
كيفية التنبؤ بإيرادات حركة المرور العضوية غير المرتبطة بعلامة تجارية استنادًا إلى موضع عنوان URL باستخدام Python
نشرت: 2022-05-24ما هو توقع تحسين محركات البحث؟
توقع مُحسّنات محرّكات البحث ، أو تقدير حركة المرور العضوية ، هو عملية استخدام بيانات موقعك أو بيانات الطرف الثالث لتقدير حركة المرور العضوية المستقبلية لموقعك ، وإيرادات تحسين محركات البحث ، وعائد الاستثمار في تحسين محركات البحث. يمكن حساب هذا التقدير باستخدام العديد من الطرق المختلفة بناءً على بياناتنا.
في هذا البرنامج التعليمي ، نريد أن نتنبأ بإيراداتنا العضوية غير ذات العلامات التجارية وحركة المرور العضوية غير ذات العلامات التجارية استنادًا إلى مواقع عناوين URL الخاصة بنا وإيراداتها الحالية. يمكن أن يساعدنا ذلك بصفتنا مُحسّنات محرّكات البحث في الحصول على مزيد من الدعم من أصحاب المصلحة الآخرين: من الميزانية الشهرية أو الفصلية أو السنوية المتزايدة إلى ساعات عمل أكثر من المنتج وفريق التطوير.
ضع في اعتبارك أن هذا البرنامج التعليمي لا ينطبق فقط على حركة المرور العضوية غير ذات العلامات التجارية ؛ من خلال إجراء بعض التغييرات ومعرفة Python ، يمكنك استخدامها لتقدير حركة مرور الصفحات المستهدفة.
نتيجة لذلك ، يمكننا إنتاج ورقة Google مثل الصورة أدناه.
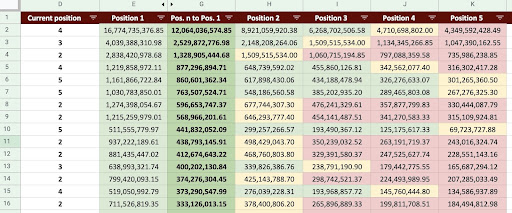
صورة جداول بيانات Google
التنبؤ بحركة سيو بدون علامات تجارية
السؤال الأول الذي قد تطرحه بعد قراءة المقدمة هو ، "لماذا تحسب الزيارات العضوية غير المتعلقة بعلامة تجارية؟".
لنفكر في شركة مثل أمازون. عندما تريد شراء كتاب أو قناع ، ما عليك سوى البحث عن "شراء قناع أمازون".
غالبًا ما تكون العلامات التجارية في قمة اهتماماتك ، وعندما تريد شراء شيء ما ، فإن تفضيلك هو شراء الأشياء التي تحتاجها من هذه الشركات. في كل صناعة ، هناك شركات ذات علامات تجارية تؤثر في سلوك المستخدمين في عمليات بحث Google.
إذا أردنا التحقق من بيانات Google Search Console (GSC) من Amazon ، فمن المحتمل أن نجد أنها تتلقى الكثير من الزيارات من الاستعلامات ذات العلامات التجارية ، وفي معظم الأحيان ، تكون النتيجة الأولى للاستعلامات ذات العلامات التجارية هي موقع تلك العلامة التجارية.
بصفتك أحد كبار المسئولين الاقتصاديين مثلي ، فمن المحتمل أنك سمعت عدة مرات أن "علامتنا التجارية فقط هي التي تساعد في تحسين محركات البحث لدينا!" كيف يمكننا أن نقول "لا ، هذا ليس هو الحال" ، ونعرض حركة وأرباح الاستعلامات التي لا تتعلق بالعلامة التجارية؟
إن إثبات هذا الأمر أكثر تعقيدًا لأننا نعلم أن خوارزميات Google معقدة للغاية ومن الصعب الفصل بشكل واضح بين عمليات البحث ذات العلامات التجارية وغير ذات العلامات التجارية. ولكن هذا هو ما يجعل ما نقوم به من تحسين محركات البحث أكثر أهمية.
