
استخدام Python و Sitemap لتدقيق إستراتيجيات المحتوى
نشرت: 2020-10-08لم يعد الاهتمام بما يمكن القيام به بالنيابة عن تحسين محركات البحث باستخدام مكتبات Python سراً. ومع ذلك ، فإن معظم الأشخاص الذين لديهم خبرة قليلة في البرمجة يواجهون صعوبات في استيراد واستخدام عدد كبير من المكتبات أو دفع النتائج التي تتجاوز ما يمكن أن يفعله أي برنامج زاحف عادي أو أداة تحسين محركات البحث.
هذا هو السبب في أن مكتبة Python التي تم إنشاؤها خصيصًا لـ SEO و SEM و SMO و SERP والتحليل المحتوى مفيدة للجميع.
في هذه المقالة ، سوف نلقي نظرة على بعض الأشياء التي يمكن القيام بها باستخدام مكتبة Advertools Python لتحسين محركات البحث ، التي أنشأها وطورها إلياس دباس ، والتي أرى لها إمكانات كبيرة في تحسين محركات البحث وإمكانيات الدفع لكل نقرة (PPC) والتشفير. في وقت قصير جدا. أيضًا ، سنستخدم نصوص Python المخصصة جنبًا إلى جنب مع مكتبات Python الأخرى بطريقة تعليمية وقابلة للتكيف.
سنقوم بفحص ما يمكن تعلمه لتحسين محركات البحث من ملف Sitemap بفضل وظيفة Sitemap_to_df الخاصة بـ Elias Dabbas والتي تساعد في تنزيل وتحليل خرائط مواقع XML (خريطة الموقع هي مستند بتنسيق XML يُستخدم للإبلاغ عن عناوين URL القابلة للزحف والفهرسة إلى محركات البحث.)
ستوضح لك هذه المقالة كيف يمكنك كتابة أكواد Python المخصصة لتحليل مواقع الويب المختلفة وفقًا لبنيتها المختلفة ، وكيفية تفسير البيانات من حيث تحسين محركات البحث ، وكيفية التفكير كمحرك بحث عندما يتعلق الأمر بملفات تعريف المحتوى وعناوين URL وهياكل المواقع .
تحليل مقياس محتوى موقع الويب وإستراتيجيته بناءً على خريطة موقعه
ملف Sitemap هو أحد مكونات موقع الويب الذي يمكنه التقاط العديد من أنواع البيانات المختلفة ، مثل عدد المرات التي ينشر فيها موقع الويب المحتوى ، وفئات المحتوى ، وتواريخ النشر ، ومعلومات المؤلف ، وموضوع المحتوى ...
في ظل الظروف العادية ، يمكنك كشط ملف Sitemap باستخدام scrapy ، وتحويله إلى DataFrame باستخدام Pandas ، وتفسيره مع العديد من المكتبات المساعدة المختلفة إذا كنت تريد ذلك.
لكن في هذه المقالة ، سنستخدم فقط Advertools وبعض أساليب وسمات مكتبة Pandas. سيتم تنشيط بعض المكتبات لتصور البيانات التي حصلنا عليها.
دعنا نتعمق في موقع ويب ونختاره لاستخدام خريطة الموقع الخاصة به لاستنتاج بعض رؤى تحسين محركات البحث المهمة.
استخراج وإنشاء إطارات البيانات من خرائط المواقع باستخدام Advertools
في Advertools ، يمكنك اكتشاف جميع خرائط مواقع موقع الويب وتصفحها ودمجها بسطر واحد فقط من التعليمات البرمجية.
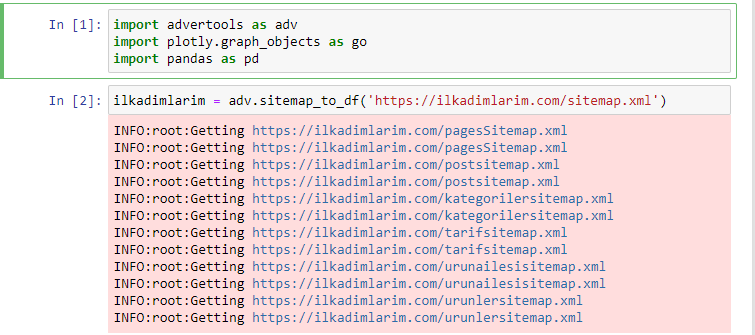
أحب استخدام Jupyter Notebook بدلاً من محرر الكود العادي أو IDE.
في الخلية الأولى ، قمنا باستيراد Pandas و Advertools لجمع وتنظيم البيانات و Plotly.graph_objects للبيانات المرئية.
يقوم الأمر adv.sitemap_to_df ("عنوان خريطة الموقع") بجمع كل خرائط المواقع وتوحيدها كإطار بيانات.
إذا كنت تفعل الشيء نفسه باستخدام Pandas و Advertools ، فيمكنك اكتشاف عنوان URL المتاح في أي خريطة موقع.
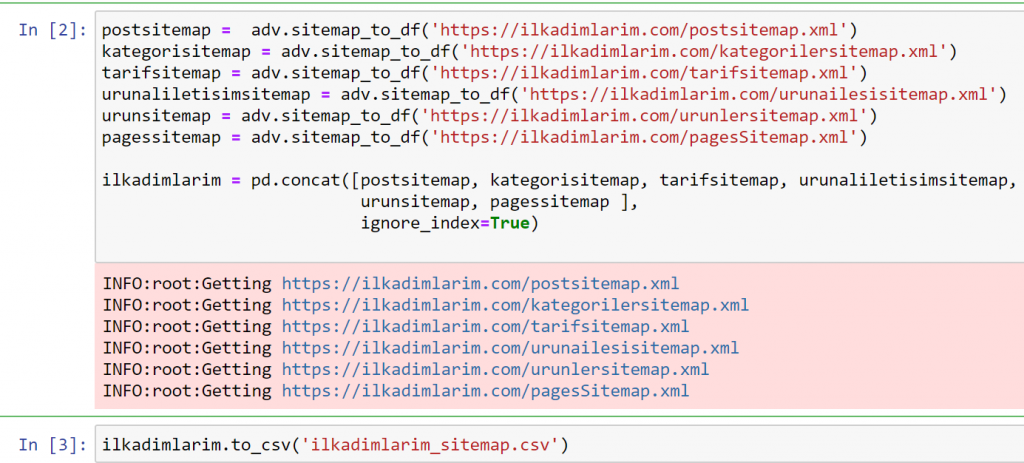
في المثال أعلاه ، قمنا بسحب خرائط المواقع نفسها بشكل منفصل ثم دمجناها مع الأمر pd.concat ونقلنا النتيجة إلى CSV. استخدم المثال السابق ملف فهرس خرائط الموقع ، وفي هذه الحالة تنتقل الوظيفة لاسترداد جميع خرائط المواقع الأخرى. لذلك لديك خيار تحديد خرائط مواقع محددة كما فعلنا هنا إذا كنت مهتمًا بقسم معين من الموقع.
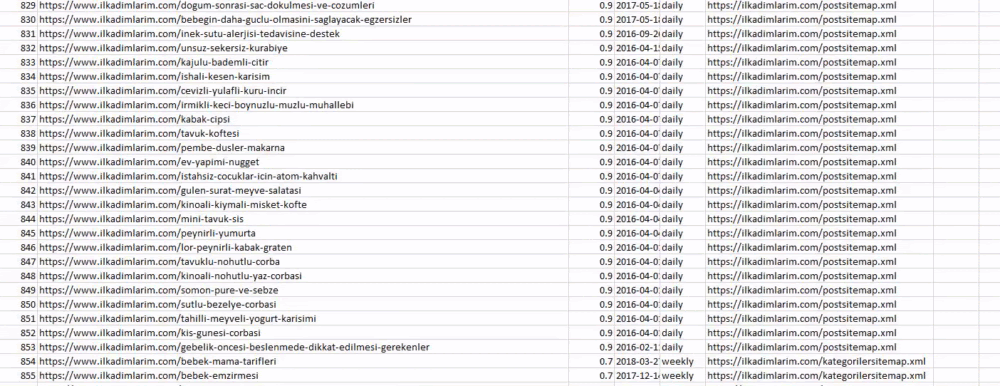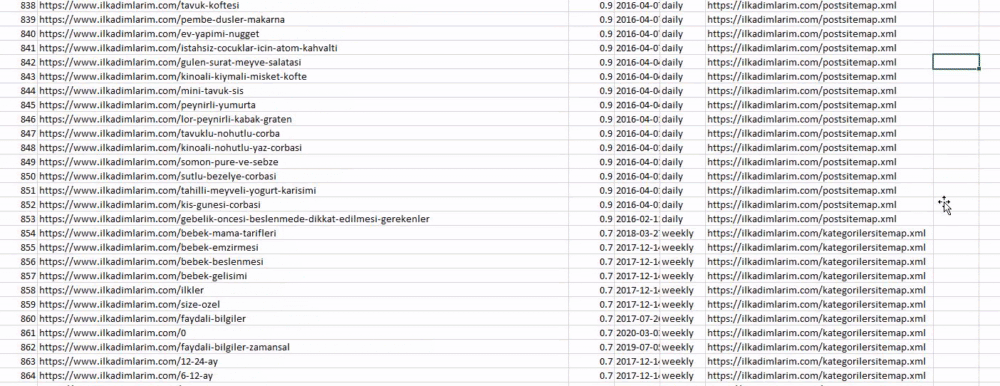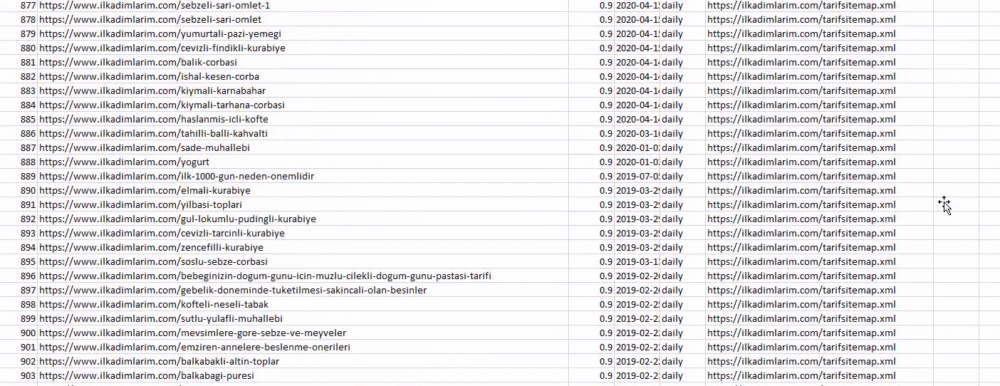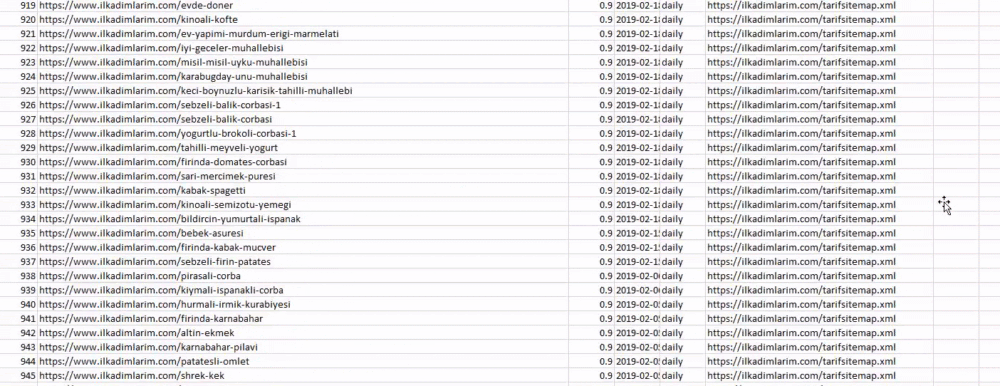
يمكنك رؤية عمود بأسماء خرائط مواقع مختلفة أعلاه. ignore_index = القسم الحقيقي مخصص للترتيب الدقيق لأرقام الفهرس الخاصة بإطارات البيانات المختلفة ، إذا قمت بدمج عدة أرقام معًا.
بيانات عند الزحف³
 يتعلم أكثر
يتعلم أكثرتنظيف وإعداد إطار بيانات خريطة الموقع لتحليل المحتوى باستخدام بايثون
لفهم ملف تعريف محتوى موقع ويب من خلال خريطة موقع ، نحتاج إلى إعداده من أجل مراجعة DataFrame الذي حصلنا عليه باستخدام Advertools.
سنستخدم بعض الأوامر الأساسية من مكتبة Pandas لتشكيل بياناتنا:
Ilkadimlarim = pd.read_csv ('ilkadimlarim_sitemap.csv')
ilkadimlarim = ilkadimlarim.drop (الأعمدة = 'لم يذكر اسمه: 0')
ilkadimlarim ['lastmod'] = pd.to_datetime (ilkadimlarim ['lastmod'])
ilkadimlarim = ilkadimlarim.set_index ('lastmod')
"Ilkadimlarim" تعني "خطواتي الأولى" باللغة التركية ، وكما يمكنك أن تتخيل ، فهي موقع للأطفال والحمل والأمومة.
لقد أجرينا ثلاث عمليات مع هذه الخطوط.
- لم يذكر اسمه: قمنا بإزالة عمود فارغ يسمى 0 من DataFrame. أيضًا ، إذا كنت تستخدم "index = False" مع وظيفة pd.to_csv () ، فلن ترى هذا العمود "بدون اسم 0" في البداية.
- قمنا بتحويل البيانات الموجودة في عمود "آخر تعديل" إلى "وقت التاريخ".
- قمنا بإحضار عمود "lastmod" إلى موضع الفهرس.
أدناه يمكنك مشاهدة الإصدار النهائي من DataFrame.
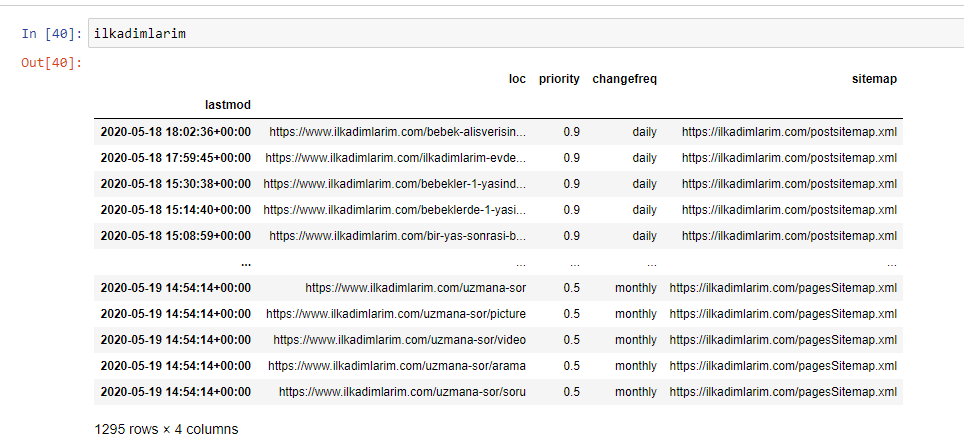
نحن نعلم أن Google لا تستخدم الأولوية وتغير معلومات التردد من خرائط المواقع. يسمونه "كيس الضوضاء". ولكن إذا أعطيت أهمية لأداء موقع الويب الخاص بك لمحركات البحث الأخرى ، فقد تجد أنه من المفيد فحصها أيضًا. أنا شخصياً لا أهتم كثيراً بهذه البيانات ، لكنني ما زلت بحاجة إلى إزالتها من DataFrame.
