
فهم الذكاء الاصطناعي: كيف علمنا أجهزة الكمبيوتر اللغة الطبيعية
نشرت: 2023-11-28تم استخدام عبارة "الذكاء الاصطناعي" فيما يتعلق بأجهزة الكمبيوتر منذ الخمسينيات من القرن الماضي، ولكن حتى العام الماضي، ربما اعتقد معظم الناس أن الذكاء الاصطناعي لا يزال خيالًا علميًا أكثر من الواقع التكنولوجي.
أدى وصول ChatGPT من OpenAI في نوفمبر 2022 فجأة إلى تغيير تصورات الناس حول ما يستطيع التعلم الآلي فعله - ولكن ما هو بالضبط ما يتعلق بـ ChatGPT الذي جعل العالم يقف ويدرك أن الذكاء الاصطناعي موجود هنا بطريقة كبيرة؟
باختصار، اللغة - السبب الذي جعل ChatGPT يبدو وكأنه قفزة ملحوظة إلى الأمام هو كيف بدا بطلاقة في اللغة الطبيعية بطريقة لم يسبق لـ chatbot أن ظهرت من قبل.
يمثل هذا مرحلة جديدة ملحوظة في "معالجة اللغة الطبيعية" (NLP)، وهي قدرة أجهزة الكمبيوتر على تفسير اللغة الطبيعية وإخراج استجابات مقنعة. تم بناء ChatGPT على "نموذج لغة كبير" (LLM)، وهو نوع من الشبكات العصبية التي تستخدم التعلم العميق المدرب على مجموعات البيانات الضخمة التي يمكنها معالجة المحتوى وإنشاءه.
"كيف تمكن برنامج كمبيوتر من تحقيق هذه الطلاقة اللغوية؟"
كيف نصل الي هناك؟ كيف حقق برنامج كمبيوتر مثل هذه الطلاقة اللغوية؟ كيف يبدو الأمر إنسانيًا بشكل لا يخطئ؟
لم يتم إنشاء ChatGPT من فراغ، بل تم بناؤه على عدد لا يحصى من الابتكارات والاكتشافات المختلفة على مدى العقود الأخيرة. كانت سلسلة الإنجازات التي أدت إلى ChatGPT كلها علامات بارزة في علوم الكمبيوتر، ولكن من الممكن رؤيتها على أنها تحاكي المراحل التي يكتسب بها البشر اللغة.
كيف نتعلم اللغة؟
لفهم كيف وصل الذكاء الاصطناعي إلى هذه المرحلة، من المفيد النظر في طبيعة تعلم اللغة نفسها - نبدأ بكلمات مفردة ثم نبدأ في دمجها معًا في تسلسلات أطول حتى نتمكن من توصيل المفاهيم والأفكار والتعليمات المعقدة.
على سبيل المثال، بعض المراحل الشائعة لاكتساب اللغة عند الأطفال هي:
- مرحلة الهولو فراستك: بين عمر 9 إلى 18 شهرًا، يتعلم الأطفال استخدام كلمات مفردة تصف احتياجاتهم أو رغباتهم الأساسية. التواصل بكلمة واحدة يعني أن هناك تركيزًا على الوضوح أكثر من الاكتمال المفاهيمي. إذا كان الطفل جائعًا فلن يقول "أريد بعض الطعام" أو "أنا جائع"، وبدلاً من ذلك سيقول ببساطة "طعام" أو "حليب".
- مرحلة الكلمتين: خلال المرحلة العمرية من 18 إلى 24 شهرًا، يبدأ الأطفال في استخدام تجميع بسيط من كلمتين لتعزيز مهارات التواصل لديهم. الآن يمكنهم التعبير عن مشاعرهم واحتياجاتهم بعبارات مثل "المزيد من الطعام" أو "اقرأ كتابًا".
- المرحلة التلغرافية: بين عمر 24-30 شهرًا، يبدأ الأطفال في ربط عدة كلمات معًا لتكوين عبارات وجمل أكثر تعقيدًا. لا يزال عدد الكلمات المستخدمة صغيرًا ولكن الترتيب الصحيح للكلمات يبدأ في الظهور. يبدأ الأطفال في تعلم بناء الجملة الأساسية، مثل "أريد أن أظهر لأمي".
- مرحلة تعدد الكلمات: بعد مرور 30 شهرًا، يبدأ الأطفال بالانتقال إلى مرحلة تعدد الكلمات. في هذه المرحلة، يبدأ الأطفال في استخدام جمل أكثر صحة نحويًا ومعقدة ومتعددة الجمل. هذه هي المرحلة الأخيرة من اكتساب اللغة ويتواصل الأطفال في النهاية بجمل معقدة مثل "إذا هطل المطر أريد البقاء في المنزل ولعب الألعاب".
إحدى المراحل الأساسية الأولى في اكتساب اللغة هي القدرة على البدء في استخدام كلمات مفردة بطريقة بسيطة جدًا. لذا فإن العقبة الأولى التي كان على باحثي الذكاء الاصطناعي التغلب عليها هي كيفية تدريب النماذج على تعلم ارتباطات الكلمات البسيطة.
النموذج 1 - تعلم الكلمات المفردة باستخدام Word2Vec (الورقة 1 والورقة 2)
أحد نماذج الشبكات العصبية المبكرة التي حاولت تعلم ارتباطات الكلمات بهذه الطريقة كان Word2Vec، الذي طوره توماش ميكولوف ومجموعة من الباحثين في Google. وقد تم نشره في ورقتين بحثيتين في عام 2013 (مما يوضح مدى سرعة تطور الأمور في هذا المجال).
