
تجميع الكلمات الدلالية الدلالية في بايثون
نشرت: 2021-04-19في عالم مليء بأساطير التسويق الرقمي ، نعتقد أن التوصل إلى حلول عملية للمشاكل اليومية هو ما نحتاجه.
في PEMAVOR ، نشارك دائمًا خبرتنا ومعرفتنا لتلبية احتياجات عشاق التسويق الرقمي. لذلك ، غالبًا ما ننشر نصوص Python النصية المجانية لمساعدتك على زيادة عائد الاستثمار.
مهدت مجموعة الكلمات الرئيسية لتحسين محركات البحث مع Python الطريق نحو اكتساب رؤى جديدة لمشاريع تحسين محركات البحث الكبيرة ، مع أقل من 50 سطرًا من أكواد Python.
كانت الفكرة من وراء هذا البرنامج النصي هي السماح لك بتجميع الكلمات الرئيسية دون دفع "رسوم باهظة" لـ ... حسنًا ، نحن نعرف من ...
لكننا أدركنا أن هذا النص لا يكفي في حد ذاته. هناك حاجة إلى نص برمجي آخر ، حتى تتمكن يا رفاق من زيادة فهمك لكلماتك الرئيسية: يجب أن تكون قادرًا على " تجميع الكلمات الرئيسية حسب المعنى والعلاقات الدلالية. "
الآن ، حان الوقت لاتخاذ Python لتحسين محركات البحث خطوة أخرى إلى الأمام.
بيانات عند الزحف³
 يتعلم أكثر
يتعلم أكثرالطريقة التقليدية للتجميع الدلالي
كما تعلم ، فإن الطريقة التقليدية للدلالات هي بناء نماذج word2vec ، ثم تجميع الكلمات الرئيسية باستخدام مسافة محرك Word .
لكن هذه النماذج تستغرق الكثير من الوقت والجهد لبناءها وتدريبها. لذلك ، نود أن نقدم لك حلاً أكثر وضوحًا. 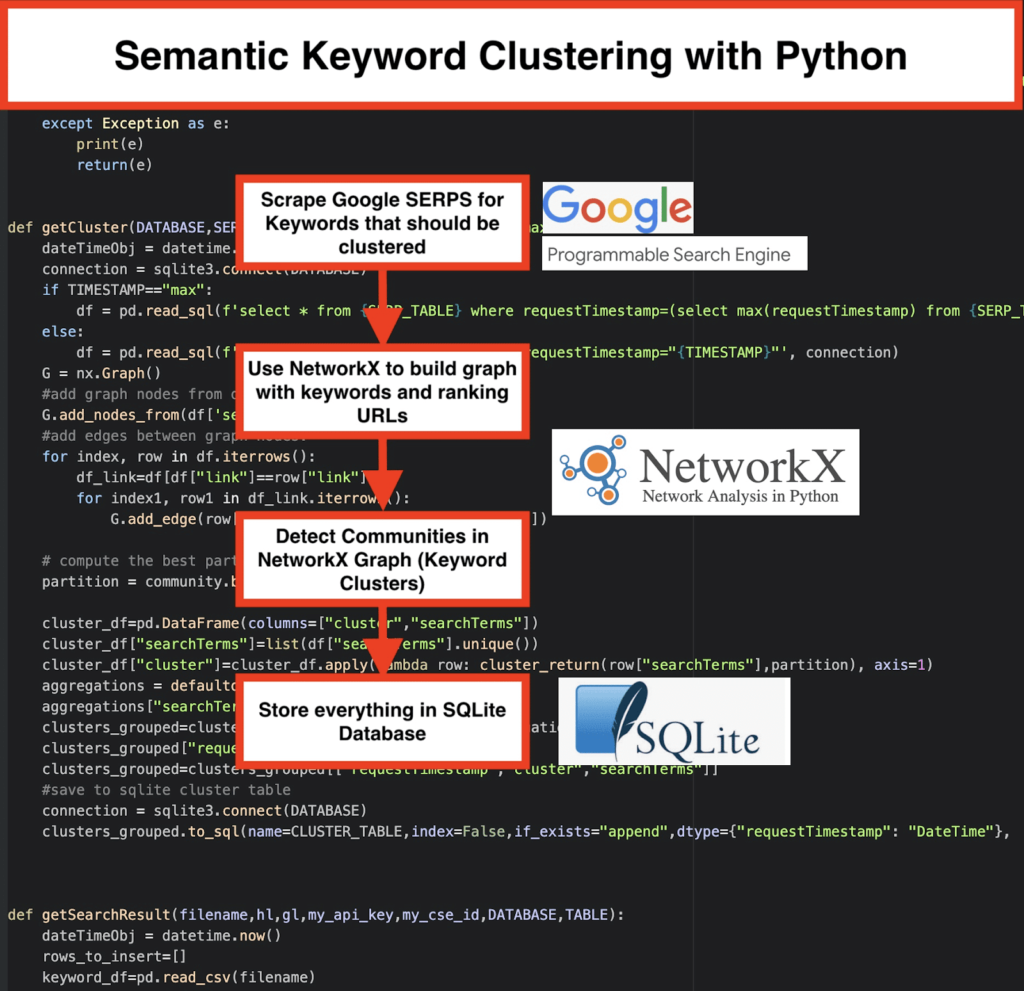
نتائج Google SERP واكتشاف الدلالات
تستخدم Google نماذج البرمجة اللغوية العصبية لتقديم أفضل نتائج البحث. إنه مثل صندوق Pandora الذي سيتم فتحه ، ونحن لا نعرفه بالضبط.
ومع ذلك ، بدلاً من بناء نماذجنا ، يمكننا استخدام هذا المربع لتجميع الكلمات الرئيسية حسب دلالاتها ومعناها.
إليك كيف نفعل ذلك:
️ أولاً ، ابتكر قائمة بالكلمات المفتاحية للموضوع.
️ ثم كشط بيانات SERP لكل كلمة رئيسية.
️ بعد ذلك ، يتم إنشاء رسم بياني بالعلاقة بين صفحات الترتيب والكلمات الرئيسية.
️ طالما يتم تصنيف الصفحات نفسها لكلمات رئيسية مختلفة ، فهذا يعني أنها مرتبطة ببعضها البعض. هذا هو المبدأ الأساسي وراء إنشاء مجموعات الكلمات الرئيسية الدلالية.
حان الوقت لتجميع كل شيء في بايثون
يقدم برنامج Python Script الوظائف التالية:
- باستخدام محرك البحث المخصص من Google ، قم بتنزيل SERPs لقائمة الكلمات الرئيسية. يتم حفظ البيانات في قاعدة بيانات SQLite . هنا ، يجب عليك إعداد واجهة برمجة تطبيقات بحث مخصصة.
- بعد ذلك ، استفد من الحصة المجانية التي تبلغ 100 طلب يوميًا. لكنهم يقدمون أيضًا خطة مدفوعة مقابل 5 دولارات لكل 1000 مهمة إذا كنت لا ترغب في الانتظار أو إذا كان لديك مجموعات بيانات كبيرة.
- من الأفضل استخدام حلول SQLite إذا لم تكن في عجلة من أمرك - سيتم إلحاق نتائج SERP بالجدول في كل شوط. (ما عليك سوى استخدام سلسلة جديدة من 100 كلمة رئيسية عندما يكون لديك حصة ثانية في اليوم التالي.)
- في غضون ذلك ، تحتاج إلى إعداد هذه المتغيرات في نص بايثون .
- CSV_FILE = ”keywords.csv” => قم بتخزين كلماتك الرئيسية هنا
- LANGUAGE = "ar"
- COUNTRY = "ar"
- API_KEY = ”xxxxxxx”
- CSE_ID = ”xxxxxxx”
- سيؤدي تشغيل
getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE)إلى كتابة نتائج SERP إلى قاعدة البيانات. - يتم التجميع بواسطة networkx ووحدة الكشف عن المجتمع. يتم جلب البيانات من قاعدة بيانات SQLite - يسمى التجميع باستخدام
getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP) - يمكن العثور على نتائج التجميع في جدول SQLite - طالما لم تتغير ، يكون الاسم افتراضيًا هو "keyword_clusters".