نحتاج إلى سطر رمز آخر لتصنيف خرائط المواقع في عمود آخر.
ilkadimlarim ['sitemap_cat'] = ilkadimlarim ['sitemap']. str.split ('/'). str [3]
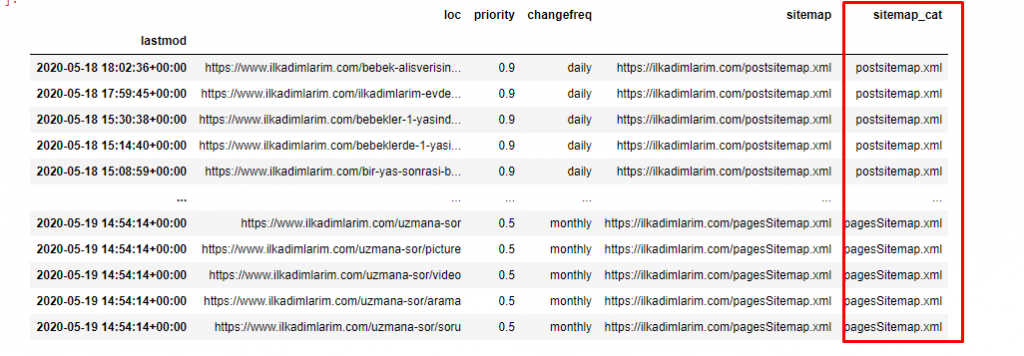
في Pandas ، يمكنك إضافة أعمدة أو صفوف جديدة إلى DataFrame أو يمكنك تحديثها بسهولة. لقد أنشأنا عمودًا جديدًا باستخدام مقتطف رمز DataFrame ['new_columns'] . يسمح لنا DataFrame ['اسم_العمود']. str بإجراء عمليات مختلفة عن طريق تغيير نوع البيانات في العمود. نقسم بيانات السلسلة في العمود المرتبط بـ .split ('/') على الحرف / ونضعها في قائمة. باستخدام .str [number] ، نقوم بإنشاء محتويات العمود الجديد عن طريق تحديد عنصر معين في تلك القائمة.
تحليل ملف تعريف المحتوى وفقًا لعدد ملفات Sitemap وأنواعها
بعد وضع خرائط المواقع في عمود مختلف وفقًا لأنواعها ، يمكننا التحقق من النسبة المئوية للمحتويات في كل خريطة موقع. وبالتالي ، يمكننا أيضًا أن نستنتج أي جزء من الموقع هو الأكثر أهمية.
ilkadimlarim ['sitemap_cat']. value_counts (normalize = True) * 100
- يقوم DataFrame ['اسم_العمود'] بتحديد العمود الذي نريد إجراء عملية.
- تحسب value_counts () تكرار القيم في العمود.
- تطبيع = تأخذ True نسبة القيم في النظام العشري.
- نجعل القراءة أسهل بجعل الأرقام العشرية أكبر باستخدام * 100.
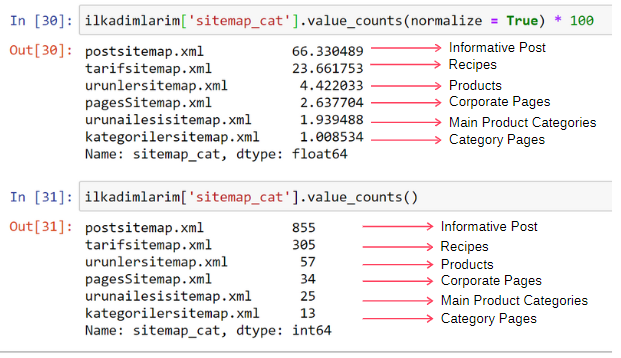
نرى أن 65٪ من المحتوى موجود في Post Sitemap و 23٪ في ملف Sitemap للوصفة. تحتوي خريطة موقع المنتج على 2٪ فقط من المحتوى.
هذا يدل على أن لدينا موقعًا على شبكة الإنترنت يجب عليه إنشاء محتوى إعلامي لجمهور عريض لتسويق منتجاته الخاصة. دعنا نتحقق مما إذا كانت أطروحتنا صحيحة.
قبل المتابعة ، نحتاج إلى تغيير اسم عمود ilkadimlarim ['sitemap_cat'] إلى "URL_Count" بالرمز أدناه:
ilkadimlarim.rename (الأعمدة = {'sitemap_cat': 'URL_Count'}، inplace = True)
- تعد وظيفة rename () مفيدة لتعديل اسم الأعمدة أو الفهارس لتوصيل البيانات ومعناها على مستوى أعمق.
- لقد قمنا بتغيير اسم العمود ليكون دائمًا بفضل السمة "inplace = True" .
- يمكنك أيضًا تغيير أنماط أحرف الأعمدة والفهارس باستخدام ilkadimlarim.rename (str.capitalize ، محور = "أعمدة" ، inplace = True) . يؤدي هذا إلى كتابة الأحرف الأولى فقط كأحرف كبيرة في كل عمود في Ilkadimlarim.

الآن ، يمكننا المضي قدما.
لرؤية هذه المعلومات في إطار واحد ، يمكنك استخدام الكود أدناه:
(ilkadimlarim ['sitemap_cat']
.value_counts ()
.لتأطير()
.assign (النسبة المئوية = lambda df: df ['sitemap_cat']. div (df ['sitemap_cat']. sum ()))
.style.format (ict (sitemap_cat = '{:،}'، النسبة المئوية = '{:. 1٪}')))
- to_frame () لإطار القيم المقاسة بواسطة value_counts () في العمود المحدد.
- تعيين () يستخدم لإضافة قيم معينة إلى الإطار.
- تشير لامدا إلى وظائف مجهولة في بايثون.
- هنا ، يتم تقسيم وظيفة Lambda وأنواع ملفات Sitemap على إجمالي عدد خريطة الموقع بواسطة طريقة Pandas div () .
- يحدد style () كيفية كتابة القيم النهائية المحددة.
- هنا ، قمنا بتعيين عدد الأرقام المكتوبة بعد الفترة باستخدام طريقة format () .
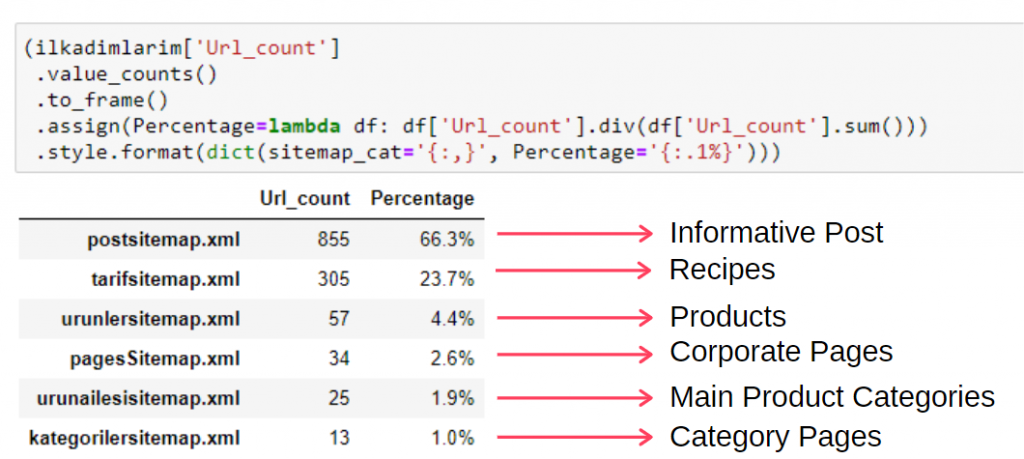
وبالتالي فإننا نرى أهمية تسويق المحتوى لهذا الموقع. يمكننا أيضًا التحقق من اتجاهات نشر مقالاتهم حسب السنة باستخدام سطرين منفصلين من التعليمات البرمجية لفحص وضعهم بشكل أعمق.
فحص اتجاهات نشر المحتوى وتصورها حسب السنة عبر خرائط المواقع و Python
لقد قمنا بمطابقة المحتوى والنية لموقع الويب الذي تم فحصه وفقًا لفئات خريطة الموقع ، لكننا لم نقم بعد بتصنيف يستند إلى الوقت. سوف نستخدم طريقة resample () لإنجاز ذلك.
post_per_month = ilkadimlarim.resample ('A') ['loc']. count ()
post_per_month.to_frame ()
Resample هي طريقة في مكتبة Pandas. resample ("A") يتحقق من سلسلة البيانات لإطار DataFrame سنوي. لأسابيع ، يمكنك استخدام "W" ، ولأشهر يمكنك استخدام "M".
Loc هنا يرمز إلى الفهرس ؛ العد يعني أنك تريد حساب مجموع أمثلة البيانات.
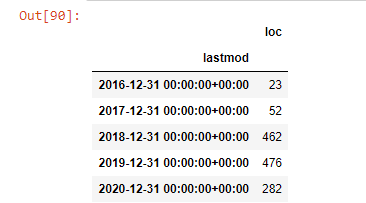
نرى أنهم بدأوا في نشر المقالات في عام 2016 ولكن اتجاه النشر الرئيسي لديهم قد ازداد بعد عام 2017. يمكننا أيضًا وضع هذا في رسم بياني بمساعدة Plotly Graph Objects.
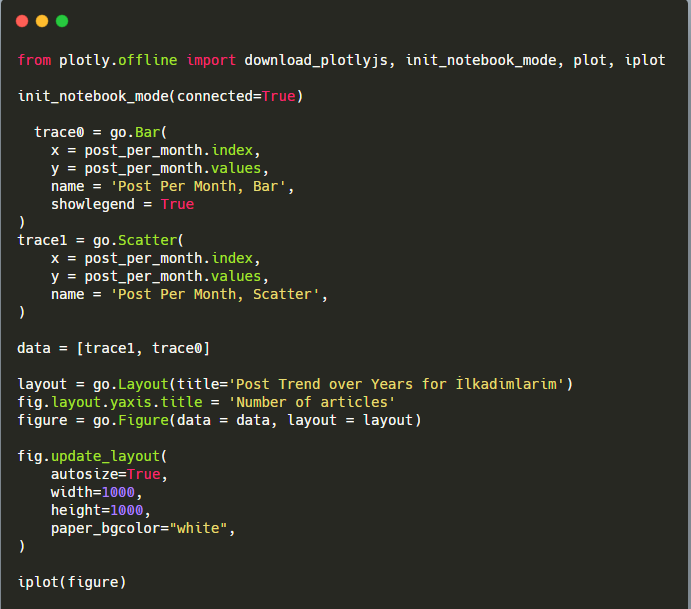
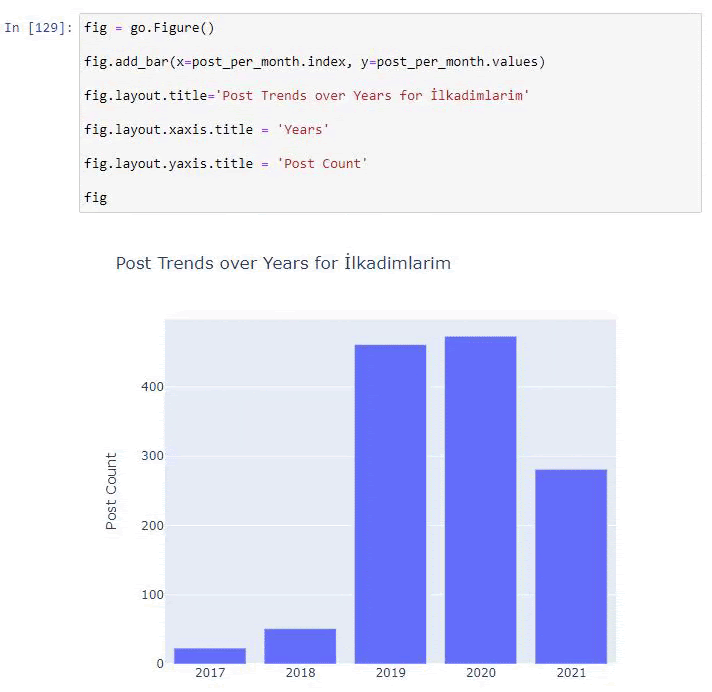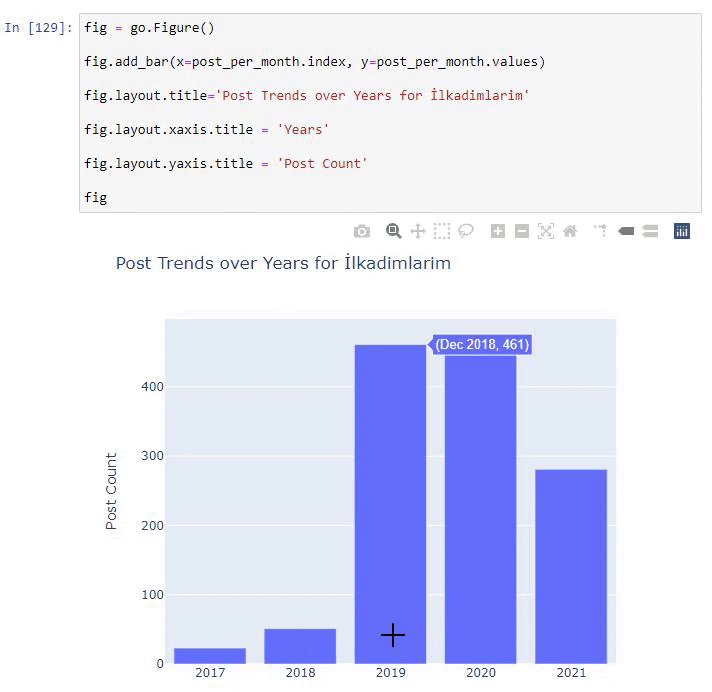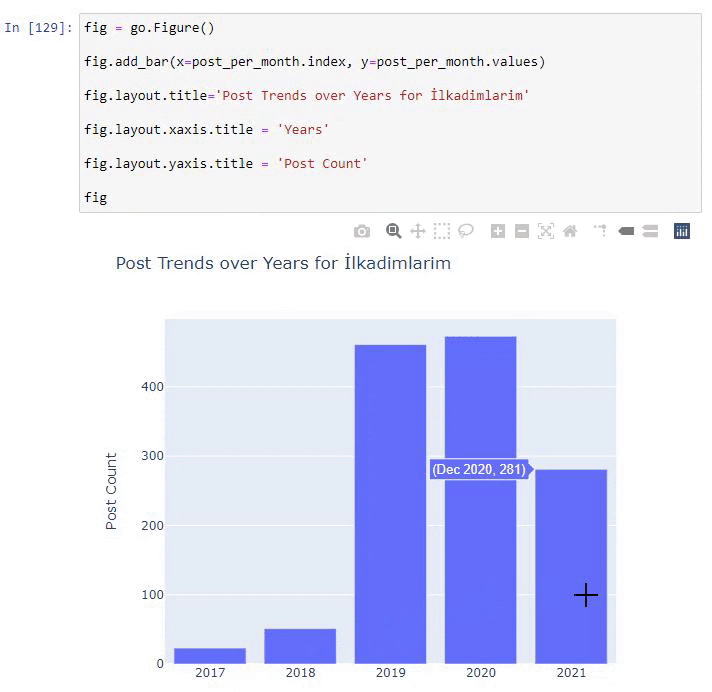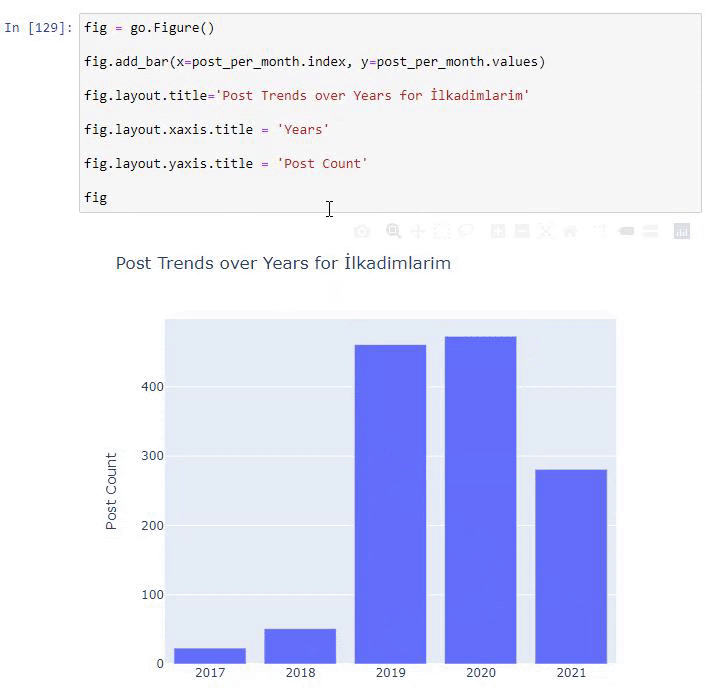
شرح مقتطف رمز Plotly Bar Plot هذا:
- fig = go.Figure () لإنشاء شخصية.