تم تدريب هذه النماذج من خلال تعلم ربط الكلمات الشائعة الاستخدام معًا. اعتمد هذا النهج على حدس الرواد اللغويين الأوائل مثل جون ر. فيرث، الذي لاحظ أن المعنى يمكن استخلاصه من ارتباط الكلمات: "يجب أن تعرف الكلمة من خلال الشركة التي تحتفظ بها".
والفكرة هي أن الكلمات التي تشترك في معنى دلالي مماثل تميل إلى أن تتكرر معًا بشكل متكرر. عادةً ما تتكرر الكلمتان "قطط" و"كلاب" معًا بشكل متكرر أكثر مما يحدث مع كلمات مثل "تفاح" أو "أجهزة كمبيوتر". بمعنى آخر، يجب أن تكون كلمة "قطة" مشابهة لكلمة "كلب" أكثر من أن تكون كلمة "قطة" مشابهة لكلمة "تفاحة" أو "كمبيوتر".
الشيء المثير للاهتمام في Word2Vec هو كيفية تدريبه على تعلم ارتباطات الكلمات هذه:
- تخمين الكلمة المستهدفة: يتم إعطاء النموذج عددًا ثابتًا من الكلمات كمدخل مع فقدان الكلمة المستهدفة وكان عليه تخمين الكلمة المستهدفة المفقودة. يُعرف هذا باسم حقيبة الكلمات المستمرة (CBOW).
- تخمين الكلمات المحيطة: يتم إعطاء النموذج كلمة واحدة ثم يتم تكليفه بتخمين الكلمات المحيطة. يُعرف هذا باسم Skip-Gram وهو النهج المعاكس لـ CBOW حيث أننا نتنبأ بالكلمات المحيطة.
إحدى مزايا هذه الأساليب هي أنك لا تحتاج إلى أي بيانات مصنفة لتدريب النموذج - تصنيف البيانات، على سبيل المثال وصف النص بأنه "إيجابي" أو "سلبي" لتعليم تحليل المشاعر، هو عمل بطيء وشاق، بعد كل شيء.
من أكثر الأشياء إثارة للدهشة في Word2Vec هي العلاقات الدلالية المعقدة التي استحوذت عليها من خلال نهج تدريبي بسيط نسبيًا. يقوم Word2Vec بإخراج المتجهات التي تمثل كلمة الإدخال. من خلال إجراء عمليات رياضية على هذه المتجهات، تمكن المؤلفون من إظهار أن ناقلات الكلمات لا تلتقط عناصر متشابهة من الناحية النحوية فحسب، بل أيضًا العلاقات الدلالية المعقدة.
ترتبط هذه العلاقات بكيفية استخدام الكلمات. والمثال الذي لاحظه المؤلفون هو العلاقة بين كلمات مثل "الملك" و"الملكة" و"الرجل" و"المرأة".
ولكن على الرغم من أنها كانت خطوة إلى الأمام، إلا أن Word2Vec كان له حدود. كان لها تعريف واحد فقط لكل كلمة - على سبيل المثال، نعلم جميعًا أن كلمة "بنك" يمكن أن تعني أشياء مختلفة اعتمادًا على ما إذا كنت تخطط لحمل واحدة أو الصيد منها. لم يهتم Word2Vec، فهو يحتوي فقط على تعريف واحد لكلمة "بنك" وسيستخدمه في جميع السياقات.
قبل كل شيء، لم يتمكن Word2Vec من معالجة التعليمات أو حتى الجمل. يمكنه فقط أن يأخذ كلمة كمدخل ومخرج "تضمين كلمة"، أو تمثيل متجه، والذي تعلمه لتلك الكلمة. وللبناء على أساس هذه الكلمة الواحدة، احتاج الباحثون إلى إيجاد طريقة لربط كلمتين أو أكثر معًا في تسلسل. يمكننا أن نتصور أن هذا يشبه مرحلة اكتساب اللغة المكونة من كلمتين.
النموذج 2 - تعلم تسلسل الكلمات باستخدام RNNs وتسلسلات النص
بمجرد أن يبدأ الأطفال في إتقان استخدام الكلمات المفردة، فإنهم يحاولون تجميع الكلمات معًا للتعبير عن أفكار ومشاعر أكثر تعقيدًا. وبالمثل، كانت الخطوة التالية في تطوير البرمجة اللغوية العصبية هي تطوير القدرة على معالجة تسلسل الكلمات. المشكلة في معالجة تسلسلات النص هي أنه ليس لها طول ثابت. يمكن أن يختلف طول الجملة من بضع كلمات إلى فقرة طويلة. لن يكون كل التسلسل مهمًا للمعنى والسياق الشامل. لكننا بحاجة إلى أن نكون قادرين على معالجة التسلسل بأكمله لمعرفة الأجزاء الأكثر صلة بالموضوع.
وهنا ظهرت الشبكات العصبية المتكررة (RNNs).
تم تطوير شبكة RNN في التسعينيات، وتعمل من خلال معالجة مدخلاتها في حلقة حيث يتم نقل مخرجات الخطوات السابقة عبر الشبكة أثناء تكرارها خلال كل خطوة في التسلسل.
