
تقييم جودة التنبؤات السببية
نشرت: 2022-02-15CausalImpact هي واحدة من أكثر الحزم شيوعًا المستخدمة في تجارب تحسين محركات البحث. شعبيتها مفهومة.
توفر تجربة مُحسّنات محرّكات البحث رؤى مثيرة وطرقًا لمُحسّنات محرّكات البحث للإبلاغ عن قيمة عملهم.
ومع ذلك ، فإن دقة أي نموذج للتعلم الآلي تعتمد على معلومات الإدخال التي يتم تقديمها.
ببساطة ، المدخلات الخاطئة قد تعيد التقدير الخاطئ.
في هذا المنشور ، سوف نوضح كيف يمكن أن يكون CausalImpact موثوقًا (وغير موثوق به). سنتعلم أيضًا كيف نصبح أكثر ثقة في نتائج تجاربك.
أولاً ، سوف نقدم لمحة موجزة عن كيفية عمل CausalImpact. بعد ذلك ، سنناقش موثوقية تقديرات التأثير السببي. أخيرًا ، سنتعرف على المنهجية التي يمكن استخدامها لتقدير نتائج تجارب تحسين محركات البحث الخاصة بك.
ما هو التأثير السببي وكيف يعمل؟
CausalImpact عبارة عن حزمة تستخدم إحصائيات Bayesian لتقدير تأثير حدث في حالة عدم وجود تجربة. هذا التقدير يسمى الاستدلال السببي.
تقديرات الاستدلال السببي إذا كان التغيير الملحوظ ناتجًا عن حدث معين.
غالبًا ما يتم استخدامه لتقييم أداء تجارب تحسين محركات البحث.
على سبيل المثال ، عند تحديد تاريخ حدث ما ، سيستخدم CausalImpact (CI) نقاط البيانات قبل التدخل للتنبؤ بنقاط البيانات بعد التدخل. سيقارن بعد ذلك التنبؤ بالبيانات المرصودة ويقدر الفرق بعتبة ثقة معينة.
علاوة على ذلك ، يمكن استخدام مجموعات التحكم لجعل التنبؤات أكثر دقة.
سيكون للمعلمات المختلفة أيضًا تأثير على دقة التنبؤ:
- حجم بيانات الاختبار.
- طول الفترة السابقة للتجربة.
- اختيار مجموعة التحكم المراد المقارنة معها.
- المعلمات الفوقية الموسمية.
- عدد التكرارات.
تساعد كل هذه المعلمات في توفير المزيد من السياق للنموذج وتعزيز موثوقيته.
Oncrawl BI
 يكتشف
يكتشفما أهمية تقييم دقة تجارب تحسين محركات البحث (SEO)؟
في السنوات الماضية ، قمت بتحليل العديد من تجارب تحسين محركات البحث وأذهلني شيء ما.
في كثير من الأحيان ، أدى استخدام مجموعات تحكم وأطر زمنية مختلفة على مجموعات اختبار وتواريخ تدخل متطابقة إلى نتائج مختلفة.
للتوضيح ، فيما يلي نتيجتان من نفس الحدث.
عاد الأول بانخفاض معتد به إحصائياً. 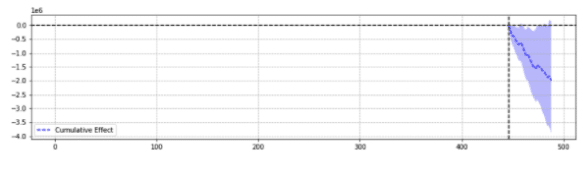
الثانية لم تكن ذات دلالة إحصائية. 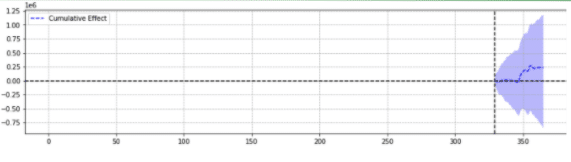
ببساطة ، لنفس الحدث ، تم إرجاع نتائج مختلفة بناءً على المعلمات المختارة.
على المرء أن يتساءل عن التنبؤ الدقيق.