في هذا البرنامج التعليمي ، سأوضح لك كيفية التمييز بين الاثنين - ذي العلامات التجارية وغير المرتبطة بعلامة تجارية - وأظهر لك مدى قوة مُحسنات محركات البحث (SEO).
حتى إذا لم تكن شركتك تحمل علامة تجارية ، فلا يزال بإمكانك كسب الكثير من هذه المقالة: يمكنك معرفة كيفية تقدير البيانات العضوية لموقعك.
SEO ROI على أساس تقدير الحركة
بغض النظر عن مكان وجودك أو ما تفعله ، هناك قيود على الموارد ؛ سواء كانت ميزانية أو مجرد عدد ساعات يوم العمل. تلعب معرفة أفضل السبل لتخصيص مواردك دورًا رئيسيًا في العائد الإجمالي على الاستثمار في تحسين محركات البحث (ROI).
لدى CMO أو نائب الرئيس للتسويق أو مسوق الأداء مؤشرات أداء رئيسية مختلفة وتتطلب موارد مختلفة لتحقيق أهدافها. أفضل طريقة لضمان حصولك على ما تحتاجه هي إثبات ضرورته من خلال إظهار العوائد التي ستجلبها للشركة. SEO ROI لا يختلف. عندما يحين وقت تخصيص الميزانية لهذا العام ويريد فريقك طلب ميزانية أكبر ، فإن تقدير عائد الاستثمار في تحسين محركات البحث (SEO ROI) يمكن أن يمنحك اليد العليا في التفاوض. بمجرد أن تقوم بحساب تقدير حركة المرور بدون علامة تجارية ، يمكنك تقييم الميزانية المطلوبة بشكل أفضل لتحقيق النتائج المرجوة.
تأثير توقع تحسين محركات البحث على إستراتيجية تحسين محركات البحث
كما نعلم ، نقوم كل 3 أو 6 أشهر بمراجعة إستراتيجية تحسين محركات البحث الخاصة بنا وتعديلها للحصول على أفضل النتائج الممكنة. ولكن ماذا يحدث عندما لا تعرف أين يكون الربح الأكبر لشركتك؟ يمكنك اتخاذ قرارات ، لكنها لن تكون فعالة مثل القرارات التي يتم اتخاذها عندما يكون لديك عرض أكثر شمولاً لحركة مرور الموقع.
يمكن دمج تقدير عائدات حركة المرور العضوية غير ذات العلامات التجارية مع صفحاتك المقصودة وتجزئة الاستعلامات لتقديم صورة كبيرة تساعدك على تطوير استراتيجيات أفضل كمدير تحسين محركات البحث أو استراتيجي تحسين محركات البحث.
الطرق المختلفة لتوقع حركة المرور العضوية
هناك الكثير من الطرق المختلفة والنصوص العامة في مجتمع مُحسّنات محرّكات البحث للتنبؤ بالزيارات العضوية المستقبلية.
بعض هذه الطرق تشمل:
- عضوية التنبؤ بحركة المرور على الموقع بأكمله
- توقع حركة المرور العضوية على صفحات معينة (مدونة ، منتجات ، فئات ، إلخ) أو صفحة واحدة
- التنبؤ بالزيارات المجانية لطلبات بحث محددة (تحتوي طلبات البحث على "شراء" و "كيفية التنفيذ" وما إلى ذلك) أو طلب بحث
- توقع حركة المرور العضوية لفترات محددة (خاصة للأحداث الموسمية)
أسلوبي لصفحات محددة والإطار الزمني لشهر واحد.
[دراسة حالة] زيادة النمو في الأسواق الجديدة باستخدام تحسين محركات البحث على الصفحة
 اقرأ دراسة الحالة
اقرأ دراسة الحالةكيفية حساب عائدات حركة المرور العضوية
تعتمد الطريقة الدقيقة على بيانات Google Analytics (GA). إذا كان موقعك جديدًا ، فسيتعين عليك استخدام أدوات الطرف الثالث. أفضل تجنب استخدام مثل هذه الأدوات عندما تكون لديك بياناتك الخاصة.
