
قرصنة الرسم البياني للموضوع باستخدام Wikipedia و Google Language API
نشرت: 2019-08-27أحد مجموعات الشرائح المفضلة لدي من السنوات العشر الماضية قام به مارك جونستون في عام 2014 ، بينما كان لا يزال مع Distilled. أطلق على المجموعة اسم How to Produce Better Content Ideas واستخدمتها على أنها كتابي المقدس لبضع سنوات أثناء تكوين فرق للقيام بالعمل الشاق المتمثل في ترويج المحتوى.
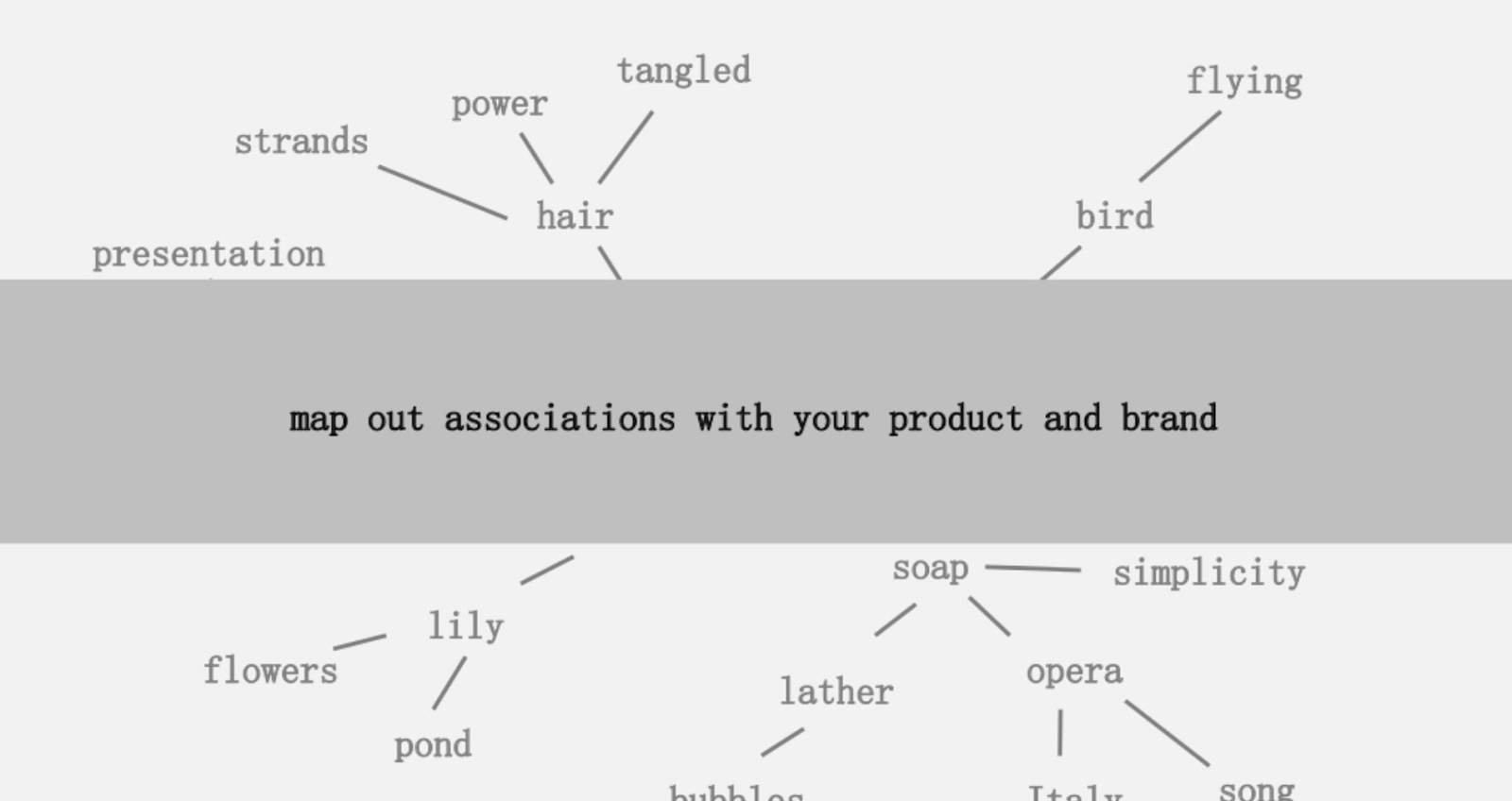
كانت إحدى الأفكار المقدمة هي إنشاء مخطط مرئي لترابط الكلمات المرتبطة بمنتجك أو علامتك التجارية بحيث يمكنك التراجع والبحث عن طرق لدمج الارتباطات في شيء مثير للاهتمام. الهدف هو إنتاج الأفكار ، والتي يعرّفها على أنها " مزيج جديد من العناصر غير المترابطة سابقًا بطريقة تضيف قيمة".