في النهاية ، أليس من المفترض أن تعزز "ذات دلالة إحصائية" الثقة في تقديراتنا؟
تعريفات
لفهم عالم تجارب تحسين محركات البحث بشكل أفضل ، يجب أن يكون القارئ على دراية بالمفاهيم الأساسية لتجارب تحسين محركات البحث:
- التجربة : إجراء يتم إجراؤه لاختبار الفرضية. في حالة الاستدلال السببي ، يكون لها تاريخ بدء محدد.
- مجموعة الاختبار : مجموعة فرعية من البيانات التي يتم تطبيق التغيير عليها. يمكن أن يكون موقع ويب كاملًا أو جزءًا من الموقع.
- المجموعة الضابطة : مجموعة فرعية من البيانات التي لم يتم تطبيق أي تغيير عليها. يمكن أن يكون لديك مجموعة تحكم واحدة أو أكثر. يمكن أن يكون هذا موقعًا منفصلاً في نفس الصناعة أو جزءًا مختلفًا من نفس الموقع.
سيساعد المثال أدناه في توضيح هذه المفاهيم:
يجب أن يؤدي تعديل العنوان (التجربة) إلى زيادة نسبة النقر إلى الظهور العضوية بنسبة 1٪ (فرضية) لصفحات المنتج في خمس مدن (مجموعة اختبارية). سيتم تحسين التقديرات باستخدام عنوان غير متغير في جميع المدن الأخرى (المجموعة الضابطة).
أركان التنبؤ الدقيق بتجربة تحسين محركات البحث
- من أجل البساطة ، قمت بتجميع بعض الأفكار المثيرة للاهتمام لمتخصصي تحسين محركات البحث (SEO) الذين يتعلمون كيفية تحسين دقة التجارب:
- ستؤدي بعض المدخلات في CausalImpact إلى إرجاع تقديرات خاطئة ، حتى عندما تكون ذات دلالة إحصائية. هذا ما نطلق عليه "الإيجابيات الكاذبة" و "السلبيات الكاذبة".
- لا توجد قاعدة عامة تحكم أي عنصر تحكم يتم استخدامه مقابل مجموعة اختبار. يلزم إجراء تجربة لتحديد أفضل بيانات التحكم لاستخدامها في مجموعة اختبار محددة.
- يمكن أن يكون استخدام CausalImpact مع التحكم الصحيح والطول المناسب لبيانات ما قبل الفترة الزمنية دقيقًا للغاية ، حيث يصل متوسط الخطأ إلى 0.1٪.
- بدلاً من ذلك ، يمكن أن يؤدي استخدام CausalImpact مع عنصر التحكم الخاطئ إلى معدل خطأ قوي. أظهرت التجارب الشخصية اختلافات ذات دلالة إحصائية تصل إلى 20٪ ، بينما في الواقع لم يكن هناك تغيير.
- لا يمكن اختبار كل شيء. بعض مجموعات الاختبار لا تُرجع أبدًا تقديرات دقيقة.
- تحتاج التجارب مع مجموعات التحكم أو بدونها إلى أطوال مختلفة من البيانات قبل التدخل.
لن تقوم جميع مجموعات الاختبار بإرجاع تقديرات دقيقة
ستعرض بعض مجموعات الاختبار دائمًا تنبؤات غير دقيقة. لا ينبغي استخدامها للتجريب.
غالبًا ما تُرجع مجموعات الاختبار ذات الاختلافات الكبيرة غير الطبيعية في حركة المرور نتائج غير موثوقة.
على سبيل المثال ، في نفس العام الذي شهد ترحيل موقع ويب ، وتأثر بوباء كوفيد ، وجزء من الموقع تم "noindexed" لمدة أسبوعين بسبب خطأ تقني. سيؤدي إجراء التجارب على هذا الموقع إلى نتائج غير موثوقة.
تم جمع الوجبات السريعة المذكورة أعلاه من خلال سلسلة واسعة من الاختبارات التي تم إجراؤها باستخدام المنهجية الموضحة أدناه.
عند عدم استخدام مجموعات التحكم
- يمكن أن يؤدي استخدام عنصر تحكم بدلاً من النشر المسبق البسيط إلى زيادة دقة التقدير حتى 18 مرة.
- كان استخدام 16 شهرًا من البيانات مسبقًا بنفس دقة استخدام 3 سنوات.