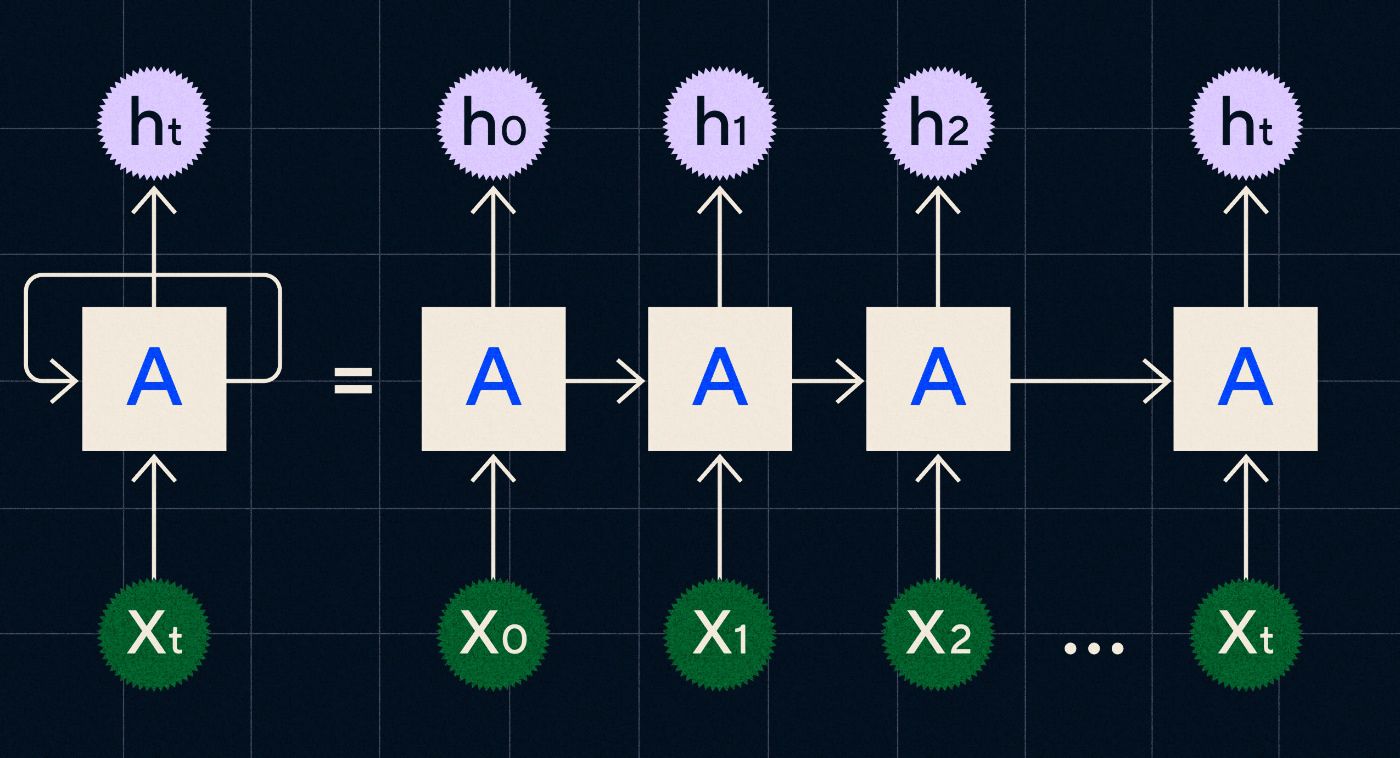
المصدر: مشاركة مدونة كريستوفر أولاه على RNNs
يوضح الرسم البياني أعلاه كيفية تصوير RNN كسلسلة من الشبكات العصبية (A) حيث يتم نقل مخرجات الخطوة السابقة (h0، h1، h2…ht) إلى الخطوة التالية. وفي كل خطوة تتم أيضًا معالجة مدخلات جديدة (X0، X1، X2 … Xt) بواسطة الشبكة.
شبكات RNN (وعلى وجه التحديد شبكات الذاكرة طويلة المدى، أو LSTMs، وهو نوع خاص من RNN قدمه سيب هوخريتر ويورغن شميدهوبر في عام 1997) مكنتنا من إنشاء بنيات الشبكات العصبية التي يمكنها أداء مهام أكثر تعقيدًا مثل الترجمة.
في عام 2014، نشر إيليا سوتسكيفر (المؤسس المشارك لشركة OpenAI)، وأوريول فينيالز، وكووك في لو في جوجل، ورقة بحثية تصف نماذج التسلسل إلى التسلسل (Seq2Seq). أظهرت هذه الورقة كيف يمكنك تدريب الشبكة العصبية على أخذ نص مُدخل وإرجاع ترجمة لذلك النص. يمكنك التفكير في هذا كمثال مبكر للشبكة العصبية التوليدية، حيث تعطيها مطالبة وتقوم بإرجاع الاستجابة. ومع ذلك، كانت المهمة ثابتة، فإذا تم تدريبه على الترجمة، فلن تتمكن من "حثه" على القيام بأي شيء آخر.
تذكر أن النموذج السابق، Word2Vec، يمكنه معالجة الكلمات المفردة فقط. لذا، إذا مررت عليها جملة مثل "طبيب الأسنان قلع سني"، فسيقوم ببساطة بإنشاء ناقل لكل كلمة كما لو كانت غير مرتبطة.
ومع ذلك، فإن الترتيب والسياق مهمان لمهام مثل الترجمة. لا يمكنك ترجمة الكلمات الفردية فحسب، بل تحتاج إلى تحليل تسلسل الكلمات ثم إخراج النتيجة. هذا هو المكان الذي قامت فيه RNNs بتمكين نماذج Seq2Seq من معالجة الكلمات بهذه الطريقة.