في هذه المقالة ، نتبنى نهجًا أكثر بكثير من الدماغ الأيسر ، باستخدام Python ، واجهة برمجة تطبيقات اللغة من Google ، جنبًا إلى جنب مع Wikipedia ، لاستكشاف ارتباطات الكيانات الموجودة من موضوع أولي. الهدف هو عرض عالي المستوى لعلاقات الكيانات على طول الرسم البياني للموضوع. هذه المقالة ليست للقارئ العادي. القراء الذين هم على دراية ببايثون ولديهم على الأقل مستوى أساسي من القدرة على الترميز سيجدونها أكثر إفادة.
الفكرة
متابعةً لفكرة تعيين مارك جونستون ، اعتقدت أنه سيكون من المثير للاهتمام السماح لـ Google و Wikipedia بتحديد هيكل موضوع بدءًا من موضوع أولي أو صفحة ويب. الهدف هو بناء مخطط للعلاقات مع الموضوع الرئيسي بصريًا ، في رسم بياني يشبه الشجرة يمكن مراجعته للبحث عن روابط وربما إنشاء أفكار للمحتوى. الصورة التالية تمثل فكرة التصميم الأولية.
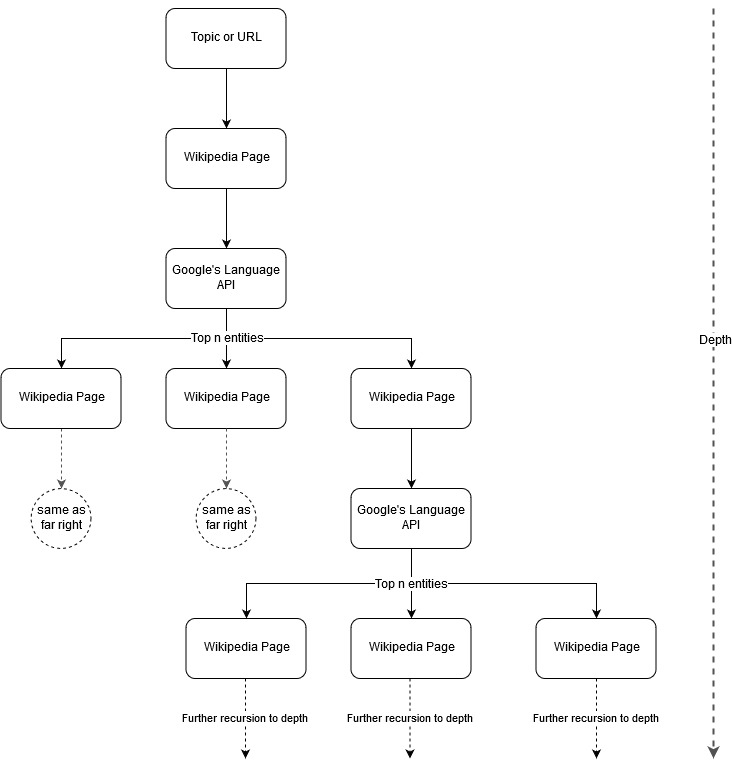
بشكل أساسي ، نعطي الأداة موضوعًا أو عنوان URL ، ونسمح لـ Google's Language API بتحديد الكيانات n (3 في أمثلةنا) (التي تتضمن عناوين URL لـ Wikipedia) لكل صفحة كيان ، ونستمر بشكل متكرر في إنشاء رسم بياني للشبكة لكل كيان تم العثور عليه لأقصى عمق.