عند استخدام مجموعات التحكم
- غالبًا ما يكون استخدام عنصر التحكم الصحيح أفضل من استخدام عناصر تحكم متعددة. ومع ذلك ، فإن عنصر تحكم واحد يزيد من مخاطر التنبؤ الخاطئ في الحالات التي تختلف فيها حركة مرور عنصر التحكم كثيرًا.
- يمكن أن يؤدي اختيار عنصر التحكم الصحيح إلى زيادة الدقة بمقدار 10 أضعاف (على سبيل المثال ، تقرير واحد + 3.1٪ والآخر + 4.1٪ بينما كان في الواقع + 3٪).
- معظم أنماط الحركة المترابطة بين بيانات الاختبار وبيانات التحكم لا تعني بالضرورة تقديرات أفضل.
- استخدام 16 شهرًا من البيانات سابقًا لم يكن دقيقًا مثل استخدام 3 سنوات.
احذر من طول البيانات قبل التجارب
ومن المثير للاهتمام ، عند تجربة المجموعات الضابطة ، أن استخدام 16 شهرًا من البيانات مسبقًا يمكن أن يتسبب في معدل خطأ شديد للغاية.
في الواقع ، يمكن أن تكون الأخطاء كبيرة مثل تقدير زيادة 3 أضعاف في حركة المرور في حالة عدم وجود تغييرات فعلية.
ومع ذلك ، أدى استخدام 3 سنوات من البيانات إلى إزالة معدل الخطأ هذا ، وهذا يتناقض مع التجارب البسيطة السابقة على ما قبل حيث لم يتم زيادة معدل الخطأ هذا عن طريق زيادة الطول من 16 إلى 36 شهرًا.
هذا لا يعني أن استخدام عناصر التحكم أمر سيء. بل على العكس تماما.
إنه يوضح ببساطة كيف تؤثر إضافة التحكم على التنبؤات.

هذا هو الحال عندما تكون هناك اختلافات كبيرة في المجموعة الضابطة.
هذه الوجبات الجاهزة مهمة بشكل خاص لمواقع الويب التي شهدت اختلافات غير طبيعية في حركة المرور في العام الماضي (خطأ فني فادح ، جائحة COVID ، وما إلى ذلك).
كيف تقيم توقع التأثير السببي؟
الآن ، لا توجد درجة دقة مضمنة في مكتبة CausalImpact. لذلك ، يجب استنتاجها بطريقة أخرى.
يمكن للمرء أن ينظر في كيفية تقدير نماذج التعلم الآلي الأخرى لدقة تنبؤاتها وإدراك أن مجموع أخطاء المربعات (SSE) هو مقياس شائع جدًا.
يحسب مجموع أخطاء المربعات ، أو مجموع المربعات المتبقية ، مجموع كل (n) الفروق بين التوقعات (yi) والنتائج الفعلية (f (xi)) ، تربيع. 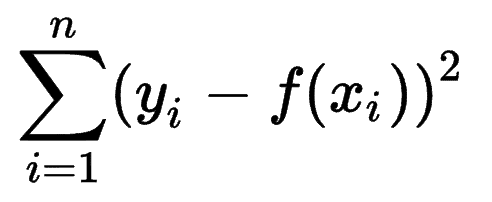
كلما انخفض SSE ، كانت النتيجة أفضل.
يكمن التحدي في أنه مع التجارب السابقة على زيارات تحسين محركات البحث ، لا توجد نتائج فعلية.
على الرغم من عدم إجراء تغييرات في الموقع ، فقد تكون بعض التغييرات قد حدثت خارج نطاق سيطرتك (على سبيل المثال ، تحديث خوارزمية Google ، أو المنافس الجديد ، وما إلى ذلك). لا تختلف حركة تحسين محركات البحث (SEO) عن طريق رقم ثابت ولكنها تختلف تدريجيًا لأعلى ولأسفل.
قد يتساءل متخصصو تحسين محركات البحث عن كيفية التغلب على التحدي.
إدخال الاختلافات الوهمية
للتأكد من حجم التباين الناجم عن حدث ما ، يمكن للمُجرِّب إدخال اختلافات ثابتة في نقاط زمنية مختلفة ، ومعرفة ما إذا كان CausalImpact قد قدر التغيير بنجاح.
