
شبكة عصبية واحدة على لغة بايثون - مع الحدس الرياضي
نشرت: 2021-06-21لنقم ببناء شبكة بسيطة - بسيطة للغاية ، لكنها شبكة كاملة - بطبقة واحدة. مدخل واحد فقط - وخلايا عصبية واحدة (وهي المخرجات أيضًا) ، ووزن واحد ، وتحيز واحد.
لنقم بتشغيل الكود أولاً ثم نحلل جزءًا تلو الآخر
انسخ مشروع Github ، أو قم ببساطة بتشغيل الكود التالي في IDE المفضل لديك.
إذا كنت بحاجة إلى مساعدة في إعداد IDE ، فقد وصفت العملية هنا.
إذا سارت الأمور على ما يرام ، فستحصل على هذا الناتج:
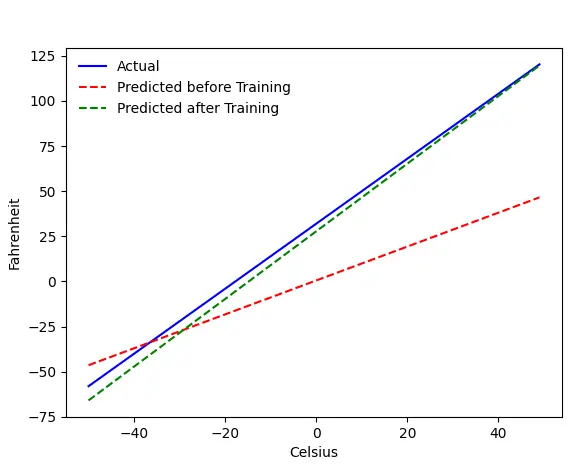
المشكلة - فهرنهايت من درجة مئوية
سنقوم بتدريب آلتنا على التنبؤ بالفهرنهايت من الدرجة المئوية. كما يمكنك أن تفهم من الكود (أو الرسم البياني) ، فإن الخط الأزرق هو العلاقة الفعلية بالدرجة المئوية والفهرنهايت. الخط الأحمر هو العلاقة التي تنبأ بها جهاز الأطفال دون أي تدريب. أخيرًا ، نقوم بتدريب الآلة ، والخط الأخضر هو التنبؤ بعد التدريب.
انظر إلى السطر رقم 65-67 - قبل التدريب وبعده ، من المتوقع استخدام نفس الوظيفة ( get_predicted_fahrenheit_values () ). إذن ما هو القطار السحري () الذي يفعله؟ هيا نكتشف.
هيكل الشبكة
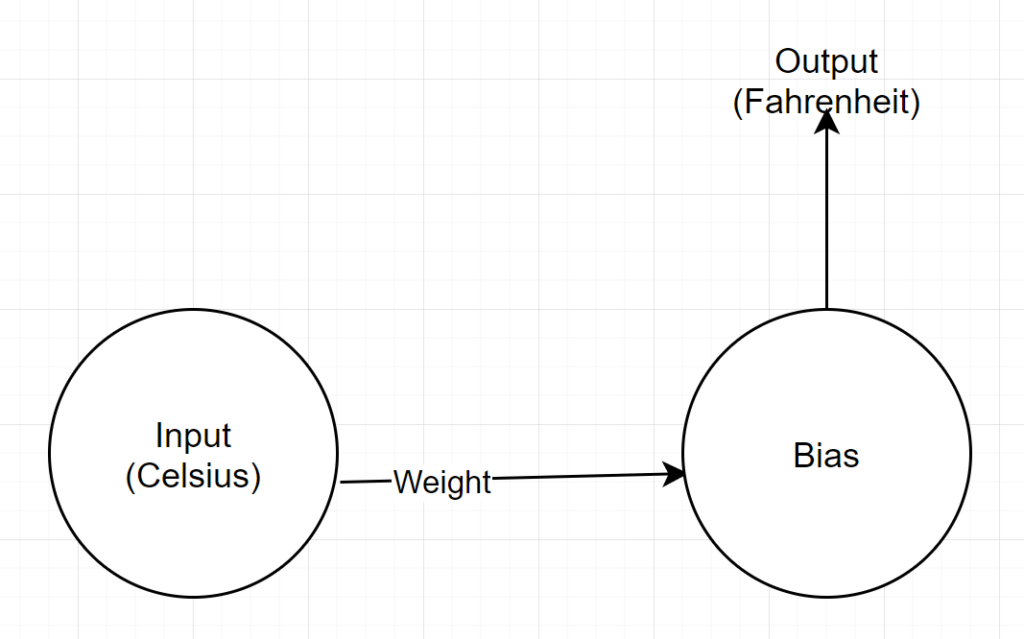
الإدخال: رقم يمثل الدرجة المئوية