خلفية الأدوات المستخدمة
واجهة برمجة تطبيقات لغة Google
تسمح لك واجهة برمجة تطبيقات اللغة من Google بتمريرها إما بنص عادي أو HTML وتقوم بطريقة سحرية بإرجاع جميع الكيانات المختلفة المرتبطة بالمحتوى. تقوم واجهة برمجة التطبيقات بأكثر من ذلك ، ولكن بالنسبة لهذا التحليل ، سنركز فقط على هذا الجزء. فيما يلي قائمة بأنواع الكيانات التي يقوم بإرجاعها:
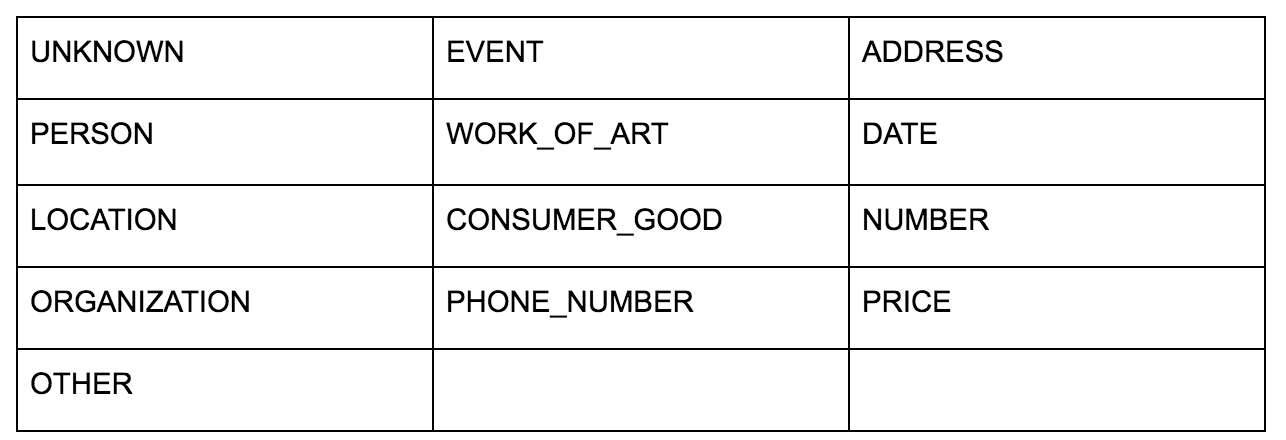
كان تحديد الكيان جزءًا أساسيًا من معالجة اللغة الطبيعية (NLP) لفترة طويلة والمصطلحات الصحيحة للمهمة هي التعرف على الكيان المسمى (NER). تعد NER مهمة صعبة لأن العديد من الكلمات لها معاني مختلفة بناءً على السياق المستخدم لذلك يجب على أدوات البرمجة اللغوية العصبية أو واجهات برمجة التطبيقات فهم السياق الكامل المحيط بالمصطلحات حتى تتمكن من تحديدها بشكل صحيح ككيان معين.
لقد قدمت نظرة عامة مفصلة جدًا عن واجهة برمجة التطبيقات هذه ، والكيانات على وجه الخصوص ، في مقال على openource.com إذا كنت تريد اللحاق ببعض السياق قبل الانتهاء من هذه المقالة.
تتمثل إحدى الميزات المثيرة للاهتمام في واجهة برمجة تطبيقات اللغة في Google ، بالإضافة إلى البحث عن الكيانات ذات الصلة ، في تحديد مدى ارتباطها بالمستند العام (الأهمية) ، وبالنسبة للبعض ، توفر مقالة Wikipedia (الرسم البياني المعرفي) ذات الصلة تمثل الكيان.