والأفضل من ذلك ، يمكن لخبير تحسين محركات البحث (SEO) تكرار العملية لمجموعات اختبار ومراقبة مختلفة.
باستخدام Python ، تم إدخال تغييرات ثابتة على البيانات في تواريخ تدخل مختلفة للفترة اللاحقة.
ثم تم تقدير مجموع أخطاء المربعات بين التباين الذي تم الإبلاغ عنه بواسطة CausalImpact والتباين المقدم.
الفكرة تسير على النحو التالي:
- اختر اختبارًا وتحكم في البيانات.
- إدخال تدخلات زائفة في البيانات الحقيقية في تواريخ مختلفة (على سبيل المثال ، زيادة بنسبة 5٪).
- قارن تقديرات CausalImpact لكل من الاختلافات المقدمة.
- حساب مجموع أخطاء المربعات (SSE).
- كرر الخطوة 1 باستخدام عناصر تحكم متعددة.
- اختر عنصر التحكم باستخدام أصغر SSE لإجراء تجارب في العالم الحقيقي
المنهجية
باستخدام المنهجية أدناه ، قمت بإنشاء جدول يمكنني استخدامه لتحديد عنصر التحكم الذي يحتوي على أفضل وأسوأ معدلات الخطأ في نقاط زمنية مختلفة.
أولاً ، اختر بيانات الاختبار والتحكم وأدخل الاختلافات من -50٪ إلى 50٪.
بعد ذلك ، قم بتشغيل CausalImpact (CI) واطرح الاختلافات التي أبلغت عنها CI إلى التباين الذي قدمته بالفعل.
بعد ذلك ، احسب مربعات هذه الاختلافات وجمع كل القيم معًا.
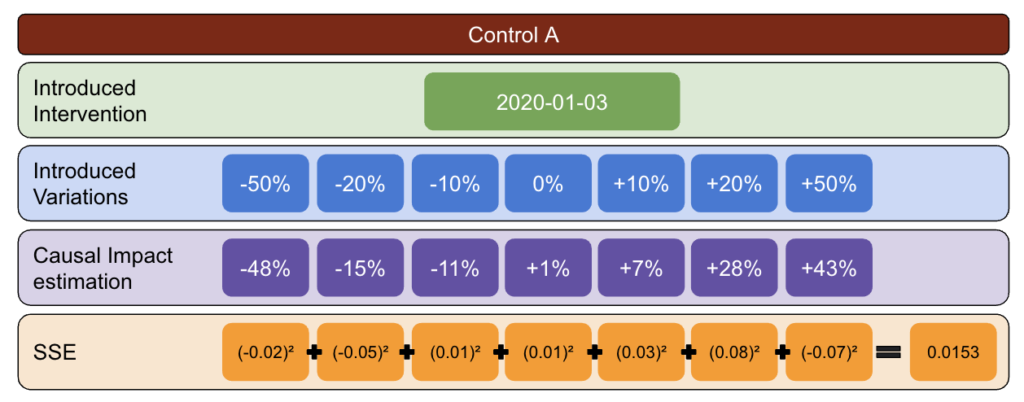
بعد ذلك ، كرر نفس العملية في تواريخ مختلفة لتقليل خطر التحيز الناجم عن اختلاف حقيقي في تاريخ محدد.