الوزن: عوامة تمثل الوزن
الانحياز: عائم يمثل التحيز
الإخراج: عائم يمثل درجة فهرنهايت المتوقعة
لذلك ، لدينا معلمتان إجمالتان - وزن واحد وتحيز واحد
تحليل الكود
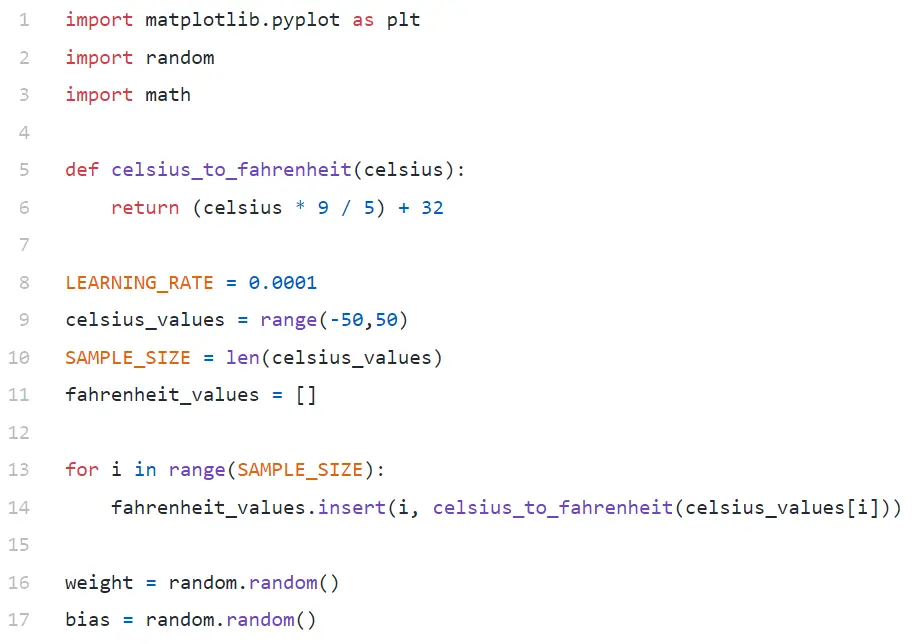
في السطر رقم 9 ، نقوم بإنشاء صفيف من 100 رقم بين -50 و +50 (باستثناء 50 - تستبعد دالة النطاق قيمة الحد الأعلى).
في السطر رقم 11-14 ، نقوم بتوليد فهرنهايت لكل قيمة مئوية.
في السطر رقم 16 و 17 ، نقوم بتهيئة الوزن والتحيز.
قطار()

نحن نجري 10000 تكرار للتدريب هنا. يتكون كل تكرار من:
- تمرير إلى الأمام (الخط رقم 57)
- تمرير للخلف (الخط رقم 58)
- update_parameters (خط # 59)
إذا كنت جديدًا في استخدام لغة python ، فقد يبدو الأمر غريبًا بعض الشيء بالنسبة لك - يمكن أن ترجع وظائف python قيمًا متعددة على هيئة tuple .
لاحظ أن update_parameters هو الشيء الوحيد الذي نهتم به. كل شيء آخر نقوم به هنا هو تقييم معلمات هذه الوظيفة ، وهي التدرجات (سنشرح أدناه ما هي التدرجات) لوزننا وانحيازنا.
- grad_weight: عائم يمثل تدرج الوزن
- grad_bias: عائم يمثل تدرج التحيز
نحصل على هذه القيم عن طريق الاتصال بالخلف ، ولكنها تتطلب مخرجات ، والتي نحصل عليها من خلال الاتصال إلى الأمام في السطر رقم 57.