كان مفتاح نماذج Seq2Seq هو تصميم الشبكة العصبية، والذي استخدم شبكتين RNN متتاليتين. أحدهما كان عبارة عن برنامج تشفير يقوم بتحويل الإدخال من النص إلى تضمين، والآخر كان عبارة عن وحدة فك ترميز تأخذ كمدخلاتها التضمينات التي يخرجها برنامج التشفير:
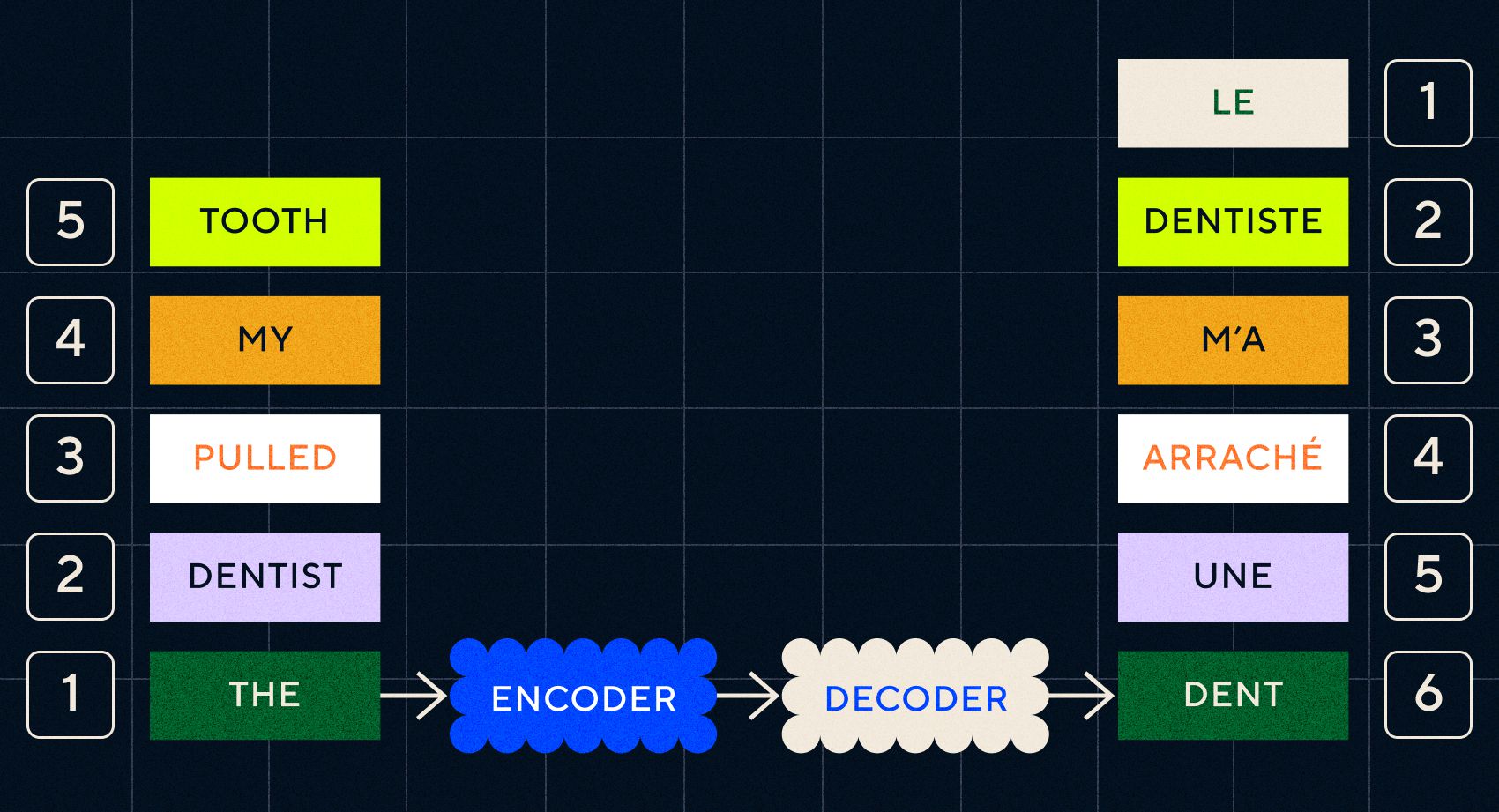
بمجرد أن يقوم برنامج التشفير بمعالجة المدخلات في كل خطوة، يبدأ بعد ذلك في تمرير الإخراج إلى جهاز فك التشفير الذي يحول التضمينات إلى نص مترجم.
يمكننا أن نرى مع تطور هذه النماذج أنها بدأت تشبه، بشكل بسيط، ما نراه اليوم مع ChatGPT. ومع ذلك، يمكننا أيضًا أن نرى مدى محدودية هذه النماذج بالمقارنة. كما هو الحال مع تطور لغتنا، لتحسين قدراتنا اللغوية حقًا، نحتاج إلى معرفة ما يجب الانتباه إليه بالضبط من أجل إنشاء عبارات وجمل أكثر تعقيدًا.
النموذج 3 - التعلم عن طريق الاهتمام والقياس باستخدام المحولات
لاحظنا سابقًا أن المراحل التلغرافية هي التي يبدأ فيها الأطفال بتكوين جمل قصيرة مكونة من كلمتين أو أكثر. أحد الجوانب الرئيسية لهذه المرحلة من اكتساب اللغة هو أن الأطفال يبدأون في تعلم كيفية بناء الجمل المناسبة.
ساعدت نماذج RNNs وSeq2Seq نماذج اللغة على معالجة تسلسلات متعددة من الكلمات، لكنها كانت لا تزال محدودة في أطوال الجمل التي يمكنها معالجتها. مع زيادة طول الجملة، نحتاج إلى الاهتمام بمعظم الأشياء في الجملة.
على سبيل المثال، خذ الجملة التالية "كان هناك الكثير من التوتر في الغرفة بحيث يمكنك قطعه بسكين". هناك الكثير يحدث هناك. لكي نعرف أننا لا نقطع شيئًا ما بسكين حرفيًا هنا، نحتاج إلى ربط كلمة "قطع" بكلمة "توتر" في بداية الجملة.
مع زيادة طول الجملة، يصبح من الصعب معرفة الكلمات التي تشير إليها من أجل استنتاج المعنى الصحيح. هذا هو المكان الذي بدأت فيه RNNs تواجه حدودًا وكنا بحاجة إلى نموذج جديد للانتقال إلى المرحلة التالية من اكتساب اللغة.
