
مقدمة إلى زاحف الويب
نشرت: 2016-03-08عندما أتحدث إلى الناس حول ما أقوم به وما هو مُحسّنات محرّكات البحث ، فهم عادةً ما يحصلون عليه بسرعة إلى حد ما ، أو يتصرفون كما يفعلون. هيكل موقع جيد ، محتوى جيد ، روابط خلفية جيدة. لكن في بعض الأحيان ، يصبح الأمر أكثر تقنية قليلاً وينتهي بي الأمر بالحديث عن محركات البحث التي تزحف إلى موقع الويب الخاص بك وعادةً ما أفقدها ...
لماذا الزحف إلى موقع ويب؟
بدأ زحف الويب كرسم خرائط للإنترنت وكيفية اتصال كل موقع ويب ببعضه البعض. كما تم استخدامه من قبل محركات البحث لاكتشاف وفهرسة صفحات جديدة على الإنترنت. تم استخدام برامج زحف الويب أيضًا لاختبار ضعف موقع الويب عن طريق اختبار موقع ويب وتحليل ما إذا تم اكتشاف أي مشكلة.
يمكنك الآن العثور على الأدوات التي تزحف إلى موقع الويب الخاص بك لتزويدك بالرؤى. على سبيل المثال ، يوفر OnCrawl بيانات تتعلق بالمحتوى الخاص بك ومُحسّنات محرّكات البحث في الموقع أو Majestic والتي توفر رؤى بخصوص جميع الروابط التي تشير إلى صفحة.
تُستخدم برامج الزحف لجمع المعلومات التي يمكن استخدامها بعد ذلك ومعالجتها لتصنيف المستندات وتقديم رؤى حول البيانات التي تم جمعها.
يمكن الوصول إلى بناء الزاحف لأي شخص يعرف القليل من التعليمات البرمجية. ومع ذلك ، فإن صنع زاحف فعال هو أمر أكثر صعوبة ويستغرق وقتًا.
كيف يعمل ؟
من أجل الزحف إلى موقع ويب أو الويب ، تحتاج أولاً إلى نقطة دخول. تحتاج الروبوتات إلى معرفة وجود موقع الويب الخاص بك حتى يتمكنوا من القدوم وإلقاء نظرة عليه. مرة أخرى في الأيام التي كنت قد قدمت موقع الويب الخاص بك إلى محركات البحث لإخبارهم أن موقع الويب الخاص بك متصل بالإنترنت. الآن يمكنك بسهولة إنشاء بعض الروابط إلى موقع الويب الخاص بك و Voila فأنت في الحلقة!
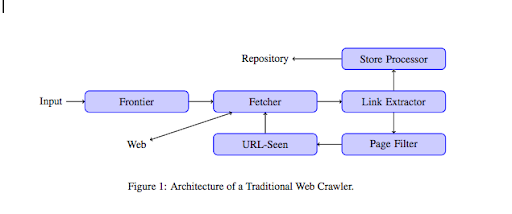
بمجرد وصول الزاحف إلى موقع الويب الخاص بك ، فإنه يقوم بتحليل كل المحتوى الخاص بك سطرًا بسطر ويتبع كل الروابط التي لديك سواء كانت داخلية أو خارجية. وهكذا حتى تصل إلى صفحة لا تحتوي على روابط أخرى أو إذا واجهت أخطاء مثل 404 ، 403 ، 500 ، 503.
من وجهة نظر أكثر تقنية ، يعمل الزاحف مع (أو قائمة) أولية من عناوين URL. يتم تمرير هذا إلى الجلب الذي سيسترد محتوى الصفحة. يتم بعد ذلك نقل هذا المحتوى إلى مستخرج الارتباط الذي سيقوم بتحليل HTML واستخراج جميع الروابط. يتم إرسال هذه الروابط إلى كلٍ من معالج المتجر الذي سيقوم ، كما يوحي اسمه ، بتخزينها. ستمر عناوين URL هذه أيضًا من خلال مرشح الصفحة الذي سيرسل جميع الروابط المثيرة للاهتمام إلى وحدة URL التي تتم رؤيتها. تكتشف هذه الوحدة ما إذا كان عنوان URL قد تمت رؤيته بالفعل أم لا. إذا لم يكن الأمر كذلك ، فسيتم إرساله إلى برنامج الجلب الذي سيسترد محتوى الصفحة وما إلى ذلك.