إلى الأمام()

لاحظ أنه هنا celsius_values و fahrenheit_values عبارة عن صفائف من 100 صف:
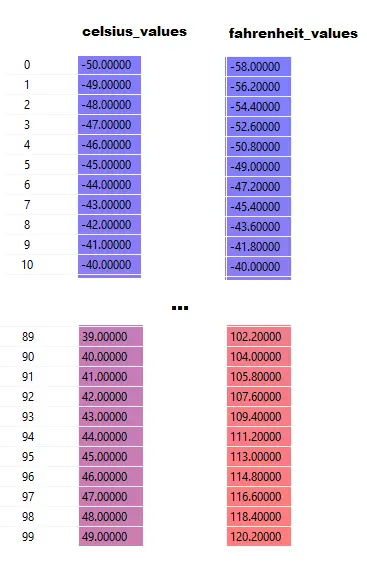
بعد تنفيذ السطر رقم 20-23 ، لقيمة مئوية ، قل 42
الإخراج = 42 * الوزن + التحيز
لذلك ، بالنسبة لـ 100 عنصر في celsius_values ، سيكون الإخراج عبارة عن مصفوفة من 100 عنصر لكل قيمة مئوية مقابلة.
يحسب السطر رقم 25-30 الخسارة باستخدام دالة الخسارة المتوسطة للخطأ التربيعي (MSE) ، وهي مجرد اسم خيالي لمربع جميع الاختلافات مقسومًا على عدد العينات (100 في هذه الحالة).
خسارة صغيرة تعني تنبؤ أفضل. إذا استمر فقدان الطباعة في كل تكرار ، فسترى أنه يتناقص مع تقدم التدريب.
أخيرًا ، في السطر رقم 31 ، نعيد الإنتاج والخسارة المتوقعة.
الى الوراء

نحن مهتمون فقط بتحديث وزننا وانحيازنا. لتحديث هذه القيم ، يجب أن نعرف تدرجاتها ، وهذا ما نحسبه هنا.
يتم حساب التدرجات اللونية للإشعار بترتيب عكسي. يتم حساب تدرج المخرجات أولاً ، ثم للوزن والانحياز ، ومن ثم يتم حساب الاسم "backpropagation". والسبب هو ، لحساب تدرج الوزن والانحياز ، نحتاج إلى معرفة تدرج الناتج - حتى نتمكن من استخدامه في صيغة قاعدة السلسلة .
الآن دعونا نلقي نظرة على ماهية الانحدار وقاعدة السلسلة.
الانحدار
من أجل التبسيط ، ضع في اعتبارك أن لدينا قيمة واحدة فقط من قيم_مئوية وقيمة فهرنهايت ، 42 و 107.6 على التوالي.
الآن ، يصبح تفصيل الحساب في السطر رقم 30:
الخسارة = (107.6 - (42 * وزن + انحياز)) ² / 1
كما ترى ، تعتمد الخسارة على معلمتين - الأوزان والتحيز. ضع في اعتبارك الوزن. تخيل أننا بدأناها بقيمة عشوائية ، لنقل 0.8 ، وبعد تقييم المعادلة أعلاه ، نحصل على 123.45 كقيمة الخسارة . بناءً على قيمة الخسارة هذه ، عليك أن تقرر كيفية تحديث الوزن. هل يجب أن تجعلها 0.9 أم 0.7؟
يجب عليك تحديث الوزن بطريقة بحيث تحصل في التكرار التالي على قيمة أقل للخسارة (تذكر أن تقليل الخسارة هو الهدف النهائي). لذلك ، إذا أدت زيادة الوزن إلى زيادة الخسارة ، فسنقللها. وإذا أدت زيادة الوزن إلى تقليل الخسارة ، فسنزيدها.
الآن ، السؤال ، كيف نعرف ما إذا كانت زيادة الأوزان ستزيد أو تنقص الخسارة. هذا هو المكان الذي يأتي فيه التدرج . بشكل عام ، يتم تعريف التدرج اللوني بواسطة مشتق. تذكر من حساب المدرسة الثانوية أن ∂y / ∂x (وهو مشتق جزئي / انحدار من y بالنسبة إلى x) يشير إلى كيفية تغير y مع تغير بسيط في x.