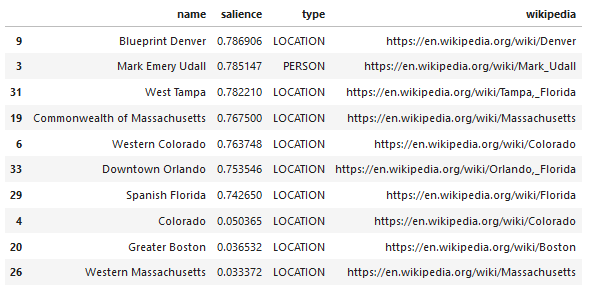
فيما يلي عينة من ما تقوم بإرجاعه واجهة برمجة التطبيقات (مرتبة حسب الأهمية):
مطور Oncrawl
 يتعلم أكثر
يتعلم أكثربايثون
Python هي لغة برمجية أصبحت شائعة في مجال علوم البيانات بسبب مجموعة كبيرة ومتنامية من المكتبات التي تجعل من السهل استيعاب مجموعات البيانات الكبيرة وتنظيفها ومعالجتها وتحليلها. كما أنها تستفيد من بيئة تعاونية تسمى دفاتر Jupyter والتي تتيح للمستخدمين اختبار التعليمات البرمجية الخاصة بهم بسهولة والتعليق عليها بطريقة سهلة.
في هذه المراجعة ، سنستخدم عددًا قليلاً من المكتبات الرئيسية التي ستسمح لنا بالقيام ببعض الأشياء المثيرة للاهتمام باستخدام بيانات البرمجة اللغوية العصبية الخاصة بـ Google.
- Pandas: فكر في القدرة على برمجة برنامج Microsoft Excel لقراءة جداول البيانات أو حفظها أو تحليلها أو إعادة ترتيبها وستحصل على فكرة عما يفعله Pandas. الباندا أمر مذهل. (حلقة الوصل)
- Networkx: Networkx هي أداة لإنشاء الرسوم البيانية للعقد والحواف التي تحدد العلاقات بين العقد. كما أن لديها دعمًا يحمل في ثناياه عوامل لتخطيط الرسوم البيانية بحيث يسهل تصورها. (حلقة الوصل)
- Pywikibot: Pywikibot هي مكتبة تسمح لك بالتفاعل مع ويكيبيديا للبحث ، والتعديل ، والعثور على العلاقات ، وما إلى ذلك ، مع كل محتوى كل موقع من مواقع ويكيبيديا. (حلقة الوصل)
العملية
نشارك هنا دفتر ملاحظات Google Colab يمكن استخدامه للمتابعة. (شكر خاص لتايلر ريردون للتحقق من صحة المقالة وهذا دفتر الملاحظات.)
اعداد
تتعامل الخلايا القليلة الأولى في دفتر الملاحظات مع تثبيت بعض المكتبات ، وإتاحة تلك المكتبات لبايثون ، وتوفير بيانات اعتماد وملف تكوين لـ Google Language API و Pywikibot ، على التوالي. إليك جميع المكتبات التي نحتاج إلى تثبيتها لضمان إمكانية تشغيل الأداة:
- الباندا
- الطلبات
- HTplib2
- google-cloud-language
- Pywikibot
- الشبكة x
- المدققين
- بكالوريوس 4
ملاحظة: الجزء الأصعب في القدرة على تشغيل هذا الكمبيوتر الدفتري هو الحصول على بيانات اعتماد من Google للوصول إلى واجهات برمجة التطبيقات الخاصة بهم. بالنسبة لأولئك الذين لا يتمتعون بالخبرة في هذا الأمر ، سيستغرق ذلك ساعة أو نحو ذلك لمعرفة ذلك. لقد ربطنا تعليمات الحصول على بيانات اعتماد حساب الخدمة في الجزء العلوي من دفتر الملاحظات لمساعدتك. فيما يلي مثال على كيفية تضميننا لنا.

وظائف الفوز
في الخلية المشار إليها بواسطة "تحديد بعض الوظائف لـ Google NLP" ، نقوم بتطوير ثماني وظائف تتعامل مع أشياء مثل الاستعلام عن واجهة برمجة تطبيقات اللغة ، والتفاعل مع ويكيبيديا ، واستخراج نص صفحة الويب ، وبناء الرسوم البيانية ورسمها. الوظائف هي في الأساس وحدات صغيرة من التعليمات البرمجية تأخذ بعض بيانات الإعدادات ، وتقوم ببعض الأعمال ، وتنتج شيئًا ما. يتم التعليق على جميع الوظائف لإخبار المتغيرات التي تدخلها ، وما تنتجه.
اختبار API
تأخذ الخليتان التاليتان عنوان URL ، وتستخرج النص من عنوان URL ، وتسحب الكيانات من واجهة برمجة تطبيقات اللغة في Google. يقوم أحدهم بسحب الكيانات التي لها عناوين URL لـ Wikipedia والآخر يسحب جميع الكيانات من تلك الصفحة.