أدناه ، سترى الرمز الكامل:
# تجميع الكلمات الدلالية الدلالية بواسطة Pemavor.com # المؤلف: ستيفان نيفيشير ([email protected]) من إصدار استيراد googleapiclient.discovery استيراد الباندا كما pd استيراد Levenshtein من تاريخ استيراد ووقت وتاريخ من ضباب الاستيراد الضبابي من urllib.parse استيراد urlparse من tld استيراد get_tld استيراد لانجيد استيراد json استيراد الباندا كما pd استيراد numpy كـ np استيراد networkx كـ nx مجتمع الاستيراد استيراد sqlite3 استيراد الرياضيات استيراد io من مجموعات الاستيراد الافتراضي ديكت def الكتلة_ريتورن (searchTerm ، التقسيم): عودة التقسيم [searchTerm] def language_detection (str_lan): lan = تصنيف langid.classify (str_lan) العودة للشبكة المحلية [0] def extract_domain (url، remove_http = True): uri = urlparse (url) إذا remove_http: domain_name = f "{uri.netloc}" آخر: domain_name = f "{uri.netloc}: // {uri.netloc}" إرجاع domain_name def extract_mainDomain (url): res = get_tld (url، as_object = صحيح) عودة res.fld def fuzzy_ratio (str1، str2): عودة fuzz.ratio (str1، str2) def fuzzy_token_set_ratio (str1، str2): عودة fuzz.token_set_ratio (str1، str2) def google_search (search_term، api_key، cse_id، hl، gl، ** kwargs): محاولة: service = build ("customearch"، "v1"، developerKey = api_key، cache_discovery = False) res = service.cse (). list (q = search_term، hl = hl، gl = gl، field = 'queries (request (totalResults، searchTerms، hl، gl))، items (title، displayLink، link، snippet)' ، num = 10، cx = cse_id، ** kwargs). تنفيذ () عودة الدقة باستثناء الاستثناء كـ e: طباعة (هـ) عودة (ه) def google_search_default_language (search_term، api_key، cse_id، gl، ** kwargs): محاولة: service = build ("customearch"، "v1"، developerKey = api_key، cache_discovery = False) res = service.cse (). list (q = search_term، gl = gl، field = 'queries (request (totalResults، searchTerms، hl، gl))، items (title، displayLink، link، snippet)'، num = 10 ، cx = cse_id، ** kwargs). تنفيذ () عودة الدقة باستثناء الاستثناء كـ e: طباعة (هـ) عودة (ه) def getCluster (قاعدة البيانات ، SERP_TABLE ، CLUSTER_TABLE ، TIMESTAMP = "max"): dateTimeObj = datetime.now () اتصال = sqlite3.connect (قاعدة البيانات) إذا كانت TIMESTAMP == "max": df = pd.read_sql (f'select * من {SERP_TABLE} حيث requestTimestamp = (حدد max (requestTimestamp) من {SERP_TABLE}) '، اتصال) آخر: df = pd.read_sql (اختر * من {SERP_TABLE} حيث requestTimestamp = "{TIMESTAMP}" '، اتصال) G = nx.Graph () # إضافة عقد الرسم البياني من dataframe columun G.add_nodes_from (df ['searchTerms']) # إضافة حواف بين عقد الرسم البياني: للفهرس ، صف في df.iterrows (): df_link = df [df ["link"] == صف ["رابط"]] لـ index1 ، row1 في df_link.iterrows (): G.add_edge (row ["searchTerms"]، row1 ['searchTerms']) # حساب أفضل قسم للمجتمع (مجموعات) التقسيم = community.best_partition (G) cluster_df = pd.DataFrame (أعمدة = ["مجموعة" ، "searchTerms"]) cluster_df ["searchTerms"] = list (df ["searchTerms"]. unique ()) clust_df ["الكتلة"] = "clustral_df.apply" (صف لامدا: الكتلة_ريتورن (الصف ["شروط البحث"] ، القسم) ، المحور = 1) التجميعات = defaultdict () التجميعات ["searchTerms"] = '| '.