"فكر في محاولة تلخيص محادثة لأنها تصبح أطول وأطول مع حد ثابت من الكلمات. في كل خطوة تبدأ في فقدان المزيد والمزيد من المعلومات.
في عام 2017، نشر مجموعة من الباحثين في جوجل ورقة بحثية تقترح تقنية لتمكين النماذج من الاهتمام بشكل أفضل بالسياق المهم في جزء من النص.
ما طوروه كان طريقة لنماذج اللغة للبحث بسهولة أكبر عن السياق الذي يحتاجونه أثناء معالجة تسلسل إدخال النص. وقد أطلقوا على هذا النهج اسم "هندسة المحولات"، وكان يمثل أكبر قفزة إلى الأمام في معالجة اللغة الطبيعية حتى الآن.
تسهل آلية البحث هذه على النموذج تحديد أي من الكلمات السابقة توفر سياقًا أكبر للكلمة الحالية التي تتم معالجتها. تحاول شبكات RNN توفير السياق عن طريق تمرير حالة مجمعة لجميع الكلمات التي تمت معالجتها بالفعل في كل خطوة. فكر في محاولة تلخيص محادثة لأنها تصبح أطول وأطول مع حد ثابت من الكلمات. في كل خطوة تبدأ في فقدان المزيد والمزيد من المعلومات. بدلاً من ذلك، تقوم المحولات بوزن الكلمات (أو الرموز، التي ليست كلمات كاملة بل أجزاء من الكلمات) بناءً على أهميتها للكلمة الحالية من حيث سياقها. وهذا جعل من السهل معالجة تسلسلات أطول وأطول من الكلمات دون الاختناق الذي يظهر في شبكات RNN. سمحت آلية الاهتمام الجديدة هذه أيضًا بمعالجة النص بالتوازي بدلاً من التسلسل مثل RNN.
لذا تخيل جملة مثل "الحيوان لم يعبر الشارع لأنه كان متعبًا للغاية". بالنسبة إلى RNN، يجب أن تمثل جميع الكلمات السابقة في كل خطوة. مع زيادة عدد الكلمات بين "it" و"animal" يصبح من الصعب على RNN تحديد السياق المناسب.

بفضل بنية المحولات، يتمتع النموذج الآن بالقدرة على البحث عن الكلمة التي من المرجح أن تشير إلى "it". يوضح الرسم البياني أدناه كيف أن نماذج المحولات قادرة على التركيز على الجزء "الحيواني" من النص أثناء محاولتها معالجة الجملة.
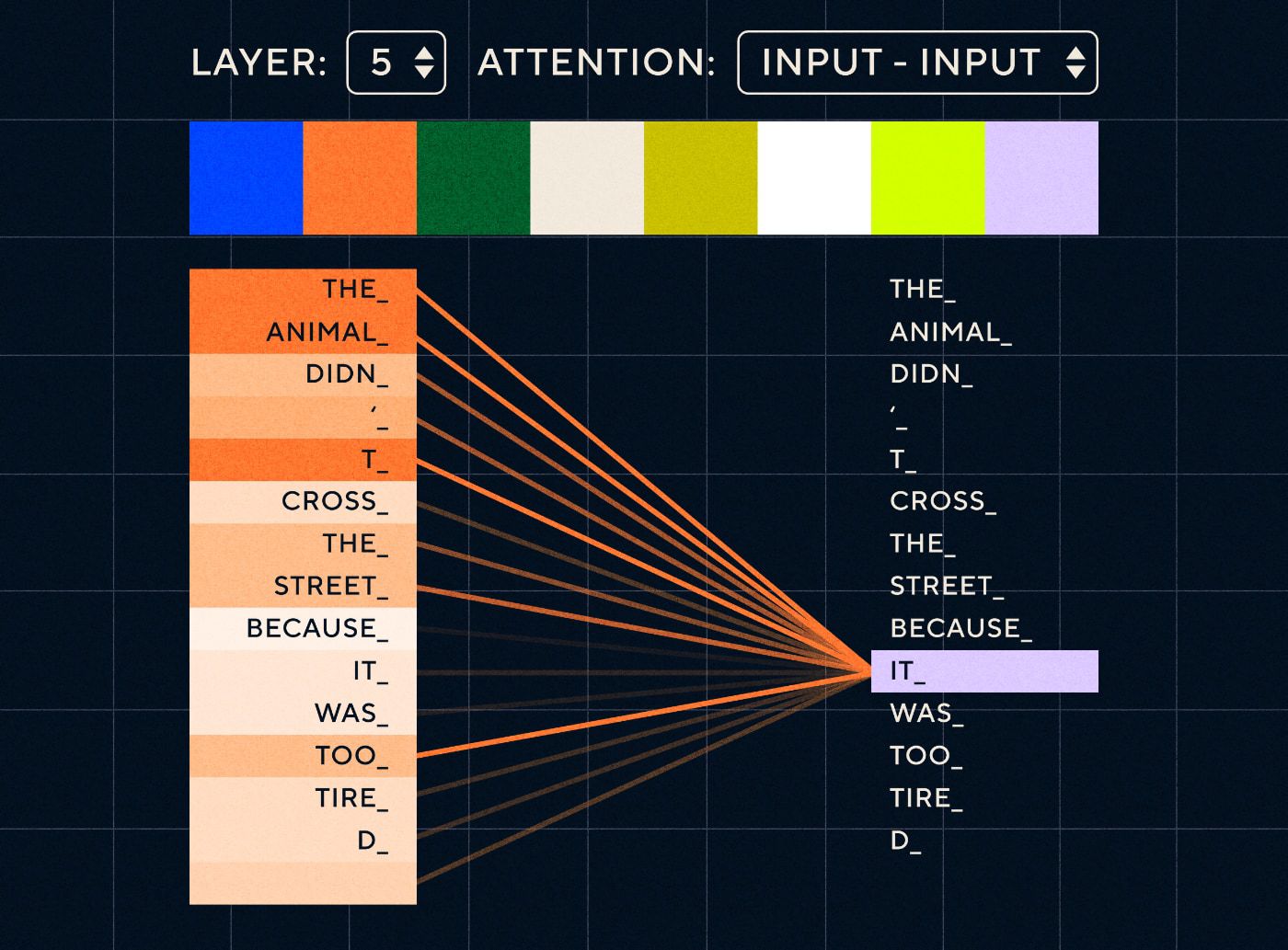
المصدر: المحول المصور
يوضح الرسم البياني أعلاه الانتباه عند الطبقة 5 من الشبكة. في كل طبقة، يقوم النموذج ببناء فهمه للجملة و"الانتباه إلى" جزء معين من المدخلات الذي يعتقد أنه أكثر صلة بالخطوة التي يقوم بمعالجتها في ذلك الوقت، أي أنه يولي المزيد من الاهتمام إلى "الخطوة التي يقوم بمعالجتها في ذلك الوقت". "حيوان" لـ "هو" في هذه الطبقة. المصدر : المحول المصور
فكر في الأمر كقاعدة بيانات حيث يمكنها استرداد الكلمة ذات أعلى الدرجات والتي من المرجح أن تكون مرتبطة بـ "it".