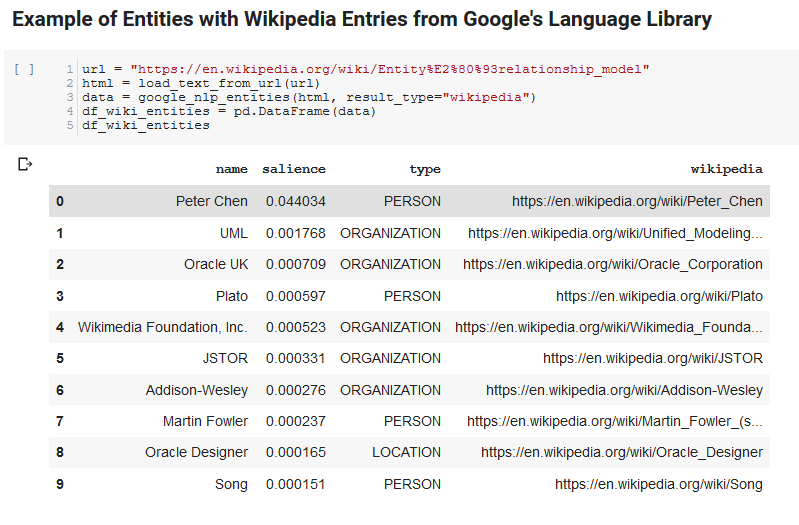
كانت هذه خطوة أولى مهمة فقط لتصحيح جزء استخراج المحتوى وفهم كيفية عمل واجهة برمجة تطبيقات اللغة وإرجاع البيانات.
الشبكة x
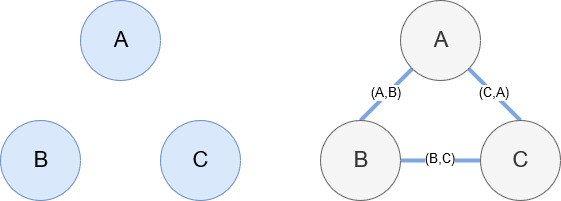
Networkx ، كما ذكرنا سابقًا ، هي مكتبة رائعة يسهل اللعب بها. بشكل أساسي ، عليك أن تخبرها ما هي العقد الخاصة بك وكيف ترتبط العقد. على سبيل المثال ، في الصورة أدناه ، نعطي Networkx ثلاث عقد (A ، B ، C). ثم نخبر Networkx أنها متصلة بواسطة الحواف (A ، B) ، (B ، C) ، (C ، A) تحدد العلاقات بين العقد. لاستخدامنا ، ستكون الكيانات التي تحتوي على عناوين URL لـ Wikipedia هي العقد ويتم تحديد الحواف بواسطة كيانات جديدة يتم العثور عليها في صفحة الكيان الحالية. لذلك ، إذا كنا نراجع صفحة ويكيبيديا للكيان أ ، وفي تلك الصفحة ، تم اكتشاف الكيان ب ، فهذه ميزة بين الكيان أ والكيان ب.
ضع كل شيء معا
القسم التالي من دفتر الملاحظات يسمى Wikipedia Topic Branching بواسطة URL. هذا هو المكان الذي يحدث السحر. لقد حددنا وظيفة خاصة (recurse_entities) في وقت سابق تتكرر من خلال صفحات على Wikipedia تتبع الكيانات الجديدة المحددة بواسطة واجهة برمجة تطبيقات لغة Google. أضفنا أيضًا وظيفة محرجة حقًا للفهم (hierarchy_pos) التي رفعناها من Stack Overflow والتي تقوم بعمل جيد في تقديم رسم بياني يشبه الشجرة مع العديد من العقد. في الخلية أدناه ، نحدد الإدخال على أنه "تحسين محرك البحث" ونحدد عمق 3 (هذا هو عدد الصفحات التي تتبعها بشكل متكرر) ، والحد من 3 (هذا هو عدد الكيانات التي تسحبها لكل صفحة).