- fig.add_bar () هو إضافة barplot إلى الشكل. نحدد أيضًا ما سيكون المحاور X و Y داخل الأقواس.
- الشكل التوضيحي مخصص لإنشاء عنوان عام للشكل والمحاور.
- في السطر الأخير نسمي الحبكة التي أنشأناها بأمر التين الذي يساوي go.
أدناه ، ستجد نفس البيانات حسب الشهر ، مع scatterplot و barplot:
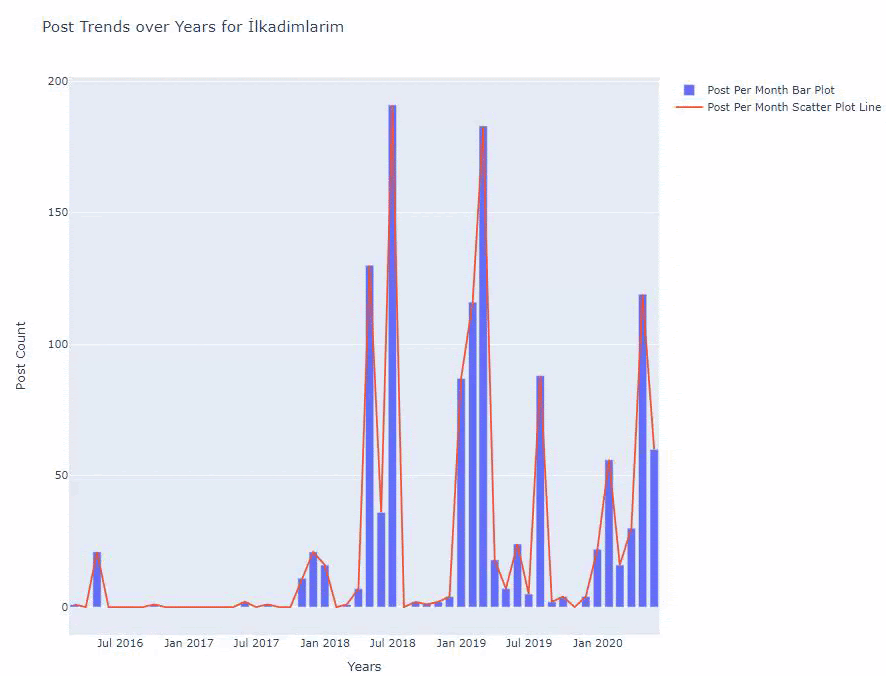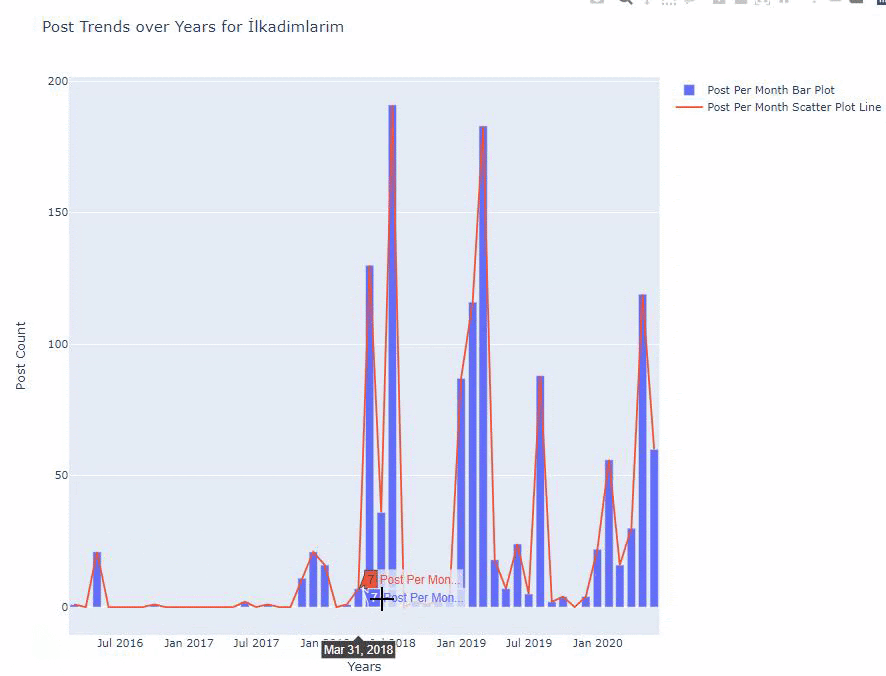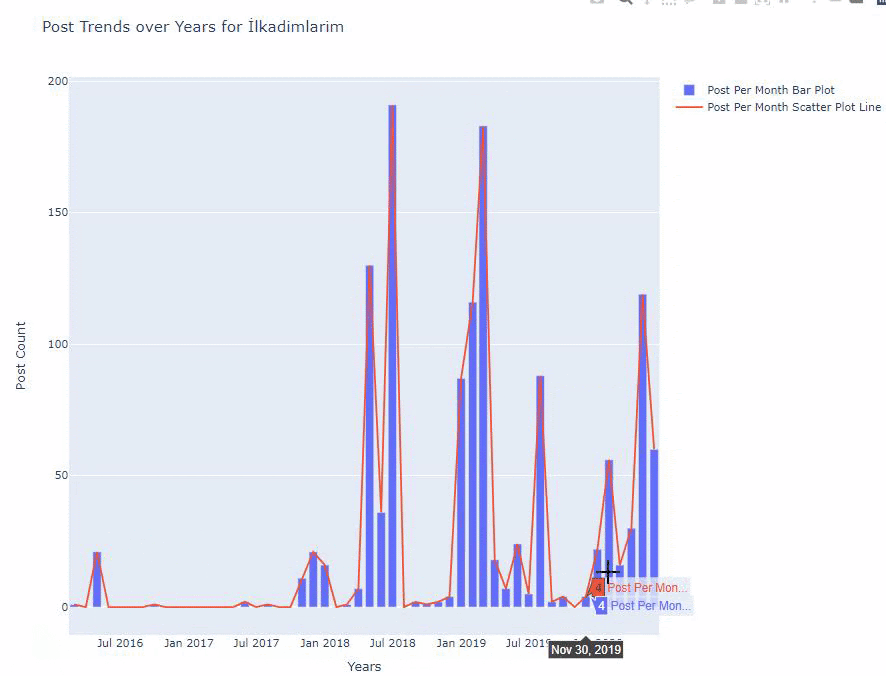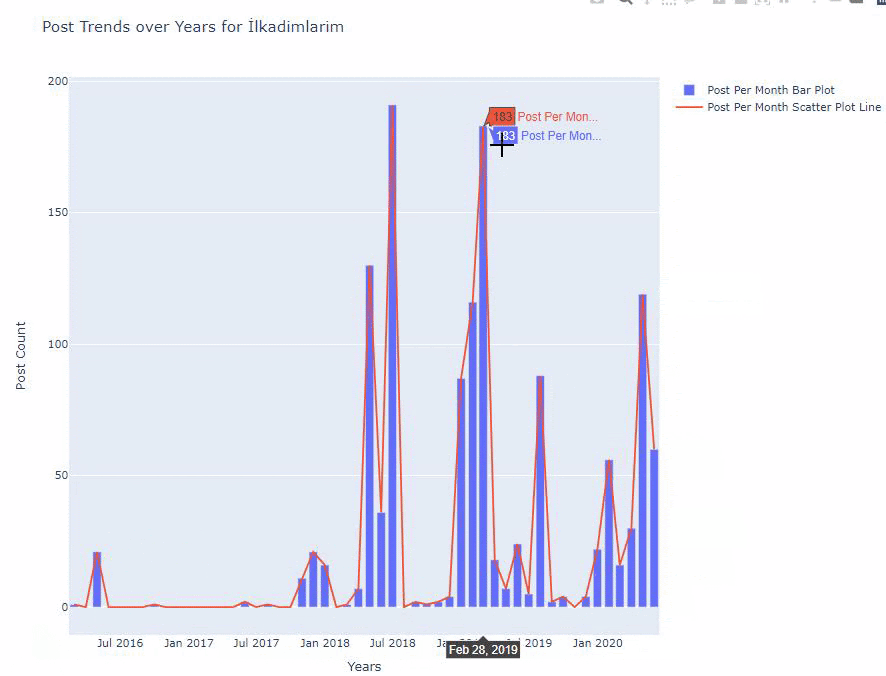
فيما يلي الرموز لإنشاء هذا الشكل:
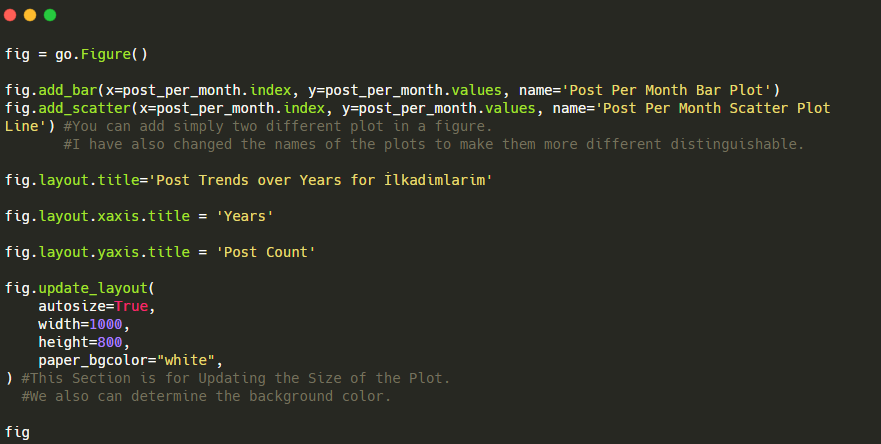
لقد أضفنا مخططًا ثانيًا باستخدام fig.add_scatter () ، وقمنا أيضًا بتغيير الأسماء باستخدام سمة الاسم. fig.update_layout () لتغيير حجم ولون الخلفية للمخطط.
يمكنك أيضًا تغيير وضع التمرير والمسافة بين الأشرطة والمزيد. أعتقد أنه يكفي مشاركة الرموز فقط ، لأن شرح كل رمز هنا بشكل منفصل قد يدفعنا إلى الابتعاد عن الموضوع الرئيسي.
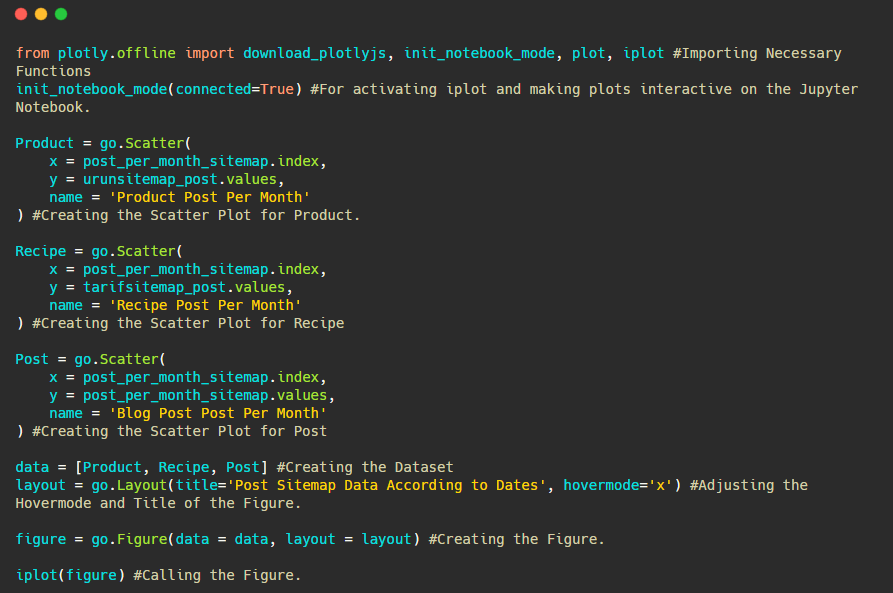
يمكننا أيضًا مقارنة اتجاهات نشر محتوى المنافسين وفقًا للفئات التالية:
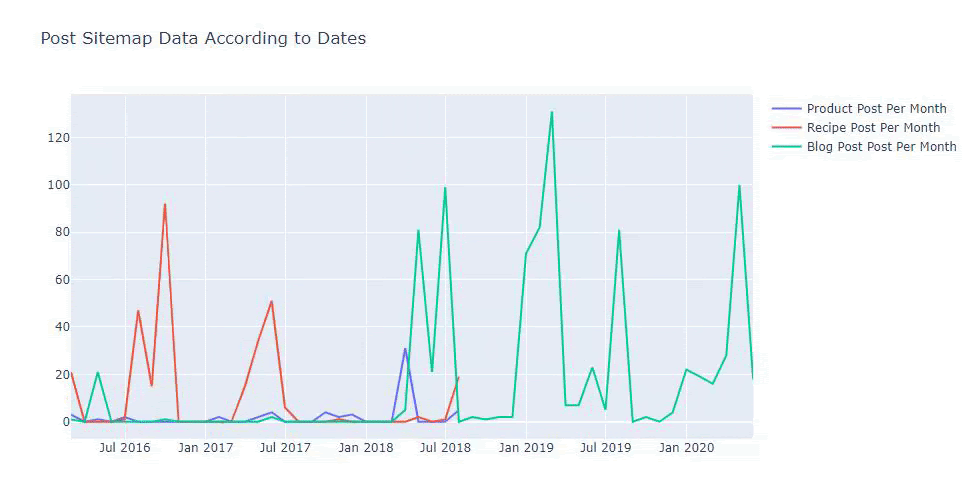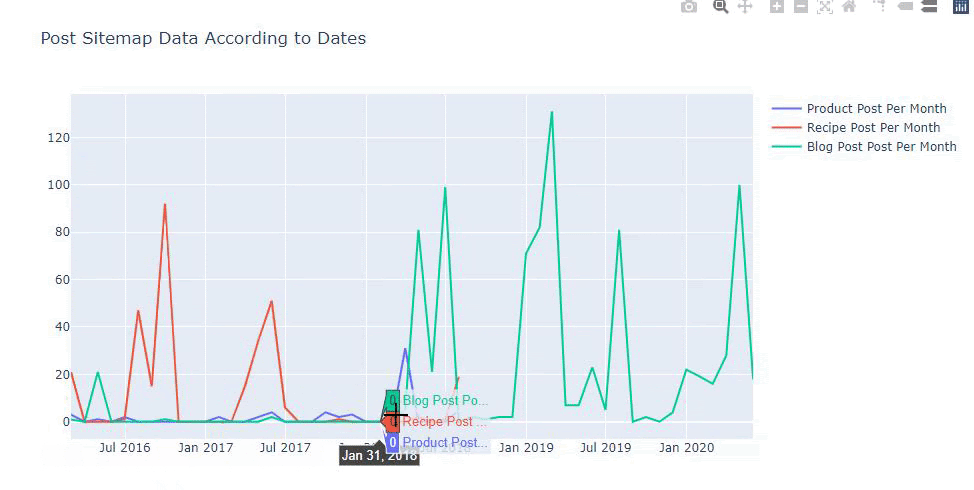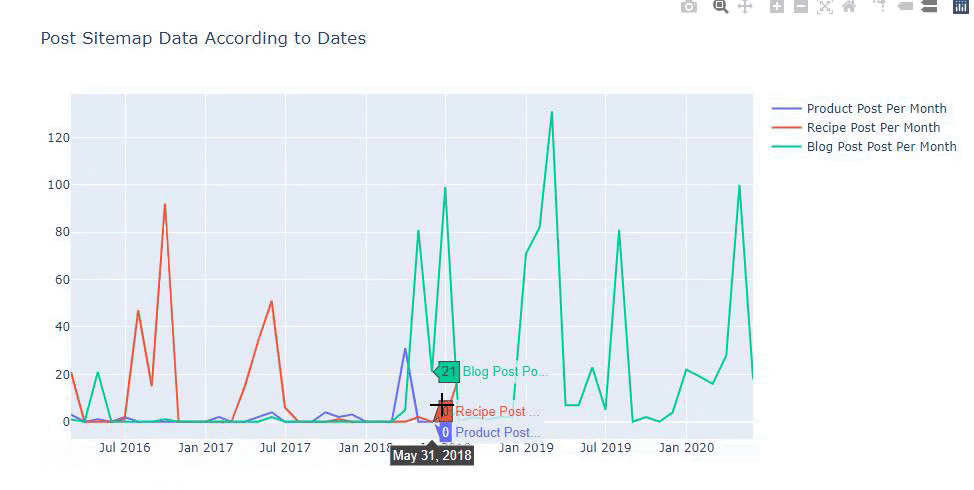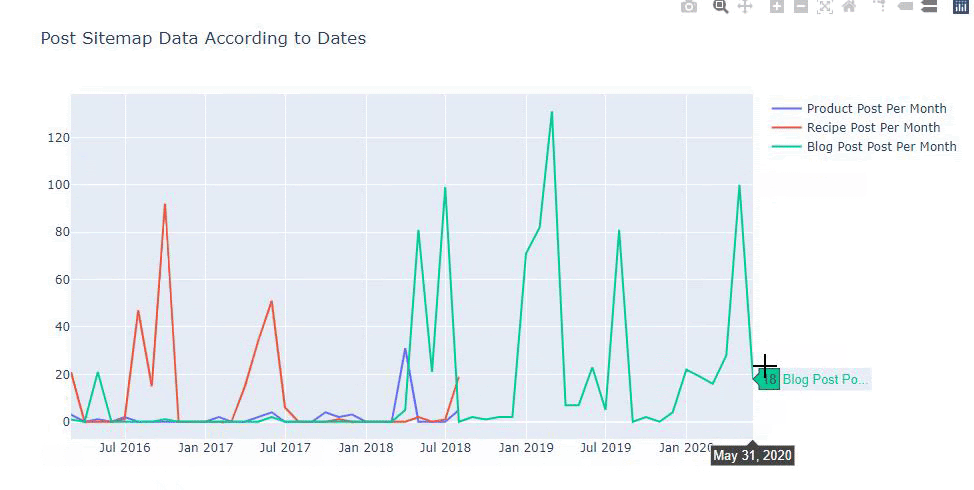
تم إنشاء هذا المخطط بالطريقة الثانية ، كما قد ترى أنه لا يوجد فرق ولكن إحداها بسيط للغاية.