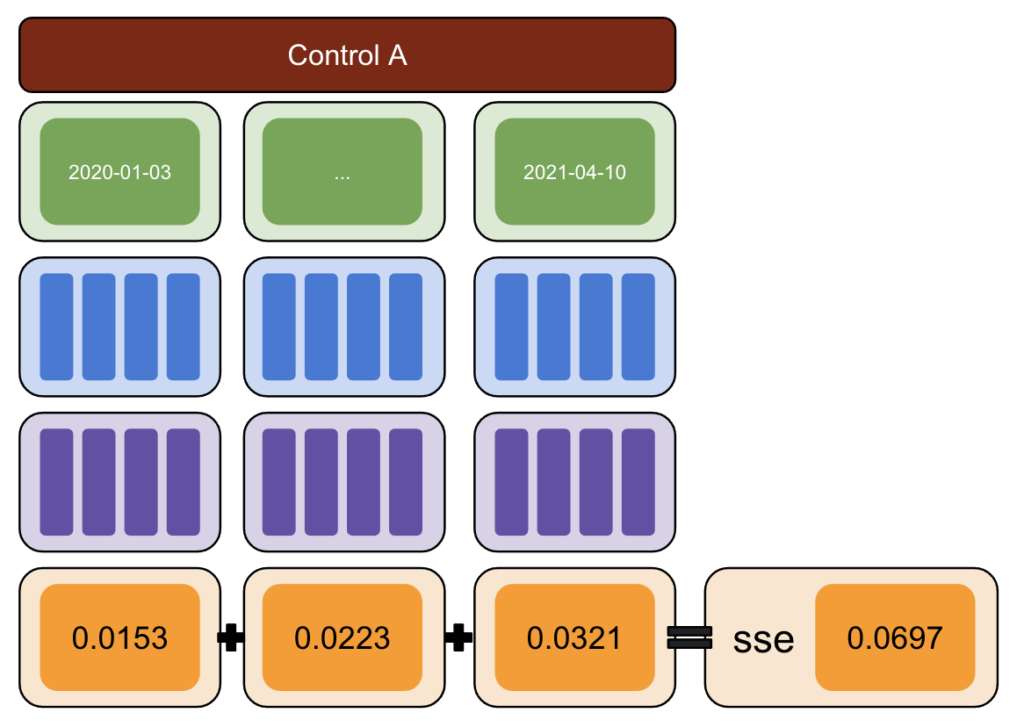
مرة أخرى ، كرر مع مجموعات تحكم متعددة.
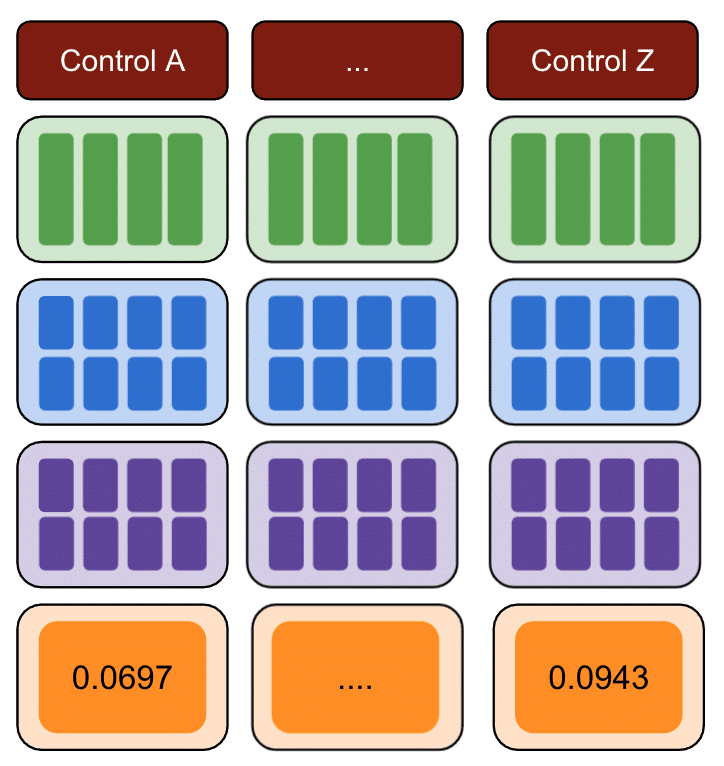
أخيرًا ، يعد عنصر التحكم الذي يحتوي على أصغر مجموع لأخطاء المربعات هو أفضل مجموعة تحكم لاستخدامها في بيانات الاختبار الخاصة بك.
إذا كررت كل خطوة من الخطوات لكل من بيانات الاختبار الخاصة بك ، فستختلف النتيجة.
في الجدول الناتج ، يمثل كل صف مجموعة تحكم ، ويمثل كل عمود مجموعة اختبار. البيانات الموجودة بالداخل هي SSE.