تذكر أنك ستحتاج إلى اختبار بيانات الطرف الثالث التي تستخدمها مقابل بعض بيانات صفحتك الحقيقية للعثور على أي أخطاء محتملة في بياناتهم.
كيفية حساب عائدات حركة تحسين محركات البحث التي لا تحمل علامة تجارية باستخدام Python
حتى الآن ، قمنا بتغطية الكثير من المفاهيم النظرية التي يجب أن نكون على دراية بها من أجل فهم أفضل للجوانب المختلفة لحركة المرور العضوية وتوقع الإيرادات. الآن ، سوف نتعمق في الجزء العملي من هذه المقالة.
أولاً ، سنبدأ بحساب منحنى نسبة النقر إلى الظهور. في مقالة منحنى نسبة النقر إلى الظهور (CTR) الخاصة بي على Oncrawl ، أشرح طريقتين مختلفتين وأيضًا طرق أخرى يمكنك استخدامها من خلال إجراء بعض التغييرات في الكود الخاص بي. أوصيك بقراءة مقالة منحنى النقر أولاً ؛ يمنحك رؤى حول هذه المقالة.
في هذه المقالة ، أقوم بتعديل بعض أجزاء الكود الخاص بي للحصول على النتائج المحددة التي نريدها في تقدير حركة المرور. بعد ذلك ، سنحصل على بياناتنا من GA ونستخدم بُعد إيرادات GA لتقدير أرباحنا.
التنبؤ بإيرادات حركة المرور العضوية غير المرتبطة بعلامة تجارية باستخدام Python: الشروع في العمل
يمكنك تشغيل هذا الكود بنفسك ، دون معرفة أي لغة بايثون. ومع ذلك ، أفضل أن تعرف القليل عن بناء جملة Python والمعرفة الأساسية حول مكتبات Python التي سأستخدمها في كود التنبؤ هذا. سيساعدك هذا على فهم الكود الخاص بي بشكل أفضل وتخصيصه بطريقة مفيدة لك.
لتشغيل هذا الرمز ، سأستخدم Visual Studio Code بامتداد Python من Microsoft ، والذي يتضمن امتداد "Jupyter". ولكن ، يمكنك استخدام دفتر Jupyter نفسه.
للعملية بأكملها ، نحتاج إلى استخدام مكتبات Python هذه:
- نومبي
- الباندا
- مؤامرة
أيضًا ، سنقوم باستيراد بعض مكتبات Python القياسية:
- جسون
- الطباعة
# استيراد المكتبات التي نحتاجها لعمليتنا استيراد json من pprint استيراد pprint استيراد numpy كـ np استيراد الباندا كما pd استيراد plotly.express كـ بكسل
الخطوة 1: حساب منحنى نسبة النقر إلى الظهور النسبي (منحنى النقر النسبي)
في الخطوة الأولى ، نريد حساب منحنى نسبة النقر إلى الظهور النسبي. ولكن ، ما هو منحنى نسبة النقر إلى الظهور النسبي؟
ما هو منحنى نسبة النقر إلى الظهور النسبي؟
لنبدأ أولاً بالحديث عن "منحنى نسبة النقر إلى الظهور المطلق". عندما نحسب منحنى نسبة النقر إلى الظهور المطلق ، نقول إن متوسط نسبة النقر إلى الظهور (أو متوسط نسبة النقر إلى الظهور) للموضع الأول هو 36٪ والموضع الثاني 20٪ ، وهكذا.
في منحنى نسبة النقر إلى الظهور النسبي ، لحظة النسبة المئوية ، نقسم كل وسيط موضع على نسبة النقر إلى الظهور (CTR) للموضع الأول. على سبيل المثال ، سيكون منحنى نسبة النقر إلى الظهور النسبي للموضع الأول 0.36 / 0.36 = 1 ، والثاني سيكون 0.20 / 0.36 = 0.55 ، وهكذا.