من أجل رسم بياني لتكرار واتجاه نشر المحتوى من ثلاث خرائط مواقع منفصلة ، يجب أن نضع ملف Sitemap ، الذي يحتوي على أطول فترة زمنية ، على المحور X. وبالتالي ، يمكننا مقارنة التردد الذي ينشر به موقع الويب الذي نقوم بفحصه كل نوع مختلف من المحتوى لأغراض البحث المختلفة.
عند فحص الرموز ذات الصلة أدناه ، سترى أنها لا تختلف كثيرًا عما سبق.
لإنشاء مخطط مبعثر بمحاور ص متعددة ، يمكنك استخدام الكود أدناه.
هناك طرق أخرى مثل توحيد خرائط مواقع مختلفة واستخدام حلقة for للأعمدة لاستخدام عدة محاور ص في مخطط مبعثر ولكننا لسنا بحاجة إلى ذلك لموقع صغير كهذا. بالنسبة للجزء الأكبر ، سيكون من المنطقي أكثر استخدام هذه الطريقة على مواقع الويب التي تحتوي على مئات من خرائط المواقع.
أيضًا ، نظرًا لصغر حجم موقع الويب ، فقد يبدو الرسم سطحيًا ، ولكن كما سترى لاحقًا في المقالة على موقع ويب يحتوي على ملايين عناوين URL ، تُعد هذه الرسومات طريقة رائعة لمقارنة المواقع المختلفة وكذلك لمقارنة فئات مختلفة من نفس الموقع.
فحص وتصور فئات المحتوى والنية واتجاهات النشر باستخدام ملفات Sitemap و Python
في هذا القسم ، سوف نتحقق من أنهم كتبوا عددًا كبيرًا من المحتوى في مجال معرفي محدد لتسويق عدد صغير من المنتجات ، وهو ما قلناه في بداية المقال. بفضل هذا ، قد نرى ما إذا كان لديهم شراكة محتوى مع علامات تجارية أخرى أم لا.
لإظهار ما يمكن العثور عليه أيضًا في خرائط المواقع ، سنواصل البحث أكثر قليلاً. يمكننا أيضًا الحصول على بعض المعلومات من الجزء "loc" من خريطة الموقع مثل الأجزاء الأخرى.
لا يوجد تصنيف للفئات في عناوين URL الخاصة بـ Ilkadimlarim. إذا كان موقع الويب يحتوي على تصنيف فئات في عناوين URL الخاصة به ، فيمكننا معرفة المزيد حول توزيع المحتوى. إذا لم يكن الأمر كذلك ، فيمكننا الوصول إلى نفس البيانات عن طريق كتابة رمز إضافي ، ولكن فقط بقدر أقل من اليقين.
في هذه المرحلة ، يمكنك تخيل مقدار الأعطال الأقل تكلفة لعناوين URL التي تجعلها لمحركات البحث التي تزحف إلى مليارات المواقع لفهم موقع الويب الخاص بك.
a = ilkadimlarim ['loc']. str.contains (“bebek | hamile | haftalik”)
بيبيك: حبيبي
هاميل: حامل
هفتاليك: أسبوع أو "أسبوع من الحمل"
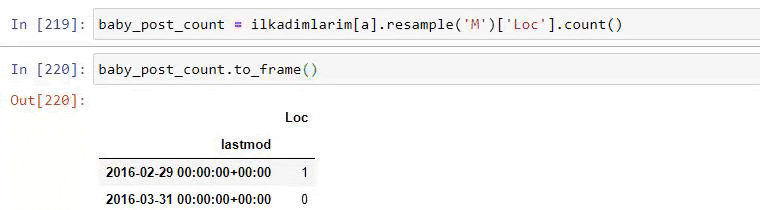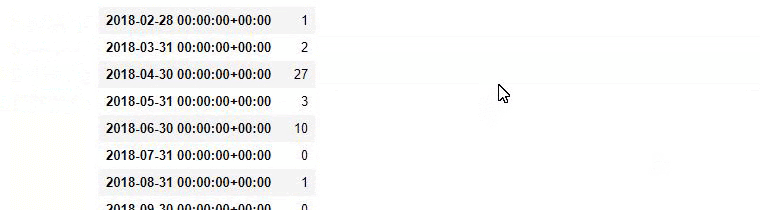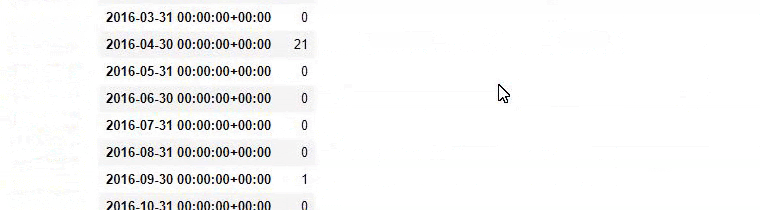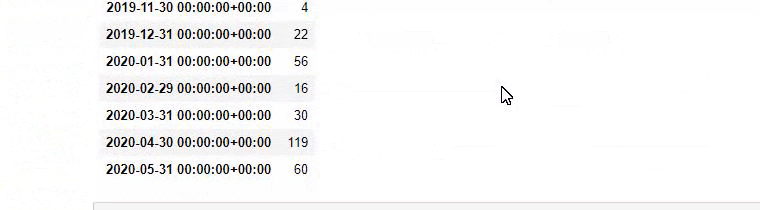
baby_post_count = ilkadimlarim [a] .resample ('M') ['loc']. count ()
baby_post_count.to_frame ()
تسمح لنا طريقة str () هنا مرة أخرى بتعيين العمود حيث نختار عمليات معينة.
باستخدام طريقة contains () ، نحدد البيانات للتحقق مما إذا كانت مضمنة في البيانات المحولة إلى سلسلة.
هنا ، "|" بين المصطلحين يعني "أو" .
ثم نقوم بتعيين البيانات التي قمنا بتصفيتها إلى متغير واستخدمنا طريقة resample () التي استخدمناها سابقًا.
طريقة العد ، من ناحية أخرى ، تقيس البيانات المستخدمة وعدد المرات.
يتم إرفاق النتيجة التي تم الحصول عليها باستخدام count () مرة أخرى مع to_frame () .
أيضًا ، تأخذ str.contains () قيم Regex افتراضيًا ، مما يعني أنه يمكنك إنشاء شروط تصفية أكثر تعقيدًا باستخدام رمز أقل.
بمعنى آخر ، في هذه المرحلة ، نقوم بتعيين عناوين URL التي تحتوي على الكلمات "طفل" ، و "أسبوعي" ، و "حامل" إلى متغير في ilkadimlarim ، ثم نضع تاريخ نشر عناوين URL في الظروف المناسبة لهذا الفلتر. تم إنشاؤها في إطار.
ثم نفعل الشيء نفسه بالنسبة لعناوين URL التي تحتوي على كلمة "aptamil". Aptamil هو اسم أحد منتجات تغذية الأطفال الذي قدمته Ilkadimlarim. لذلك ، يمكننا أيضًا الانتباه إلى كثافة بث المحتوى الإعلامي والتجاري.
وقد ترى مجموعتين مختلفتين من مجموعات المحتوى تنشران جداول زمنية على مدار سنوات من أجل أهداف بحث مختلفة بمزيد من اليقين والمعلومات الدقيقة من عناوين URL.
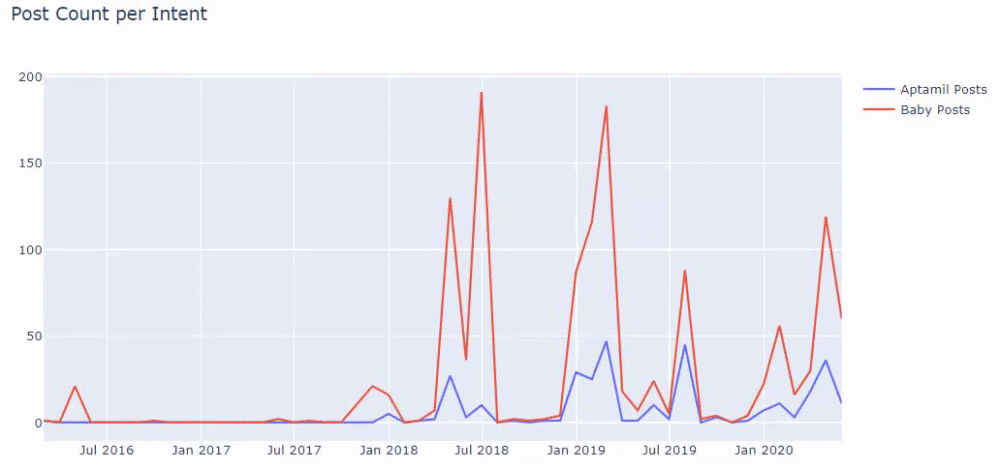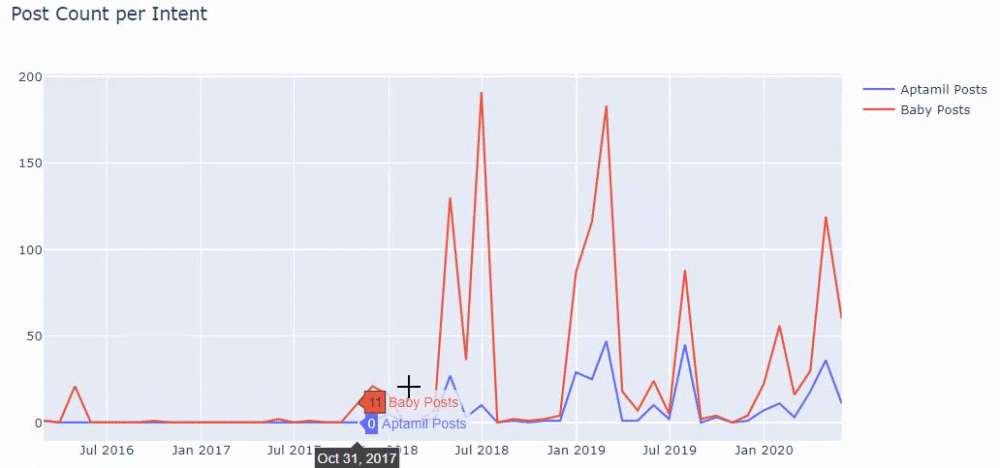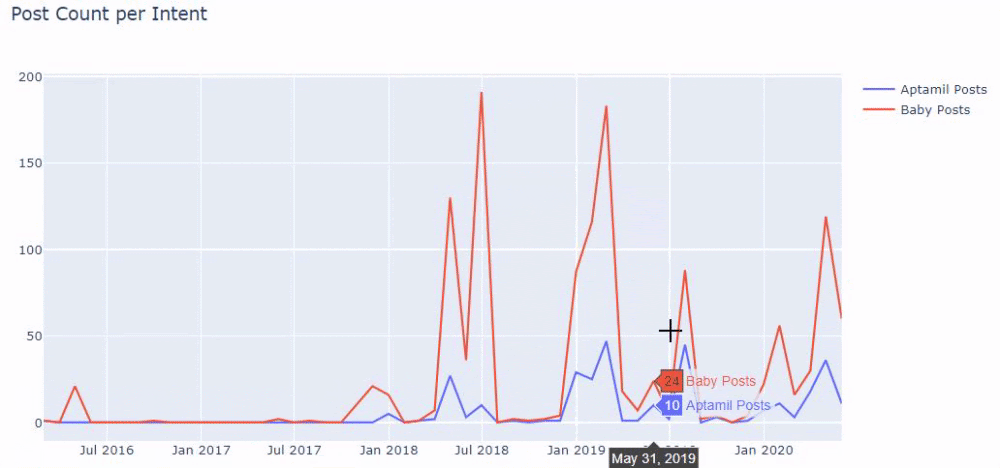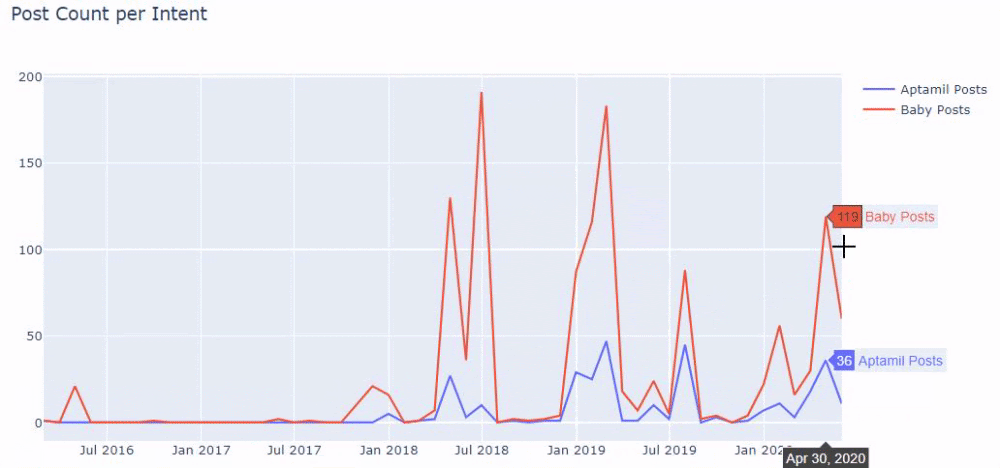
لم تتم مشاركة الكود الخاص بإنتاج هذا المخطط لأنه هو نفسه المستخدم في الرسم البياني السابق
بمساعدة عوامل تشغيل البحث على Google ، أحصل على 38 نتيجة عندما أريد الصفحات التي يتم فيها استخدام كلمة Aptamil في نص الرابط في Ilkadimlarim.com. عدد كبير من هذه الصفحات بالمعلومات ويربطون المحتوى التجاري.