انضم clusters_grouped = cluster_df.groupby ("الكتلة"). agg (التجميعات) .reset_index () clusters_grouped ["requestTimestamp"] = dateTimeObj clusters_grouped = clusters_grouped [["requestTimestamp"، "clusters"، "searchTerms"]] # حفظ في جدول الكتلة sqlite اتصال = sqlite3.connect (قاعدة البيانات) clusters_grouped.to_sql (الاسم = CLUSTER_TABLE ، الفهرس = خطأ ، if_exists = "إلحاق" ، dtype = {"requestTimestamp": "DateTime"} ، con = Connection) def getSearchResult (اسم الملف ، hl ، gl ، my_api_key ، my_cse_id ، قاعدة البيانات ، الجدول): dateTimeObj = datetime.now () rows_to_insert = [] keyword_df = pd.read_csv (اسم الملف) الكلمات الرئيسية = keyword_df.iloc [:، 0] .tolist () للاستعلام في الكلمات الرئيسية: إذا كانت hl == "افتراضي": النتيجة = google_search_default_language (استعلام ، my_api_key ، my_cse_id ، gl) آخر: نتيجة = google_search (استعلام ، my_api_key ، my_cse_id ، hl ، gl) إذا كانت "العناصر" في النتيجة و "استفسارات" في النتيجة: للوضع في النطاق (0، len (النتيجة ["العناصر"])): النتيجة ["العناصر"] [الموضع] ["الموضع"] = الموضع + 1 النتيجة ["العناصر"] [الموضع] ["main_domain"] = extract_mainDomain (النتيجة ["العناصر"] [الموضع] ["الرابط"]) النتيجة ["العناصر"] [الموضع] ["title_matchScore_token"] = fuzzy_token_set_ratio (نتيجة ["العناصر"] [الموضع] ["العنوان"] ، الاستعلام) النتيجة ["العناصر"] [الموضع] ["snippet_matchScore_token"] = fuzzy_token_set_ratio (النتيجة ["العناصر"] [الموضع] ["المقتطف"] ، الاستعلام) النتيجة ["العناصر"] [الموضع] ["title_matchScore_order"] = fuzzy_ratio (النتيجة ["العناصر"] [الموضع] ["العنوان"] ، الاستعلام) النتيجة ["العناصر"] [الموضع] ["snippet_matchScore_order"] = fuzzy_ratio (النتيجة ["العناصر"] [الموضع] ["المقتطف"] ، الاستعلام) النتيجة ["العناصر"] [الموضع] ["snipped_language"] = اكتشاف اللغة (النتيجة ["العناصر"] [الموضع] ["المقتطف"]) للوضع في النطاق (0، len (النتيجة ["العناصر"])): rows_to_insert.append ({"requestTimestamp": dateTimeObj، "searchTerms": query، "gl": gl، "hl": hl، "totalResults": النتيجة ["استعلامات"] ["طلب"] [0] ["totalResults"]، "رابط": نتيجة ["عناصر"] [موقع] ["رابط"]، "displayLink": النتيجة ["items"] [position] ["displayLink"]، "main_domain": النتيجة ["items"] [position] ["main_domain"]، "الموضع": النتيجة ["العناصر"] [الموضع] ["الموضع"] ، "المقتطف": النتيجة ["العناصر"] [الموضع] ["المقتطف"] ، "snipped_language": النتيجة ["العناصر"] [الموضع] ["snipped_language"] ، "snippet_matchScore_order": النتيجة ["العناصر"] [الموضع] ["snippet_matchScore_order"] ، "snippet_matchScore_token": النتيجة ["العناصر"] [الموضع] ["snippet_matchScore_token"] ، "العنوان": النتيجة ["العناصر"] [الموضع] ["العنوان"] ، "title_matchScore_order": النتيجة ["العناصر"] [الموضع] ["title_matchScore_order"] ، "title_matchScore_token": النتيجة ["العناصر"] [الموضع] ["title_matchScore_token"] ، }) df = pd.DataFrame (rows_to_insert) # حفظ نتائج serp إلى قاعدة بيانات sqlite اتصال = sqlite3.connect (قاعدة البيانات) df.to_sql (الاسم = TABLE ، الفهرس = خطأ ، if_exists = "إلحاق" ، dtype = {"requestTimestamp": "DateTime"} ، con = connection) ################################################## ################################################## ########################################### # اقرأ لي: # ################################################## ################################################## ########################################### # 1- تحتاج إلى إعداد محرك بحث مخصص من Google. # # يرجى تقديم مفتاح API ومعرف البحث. # # قم أيضًا بتعيين بلدك ولغتك حيث تريد مراقبة نتائج SERP. # # إذا لم يكن لديك مفتاح API ومعرف بحث حتى الآن ، # # يمكنك اتباع الخطوات الموجودة ضمن قسم المتطلبات الأساسية في هذه الصفحة https://developers.google.com/custom-search/v1/overview#prerequisites # # # # 2 - تحتاج أيضًا إلى إدخال أسماء قاعدة البيانات وجدول serp وجدول الكتلة لاستخدامها في حفظ النتائج. # # # # 3- أدخل اسم ملف csv أو المسار الكامل الذي يحتوي على الكلمات الرئيسية التي سيتم استخدامها ل serp # # # # 4- لتجميع الكلمات الرئيسية ، أدخل الطابع الزمني لنتائج serp التي سيتم استخدامها للتجميع. # # إذا كنت بحاجة إلى تجميع نتائج serp الأخيرة ، أدخل "max" للطابع الزمني. # # أو يمكنك إدخال طابع زمني محدد مثل "2021-02-18 17:18: 05.195321" # # # # 5- تصفح النتائج من خلال متصفح DB لبرنامج Sqlite # ################################################## ################################################## ########################################### #csv اسم الملف الذي يحتوي على كلمات رئيسية لـ serp CSV_FILE = "keywords.csv" # تحديد اللغة LANGUAGE = "ar" # ديترميني المدينة COUNTRY = "ar" #google البحث المخصص json api key API_KEY = "أدخل المفتاح هنا" # معرف محرك البحث محرك بحث مخصص_ # اسم قاعدة بيانات sqlite DATABASE = "keywords.db" #table name لحفظ نتائج serp إليه SERP_TABLE = "keywords_serps" # تشغيل serp للكلمات الرئيسية getSearchResult (CSV_FILE ، LANGUAGE ، COUNTRY ، API_KEY ، CSE_ID ، DATABASE ، SERP_TABLE) #table name ستحفظ نتائج المجموعة فيه. CLUSTER_TABLE = "keyword_clusters" # الرجاء إدخال الطابع الزمني ، إذا كنت تريد إنشاء مجموعات لطابع زمني محدد # إذا كنت بحاجة إلى إنشاء مجموعات لنتائج serp الأخيرة ، فأرسلها بقيمة "max" # TIMESTAMP = "2021-02-18 17:18: 05.195321" TIMESTAMP = "ماكس" # تشغيل مجموعات الكلمات الرئيسية وفقًا للشبكات وخوارزميات المجتمع getCluster (قاعدة بيانات ، SERP_TABLE ، CLUSTER_TABLE ، TIMESTAMP)

نتائج Google SERP واكتشاف الدلالات
نأمل أن تكون قد استمتعت بهذا البرنامج النصي باختصاره لتجميع كلماتك الرئيسية في مجموعات دلالية دون الاعتماد على النماذج الدلالية. نظرًا لأن هذه النماذج غالبًا ما تكون معقدة ومكلفة ، فمن المهم النظر في طرق أخرى لتحديد الكلمات الرئيسية التي تشترك في الخصائص الدلالية.
من خلال معالجة الكلمات الرئيسية ذات الصلة الدلالية معًا ، يمكنك تغطية موضوع بشكل أفضل ، وربط المقالات الموجودة على موقعك ببعضها البعض بشكل أفضل ، وزيادة ترتيب موقع الويب الخاص بك لموضوع معين.