
مفاتيح بناء ملف Robots.txt يعمل
نشرت: 2020-02-18الروبوتات ، المعروفة أيضًا باسم برامج الزاحف أو العناكب ، هي برامج "تنتقل" عبر الويب تلقائيًا من موقع ويب إلى موقع ويب باستخدام الروابط باعتبارها الطريق. على الرغم من أنها قدمت دائمًا بعض الأشياء المثيرة للفضول ، إلا أن ملفات robot.txt يمكن أن تكون أدوات فعالة للغاية. تستخدم محركات البحث مثل Google و Bing برامج الروبوت للزحف إلى محتوى الويب. يوفر ملف robots.txt إرشادات لبرامج الروبوت المختلفة بشأن الصفحات التي لا يجب الزحف إليها على موقعك. يمكنك أيضًا الارتباط بخريطة موقع XML الخاصة بك من ملف robots.txt بحيث يكون لدى الروبوت خريطة لكل صفحة يجب الزحف إليها.
لماذا يعتبر ملف robots.txt مفيدًا؟
يحد ملف robots.txt من عدد الصفحات التي يحتاج الروبوت للزحف إليها وفهرستها في حالة روبوتات محرك البحث. إذا كنت تريد منع Google من الزحف إلى صفحات المسؤول ، فيمكنك حظرها في ملف robots.txt لمحاولة إبقاء الصفحة خارج خوادم Google.
إلى جانب منع الصفحات من الفهرسة ، يعد ملف robots.txt رائعًا لتحسين ميزانية الزحف. ميزانية الزحف هي عدد الصفحات التي حددت Google أنها ستقوم بالزحف إليها على موقعك. عادةً ما تتمتع مواقع الويب التي تتمتع بسلطة أكبر وعدد أكبر من الصفحات بميزانية زحف أكبر من مواقع الويب ذات عدد الصفحات المنخفض والسلطة المنخفضة. نظرًا لأننا لا نعرف مقدار ميزانية الزحف المخصصة لموقعنا ، فنحن نريد تحقيق أقصى استفادة من هذا الوقت من خلال السماح لبرنامج Googlebot بالوصول إلى الصفحات الأكثر أهمية بدلاً من الزحف إلى الصفحات التي لا نريد فهرستها.
من التفاصيل المهمة جدًا التي تحتاج إلى معرفتها حول ملف robots.txt أنه على الرغم من عدم قيام Google بالزحف إلى الصفحات التي تم حظرها بواسطة ملف robots.txt ، إلا أنه لا يزال من الممكن فهرستها إذا تم ربط الصفحة من موقع ويب آخر. لمنع فهرسة صفحاتك والظهور في نتائج بحث Google بشكل صحيح ، يلزمك حماية الملفات الموجودة على الخادم بكلمة مرور ، أو استخدام علامة noindex الوصفية أو رأس الاستجابة ، أو إزالة الصفحة بالكامل (استجب بـ 404 أو 410). لمزيد من المعلومات حول الزحف والتحكم في الفهرسة ، يمكنك قراءة دليل ملف robots.txt الخاص بـ OnCrawl.
[دراسة حالة] إدارة زحف روبوت Google
 اقرأ دراسة الحالة
اقرأ دراسة الحالةبنية ملف Robots.txt الصحيحة
قد يكون بناء جملة robots.txt معقدًا بعض الشيء في بعض الأحيان ، نظرًا لأن برامج الزحف المختلفة تفسر البنية بشكل مختلف. أيضًا ، ترى بعض برامج الزحف غير حسنة السمعة توجيهات robots.txt على أنها اقتراحات وليست قاعدة محددة يجب اتباعها. إذا كانت لديك معلومات سرية على موقعك ، فمن المهم استخدام الحماية بكلمة مرور إلى جانب حظر برامج الزحف باستخدام ملف robots.txt
أدرجت أدناه بعض الأشياء التي يجب أن تضعها في اعتبارك عند العمل على ملف robots.txt الخاص بك:
- يجب أن يعيش ملف robots.txt ضمن المجال وليس ضمن دليل فرعي. لا تتحقق برامج الزحف من ملفات robots.txt في الدلائل الفرعية.