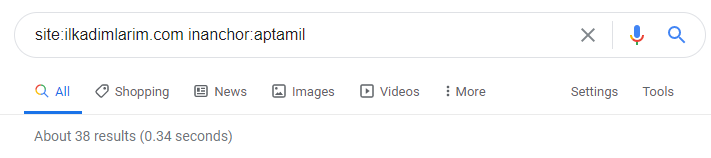

تم إثبات أطروحتنا.
تستخدم "خطواتي الأولى" المئات من مقاطع المحتوى التثقيفية حول الأمومة ورعاية الأطفال والحمل للوصول إلى الجمهور المستهدف. يربط "Ilkadimlarim" الصفحات التي تحتوي على منتجات Aptamil من هذا المحتوى ويوجه المستخدمين هناك.
التنميط المقارن للمحتوى وتحليل إستراتيجية المحتوى عبر خرائط المواقع باستخدام Python
الآن ، إذا كنت تريد ، فلنفعل الشيء نفسه لشركة من نفس الصناعة ونجري مقارنة لفهم الجانب العام لهذه الصناعة والاختلافات الاستراتيجية بين هاتين العلامتين التجاريتين.
كمثال ثان ، اخترت Prima.com.tr ، وهو Pampers ، ولكنه يستخدم الاسم التجاري Prima في تركيا. نظرًا لأن Prima لديه خريطة موقع واحدة ، فلن نتمكن من التصنيف حسب خرائط المواقع ، ولكن على الأقل لديهم فواصل مختلفة في عناوين URL الخاصة بهم. لذلك نحن محظوظون جدًا: سيتعين علينا كتابة كود أقل.
تخيل مقدار تكلفة الخوارزميات التي يتعين على Google تشغيلها نيابةً عنك عندما تنشئ موقعًا يصعب فهمه! يمكن أن يساعد ذلك في جعل حساب تكلفة الزحف أكثر واقعية في ذهنك ، حتى فيما يتعلق ببنية عنوان URL فقط.
من أجل عدم زيادة حجم المقالة بشكل أكبر ، لا نضع رموز العمليات المشابهة لتلك التي قمنا بها بالفعل.
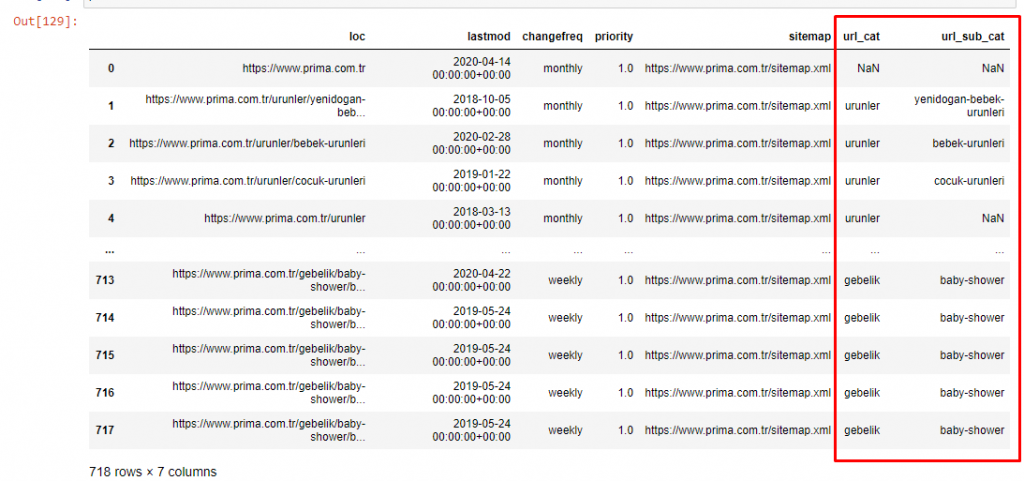
الآن ، يمكننا فحص توزيع فئة المحتوى الخاصة بهم حسب فئات عناوين URL والفئات الفرعية لعناوين URL. نرى أن لديهم قدرًا كبيرًا من صفحات الويب الخاصة بالشركات. يتم وضع صفحات الويب الخاصة بالشركات في قسم "prima-hakkinda" ("حول Prima"). لكن عندما أتحقق منها باستخدام Python ، أرى أنهم وحدوا منتجاتهم وصفحات الويب الخاصة بالشركات في فئة واحدة. يمكنك مشاهدة توزيع المحتوى الخاص بهم أدناه:

يمكننا أن نفعل الشيء نفسه بالنسبة للفئات الفرعية التالية.
من المثير للاهتمام أن نلاحظ أن بريما تستخدم "gebelik" (الحمل باللغة التركية) وهو نوع مختلف من "hamilelik" (الحمل باللغة العربية) ، وكلاهما يعني فترة الحمل.

الآن نرى تصنيفًا أعمق لمحتواها. 9.2٪ من المحتوى حول الحمل الصحي ، و 7.3٪ حول عملية نمو الأطفال ، و 8.3٪ حول الأنشطة التي يمكن القيام بها مع الأطفال ، و 0.7٪ حول ترتيب نوم الأطفال. حتى أن هناك مواضيع مثل التسنين بنسبة 3.9٪ ، وأمن الأطفال بنسبة 1.9٪ ، وكشف الحمل للأسرة بنسبة 1.4٪. كما ترى ، يمكنك التعرف على صناعة باستخدام عناوين URL فقط ونسبة توزيعها.
هذا ليس التصنيف المثالي ولكن على الأقل يمكننا أن نرى عقلية منافسينا واتجاهات تسويق المحتوى ومحتوى موقع الويب الخاص بهم وفقًا للفئات. الآن دعنا نتحقق من وتيرة نشر المحتوى حسب الشهر.
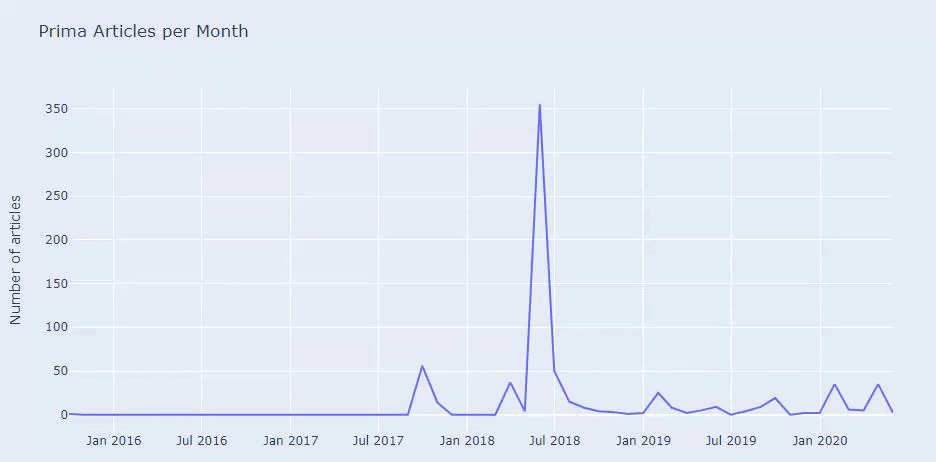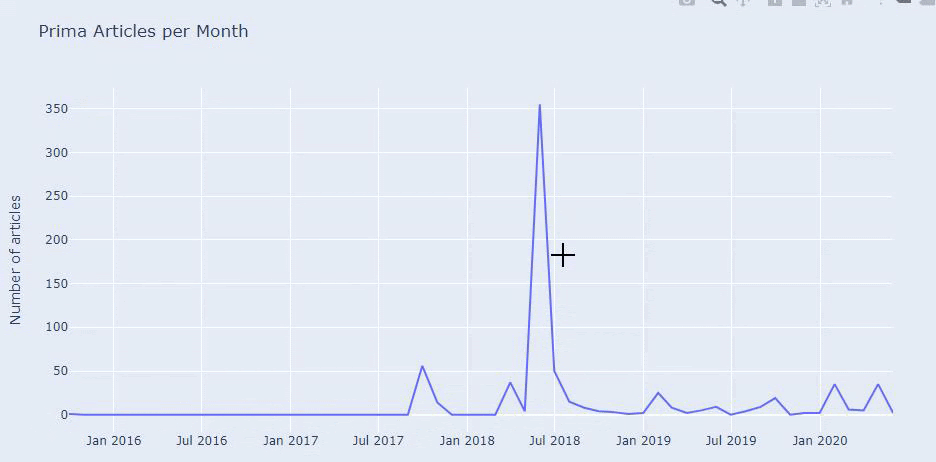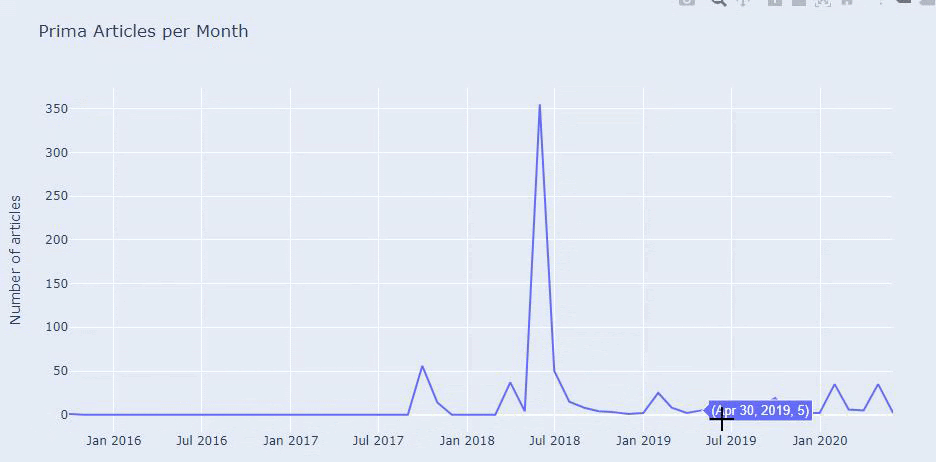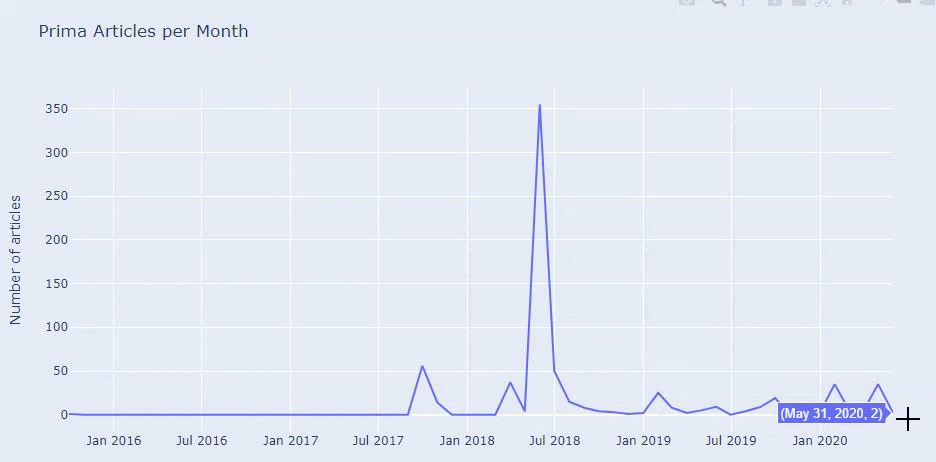
نرى أنهم قد نشروا 355 مقالة في يوليو 2018 ووفقًا لخريطة الموقع ، لم يتم تحديث محتوياتهم منذ ذلك الحين. يمكننا أيضًا مقارنة اتجاهات نشر المحتوى وفقًا للفئات على مر السنين. كما ترى ، يقع محتواها بشكل أساسي في أربع فئات مختلفة ويتم نشر معظمها في نفس الشهر.
قبل المتابعة ، يجب أن أقول إن بيانات خريطة الموقع قد لا تكون دائمًا صحيحة. على سبيل المثال ، ربما تم تحديث بيانات Lastmod لجميع عناوين URL لأنها جددت جميع خرائط المواقع في هذا التاريخ. للتغلب على هذا ، يمكننا أيضًا التحقق من أنهم لم يغيروا محتواهم منذ ذلك الحين باستخدام Wayback Machine.
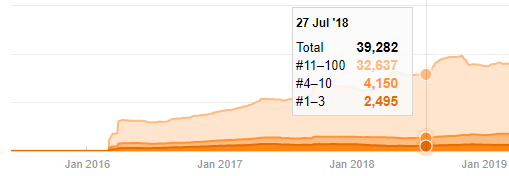
حتى لو بدت مشبوهة ، يمكن أن تكون هذه البيانات حقيقية. تميل العديد من الشركات في تركيا إلى إعطاء عدد كبير من الطلبات ونشر المحتوى للحظة من قبل. عندما أتحقق من عدد كلماتهم الرئيسية ، أرى قفزة في هذه الفترة الزمنية. لذلك ، إذا كنت تجري ملف تعريف محتوى مقارنًا وتحليلًا للإستراتيجية ، فيجب أن تفكر أيضًا في هذه المشكلات.
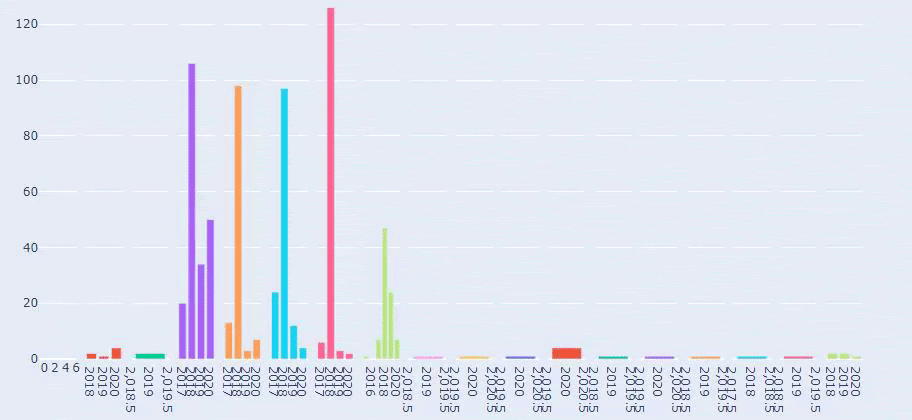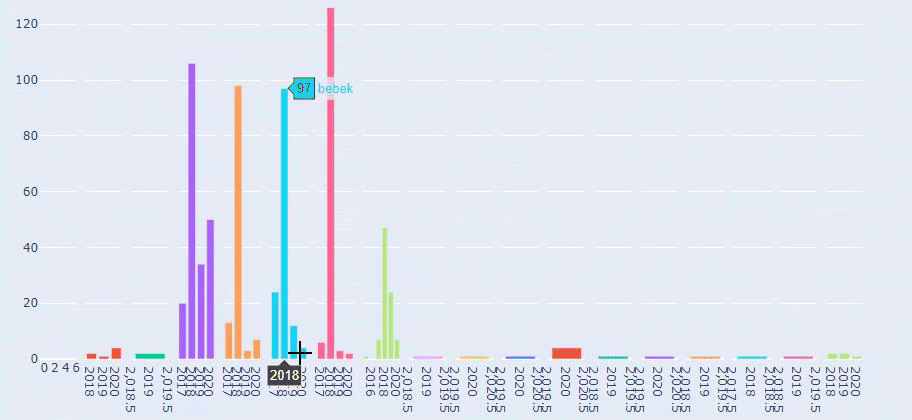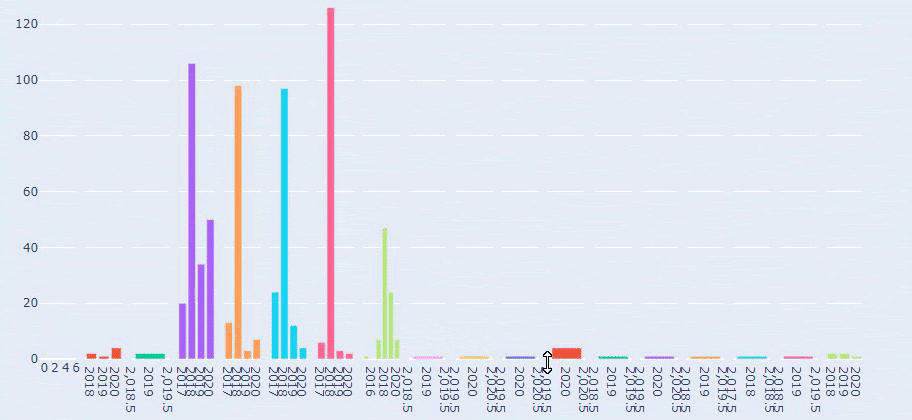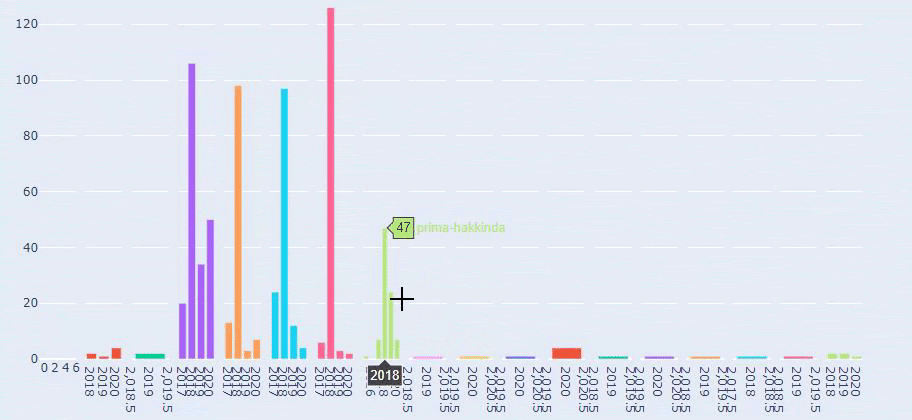
هذه مقارنة بين اتجاهات نشر المحتوى لكل فئة على مدار سنوات لموقع Prima.com.tr
الآن ، يمكننا مقارنة فئات محتوى موقعي الويب المختلفين واتجاهات النشر الخاصة بهما.