ومع هذا التطور، لم تقتصر النماذج اللغوية على تحليل التسلسلات النصية القصيرة. بدلاً من ذلك، يمكنك استخدام تسلسلات نصية أطول كمدخلات. نحن نعلم أن تعريض الأطفال لمزيد من الكلمات من خلال "المحادثة المتفاعلة" يساعد في تحسين تطور لغتهم.
وبالمثل، مع آلية الانتباه الجديدة، تمكنت النماذج اللغوية من تحليل أنواع أكثر ومتنوعة من بيانات التدريب النصية. يتضمن ذلك مقالات ويكيبيديا، ومنتديات الإنترنت، وتويتر، وأي بيانات نصية أخرى يمكنك تحليلها. وكما هو الحال مع تنمية الطفولة، فإن التعرض لكل هذه الكلمات واستخدامها في سياقات مختلفة ساعد نماذج اللغة على تطوير قدرات لغوية جديدة وأكثر تعقيدًا.
في هذه المرحلة بدأنا نرى سباقًا للتوسع حيث قام الأشخاص بإلقاء المزيد والمزيد من البيانات على هذه النماذج لمعرفة ما يمكنهم تعلمه. ولم تكن هناك حاجة إلى تصنيف هذه البيانات من قبل البشر، حيث يمكن للباحثين فقط تصفح الإنترنت وإدخالها إلى النموذج ومعرفة ما تعلمه.
"لقد حطمت نماذج مثل BERT كل الأرقام القياسية المتاحة لمعالجة اللغات الطبيعية. في الواقع، كانت مجموعات بيانات الاختبار التي تم استخدامها لهذه المهام بسيطة للغاية بالنسبة لنماذج المحولات هذه.
يستحق نموذج BERT (تمثيلات التشفير ثنائية الاتجاه من المحولات) إشارة خاصة لعدة أسباب. لقد كان أحد النماذج الأولى التي استخدمت ميزة الانتباه التي تمثل جوهر بنية المحولات. أولاً، كان BERT ثنائي الاتجاه حيث يمكنه النظر إلى النص على يسار ويمين الإدخال الحالي. كان هذا مختلفًا عن شبكات RNN التي يمكنها فقط معالجة النص بالتسلسل من اليسار إلى اليمين. ثانيًا، استخدم BERT أيضًا تقنية تدريب جديدة تسمى "الإخفاء"، والتي، بطريقة ما، أجبرت النموذج على تعلم معنى المدخلات المختلفة عن طريق "إخفاء" أو "إخفاء" الرموز المميزة العشوائية لضمان عدم قدرة النموذج على "الغش" و التركيز على رمز واحد في كل تكرار. وأخيرًا، يمكن ضبط BERT بشكل دقيق لأداء مهام البرمجة اللغوية العصبية المختلفة. ولم يكن من الضروري تدريبها من الصفر على هذه المهام.
وكانت النتائج مذهلة. نماذج مثل BERT حطمت كل الأرقام القياسية المتاحة لمعالجة اللغات الطبيعية. في الواقع، كانت مجموعات بيانات الاختبار التي تم استخدامها لهذه المهام بسيطة للغاية بالنسبة لنماذج المحولات هذه.
الآن لدينا القدرة على تدريب نماذج لغوية كبيرة والتي كانت بمثابة النماذج الأساسية لمهام معالجة اللغة الطبيعية الجديدة. في السابق، كان الناس في الغالب يدربون نماذجهم من الصفر. ولكن الآن أصبحت النماذج المدربة مسبقًا مثل BERT ونماذج GPT المبكرة جيدة جدًا لدرجة أنه لم يكن هناك أي فائدة من القيام بذلك بنفسك. في الواقع، كانت هذه النماذج عبارة عن أشخاص جيدين جدًا اكتشفوا أنهم يستطيعون أداء مهام جديدة بأمثلة قليلة نسبيًا - وقد تم وصفهم بأنهم "متعلمون قليلون"، على غرار الطريقة التي لا يحتاج بها معظم الناس إلى الكثير من الأمثلة لفهم المفاهيم الجديدة.
وكانت هذه نقطة انعطاف هائلة في تطور هذه النماذج وقدراتها اللغوية. الآن نحن بحاجة فقط إلى التحسن في صياغة التعليمات.