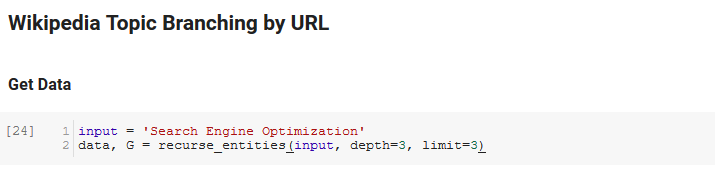
عند تشغيله لمصطلح "Search Engine Optimization" ، يمكننا أن نرى المسار التالي الذي سلكته الأداة ، بدءًا من صفحة تحسين محرك البحث في Wikipedia (المستوى 0) ، وبعد ذلك ، بشكل متكرر ، الصفحات حتى أقصى عمق محدد (3).

ثم نأخذ جميع الكيانات التي تم العثور عليها ونضيفها إلى Pandas DataFrame ، مما يجعل من السهل حقًا الحفظ كملف CSV. نقوم بفرز هذه البيانات حسب الأهمية (وهي مدى أهمية الكيان للصفحة التي تم العثور عليها فيها) ، ولكن هذه النتيجة مضللة بعض الشيء في هذا السياق لأنها لا تخبرك بمدى ارتباط الكيان بمصطلحك الأصلي (" محرك البحث الأمثل "). سنترك هذا العمل الإضافي للقارئ.

أخيرًا ، قمنا برسم الرسم البياني الذي أنشأته الأداة لإظهار الترابط بين جميع الكيانات. في الخلية أدناه ، المعلمات التي يمكنك تمريرها إلى الوظيفة هي: ( G : الرسم البياني الذي تم إنشاؤه مسبقًا بواسطة دالة recurse_entities ، w: عرض الرسم البياني ، h: ارتفاع الرسم البياني ، c: النسبة المئوية للدائرة المؤامرة واسم الملف: ملف PNG الذي تم حفظه في مجلد الصور.)

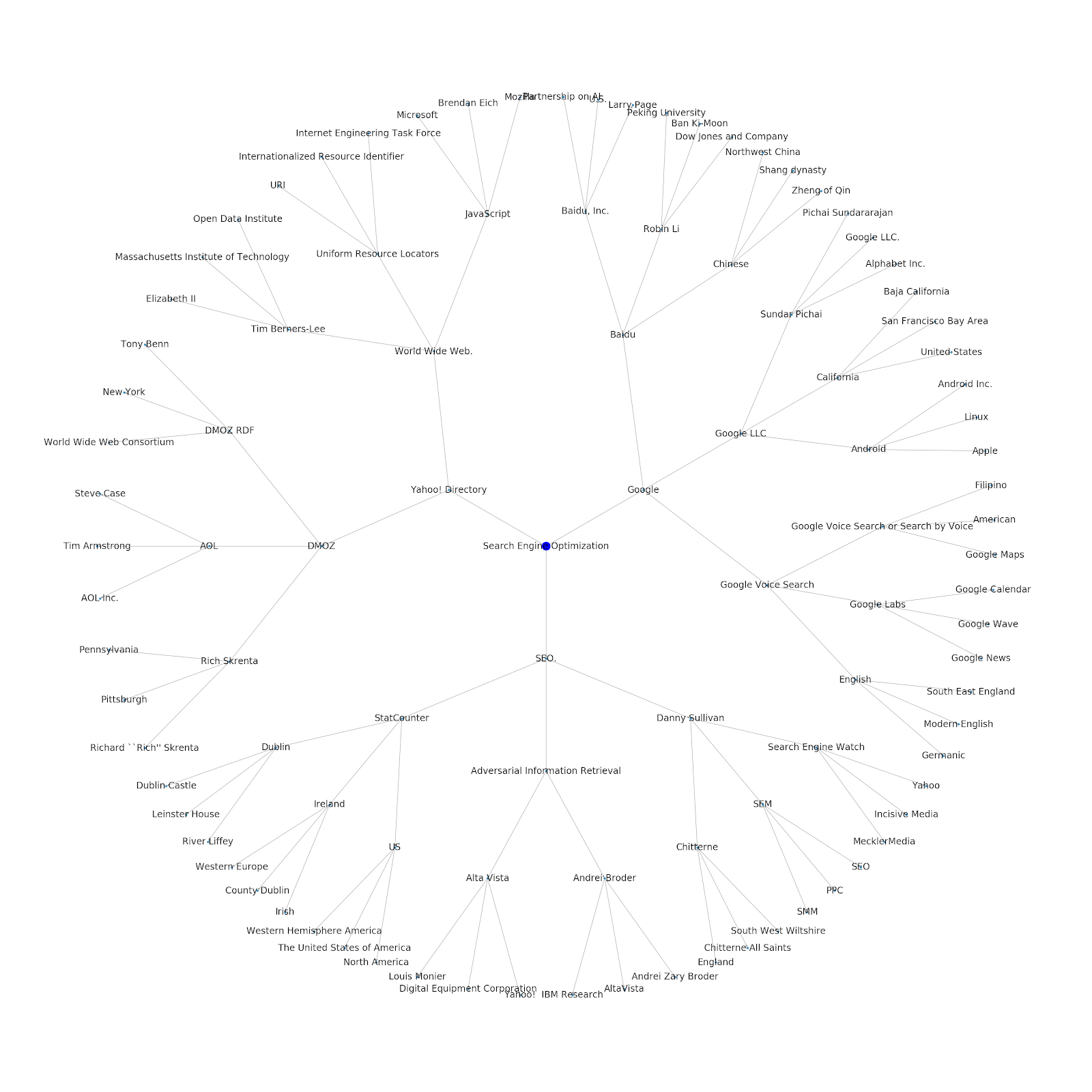