- يحتاج كل نطاق فرعي إلى ملف robots.txt الخاص به:
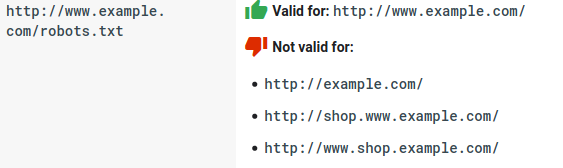
- يعتبر ملف robots.txt حساسًا لحالة الأحرف:
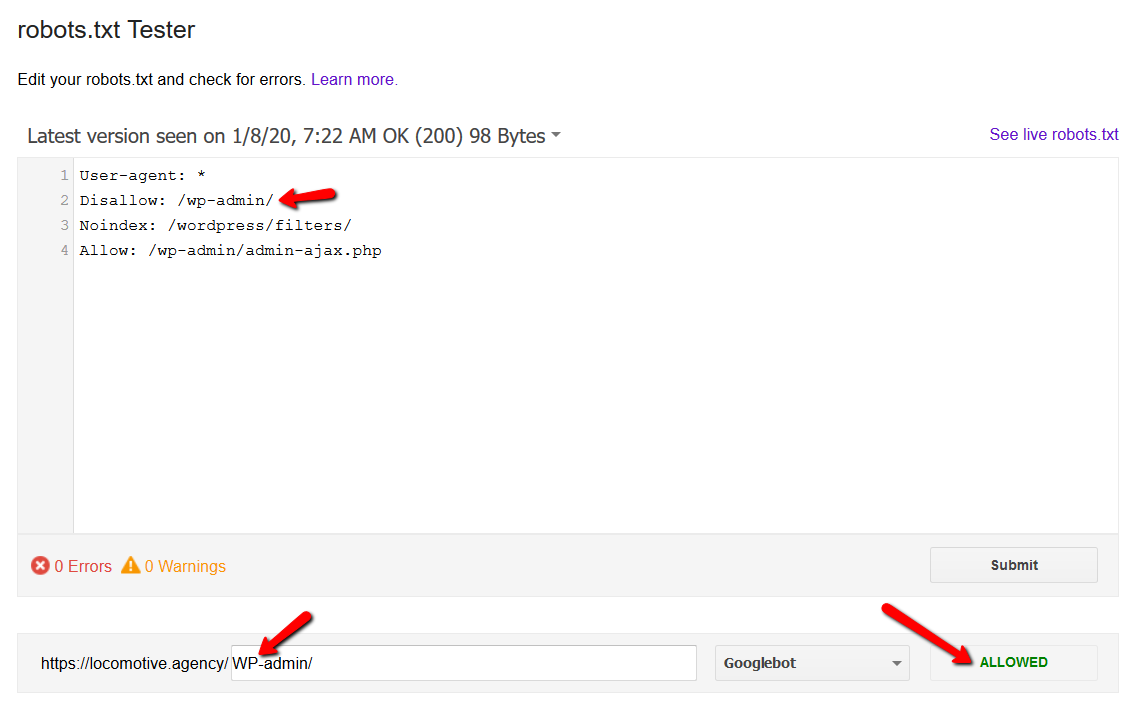
- أمر noindex: عند استخدام noindex في ملف robots.txt ، سيعمل بنفس طريقة disallow. سيتوقف محرك بحث Google عن الزحف إلى الصفحة ولكنه سيحتفظ بها في فهرسها. أنشأنا أنا وjroakes اختبارًا حيث استخدمنا توجيه Noindex في المقالة / wordpress / filter / وأرسلنا الصفحة في Google. يمكنك أن ترى في لقطة الشاشة أدناه أنها توضح أن عنوان URL قد تم حظره:
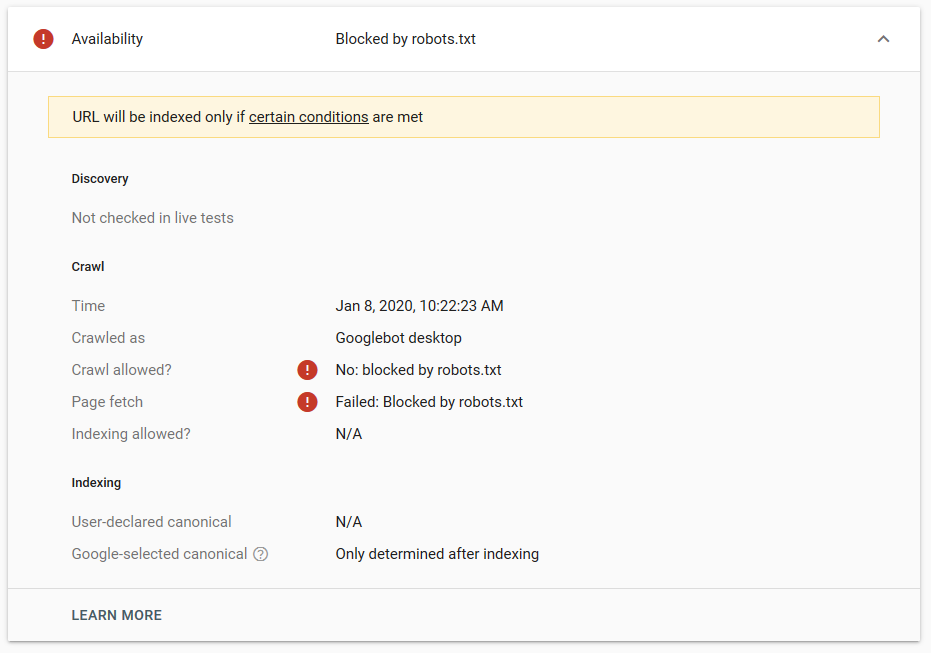
لقد أجرينا عدة اختبارات في Google ولم تتم إزالة الصفحة من الفهرس مطلقًا:
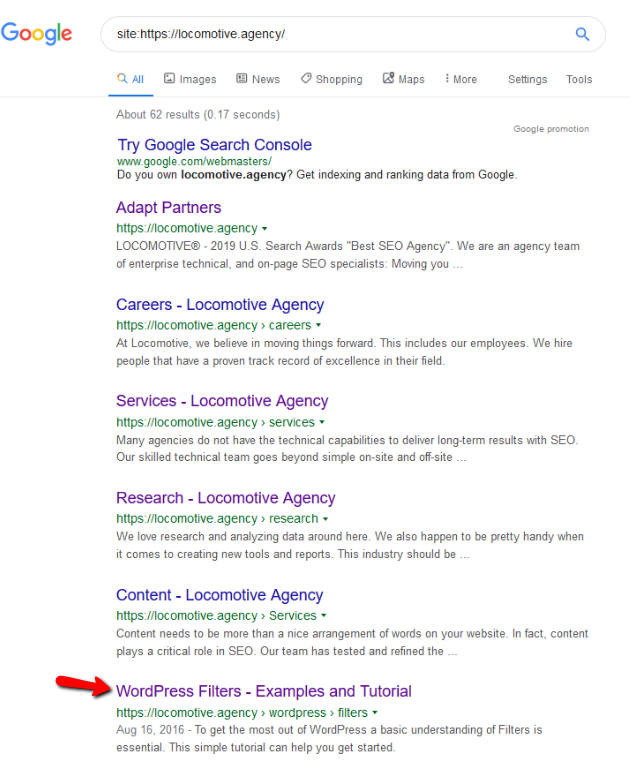

دار نقاش العام الماضي حول أمر noindex الذي يعمل في ملف robots.txt ، وإزالة الصفحات باستثناء Google. إليكم خيط حيث صرح Gary Illyes أنه سيذهب بعيدًا. في هذا الاختبار ، يمكننا أن نرى أن حل Google قيد التنفيذ ، نظرًا لأن التوجيه noindex لم يزيل الصفحة من نتائج البحث.