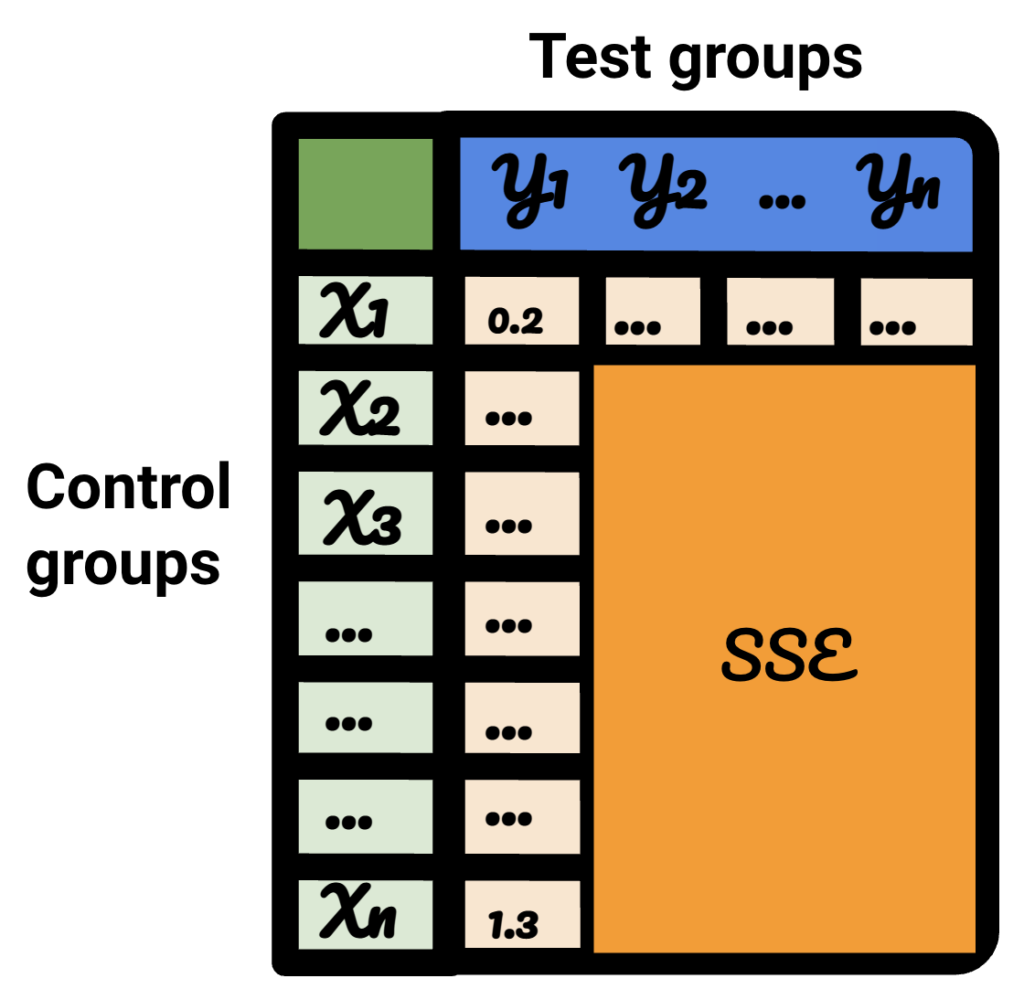
بفرز هذا الجدول ، أنا واثق الآن أنه ، لكل مجموعة من مجموعات الاختبار ، يمكنني تحديد أفضل مجموعة تحكم لها.
هل يجب استخدام مجموعات التحكم أم لا؟
تشير الدلائل إلى أن استخدام مجموعات التحكم يساعد في الحصول على تقديرات أفضل من التقييم المسبق البسيط.
ومع ذلك ، هذا صحيح فقط إذا اخترنا المجموعة الضابطة الصحيحة.
كم يجب أن تكون فترة التقدير؟
الجواب على ذلك يعتمد على الضوابط التي نختارها.
عند عدم استخدام عنصر تحكم ، يبدو أن التجربة السابقة لمدة 16 شهرًا كافية.
عند استخدام عنصر تحكم ، قد يؤدي استخدام 16 شهرًا فقط إلى معدلات خطأ هائلة. يساعد استخدام 3 سنوات في تقليل مخاطر سوء التفسير.
هل يجب استخدام عنصر تحكم واحد أم عناصر تحكم متعددة؟
تعتمد إجابة هذا السؤال على بيانات الاختبار.