ضع في اعتبارك أنه من المستحيل على العناكب الزحف إلى بعض المحتويات مثل Flash. يتم الآن الزحف إلى جافا سكريبت بشكل صحيح بواسطة GoogleBot ، ولكن بين الحين والآخر لا يقوم بالزحف إلى أي منها. الصور ليست محتوى يمكن لـ Google الزحف إليه تقنيًا ، لكنها أصبحت ذكية بما يكفي لبدء فهمها!
إذا لم يتم إخبار الروبوتات بالعكس ، فسوف تزحف إلى كل شيء. هذا هو المكان الذي يصبح فيه ملف robots.txt مفيدًا جدًا. إنها تخبر برامج الزحف (يمكن أن تكون محددة لكل زاحف مثل GoogleBot أو MSN Bot - اكتشف المزيد حول الروبوتات هنا) بالصفحات التي لا يمكنهم الزحف إليها. لنفترض على سبيل المثال أن لديك تنقلًا باستخدام الواجهات ، فقد لا ترغب في أن تقوم الروبوتات بالزحف إليها جميعًا لأن لها قيمة مضافة قليلة وستستخدم ميزانية الزحف. سيساعدك استخدام هذا الخط البسيط في منع أي روبوت من الزحف إليه
وكيل المستخدم: *
Disallow: / folder-a /
هذا يخبر جميع برامج الروبوت بعدم الزحف إلى المجلد أ.
وكيل المستخدم: GoogleBot
Disallow: / مرجع- ب /
من ناحية أخرى ، يحدد هذا أن Google Bot هو الوحيد الذي لا يمكنه الزحف إلى المجلد B.
يمكنك أيضًا استخدام إشارة في HTML تخبر برامج الروبوت بعدم اتباع رابط معين باستخدام العلامة rel = ”nofollow”. أظهرت بعض الاختبارات أن استخدام العلامة rel = ”nofollow” على رابط لن يمنع Googlebot من متابعته. هذا يتعارض مع الغرض منه ، لكنه سيكون مفيدًا في حالات أخرى.
[دراسة حالة] زيادة الرؤية عن طريق تحسين إمكانية الزحف إلى موقع الويب لبرنامج Googlebot
 اقرأ دراسة الحالة
اقرأ دراسة الحالة
لقد ذكرت ميزانية الزحف ولكن ما هي؟
لنفترض أن لديك موقعًا تم اكتشافه بواسطة محركات البحث. يأتون بانتظام لمعرفة ما إذا كنت قد أجريت أي تحديثات على موقع الويب الخاص بك وأنشأت صفحات جديدة.
يحتوي كل موقع على ميزانية الزحف الخاصة به اعتمادًا على عدة عوامل مثل عدد الصفحات التي يحتوي عليها موقع الويب الخاص بك ومدى سلامته (إذا كان به الكثير من الأخطاء على سبيل المثال). يمكنك بسهولة الحصول على فكرة سريعة عن ميزانية الزحف الخاصة بك عن طريق تسجيل الدخول إلى Search Console.
ستعمل ميزانية الزحف الخاصة بك على إصلاح عدد الصفحات التي يزحف إليها الروبوت على موقع الويب الخاص بك في كل مرة يأتي فيها لزيارة. إنه مرتبط نسبيًا بعدد الصفحات الموجودة على موقع الويب الخاص بك وقد تم الزحف إليه بالفعل. يتم الزحف إلى بعض الصفحات أكثر من غيرها خاصة إذا تم تحديثها بانتظام أو إذا كانت مرتبطة من صفحات مهمة.
على سبيل المثال ، منزلك هو نقطة الدخول الرئيسية الخاصة بك والتي سيتم الزحف إليها كثيرًا. إذا كانت لديك مدونة أو صفحة فئة ، فسيتم الزحف إليها غالبًا إذا كانت مرتبطة بالملاحة الرئيسية. سيتم أيضًا الزحف إلى المدونة بشكل متكرر حيث يتم تحديثها بانتظام. قد يتم الزحف إلى إحدى مشاركات المدونة بشكل متكرر عند نشرها لأول مرة ، ولكن بعد بضعة أشهر من المحتمل ألا يتم تحديثها.