إذا كانت ∂y / ∂x موجبة ، فهذا يعني أن الزيادة الصغيرة في x ستزيد y.
إذا كانت ∂y / ∂x سالبة ، فهذا يعني أن الزيادة الصغيرة في x ستنقص y.

إذا كانت ∂y / ∂x كبيرة ، فإن التغيير البسيط في x سيؤدي إلى تغيير كبير في y.
إذا كانت y / ∂x صغيرة ، فإن التغيير البسيط في x سيؤدي إلى تغيير طفيف في y.
لذلك ، من التدرجات ، نحصل على معلومتين. أي اتجاه يجب تحديث المعلمة (زيادة أو نقصان) ومقدارها (كبير أو صغير).
حكم السلسلة
بشكل غير رسمي ، تقول قاعدة السلسلة:
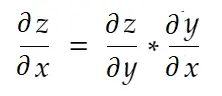
ضع في اعتبارك مثال الوزن أعلاه. نحتاج إلى حساب grad_weight لتحديث هذا الوزن ، والذي سيتم حسابه من خلال:
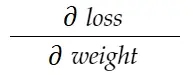
باستخدام صيغة قاعدة السلسلة ، يمكننا اشتقاقها:
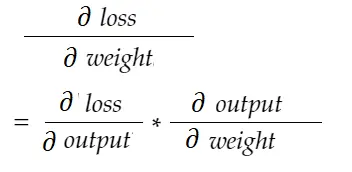
وبالمثل ، التدرج من أجل التحيز:
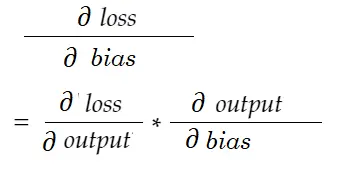
لنرسم مخطط تبعية.
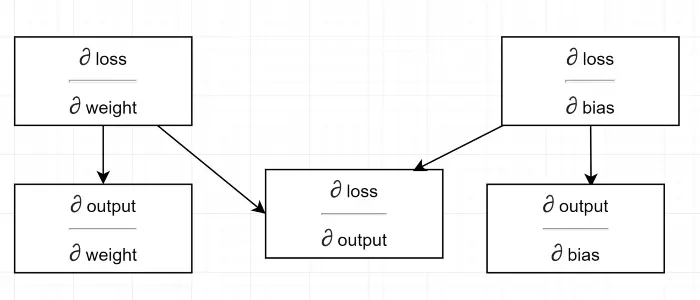
مشاهدة كل العمليات الحسابية تعتمد على التدرج اللوني للإخراج (∂ خسارة / ∂ الإخراج) . هذا هو السبب في أننا نحسبه أولاً على الممر الخلفي (السطر رقم 34-36).
في الواقع ، في أطر ML عالية المستوى ، على سبيل المثال في PyTorch ، لا يتعين عليك كتابة أكواد للتخطي الخلفي! أثناء التمرير الأمامي ، يقوم بإنشاء رسوم بيانية حسابية ، وأثناء التمرير الخلفي ، يمر عبر الاتجاه المعاكس في الرسم البياني ويحسب التدرجات باستخدام قاعدة السلسلة.
∂ خسارة / ∂ الإخراج
نحدد هذا المتغير من خلال grad_output في الكود ، والذي حسبناه في السطر رقم 34-36. دعنا نتعرف على سبب الصيغة التي استخدمناها في الكود.
تذكر أننا نقوم بتغذية كل 100 درجة مئوية في الماكينة معًا. لذا ، فإن grad_output ستكون مصفوفة من 100 عنصر ، كل عنصر يحتوي على تدرج ناتج للعنصر المقابل في celsius_values . للتبسيط ، دعنا نفكر ، لا يوجد سوى عنصرين في celsius_values .