ربما تتساءل لماذا من المفيد حساب هذا؟ فكر في صفحة مرتبة في الموضع الأول ، بها 44٪ نسبة النقر إلى الظهور. إذا انتقلت هذه الصفحة إلى الموضع الثاني ، فلن ينخفض منحنى نسبة النقر إلى الظهور إلى 20٪ ، ومن المرجح أن تنخفض نسبة النقر إلى الظهور إلى 44٪ * 0.55 = 24.2٪.
1. الحصول على بيانات حركة المرور العضوية ذات العلامات التجارية وغير ذات العلامات التجارية من GSC
بالنسبة لعملية الحساب لدينا ، نحتاج إلى الحصول على بياناتنا من GSC. في المرة الأولى ، ستستند جميع البيانات إلى استعلامات ذات علامة تجارية وفي المرة القادمة ، ستستند جميع البيانات إلى استعلامات غير متعلقة بعلامة تجارية.
للحصول على هذه البيانات ، يمكنك استخدام طرق مختلفة: من نصوص Python النصية أو من الوظيفة الإضافية "Search Analytics for Sheets" في جداول بيانات Google. سأستخدم مستكشف GSC API.
ناتج هذه البيانات عبارة عن ملفين JSON يعرضان أداء كل صفحة. ملف JSON يعرض أداء الصفحات المقصودة استنادًا إلى الاستعلامات المتعلقة بالعلامة التجارية بينما يعرض الآخر أداء الصفحات المقصودة بناءً على طلبات البحث غير المتعلقة بعلامة تجارية.
للحصول على البيانات من GSC API Explorer ، اتبع الخطوات التالية:
- انتقل إلى https://developers.google.com/webmaster-tools/v1/searchanalytics/query.
- قم بتكبير مستكشف API الموجود في الزاوية اليمنى العليا من الصفحة.
- في حقل "
siteUrl" ، أدخل اسم المجال الخاص بك. على سبيل المثال "https://www.example.com" أو "http://your-domain.com". - في نص الطلب ، نحتاج أولاً إلى تحديد معلمات "
startDate" و "endDate". أفضّل هو الثلاثين يومًا الماضية. - ثم نضيف "
dimensions" ونختار "page" لهذه القائمة. - نضيف الآن "
dimensionFilterGroups" لتصفية استفساراتنا. مرة واحدة للعلامات التجارية والثانية لطلبات البحث غير المتعلقة بالعلامة التجارية. - في النهاية ، حددنا "
rowLimit" على 25000. إذا كانت صفحات موقعك التي تحصل على حركة مرور عضوية كل شهر أكثر من 25 ألفًا ، فيجب عليك تعديل نص الطلب. - بعد إجراء كل طلب ، احفظ استجابة JSON. للحصول على أداء ذي علامة تجارية ، احفظ ملف JSON باسم "
branded_data.json" وللحصول على أداء لا يحمل علامة تجارية ، احفظ ملف JSON باسم "non_branded_data.json".
بعد أن نفهم المعلمات في نص الطلب الخاص بنا ، فإن الشيء الوحيد الذي عليك القيام به هو نسخ ، ولصق نصوص الطلب أدناه. ضع في اعتبارك استبدال أسماء العلامات التجارية " brand variation names ".
يجب فصل أسماء العلامات التجارية بخط أنابيب أو “ | ". على سبيل المثال " amazon|amazon.com|amazn ".
