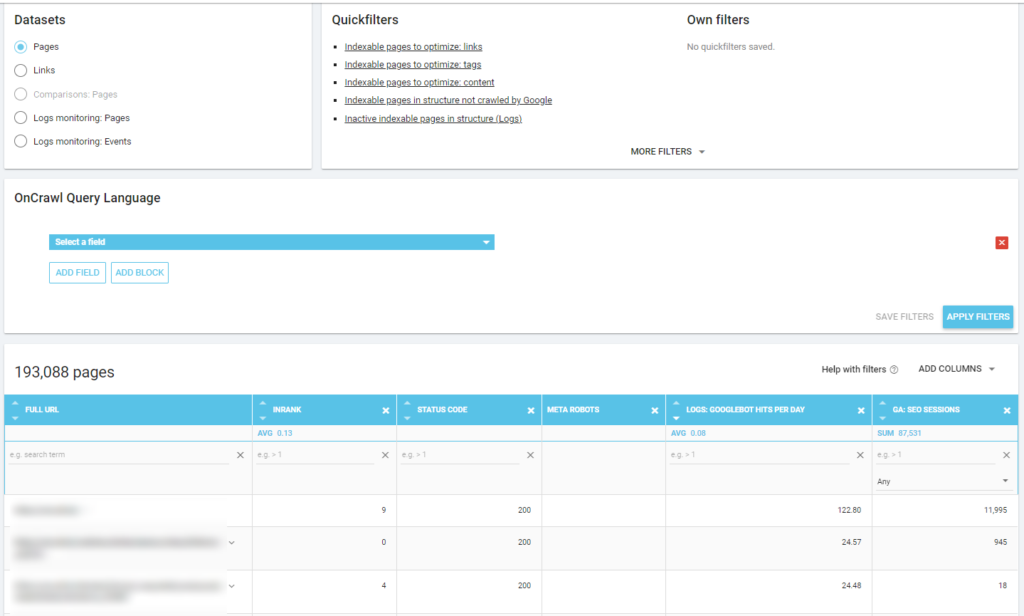
Imbiss
Die Protokollanalyse ist nicht rein technisch: Um sie bestmöglich durchzuführen, müssen wir technische Fähigkeiten, SEO-Kenntnisse und Marketingkenntnisse kombinieren.
Zu oft wird eine Analyse von einer „SEO-Checkliste“ ausgeschlossen, weil unser Kunde keinen Zugriff auf Logfiles hat oder weil es eine kostspielige Analyse sein kann.
Die Realität ist, dass die Protokolle die einzigen Quellen sind, um wirklich zu überprüfen, wohin sich Bots auf unseren Websites bewegen, und um zu wissen, wie unsere Server darauf reagieren.
Ein Tool wie Oncrawl kann die technischen Anforderungen stark reduzieren: Einfach die Logfiles hochladen und mit der Analyse beginnen!