في الآونة الأخيرة ، كان هناك موضوع آخر مثير للاهتمام على تويتر من كريستيان أوليفيرا ، حيث شارك العديد من التفاصيل لأخذها في الاعتبار عند العمل على ملف robots.txt الخاص بك.
- إذا أردنا أن تكون لدينا قواعد وقواعد عامة لبرنامج Googlebot فقط ، فنحن بحاجة إلى تكرار جميع القواعد العامة ضمن User-agent: مجموعة قواعد Google bot. إذا لم يتم تضمينها ، فسيتجاهل Googlebot جميع القواعد:

- سلوك محير آخر هو أن أولوية القواعد (داخل نفس مجموعة وكيل المستخدم) لا يتم تحديدها بترتيبها ، ولكن بطول القاعدة.
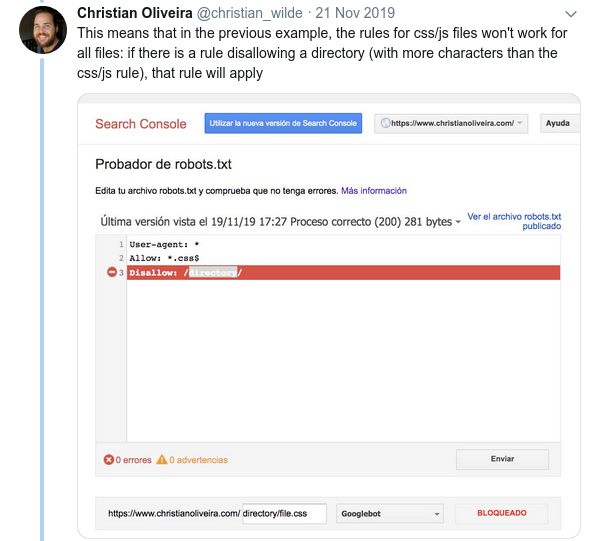
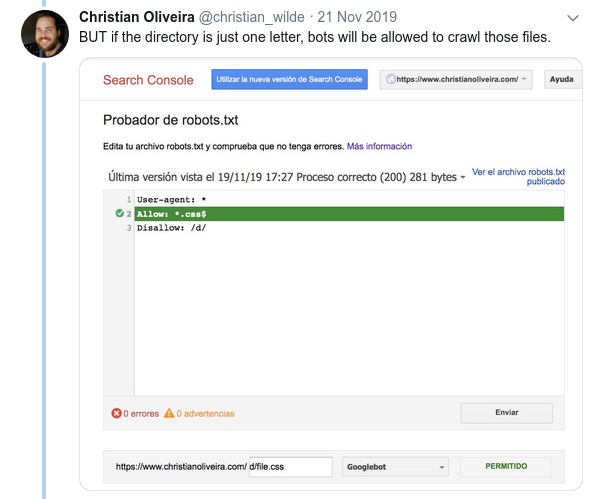
- الآن ، عندما يكون لديك قاعدتان ، بنفس الطول والسلوك المعاكس (أحدهما يسمح بالزحف والآخر يمنعه) ، يتم تطبيق القاعدة الأقل تقييدًا:
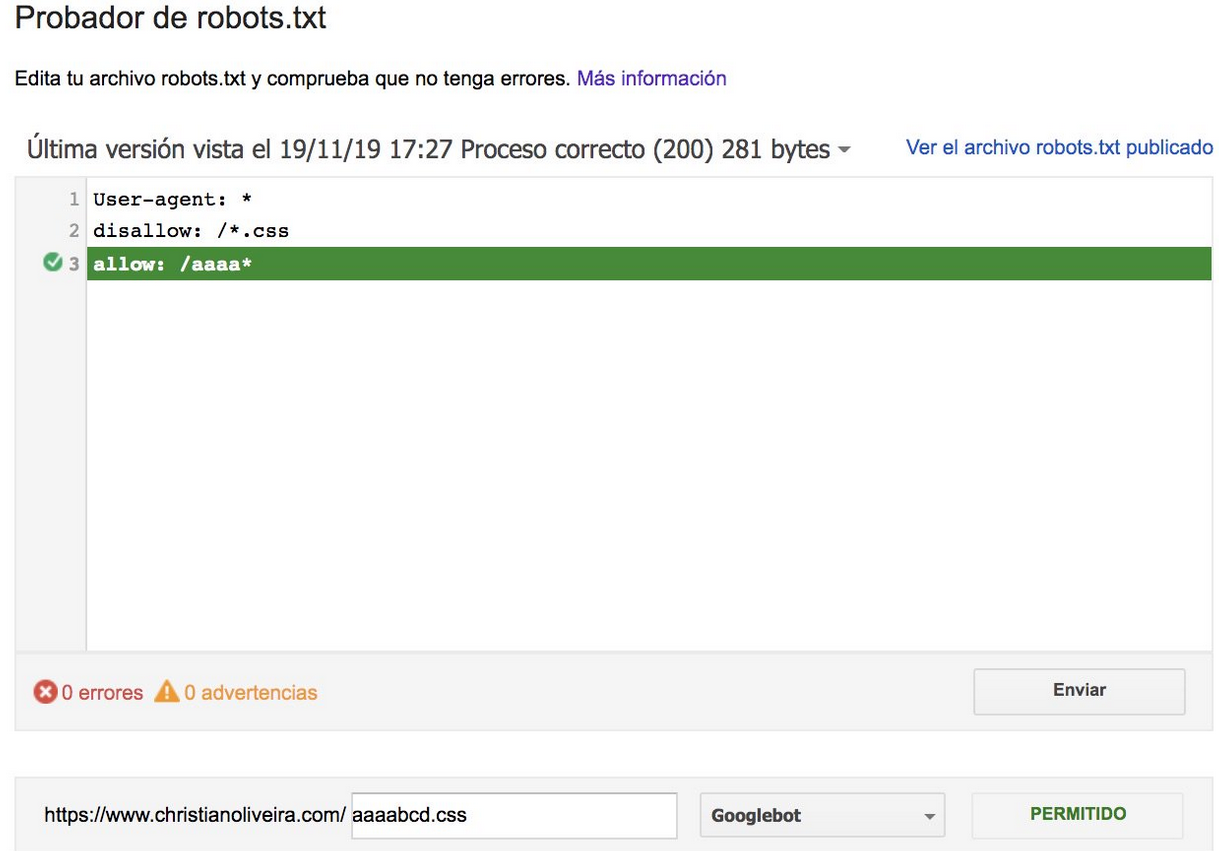
لمزيد من الأمثلة ، يرجى قراءة مواصفات ملف robots.txt المقدمة من Google.