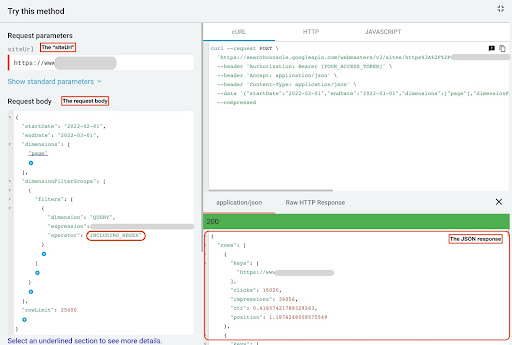
مستكشف واجهة برمجة تطبيقات GSC
نص الطلب ذو العلامات التجارية:
{
"تاريخ البدء": "2022-02-01"،
"تاريخ الانتهاء": "2022-03-01"،
"أبعاد": [
"صفحة"
] ،
"DimFilterGroups": [
{
"الفلاتر": [
{
"البعد": "QUERY" ،
"التعبير": "أسماء أنواع العلامات التجارية" ،
"عامل التشغيل": "INCLUDING_REGEX"
}
]
}
] ،
"rowLimit": 25000
}
نص طلب ليس له علامة تجارية:
{
"تاريخ البدء": "2022-02-01"،
"تاريخ الانتهاء": "2022-03-01"،
"أبعاد": [
"صفحة"
] ،
"DimFilterGroups": [
{
"الفلاتر": [
{
"البعد": "QUERY" ،
"التعبير": "أسماء أنواع العلامات التجارية" ،
"عامل التشغيل": "EXCLUDING_REGEX"
}
]
}
] ،
"rowLimit": 25000
}
2. استيراد البيانات إلى دفتر Jupyter الخاص بنا واستخراج أدلة الموقع
الآن ، نحتاج إلى تحميل بياناتنا في دفتر Jupyter الخاص بنا حتى نتمكن من تعديله واستخراج ما نريد منه. دعنا ننتقل من حيث توقفنا أعلاه.
من أجل تحميل البيانات ذات العلامات التجارية ، تحتاج إلى تنفيذ كتلة التعليمات البرمجية هذه:
# إنشاء إطار بيانات لأداء عناوين URL الخاصة بموقع الويب على العلامة التجارية والاستعلامات ذات العلامات التجارية
مع فتح ("./ branded_data.json") مثل json_file:
branded_data = json.loads (json_file.read ()) ["صفوف"]
branded_df = pd.DataFrame (branded_data)
# إعادة تسمية عمود "المفاتيح" إلى عمود "الصفحة المقصودة" ، وتحويل قائمة "الصفحة المقصودة" إلى عنوان URL
branded_df.rename (الأعمدة = {"keys": "الهبوط الصفحة"} ، inplace = True)
branded_df ["الصفحة المقصودة"] = branded_df ["الصفحة المقصودة"]. تنطبق (lambda x: x [0])
بالنسبة إلى الصفحات المقصودة ذات الأداء غير المرتبط بعلامة تجارية ، ستحتاج إلى تنفيذ هذا الجزء من التعليمات البرمجية:
# إنشاء إطار بيانات لأداء عناوين URL الخاصة بالموقع على الاستعلامات غير المتعلقة بعلامة تجارية
مع open ("./ non_branded_data.json") كملف json_file:
non_branded_data = json.loads (json_file.read ()) ["صفوف"]
non_branded_df = pd.DataFrame (non_branded_data)
# إعادة تسمية عمود "المفاتيح" إلى عمود "الصفحة المقصودة" ، وتحويل قائمة "الصفحة المقصودة" إلى عنوان URL
non_branded_df.rename (الأعمدة = {"keys": "Land page"}، inplace = True)
non_branded_df ["الصفحة المقصودة"] = non_branded_df ["الصفحة المقصودة"]. تنطبق (lambda x: x [0])
نقوم بتحميل بياناتنا ، ثم نحتاج إلى تحديد اسم موقعنا لاستخراج الأدلة الخاصة به.
# تحديد اسم موقعك بين الاقتباسات. على سبيل المثال ، "https://www.example.com/" أو "http://mydomain.com/" SITE_NAME = "https://www.your_domain.com/"
نحتاج فقط إلى استخراج الدلائل من الأداء غير ذي العلامات التجارية.
# الحصول على دليل كل صفحة مقصودة (URL)
non_branded_df ["directory"] = non_branded_df ["الصفحة المقصودة"]. str.extract (
بات = f "((؟ <= {SITE_NAME}) [^ /] +)"
)
ثم نقوم بطباعة الدلائل من أجل تحديد أي منها مهم لهذه العملية. قد ترغب في تحديد كافة الأدلة للحصول على رؤية أفضل لموقعك.