عندما ننظر إلى تواتر بريما لنشر مقالات حول نمو الطفل والحمل والأمومة ، نرى تشابهًا مع Ilkadimlarim:
- تم نشر معظم المقالات في وقت معين.
- لم يتم تحديثها لفترة طويلة.
- كان عدد المنتجات والصفحات منخفضًا جدًا مقارنة بعدد صفحات المحتوى الإعلامي.
- في الآونة الأخيرة ، قاموا للتو بإضافة منتجات جديدة إلى مواقعهم.
يمكننا اعتبار هذه الميزات الأربع هي العقلية الافتراضية للصناعة وقد نستخدم نقاط الضعف هذه لصالح حملتنا. بعد كل شيء ، تتطلب الجودة نضارة (كما ذكر أميت سنغال ، زميل Google).
في هذه المرحلة ، نرى أيضًا أن الصناعة ليست على دراية بسلوك Googlebot. بدلاً من تحميل 250 قطعة محتوى في يوم واحد ثم عدم إجراء أي تغييرات لمدة عام ، من الأفضل إضافة محتوى جديد بشكل دوري وتحديث المحتوى القديم بانتظام. وبالتالي ، يمكنك الحفاظ على جودة المحتوى ، ويمكن لبرنامج Googlebot فهم موقعك بسهولة أكبر ، وستكون قيم تكرار طلب الزحف أعلى من منافسيك.
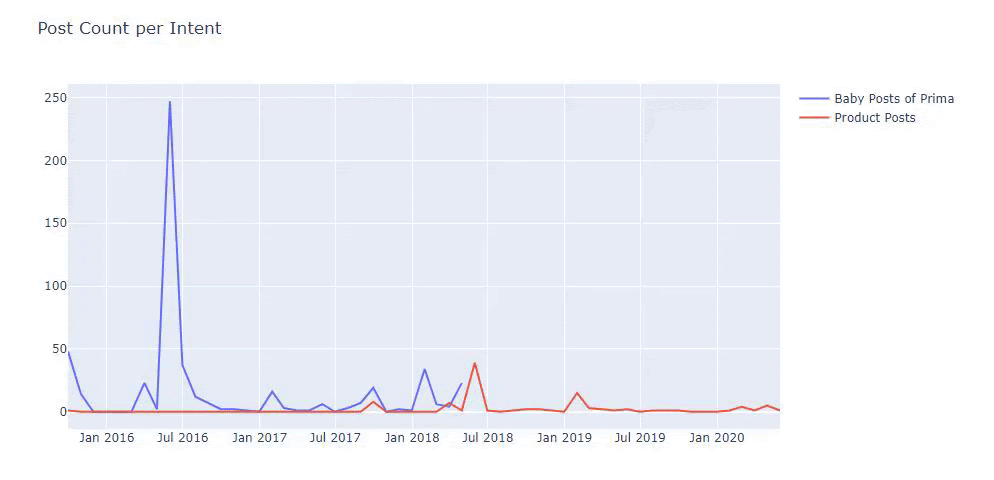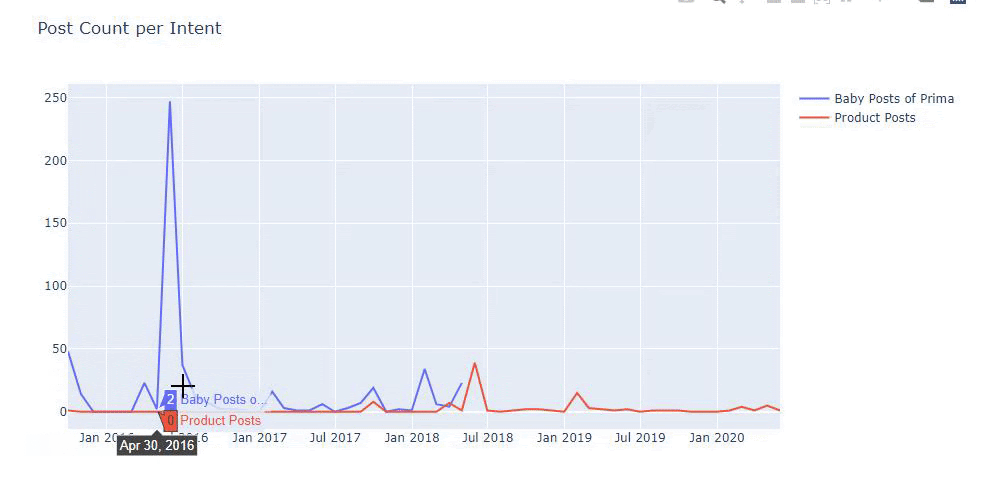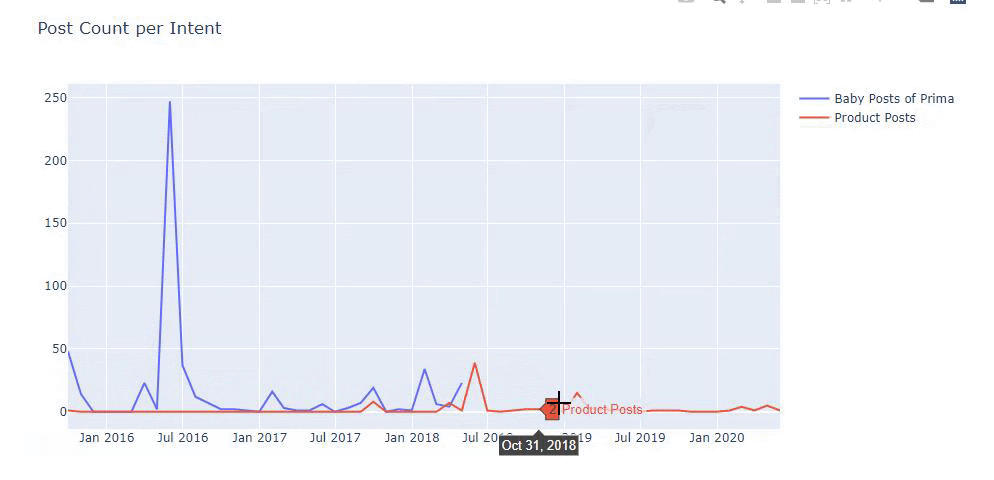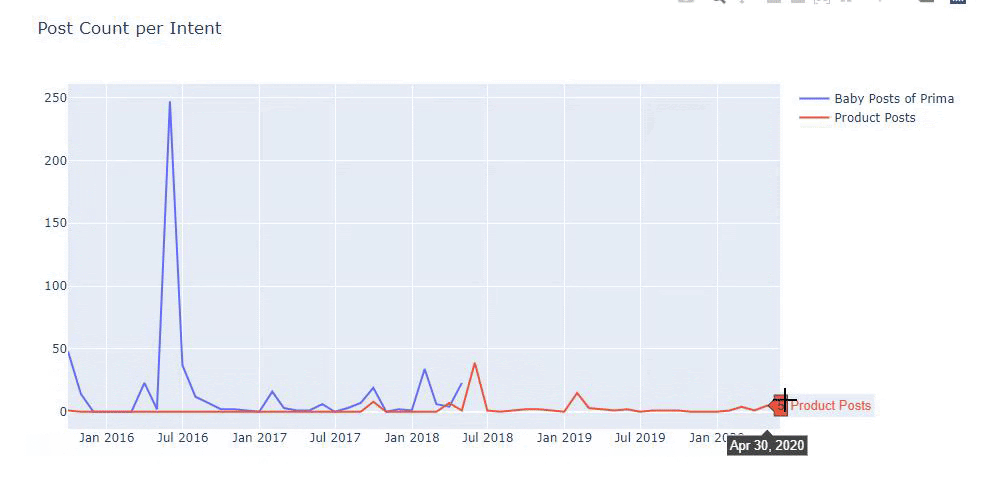
لقد استخدمت الطرق السابقة للتمييز بين صفحات المحتوى الإعلامي والمنتج وقمت بتحديد أكثر الكلمات استخدامًا في عناوين URL. تعني منشورات الأطفال هنا أنها محتوى إعلامي.
كما ترى ، فقد أضافوا 247 محتوى في يوم واحد. أيضًا ، لم ينشروا أو يحدّثوا المحتوى الإعلامي خلال أكثر من عام ، وقاموا أحيانًا بإضافة بعض صفحات المنتجات الجديدة.
الآن دعونا نقارن اتجاهات النشر الخاصة بهم في شكل واحد ولكن مع مؤتمرين مختلفين. لقد استخدمت الرموز أدناه لإنشاء هذا الشكل:
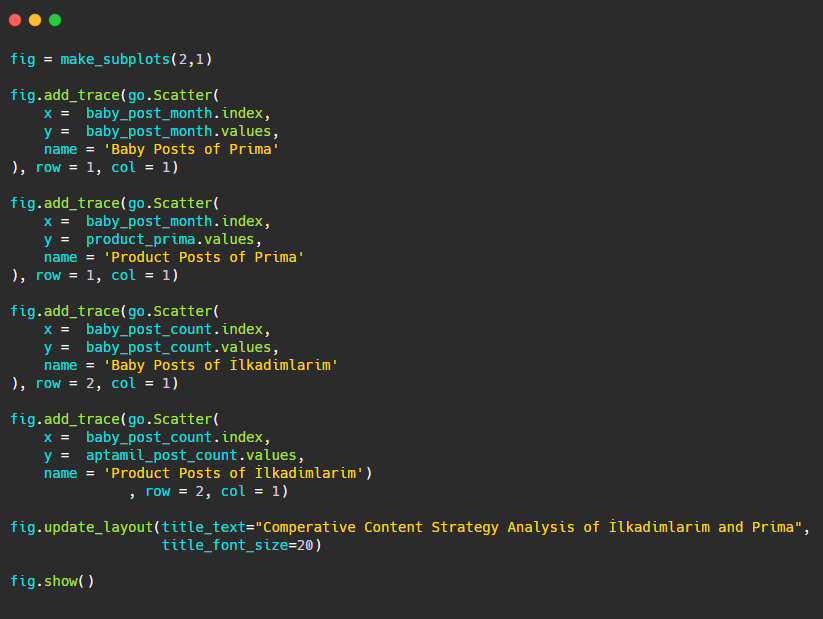
نظرًا لأن هذا الرسم يختلف عن الرسوم السابقة ، فقد أردت أن أوضح لك الرمز. هنا ، يتم وضع قطعتين منفصلتين في نفس الشكل. لهذا ، تم استدعاء طريقة make_subplots بالأمر من plotly.subplots import make_subplots.
تم إنشاؤه كشكل من صفين وعمود واحد مع make_subplots (2،1) .
لذلك ، يتم كتابة العمود والصف في نهاية التتبع ويتم تحديد مواضعهما. إنه نظام يمكن لأي شخص مطلع على نظام الشبكة في CSS التعرف عليه بسهولة.