النموذج 4 - تعليمات التعلم باستخدام InstructGPT
من الأشياء التي يتعلمها الأطفال في المرحلة الأخيرة من اكتساب اللغة، مرحلة الكلمات المتعددة، هي القدرة على استخدام الكلمات الوظيفية لربط العناصر التي تحمل المعلومات في الجملة. تخبرنا الكلمات الوظيفية عن العلاقة بين الكلمات المختلفة في الجملة. إذا أردنا إنشاء تعليمات، فيجب أن تكون نماذج اللغة قادرة على إنشاء جمل تحتوي على كلمات محتوى وكلمات وظيفية تلتقط العلاقات المعقدة. على سبيل المثال، تحتوي التعليمات التالية على الكلمات الوظيفية المميزة بالخط العريض:
- " أريدك أن تكتب رسالة..."
- " أخبرني ما رأيك في النص أعلاه "
ولكن قبل أن نتمكن من محاولة تدريب النماذج اللغوية على اتباع التعليمات، كان علينا أن نفهم بالضبط ما يعرفونه عن التعليمات بالفعل.
تم إصدار GPT-3 من OpenAI في عام 2020. وكانت هذه لمحة عما تستطيع هذه النماذج فعله ولكننا ما زلنا بحاجة إلى فهم كيفية إطلاق القدرات الأساسية لهذه النماذج. كيف يمكننا التفاعل مع هذه النماذج لحملها على أداء مهام مختلفة؟
على سبيل المثال، أظهر GPT-3 أن زيادة حجم النموذج وبيانات التدريب مكنت ما أطلق عليه المؤلفون "التعلم الفوقي" - وهذا هو المكان الذي يطور فيه نموذج اللغة مجموعة واسعة من القدرات اللغوية، وكثير منها غير متوقع، ويمكنه استخدام تلك القدرات. المهارات اللازمة لفهم مهمة معينة.
"هل سيكون النموذج قادرًا على فهم القصد من التعليمات وتنفيذ المهمة بدلاً من مجرد التنبؤ بالكلمة التالية؟"
تذكر أن نماذج GPT-3 والنماذج اللغوية السابقة لم تكن مصممة لتطوير هذه المهارات، بل تم تدريبها في الغالب على التنبؤ بالكلمة التالية في تسلسل النص. ولكن من خلال التقدم في RNNs وSeq2Seq وشبكات الانتباه، تمكنت هذه النماذج من معالجة المزيد من النصوص، في تسلسلات أطول والتركيز بشكل أفضل على السياق ذي الصلة.
يمكنك التفكير في GPT-3 كاختبار لمعرفة إلى أي مدى يمكننا الوصول إلى هذا. ما حجم النماذج التي يمكننا صنعها وما حجم النص الذي يمكننا تغذيته؟ ثم بعد القيام بذلك، بدلاً من مجرد تغذية النموذج ببعض نص الإدخال حتى يكتمل، يمكننا استخدام نص الإدخال كتعليمات. هل سيكون النموذج قادرًا على فهم القصد من التعليمات وتنفيذ المهمة بدلاً من مجرد التنبؤ بالكلمة التالية؟ بطريقة ما، كان الأمر أشبه بمحاولة فهم المرحلة التي وصلت إليها هذه النماذج في اكتساب اللغة.
نحن نصف هذا الآن بأنه "محفز"، ولكن في عام 2020، في الوقت الذي صدرت فيه الورقة البحثية، كان هذا مفهومًا جديدًا للغاية.
الهلوسة والمحاذاة
كانت مشكلة GPT-3، كما نعلم الآن، هي أنها لم تكن جيدة في الالتزام الدقيق بالتعليمات الواردة في نص الإدخال. يستطيع GPT-3 اتباع التعليمات ولكنه يفقد الانتباه بسهولة، ولا يمكنه سوى فهم التعليمات البسيطة ويميل إلى اختلاق الأشياء. وبعبارة أخرى، فإن النماذج لا "تتماشى" مع نوايانا. لذا فإن المشكلة الآن لا تتعلق بتحسين القدرة اللغوية للنماذج، بل بقدرتها على اتباع التعليمات.
ومن الجدير بالذكر أن GPT-3 لم يتم تدريبه مطلقًا على التعليمات. ولم يتم إخباره ما هي التعليمات، أو كيف يختلف عن النص الآخر، أو كيف كان من المفترض أن يتبع التعليمات. بطريقة ما، تم "خداعه" لاتباع التعليمات من خلال جعله "يكمل" مطالبة مثل تسلسلات النص الأخرى. ونتيجة لذلك، كان OpenAI بحاجة إلى تدريب نموذج أكثر قدرة على اتباع التعليمات مثل الإنسان. وقد فعلوا ذلك في ورقة بحثية بعنوان تدريب نماذج اللغة لمتابعة التعليمات مع التعليقات البشرية المنشورة في أوائل عام 2022. وسيثبت InstructGPT أنه مقدمة لـ ChatGPT في وقت لاحق من نفس العام.
تم أيضًا استخدام الخطوات الموضحة في تلك الورقة لتدريب ChatGPT. اتبع التدريب على التدريس ثلاث خطوات رئيسية:
- الخطوة 1 - ضبط GPT-3: نظرًا لأن GPT-3 يبدو أنه يعمل بشكل جيد من خلال التعلم بعدد قليل من اللقطات، فقد كان التفكير هو أنه سيكون من الأفضل إذا تم ضبطه بشكل دقيق على أمثلة تعليمات عالية الجودة. كان الهدف هو تسهيل مواءمة النية في التعليمات مع الاستجابة التي تم إنشاؤها. للقيام بذلك، طلبت OpenAI من واضعي العلامات البشرية إنشاء استجابات لبعض المطالبات التي أرسلها الأشخاص الذين يستخدمون GPT-3. باستخدام تعليمات حقيقية، كان المؤلفون يأملون في الحصول على "توزيع" واقعي للمهام التي كان المستخدمون يحاولون جعل GPT-3 يؤديها. وقد تم استخدام هذه لضبط GPT-3 لمساعدته على تحسين قدرته على الاستجابة السريعة.