أدوات لاختبار ملف robots.txt الخاص بك
إذا كنت ترغب في اختبار ملف robots.txt الخاص بك ، فهناك العديد من الأدوات التي يمكن أن تساعدك وأيضًا مستودعات جيثب إذا كنت تريد إنشاء مستودعات خاصة بك:
- مقطر
- ترك Google أداة اختبار ملف robots.txt من وحدة تحكم Google Search Console القديمة هنا
- على بايثون
- على C ++
نتائج العينة: الاستخدام الفعال لملف Robots.txt للتجارة الإلكترونية
أدناه قمت بتضمين حالة كنا نعمل فيها مع موقع Magento لا يحتوي على ملف robots.txt. يحتوي Magento بالإضافة إلى CMS الأخرى على صفحات إدارية وأدلة بها ملفات لا نريد أن يزحف إليها Google. أدناه ، قمنا بتضمين مثال لبعض الأدلة التي قمنا بتضمينها في ملف robots.txt:
# # أدلة ماجنتو العامة Disallow: / app / Disallow: / downloader / Disallow: / errors / عدم السماح: / يشمل / Disallow: / lib / Disallow: / pkginfo / Disallow: / قذيفة / Disallow: / var / # # لا تقم بفهرسة صفحة البحث وفئات الارتباط غير المحسّنة Disallow: / كتالوج / product_compare / Disallow: / كتالوج / فئة / عرض / Disallow: / كتالوج / منتج / عرض / Disallow: / كتالوج / منتج / معرض / Disallow: /atalogsearch /
كان للكم الهائل من الصفحات التي لم يكن من المفترض الزحف إليها تأثير على ميزانية الزحف الخاصة بهم ولم يتمكن Googlebot من الزحف إلى جميع صفحات المنتج على الموقع.
يمكنك أن ترى في الصورة أدناه كيف زادت الصفحات المفهرسة بعد 25 أكتوبر ، وهو وقت تنفيذ ملف robots.txt:
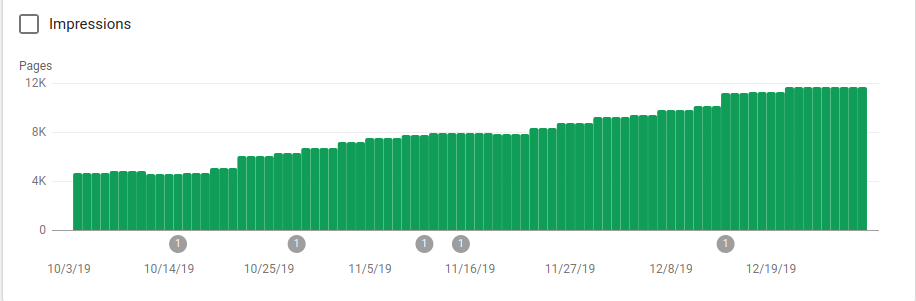
إلى جانب حظر العديد من الأدلة التي لم يكن من المفترض الزحف إليها ، تضمنت برامج الروبوت رابطًا إلى خرائط المواقع. في لقطة الشاشة أدناه ، يمكنك أن ترى كيف زاد عدد الصفحات المفهرسة مقارنة بالصفحات المستبعدة:
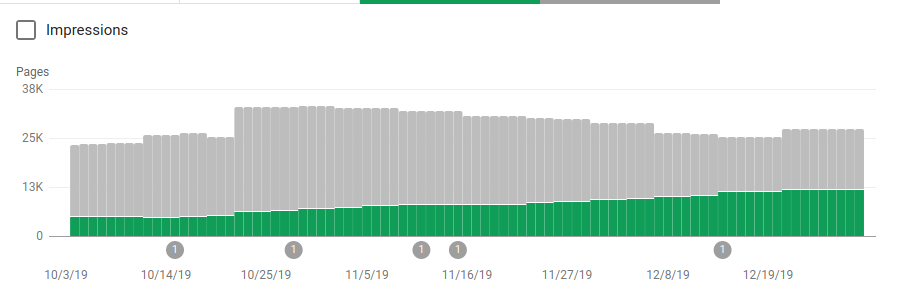
هناك اتجاه إيجابي على الصفحات الصالحة المفهرسة كما هو موضح بالأشرطة الخضراء واتجاه سلبي على الصفحات المستبعدة ممثلة بالأشرطة الرمادية.
تغليف
يمكن أحيانًا التقليل من أهمية ملف robots.txt ، وكما ترى من هذا المنشور ، هناك الكثير من التفاصيل التي يجب مراعاتها عند إنشاء واحدة. لكن العمل يؤتي ثماره: لقد أظهرت بعض النتائج الإيجابية التي يمكنك الحصول عليها من إعداد ملف robots.txt بشكل صحيح.