إذن ، تقسيم السطر رقم 30 ،
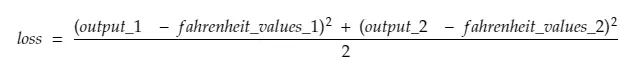
أين،
output_1 = قيمة الإخراج لقيمة الدرجة المئوية الأولى
الإخراج_2 = قيمة الإخراج لقيمة الدرجة الثانية
fahreinheit_values_1 = قيمة فهرنهايت الفعلية لقيمة الدرجة المئوية الأولى
fahreinheit_values_1 = قيمة فهرنهايت الفعلية لقيمة الدرجة الثانية
الآن ، سيحتوي المتغير grad_output الناتج على قيمتين - تدرج الإخراج_1 والمخرج_2 ، مما يعني:
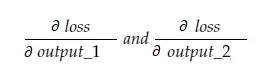
دعونا نحسب انحدار الناتج_1 فقط ، وبعد ذلك يمكننا تطبيق نفس القاعدة على الآخرين.
وقت حساب التفاضل والتكامل!

وهو نفس السطر رقم 34-36.
تدرج الوزن
تخيل ، لدينا عنصر واحد فقط في قيم_مئوية. الآن:

وهو نفس السطر رقم 38-40. بالنسبة لـ 100 درجة مئوية ، سيتم تلخيص قيم التدرج لكل من القيم. قد يكون السؤال الواضح هو لماذا لا نقوم بتصغير النتيجة (أي القسمة على SAMPLE_SIZE). نظرًا لأننا نضرب جميع التدرجات بعامل صغير قبل تحديث المعلمات ، فهذا ليس ضروريًا (راجع القسم الأخير تحديث المعلمات).
تدرج التحيز

وهو نفس السطر رقم 42. مثل تدرجات الوزن ، يتم تلخيص هذه القيم لكل من المدخلات المائة. مرة أخرى ، لا بأس بذلك حيث يتم ضرب التدرجات بعامل صغير قبل تحديث المعلمات.
تحديث المعلمات

أخيرًا ، نقوم بتحديث المعلمات. لاحظ أن التدرجات مضروبة في عامل صغير (LEARNING_RATE) قبل طرحها ، لجعل التدريب مستقرًا. ستؤدي القيمة الكبيرة لـ LEARNING_RATE إلى مشكلة تجاوز الحد ، وستؤدي القيمة الصغيرة للغاية إلى جعل التدريب أبطأ ، مما قد يتطلب الكثير من التكرارات. يجب أن نجد القيمة المثلى لها مع بعض التجربة والخطأ. هناك العديد من الموارد عبر الإنترنت ، بما في ذلك هذا المصدر لمعرفة المزيد عن معدل التعلم.
لاحظ أن المقدار الدقيق الذي نقوم بتعديله ليس بالغ الأهمية. على سبيل المثال ، إذا قمت بضبط LEARNING_RATE قليلاً ، فسيتم تغيير المتغيرين descent_grad_weight و descent_grad_bias (السطر # 49-50) ، لكن الجهاز قد يستمر في العمل. الشيء المهم هو التأكد من اشتقاق هذه المبالغ عن طريق تصغير التدرجات بنفس العامل (LEARNING_RATE في هذه الحالة). وبعبارة أخرى ، فإن "الاحتفاظ بنسب التدرجات المتناسقة" يهم أكثر من "مدى انحدارها " .
لاحظ أيضًا أن قيم التدرج اللوني هذه هي في الواقع مجموع التدرجات التي تم تقييمها لكل من المدخلات المائة. ولكن نظرًا لتحجيمها بنفس القيمة ، فلا بأس كما هو مذكور أعلاه.
لتحديث المعلمات ، يتعين علينا الإعلان عنها باستخدام كلمة رئيسية عالمية (في السطر رقم 47).
أين أذهب من هنا
سيكون الرمز أصغر بكثير عن طريق استبدال حلقات for بقائمة فهم بطريقة Pythonic. ألقِ نظرة عليها الآن - لن تستغرق أكثر من بضع دقائق لفهمها.
إذا فهمت كل شيء حتى الآن ، فربما يكون الوقت مناسبًا لرؤية الأجزاء الداخلية لشبكة بسيطة ذات خلايا عصبية / طبقات متعددة - إليك مقالة.