- الخطوة 2 - اطلب من البشر تصنيف GPT-3 الجديد والمحسن: لتقييم التعليمات الجديدة المضبوطة بدقة لـ GPT-3، قام واضعو العلامات الآن بتقييم أداء النماذج بناءً على مطالبات مختلفة دون أي استجابة محددة مسبقًا. كان الترتيب مرتبطًا بعوامل توافق مهمة مثل أن يكون مفيدًا، وصادقًا، وغير سام، أو متحيزًا، أو ضارًا. لذا، قم بإعطاء النموذج مهمة وتقييم أدائه بناءً على هذه المقاييس. تم بعد ذلك استخدام مخرجات تمرين التصنيف هذا لتدريب نموذج منفصل للتنبؤ بالمخرجات التي من المرجح أن يفضلها واضعو العلامات. يُعرف هذا النموذج بنموذج المكافأة (RM).
- الخطوة 3 - استخدم RM للتدريب على المزيد من الأمثلة: أخيرًا، تم استخدام RM لتدريب نموذج التعليمات الجديد لتوليد استجابات أفضل تتوافق مع التفضيلات البشرية.
من الصعب أن نفهم بشكل كامل ما يحدث هنا من خلال التعلم المعزز من التعليقات البشرية (RLHF)، ونماذج المكافآت، وتحديثات السياسة، وما إلى ذلك.
إحدى الطرق البسيطة للتفكير في الأمر هي أنها مجرد وسيلة لتمكين البشر من توليد أمثلة أفضل حول كيفية اتباع التعليمات. على سبيل المثال، فكر في الطريقة التي ستحاول بها تعليم الطفل أن يقول شكرًا:
- الوالد: "عندما يعطيك شخص ما X، قل شكرًا لك". هذه هي الخطوة 1، وهي مجموعة بيانات نموذجية للمطالبات والاستجابات المناسبة
- الوالد: "الآن، ماذا تقول لـ Y هنا؟". هذه هي الخطوة 2 حيث نطلب من الطفل إنشاء إجابة ومن ثم سيقوم الوالد بتقييم ذلك. "نعم هذا جيد."
- أخيرًا، في اللقاءات اللاحقة، سيكافئ الوالد الطفل بناءً على أمثلة جيدة أو سيئة للاستجابات في سيناريوهات مماثلة في المستقبل. هذه هي الخطوة 3، حيث يحدث السلوك التعزيزي.
من جانبها، تدعي شركة OpenAI أن كل ما تفعله هو ببساطة إطلاق العنان للقدرات التي كانت موجودة بالفعل في نماذج مثل GPT-3، "ولكن كان من الصعب استنباطها من خلال الهندسة السريعة وحدها"، على حد تعبير الورقة البحثية.
بمعنى آخر، لا يتعلم ChatGPT حقًا القدرات " الجديدة "، ولكنه يتعلم ببساطة " واجهة " لغوية أفضل للاستفادة منها.
سحر اللغة
يبدو ChatGPT وكأنه قفزة سحرية إلى الأمام، ولكنه في الواقع نتيجة للتقدم التكنولوجي المضني على مدى عقود.
من خلال النظر إلى بعض التطورات الرئيسية في مجال الذكاء الاصطناعي والبرمجة اللغوية العصبية في العقد الماضي، يمكننا أن نرى كيف يقف ChatGPT على أكتاف العمالقة. تعلمت النماذج السابقة لأول مرة كيفية تحديد معنى الكلمات. ثم تقوم النماذج اللاحقة بتجميع هذه الكلمات معًا ويمكننا تدريبها على أداء مهام مثل الترجمة. وبمجرد أن يتمكنوا من معالجة الجمل، قمنا بتطوير تقنيات مكنت نماذج اللغة هذه من معالجة المزيد والمزيد من النصوص وتطوير القدرة على تطبيق هذه الدروس على مهام جديدة وغير متوقعة. وبعد ذلك، باستخدام ChatGPT، قمنا أخيرًا بتطوير القدرة على التفاعل بشكل أفضل مع هذه النماذج من خلال تحديد تعليماتنا بتنسيق لغة طبيعية.
"بما أن اللغة هي وسيلة أفكارنا، فهل يؤدي تعليم أجهزة الكمبيوتر القوة الكاملة للغة إلى ذكاء اصطناعي مستقل؟"
ومع ذلك، فإن تطور البرمجة اللغوية العصبية يكشف عن سحر أعمق عادة ما نكون عميانًا عنه، ألا وهو سحر اللغة نفسها وكيف نكتسبها كبشر.
لا تزال هناك العديد من الأسئلة والخلافات المفتوحة حول كيفية تعلم الأطفال للغة في المقام الأول. هناك أيضًا أسئلة حول ما إذا كان هناك بنية أساسية مشتركة لجميع اللغات. هل تطور البشر لاستخدام اللغة أم أن الأمر هو العكس؟
والأمر الغريب هو أنه بينما يقوم ChatGPT وأتباعه بتحسين تطورهم اللغوي، فإن هذه النماذج قد تساعد في الإجابة على بعض هذه الأسئلة المهمة.
وأخيرًا، بما أن اللغة هي وسيلة نقل أفكارنا، فهل سيؤدي تعليم أجهزة الكمبيوتر القوة الكاملة للغة إلى ذكاء اصطناعي مستقل؟ كما هو الحال دائمًا في الحياة، لا يزال هناك الكثير لنتعلمه.