# للحصول على جميع الأدلة في المخرجات ، نحتاج إلى معالجة خيارات Pandas
pd.set_option ("display.max_rows" ، بلا)
# أدلة الموقع
non_branded_df ["الدليل"]. value_counts ()
هنا ، يمكنك إدراج الدلائل التي تهمك.
اختر "" أي الدلائل مهمة للحصول على منحنى نسبة النقر إلى الظهور.
أدخل الدلائل في متغير "الدلائل_المهمة".
على سبيل المثال ، "product، tag، product-category، mag". افصل قيم الدليل بفاصلة.
""
IMPORTANT_DIRECTORIES = "your_important_directories"
IMPORTANT_DIRECTORIES = IMPORTANT_DIRECTORIES.split ("،")
3. تسمية الصفحات بناءً على موضعها وحساب منحنى نسبة النقر إلى الظهور النسبي
نحتاج الآن إلى تصنيف صفحاتنا المقصودة بناءً على موضعها. نقوم بذلك ، لأننا نحتاج إلى حساب منحنى نسبة النقر إلى الظهور النسبي لكل دليل بناءً على موضع صفحته المقصودة.
# وضع العلامات على المواقع غير ذات العلامات التجارية
بالنسبة لـ i في النطاق (1 ، 11):
non_branded_df.loc [
(non_branded_df ["position"]> = i) & (non_branded_df ["position"] <i + 1) ،
"تسمية الموقع"،
] = أنا
بعد ذلك ، نقوم بتجميع الصفحات المقصودة بناءً على دليلها.
# تجميع الصفحات المقصودة بناءً على قيمة "الدليل" non_brand_grouped_df = non_branded_df.groupby (["الدليل"])
دعنا نحدد الوظيفة لحساب منحنى نسبة النقر إلى الظهور النسبي.
def each_dir_relative_ctr_curve (dir_df ، مفتاح):
"" "تحسب الوظيفة كل منحنى نسبة النقر إلى الظهور النسبي IMPORTANT_DIRECTORIES.
""
# تجميع "non_brand_grouped_df" بناءً على قيمة "تصنيف الموضع"
dir_grouped_df = dir_df.groupby (["تسمية الموقع"])
# قائمة لحفظ كل مركز متوسط نسبة النقر إلى الظهور
median_ctr_list = []
# تخزين كل دليل كمفتاح ، ويكون "median_ctr_list" كقيمة
directories_median_ctr = {}
# حلقة فوق كل مجموعة "dir_grouped_df"
بالنسبة لـ i في النطاق (1 ، 11):
# تجربة باستثناء التعامل مع المواقف التي لا يحتوي دليل على سبيل المثال على أي بيانات للموضع 4
محاولة:
tmp_df = dir_grouped_df.get_group (i)
median_ctr_list.append (np.median (tmp_df ["ctr"]))
إلا:
median_ctr_list.append (0)
# حساب منحنى نسبة النقر إلى الظهور النسبي
directories_median_ctr [مفتاح] = np.array (median_ctr_list) / np.array (
[median_ctr_list [0]] * 10
)
إرجاع directoryories_median_ctr
بعد تحديد الوظيفة ، نقوم بتشغيلها.
# التكرار على الدلائل وتنفيذ وظيفة "each_dir_relative_ctr_curve"
directories_median_ctr_dict =ict ()
للمفتاح ، عنصر في non_brand_grouped_df:
إذا كان المفتاح في IMPORTANT_DIRECTORIES:
directories_median_ctr_dict.update (each_dir_relative_ctr_curve (عنصر ، مفتاح))
المطبوعات
الآن ، سنقوم بتحميل صفحاتنا المقصودة ، ذات العلامات التجارية وغير ذات العلامات التجارية ، والأداء ونحسب منحنى نسبة النقر إلى الظهور النسبي لبياناتنا غير المتعلقة بالعلامات التجارية. لماذا نفعل هذا للبيانات التي لا تتعلق بالعلامة التجارية فقط؟ لأننا نريد توقع الزيارات والأرباح العضوية غير المرتبطة بعلامة تجارية.