كلما تم الزحف إلى الصفحة في كثير من الأحيان ، كلما اعتبر الروبوت أنها مهمة مقارنة بالصفحات الأخرى. هذا هو الوقت الذي تحتاج فيه إلى بدء العمل على تحسين ميزانية الزحف الخاصة بك.
تحسين ميزانية الزحف الخاصة بك
من أجل تحسين ميزانيتك والتأكد من أن أهم صفحاتك تحصل على الاهتمام الذي تستحقه ، يمكنك تحليل سجلات الخادم الخاص بك والبحث عن كيفية الزحف إلى موقع الويب الخاص بك:
- كم مرة يتم الزحف إلى أعلى صفحاتك
- هل يمكنك رؤية أي صفحات أقل أهمية يتم الزحف إليها أكثر من الصفحات الأخرى الأكثر أهمية؟
- هل تحصل برامج الروبوت غالبًا على خطأ 4xx أو 5xx عند الزحف إلى موقع الويب الخاص بك؟
- هل تواجه الروبوتات أي فخاخ عنكبوت؟ (كتب ماثيو هنري مقالًا رائعًا عنهم)
من خلال تحليل سجلاتك ، سترى الصفحات التي تعتبرها أقل أهمية يتم الزحف إليها كثيرًا. تحتاج بعد ذلك إلى التعمق في بنية الارتباط الداخلية الخاصة بك. إذا تم الزحف إليه ، فيجب أن يحتوي على الكثير من الروابط التي تشير إليه.
يمكنك أيضًا العمل على إصلاح كل هذه الأخطاء (4xx و 5xx) باستخدام OnCrawl. ستعمل على تحسين إمكانية الزحف بالإضافة إلى تجربة المستخدم ، إنها حالة مربحة للجانبين.
الزحف مقابل القشط؟
الزحف والقشط شيئان مختلفان يستخدمان لأغراض مختلفة. يؤدي الزحف إلى موقع ويب إلى الهبوط على الصفحة وتتبع الروابط التي تجدها عند فحص المحتوى. سينتقل الزاحف بعد ذلك إلى صفحة أخرى وما إلى ذلك.
الكشط من ناحية أخرى هو مسح الصفحة وجمع بيانات محددة من الصفحة: علامة العنوان أو الوصف التعريفي أو علامة h1 أو منطقة معينة من موقع الويب الخاص بك مثل قائمة الأسعار. عادةً ما تعمل أدوات الكشط على أنها "بشر" ، وسوف تتجاهل أي قواعد من ملف robots.txt والملف في النماذج وتستخدم وكيل مستخدم المتصفح حتى لا يتم اكتشافها.
عادةً ما تعمل برامج الزحف لمحركات البحث كقواطع بالإضافة إلى أنها تحتاج إلى جمع البيانات من أجل معالجتها لخوارزمية الترتيب الخاصة بهم. لا يبحثون عن بيانات محددة مقارنة بالمقصات ، بل يستخدمون فقط جميع البيانات المتاحة على الصفحة وأكثر (وقت التحميل شيء لا يمكنك الحصول عليه من الصفحة). ستعرف برامج زحف محركات البحث نفسها دائمًا على أنها برامج زحف حتى يتمكن مالك موقع الويب من معرفة آخر مرة زار فيها موقعه على الويب. يمكن أن يكون هذا مفيدًا جدًا عند تتبع نشاط المستخدم الحقيقي.
الآن أنت تعرف المزيد عن الزحف وكيف يعمل وسبب أهميته ، فإن الخطوة التالية هي البدء في تحليل سجلات الخادم. سيوفر لك هذا رؤى عميقة حول كيفية تفاعل الروبوتات مع موقع الويب الخاص بك ، والصفحات التي يزورونها غالبًا وعدد الأخطاء التي يواجهونها أثناء زيارة موقع الويب الخاص بك.
لمزيد من المعلومات التقنية والتاريخية حول زاحف الويب ، يمكنك قراءة "نبذة تاريخية عن برامج زحف الويب"