أضفنا القدرة على منحه موضوعًا أوليًا أو عنوان URL أوليًا. في هذه الحالة ، نلقي نظرة على الكيانات المرتبطة بالمقال تتمة مشكلات فهرسة Google ولكن هذا مختلف
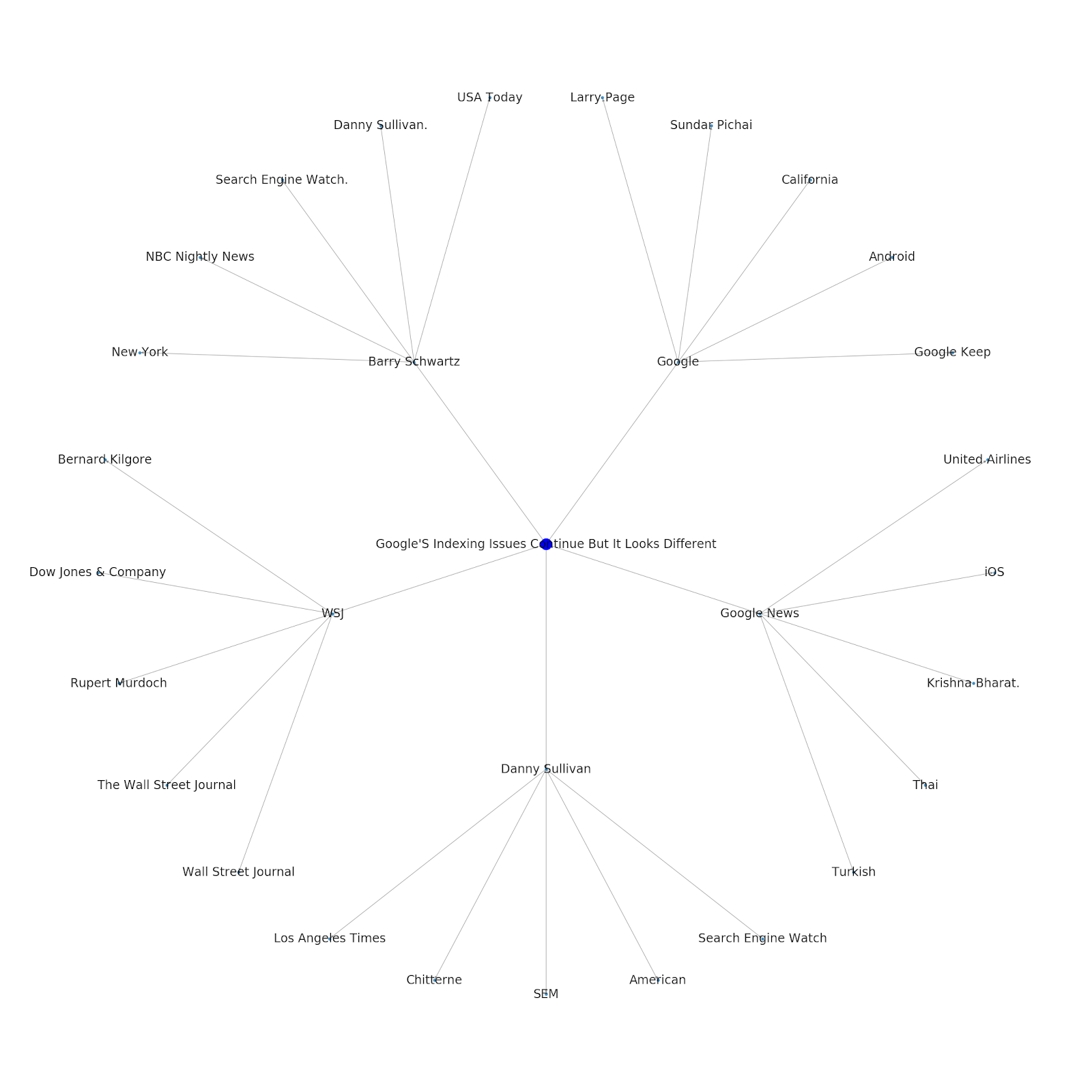
هذا هو الرسم البياني لكيان Google / Wikipedia لبيثون.
ماذا يعني هذا
يعد فهم طبقة الموضوعات على الإنترنت أمرًا مثيرًا للاهتمام من وجهة نظر تحسين محركات البحث لأنه يجبرك على التفكير فيما يتعلق بكيفية ارتباط الأشياء وليس فقط في الاستفسارات الفردية. نظرًا لأن Google تستخدم هذه الطبقة لمطابقة تقاربات المستخدمين الفرديين بالموضوعات ، كما هو مذكور في إعادة تقديم Google Discover الخاصة بهم ، فقد يصبح سير عمل أكثر أهمية بالنسبة إلى مُحسّنات محرّكات البحث التي تركز على البيانات. في الرسم البياني "Python" أعلاه ، قد يُستدل على أن إلمام المستخدم بالموضوعات المتعلقة بموضوع أولي قد يكون مقياسًا معقولاً لمستوى خبرته في الموضوع الأولي.
يوضح المثال أدناه مستخدمين مع إبرازات خضراء توضح اهتمامهما التاريخي أو تقاربهما بالموضوعات ذات الصلة. سيكون المستخدم الموجود على اليسار ، الذي يفهم ماهية IDE ، ويفهم ما تعنيه PyPy و CPython ، مستخدمًا أكثر خبرة مع Python ، من شخص يعرف أنها لغة ، ولكن ليس كثيرًا. سيكون من السهل تحويل هذا إلى درجات رقمية لكل موضوع ولكل مستخدم.

خاتمة
كان هدفي اليوم هو مشاركة عملية معيارية إلى حد ما أقوم بها لاختبار ومراجعة فعالية الأدوات أو واجهات برمجة التطبيقات المختلفة باستخدام Jupyter Notebooks. يعد استكشاف الرسم البياني للموضوع ممتعًا بشكل لا يصدق ونأمل أن تجد الأدوات التي تمت مشاركتها تمنحك السبق الذي تحتاجه لبدء الاستكشاف بنفسك. باستخدام هذه الأدوات ، يمكنك إنشاء رسوم بيانية للموضوعات تستكشف العديد من مستويات العلاقات ، والتي تقتصر فقط على مدى حصة واجهة برمجة تطبيقات اللغة من Google (والتي تبلغ 800000 يوميًا). (تحديث: يعتمد التسعير على وحدات مكونة من 1000 حرف يونيكود تم إرسالها إلى واجهة برمجة التطبيقات وهي مجانية حتى 5 آلاف وحدة. نظرًا لأن مقالات ويكيبيديا يمكن أن تطول ، فأنت تريد مراقبة إنفاقك. تلميح هات إلى جون مورش لتوضيح ذلك.) إذا قمت بتحسين دفتر الملاحظات أو وجدت حالات مثيرة للاهتمام ، آمل أن تخبرني بذلك. يمكنك أن تجدني فيjroakes على Twitter.