الخطوة 2: توقع عائدات الزيارات العضوية غير المتعلقة بعلامات تجارية
في هذه الخطوة الثانية ، سنتطرق إلى كيفية استرداد بيانات الإيرادات الخاصة بنا والتنبؤ بإيراداتنا.
1. دمج البيانات العضوية ذات العلامات التجارية وغير ذات العلامات التجارية
الآن ، سنقوم بدمج بياناتنا ذات العلامات التجارية وغير ذات العلامات التجارية. سيساعدنا هذا في حساب النسبة المئوية للزيارات العضوية غير المتعلقة بعلامة تجارية في كل صفحة مقصودة مقارنةً بجميع الزيارات.
# "main_df" هي مزيج من "بيانات الموقع بالكامل" و "البيانات غير المتعلقة بالعلامة التجارية" DataFrames.
# باستخدام DataFrame هذا ، يمكنك معرفة معظم نقراتنا ومرات الظهور
# تأتي من طلبات البحث التي لا تحمل علامة تجارية.
main_df = non_branded_df.merge (
branded_df ، على = "الصفحة المقصودة" ، اللواحق = ("_ non_brand"، "_branded")
)
ثم نقوم بتعديل الأعمدة لإزالة الأعمدة عديمة الفائدة.
# تعديل أعمدة "main_df" لتلك التي نحتاجها
main_df = main_df [
[
"الصفحة المقصودة"،
"click_non_brand"،
"ctr_non_brand" ،
"الدليل"،
"تسمية الموقع"،
"click_branded"،
]
]
الآن ، لنحسب نسبة النقرات غير المتعلقة بعلامة تجارية إلى إجمالي نقرات الصفحة المقصودة.
# حساب النسبة المئوية لنقرات طلبات البحث غير المتعلقة بعلامة تجارية استنادًا إلى الصفحات المقصودة إلى نقرات الصفحة المقصودة بالكامل
main_df.loc [:، "click_non_brand_percentage"] = main_df.apply (
lambda x: x ["click_non_brand"] / (x ["click_non_brand"] + x ["click_branded"]) ،
المحور = 1 ،
)
[كتاب إلكتروني] أتمتة SEO مع Oncrawl
 اقرأ الكتاب الإلكتروني
اقرأ الكتاب الإلكتروني2. تحميل عائدات حركة المرور العضوية
تمامًا مثل استرداد بيانات GSC ، لدينا عدد من الطرق للحصول على بيانات GA: يمكننا استخدام "الوظيفة الإضافية لجداول Google Analytics" أو واجهة برمجة تطبيقات GA. في هذا البرنامج التعليمي ، أفضل استخدام Google Data Studio (GDS) نظرًا لبساطته.
من أجل الحصول على بيانات GA من GDS ، اتبع الخطوات التالية:
- في GDS ، قم بإنشاء تقرير جديد أو مستكشف وجدول.
- بالنسبة للبعد ، أضف "الصفحة المقصودة" وبالنسبة للمقياس ، يجب أن نضيف "الإيرادات".
- بعد ذلك ، ستحتاج إلى إنشاء شريحة مخصصة في GA بناءً على المصدر والوسيط. تصفية حركة مرور "Google / العضوية". بعد إنشاء المقطع ، قم بإضافته إلى قسم المقطع في GDS.
- في الخطوة الأخيرة ، قم بتصدير الجدول وحفظه باسم "
landing_pages_revenue.csv".
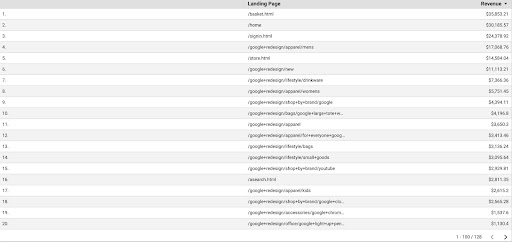
تصدير عائدات الصفحات المقصودة بتنسيق CSV
لنقم بتحميل بياناتنا.
Organic_revenue_df = pd.read_csv ("./ data / landing_pages_revenue.csv")
الآن ، نحتاج إلى إلحاق اسم موقعنا بعناوين URL لصفحات GA المقصودة.