يمكن أن تؤدي بيانات الاختبار المستقرة جدًا أداءً جيدًا عند مقارنتها بعناصر تحكم متعددة. في هذه الحالة ، يعد هذا أمرًا جيدًا لأن استخدام الكثير من التحكم يجعل النموذج أقل تأثرًا بالتقلبات غير المتوقعة في أحد عناصر التحكم.
في مجموعات البيانات الأخرى ، يمكن أن يؤدي استخدام عناصر تحكم متعددة إلى جعل النموذج أقل دقة من 10 إلى 20 مرة من استخدام واحد.
عمل مثير للاهتمام في مجتمع SEO
CausalImpact ليست المكتبة الوحيدة التي يمكن استخدامها لاختبار SEO ، كما أن المنهجية المذكورة أعلاه ليست هي الحل الوحيد لاختبار دقتها.
لمعرفة الحلول البديلة ، اقرأ بعض المقالات الرائعة التي شاركها الأشخاص في مجتمع تحسين محركات البحث.
أولاً ، كتب Andrea Volpini مقالًا مثيرًا للاهتمام حول قياس فعالية مُحسنات محركات البحث باستخدام تحليل التأثير السببي.
بعد ذلك ، غطى دانيال هيريديا حزمة نبي على فيسبوك للتنبؤ بحركة تحسين محركات البحث باستخدام نبي وبايثون.
في حين أن مكتبة النبي أكثر ملاءمة للتنبؤ منها للتجارب ، فمن الجدير تعلم مكتبات مختلفة لاكتساب فهم راسخ لعالم التنبؤات.
أخيرًا ، كنت سعيدًا جدًا بالعرض التقديمي الذي قدمته ساندي لي في برايتون لتحسين محركات البحث حيث شارك رؤى حول علم البيانات لاختبار تحسين محركات البحث وأثار بعض مخاطر اختبار تحسين محركات البحث.
أشياء يجب مراعاتها عند إجراء تجارب تحسين محركات البحث
- تعد أدوات اختبار تقسيم محركات البحث (SEO) التابعة لجهات خارجية رائعة ولكنها قد تكون غير دقيقة أيضًا. كن دقيقًا عند اختيار الحل الخاص بك.
- على الرغم من أنني كتبت عنها في الماضي ، لا يمكنك إجراء تجارب اختبار تقسيم SEO مع Google Tag Manager ، ما لم يكن ذلك من جانب الخادم. أفضل طريقة للنشر من خلال شبكات CDN.
- كن جريئا عند الاختبار. التغييرات الصغيرة لا يتم التقاطها عادة بواسطة CausalImpact.
- لا ينبغي أن يكون اختبار تحسين محركات البحث دائمًا خيارك الأول.
- هناك بدائل لاختبار التغييرات الصغيرة مثل علامات العنوان. اختبارات إعلانات Google A / B أو اختبارات A / B على النظام الأساسي. تعتبر اختبارات A / B الحقيقية أكثر دقة من اختبار تقسيم SEO وعادةً ما توفر المزيد من الأفكار حول جودة عناوينك.
نتائج قابلة للتكرار
في هذا البرنامج التعليمي ، أردت التركيز على كيفية تحسين دقة تجارب تحسين محركات البحث بدون عبء معرفة كيفية البرمجة. علاوة على ذلك ، يمكن أن يختلف مصدر البيانات ، ويختلف كل موقع عن الآخر.
ومن ثم ، فإن كود Python الذي استخدمته لإنتاج هذا المحتوى لم يكن جزءًا من نطاق هذه المقالة.
ومع ذلك ، باستخدام المنطق ، يمكنك إعادة إنتاج التجارب المذكورة أعلاه.
استنتاج
إذا كان لديك نصيحة واحدة فقط للحصول عليها من هذه المقالة ، فسيكون تحليل تأثير CausalImpact دقيقًا للغاية ، ولكن يمكن دائمًا أن يكون بعيد المنال.
من المهم جدًا لمحركات البحث الذين يرغبون في استخدام هذه الحزمة لفهم ما يتعاملون معه. نتيجة رحلتي هي أنني لن أثق في CausalImpact دون اختبار دقة النموذج في بيانات الإدخال أولاً.