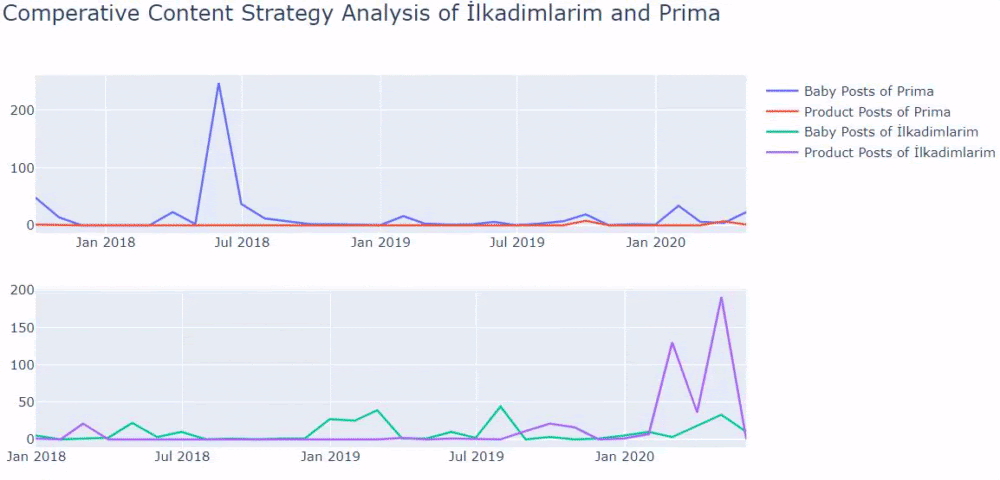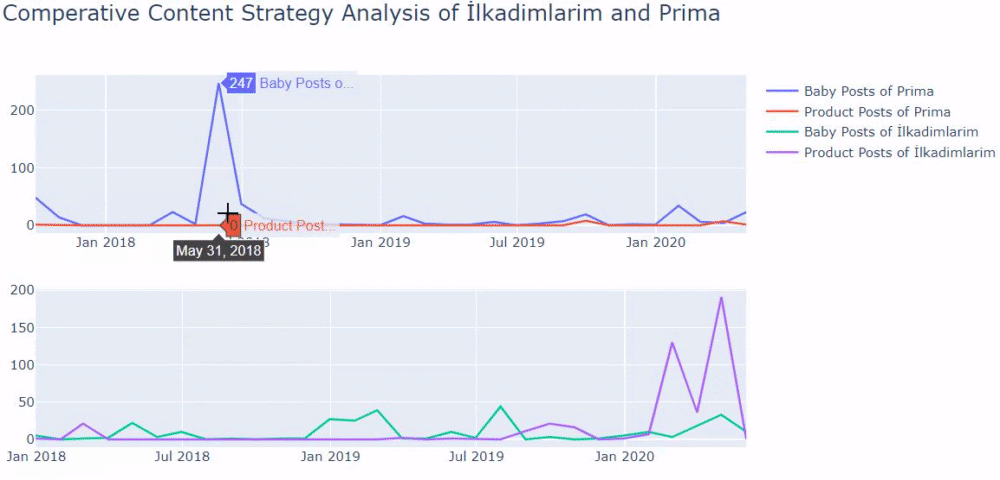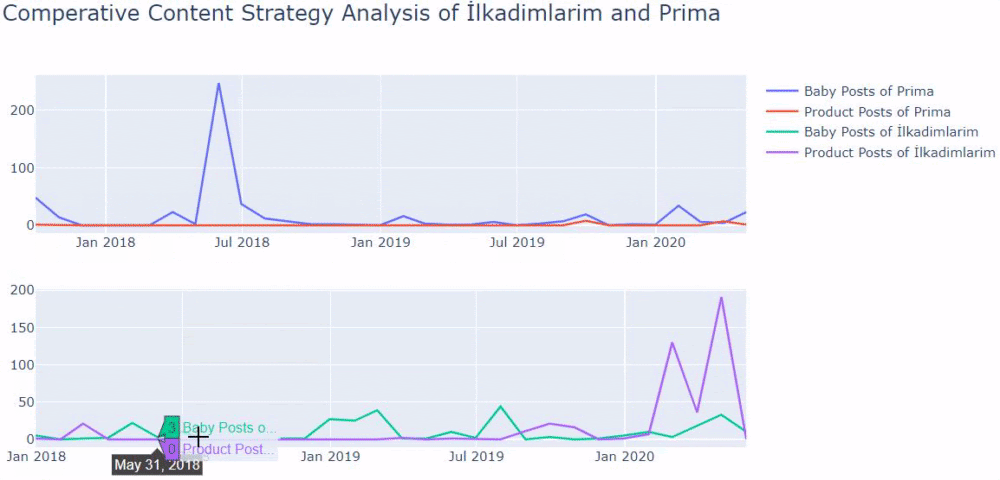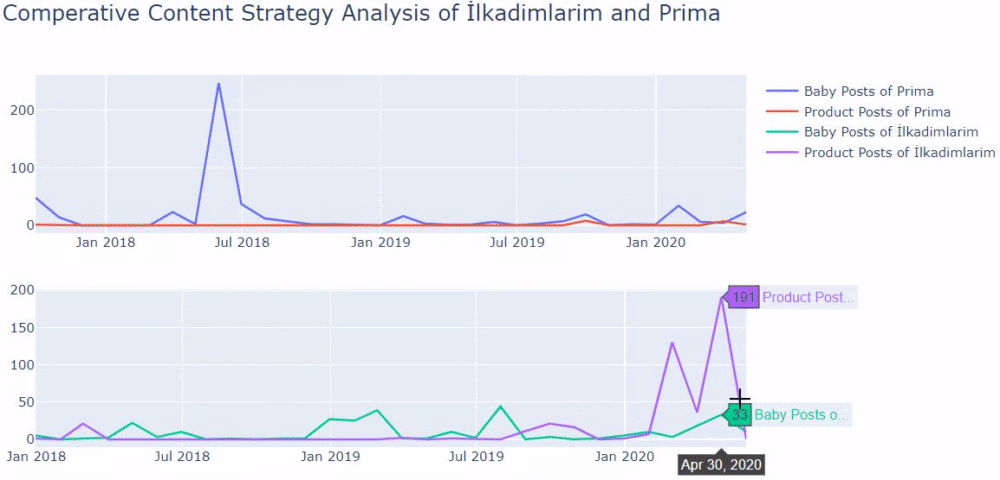
إذا كان لديك عميل في نفس القطاع ، فيمكنك استخدام هذه البيانات لإنشاء استراتيجية محتوى ، لمعرفة نقاط ضعف منافسيك وشبكة الاستعلام / الصفحة المقصودة الخاصة بهم عبر SERP. يمكنك أيضًا فهم مقدار المحتوى الذي يجب أن تنشره في نفس مجال المعرفة أو لنفس هدف المستخدم.
قبل الختام بما يمكننا تعلمه من خرائط المواقع كجزء من تحليل إستراتيجية المحتوى ، يمكننا فحص آخر موقع ويب يحتوي على عدد عناوين URL أعلى بكثير من صناعة أخرى.
تحليل إستراتيجية المحتوى لكيانات الويب الإخبارية على العملات باستخدام Python وخرائط المواقع
في هذا القسم ، سوف نستخدم مخطط خريطة الحرارة من Seaborn وأيضًا بعض طرق تأطير المربى واستخراج البيانات.

يمتلك Elias Dabbas أرشيف Kaggle ممتعًا ومفيدًا حقًا من حيث علوم البيانات وتحسين محركات البحث. هذا الشهر ، افتتح قسمًا جديدًا لمجموعة بيانات Kaggle لمواقع الأخبار التركية لي لكتابة الرموز اللازمة وإجراء تحليل لاستراتيجية المحتوى باستخدام Advertools عبر خرائط المواقع.
قبل أن أبدأ في استخدام هذه الأساليب على Kaggle ، أود أن أعرض بعض الأمثلة لما سيحدث إذا استخدمنا نفس الأساليب في كيانات الويب الأكبر في هذه المقالة.
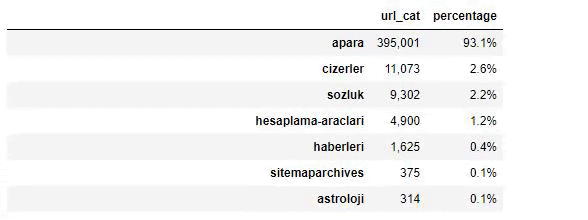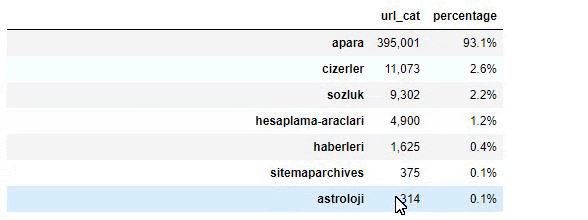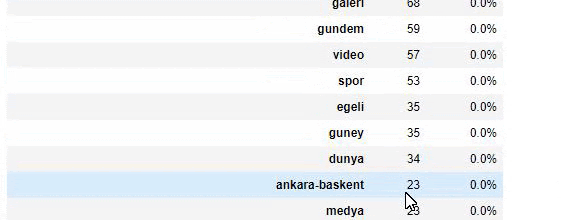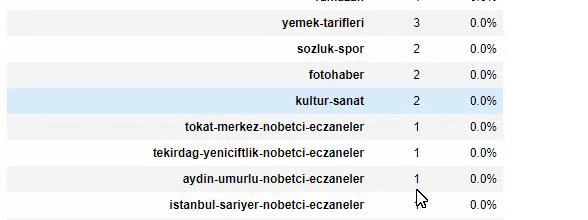
عندما نحلل محتوى جريدة صباح ، نرى أن جزءًا كبيرًا من محتوياتها (81٪) يقع في فئة تسمى "apara". أيضًا ، لديهم بعض الفئات الكبيرة لعلم التنجيم والحساب والقاموس والطقس وأخبار العالم. (الفقرة تعني المال بالتركية)
بالنسبة إلى جريدة صباح ، يمكننا أيضًا تحليل المحتوى باستخدام خرائط مواقع قمنا بجمعها باستخدام Advertools فقط ، ولكن نظرًا لأن الصحيفة المعنية كبيرة جدًا ، لم أكن أفضلها بسبب العدد الكبير من خرائط المواقع ومحتوى خرائط مواقع مختلفة تحتوي على نفس عنوان URL فئة.
أدناه يمكنك أيضًا مشاهدة الفائض من خرائط المواقع باستخدام Advertools.
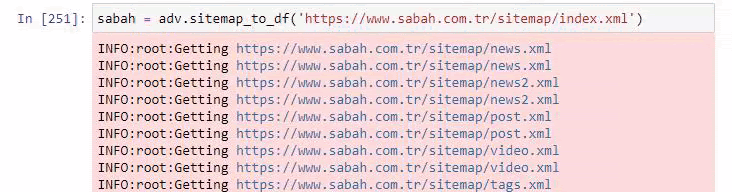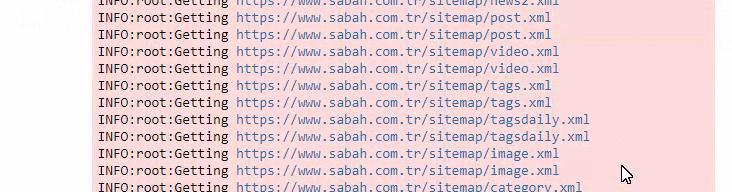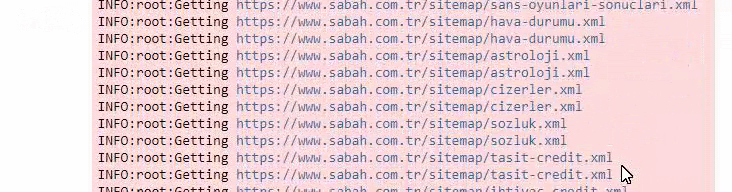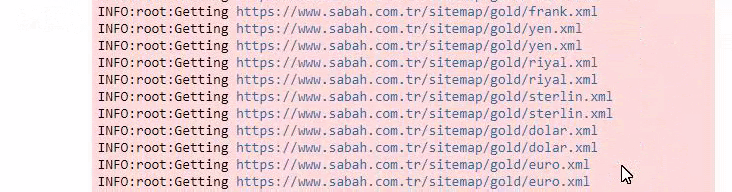
قد نرى أن لديهم خرائط مواقع مختلفة لنفس فئات عناوين URL مثل الذهب والائتمان والعملات والعلامات وأوقات الصلاة وساعات عمل الصيدلة ، إلخ ...
باختصار ، يمكننا تحقيق هذه التفاصيل من خلال التركيز على الفئات الفرعية لعناوين URL. بدلاً من توحيد خرائط مواقع مختلفة عبر المتغيرات. لذلك ، قمت بتوحيد جميع خرائط المواقع باستخدام طريقة خريطة موقع Advertools 'sitemap_to_df () كما في بداية المقالة.
يمكننا أيضًا استخدام مجموعة أخرى من الوظائف التي أنشأها إلياس دباس لإنشاء إطارات بيانات أفضل. إذا قمت بفحص وظائف dataset_utitilites ، يمكنك مشاهدة بعض الأمثلة. يعطي الكود أدناه الإجمالي والنسبة المئوية للتعبير المعتاد لعنوان URL المحدد جنبًا إلى جنب مع المجموع التراكمي عن طريق الأسلوب.
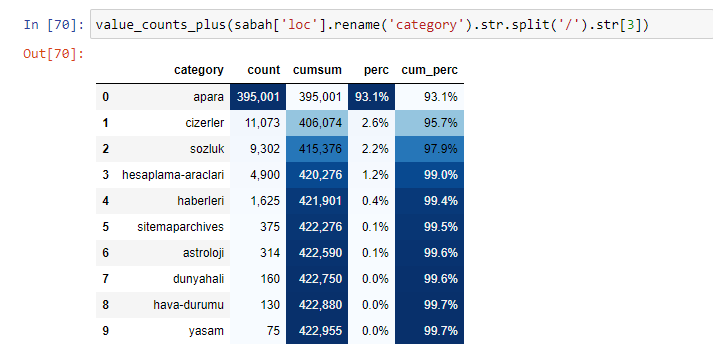
إذا فعلنا الشيء نفسه مع تحليل عناوين URL الفرعية لصحيفة صباح ، فسنحصل على النتيجة التالية.
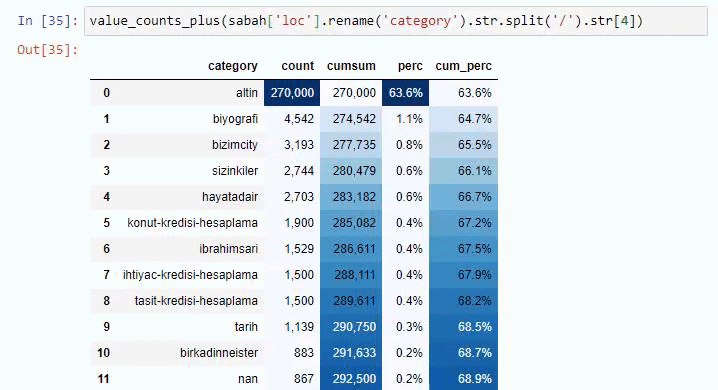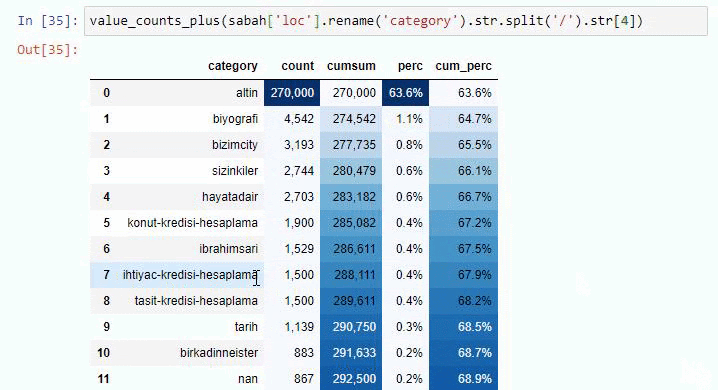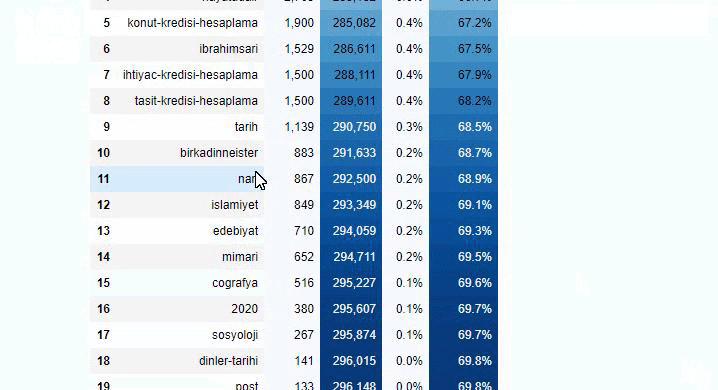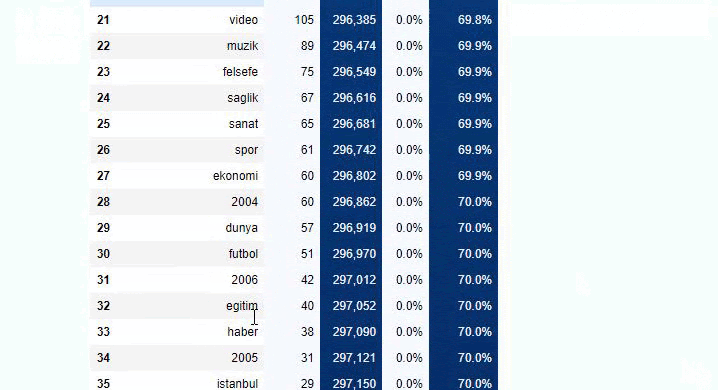
يمكنك زيادة عدد الأسطر التي ستخرجها الوظيفة المعنية عن طريق تغيير السطر أدناه. أيضًا ، إذا قمت بفحص محتوى الوظيفة ، فسترى أنه مشابه للمحتوى الذي استخدمناه من قبل.
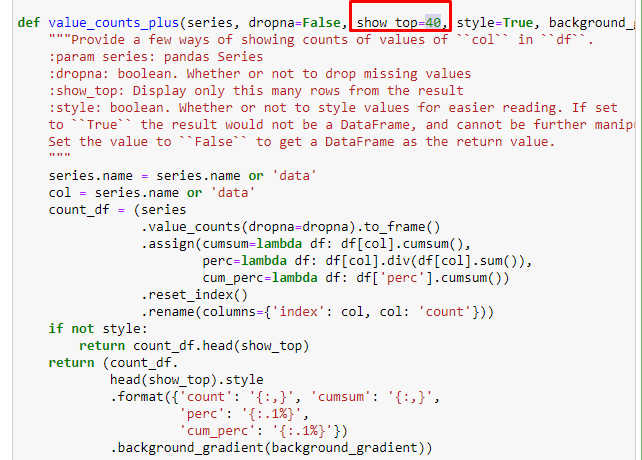
في التقسيمات الفرعية ، نرى تقسيمات مختلفة مثل "تاريخ الدين" ، "السيرة الذاتية" ، "أسماء المدن" ، "كرة القدم" ، "بيزيم سيتي (صورة كاريكاتورية)" ، "ائتمان الرهن العقاري". أكبر انهيار في فئة "الذهب".
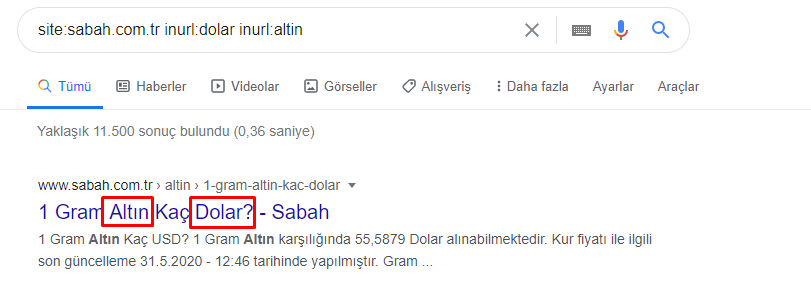
إذًا كيف يمكن لإحدى الصحف أن تحتوي على 295000 عنوان URL لأسعار الذهب؟
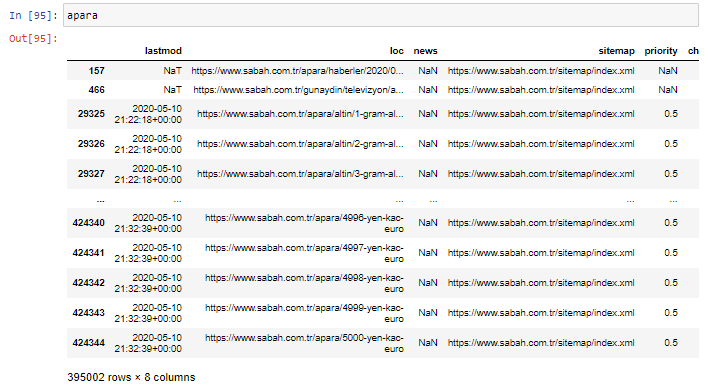
بادئ ذي بدء ، أرمي جميع عناوين URL التي تحتوي على "apara" في أول تحليل لعنوان URL لصحيفة Sabah في متغير.
apara = sabah [sabah ['loc']. str.contains ('apara')]
ها هي النتيجة:
يمكننا أيضًا تصفية الأعمدة باستخدام طريقة .filter ():
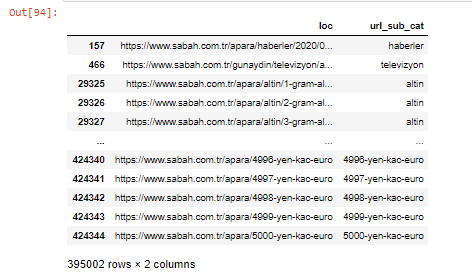
الآن ، يمكننا أن نرى في الجزء السفلي من DataFrame سبب امتلاك صحيفة Sabah لعدد كبير من عناوين URL لـ Apara لأنها فتحت صفحات ويب مختلفة لكل مبلغ من حسابات العملة مثل 5000 يورو و 4999 يورو و 4998 يورو والمزيد ...
ولكن قبل أي استنتاج ، نحتاج إلى التأكد من أن أكثر من 250.000 من عناوين URL هذه تنتمي إلى فئة "altin (gold)".
apara.filter (['loc'، 'url_sub_cat']). سوف يظهر الذيل (60) آخر 60 سطرًا من إطار البيانات هذا:

يمكننا أن نفعل الشيء نفسه بالنسبة لتفصيل عنوان URL الذهبي داخل مجموعة Apara.
gold = apara [apara ['loc']. str.contains ('altin')]
gold.filter (['loc'، 'url_sub_cat']). ذيل (85)
gold.filter (['loc'، 'url_sub_cat']). head (85)
في هذه المرحلة ، نرى أن صحيفة صباح قد فتحت 5000 صفحة مختلفة لتحويل كل عملة إلى الدولار واليورو والذهب و TL (الليرة التركية). توجد صفحة حساب منفصلة لكل وحدة نقود بين 1 و 5000. يمكنك مشاهدة مثال أول 85 سطرًا وآخر 85 سطرًا من مجموعة الذهب أدناه. تم فتح صفحة منفصلة عن سعر جرام الذهب.


ليس لدينا أدنى شك في أن هذه الصفحات غير ضرورية ، مع وجود الكثير من المحتوى المكرر ، وكبيرة جدًا ، لكن صحيفة صباح هي موقع ويب قوي للعلامة التجارية ، حيث تواصل Google عرضه في كل استعلام تقريبًا ، وفي الترتيب الأعلى.
في هذه المرحلة ، يمكننا أيضًا أن نرى أن تحمل تكلفة الزحف مرتفع بالنسبة إلى موقع إخباري قديم يتمتع بسلطة عالية.
ومع ذلك ، فإن هذا لا يفسر سبب احتواء الفئة الذهبية على عناوين URL أكثر من غيرها.
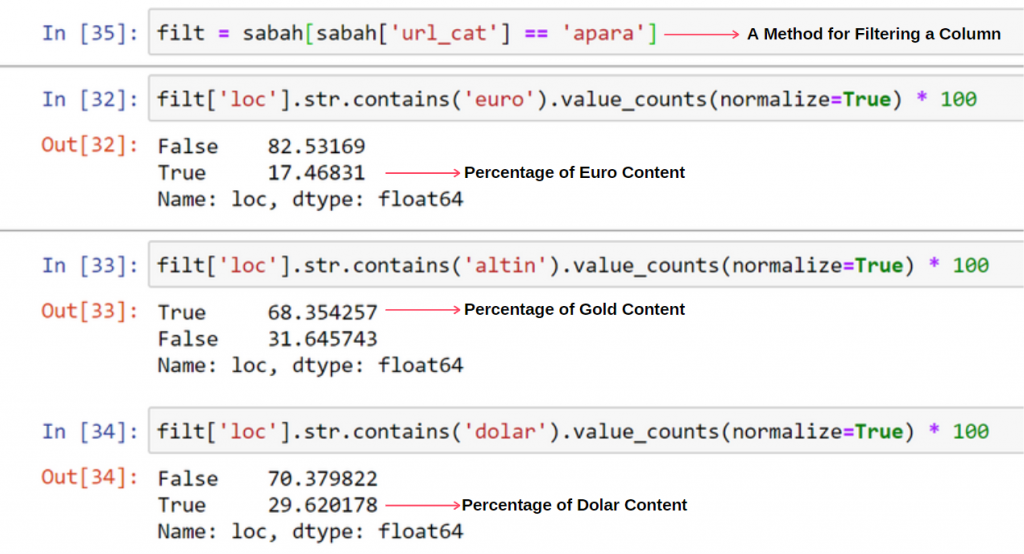
لا أرى أي شيء غريب حول تداخل القيم التي تزيد عن 100٪.
ما لم أفقد شيئا؟
كما ستلاحظ ، عندما نضيف جميع القيم الحقيقية ، نحصل على نتيجة 115.16٪. السبب في ذلك أدناه.
حتى المجموعة الرئيسية لديها تقاطع مع بعضها البعض مثل هذا. يمكننا أيضًا تحليل هذه التقاطعات ، لكنها قد تكون موضوع مقال آخر.
نرى أن 68٪ من محتويات مجموعة Apara URL مرتبطة بـ GOLD.
لفهم هذا الموقف بشكل أفضل ، فإن أول شيء يتعين علينا القيام به هو فحص عناوين URL في انكسار الذهب.
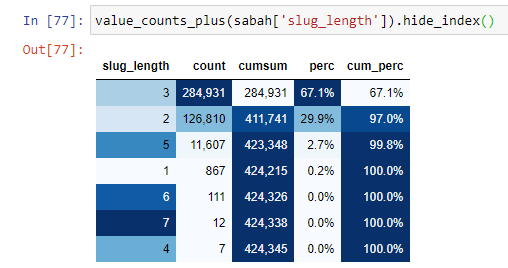
عندما نصنف عناوين URL وفقًا لمقدار "/" لديهم منذ قسم الجذر ، نرى أن عدد عناوين URL التي تحتوي على 3 فواصل بحد أقصى مرتفع. عندما نحلل عناوين URL هذه ، نرى أن 270.000 من عناوين URL الثلاثة ذات الطول البطيء تقع في الفئة الذهبية.
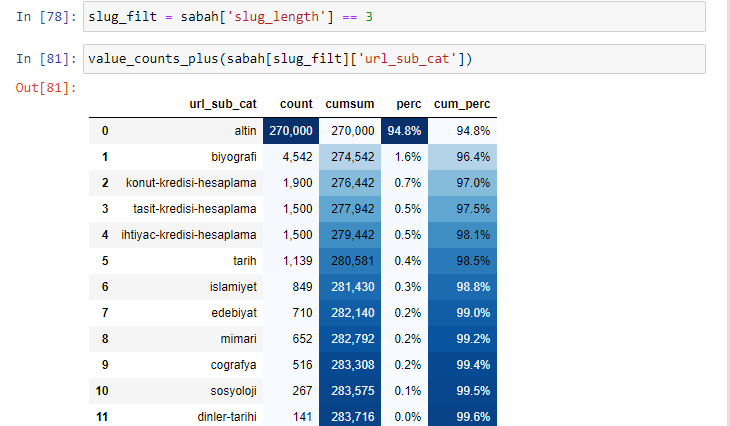
morning_filt = morning ['slug_length'] == 3 هذا يعني أنك تحصل فقط على العناصر التي تساوي 3 من مجموعة البيانات من نوع البيانات int في عمود معين من إطار بيانات معين. بعد ذلك ، بناءً على هذه المعلومات ، نقوم بتأطير عناوين URL الملائمة للشرط مع العدد والمبالغ ومعدلات التجميع بالمجموع التراكمي.
عندما نستخرج الكلمات الأكثر استخدامًا في عناوين URL الذهبية ، فإننا نصادف الكلمات التي تمثل "كامل" ، "جمهورية" ، "ربع" ، "جرام" ، "نصف" ، "سلف". أنواع الذهب Ata و Republic فريدة من نوعها لتركيا. أحدهما يمثل السيادة التركية والآخر هو مؤسس الجمهورية كمال أتاتورك. هذا هو السبب في ارتفاع حجم البحث عن استعلاماتهم.
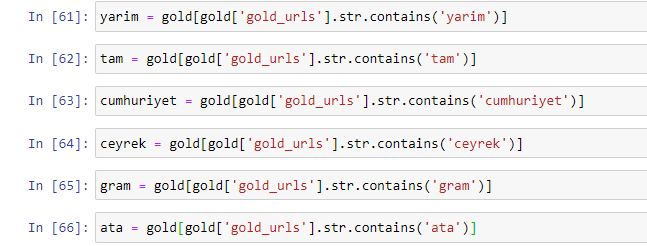
بادئ ذي بدء ، أزلنا الكلمات الشائعة الموجودة في عناوين URL وقمنا بتعيينها لمتغيرات منفصلة. بعد ذلك ، سوف نستخدم هذه المتغيرات في Gold DataFrame لإنشاء أعمدة خاصة بأنواعها.
بعد إنشاء أعمدة جديدة من خلال المتغيرات ، يجب علينا تصفيتها مع القيم المنطقية.
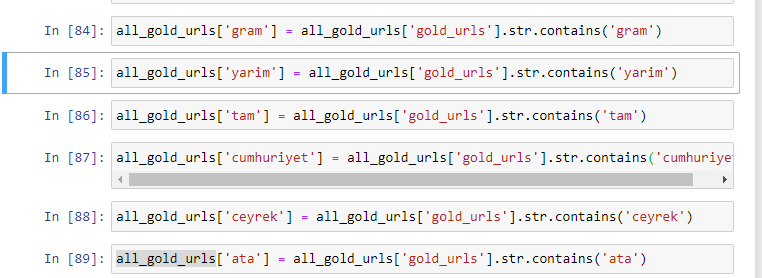
كما ترى ، تمكنا من تصنيف جميع عناوين URL الذهبية بـ 270.000 صف و 6 أعمدة. السبب الرئيسي للعدد الكبير من الصفحات الخاصة بالذهب هو أن الدولار أو اليورو ليس لهما أنواع منفصلة ، في حين أن الذهب له أنواع منفصلة. في الوقت نفسه ، فإن تنوع صفحات العبور بين الذهب والعملات المختلفة أعلى من العملات الأخرى بسبب ثقتهم التقليدية في الشعب التركي.
في رأيي ، يجب توزيع جميع أنواع الصفحات الذهبية بالتساوي ، أليس كذلك؟
يمكننا اختبار ذلك بسهولة باستخدام ميزة خريطة الحرارة من Seaborn.
استيراد seaborn as sns
استيراد matplotlib.pyplot كـ PLT
شكل plt (حجم التين = (10،8))
sns.heatmap (a، yticklabels = False، cbar = False، cmap = "viridis")
plt.show ()
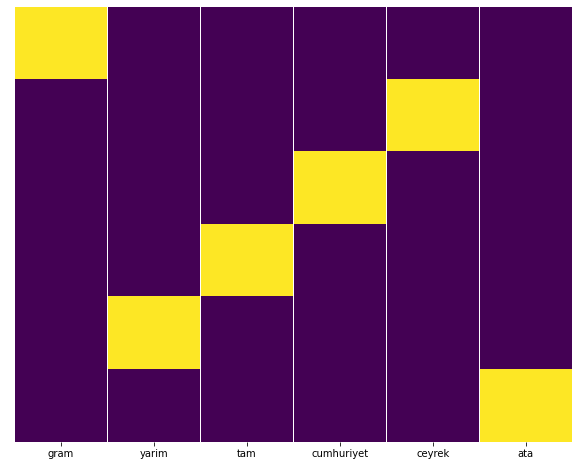
هنا على خريطة الحرارة ، يتم تمييز Trues في كل عمود ببساطة. كما يتضح ، حجم كل منها متماثل مع بعضها البعض ومرتّب بدقة على الخريطة.
وبالتالي ، فقد اتخذنا منظورًا واسعًا حول سياسة محتوى جريدة Sabah.com.tr حول العملات وحساب العملات.
في المستقبل ، سوف أكتب مواقع الأخبار التركية واستراتيجيات محتواها بناءً على خرائط المواقع Kaggle ، التي أطلقها إلياس دباس ، لكن في هذه المقالة ، تحدثنا بشكل كافٍ عما يمكن اكتشافه على كل من المواقع الكبيرة والصغيرة باستخدام خرائط المواقع .
الخلاصة والوجبات الجاهزة
أعتقد أننا رأينا مدى سهولة فهم موقع ويب بفضل بنية عنوان URL السلس والمعاني. يجب أن نتذكر أيضًا مدى أهمية بنية عنوان URL المناسبة بالنسبة إلى Google.
في المستقبل ، سنرى الكثير من مُحسّنات محرّكات البحث الذين أصبحوا على دراية متزايدة بعلوم البيانات ، وتصور البيانات ، وبرمجة الواجهة الأمامية ، والمزيد ... أرى هذه العملية كبداية لتغيير حتمي: سيتم إغلاق الفجوة بين مُحسّنات محرّكات البحث والمطورين تمامًا في غضون سنوات قليلة.
باستخدام Python ، يمكنك إجراء هذا النوع من التحليل إلى أبعد من ذلك: من الممكن الحصول على بيانات من فهم الآراء السياسية لموقع إخباري ، إلى من يكتب حول ماذا وكم مرة وبأي مشاعر. أفضل عدم الخوض في ذلك هنا لأن هذه العمليات تدور حول علم البيانات الخالص أكثر من تحسين محركات البحث (وهذه المقالة طويلة جدًا بالفعل).
ولكن إذا كنت مهتمًا ، فهناك العديد من أنواع عمليات التدقيق الأخرى التي يمكن إجراؤها عبر ملفات Sitemap و Python ، مثل التحقق من أكواد الحالة لعناوين URL في ملف Sitemap.
أنا أتطلع إلى تجربة ومشاركة مهام تحسين محركات البحث الأخرى التي يمكنك القيام بها باستخدام Python و Advertools.