عندما نقوم بتصدير بياناتنا من GA ، تكون الصفحات المقصودة في شكل نسبي ، لكن بيانات GSC الخاصة بنا في الشكل المطلق.
لا تنس التحقق من بيانات صفحات GA المقصودة الخاصة بك. في مجموعات البيانات التي عملت معها ، وجدت أن بيانات GA تحتاج إلى القليل من التنظيف في كل مرة.
# ربط عناوين URL لصفحات GA المقصودة بالموقع SITE_NAME.
# أيضا ، إعادة تسمية الأعمدة
Organic_revenue_df.loc [:، "Landing Page"] = (
SITE_NAME [: - 1] + organic_revenue_df [organic_revenue_df.columns [0]]
)
العضوية_revenue_df.rename (الأعمدة = {"الصفحة المقصودة": "الصفحة المقصودة" ، "الأرباح": "الأرباح"} ، inplace = True)
الآن ، دعنا ندمج بيانات GSC الخاصة بنا مع بيانات GA.
# في هذه الخطوة ، أقوم بدمج "main_df" مع "dk_organic_revenue_df" DataFrame الذي يحتوي على النسبة المئوية لبيانات الاستفسارات غير المتعلقة بالعلامة التجارية main_df = main_df.merge (organic_revenue_df ، على = "الصفحة المقصودة" ، كيف = "اليسار")
في نهاية هذا القسم ، نقوم ببعض التنظيف على أعمدة DataFrame الخاصة بنا.
# تنظيف بسيط لـ DataFrame "main_df"
main_df = main_df [
[
"الصفحة المقصودة"،
"click_non_brand"،
"ctr_non_brand" ،
"الدليل"،
"تسمية الموقع"،
"click_non_brand_percentage" ،
"ربح"،
]
]
3. احتساب الإيرادات غير ذات العلامات التجارية
في هذا القسم ، سنقوم بمعالجة البيانات لاستخراج المعلومات التي نبحث عنها.
ولكن قبل أي شيء ، دعنا نصفي صفحاتنا المقصودة بناءً على " IMPORTANT_DIRECTORIES ":
# إزالة أدلة أخرى من الصفحات المقصودة ، غير المدرجة في "IMPORTANT_DIRECTORIES"
main_df = (
main_df [main_df ["الدليل"]. isin (IMPORTANT_DIRECTORIES)]
.dropna (مجموعة فرعية = ["الإيرادات"])
.reset_index (قطرة = صحيح)
)
الآن ، دعنا نحسب زيارات الإيرادات العضوية غير المتعلقة بعلامة تجارية.
لقد حددت مقياسًا لا يمكننا حسابه بسهولة وهو حدس أكثر من أي شيء آخر يقودنا إلى تخصيص رقم له.
يوضح مقياس " brand_influence العلامة التجارية" قوة علامتك التجارية. إذا كنت تعتقد أن عمليات البحث غير المتعلقة بالعلامات التجارية تؤدي إلى انخفاض مبيعات نشاطك التجاري ، فقلل هذا الرقم ؛ شيء من هذا القبيل 0.8 على سبيل المثال.
# إذا كانت علامتك التجارية قوية جدًا لدرجة أن الاستعلام بدون علامتك التجارية يمكن أن يبيع بقدر الاستعلام عن علامتك التجارية ، فإن الرقم 1 مفيد لك.
# فكر في البحث عن كتاب بدون اسم علامة تجارية مدرج في استفسارك. عندما ترى أمازون ، هل تشتري من الأسواق أو المتاجر الأخرى؟
brand_influence = 1
main_df.loc [:، "non_brand_revenue"] = main_df.apply (
lambda x: x ["الأرباح"] * x ["click_non_brand_percentage"] * brand_influence ، المحور = 1
)
دعنا نرسم مخططًا دائريًا للحصول على نظرة ثاقبة للإيرادات غير ذات العلامات التجارية استنادًا إلى الدلائل المهمة.
# في هذه الخلية ، أرغب في الحصول على جميع إيرادات الصفحات المقصودة التي لا تحمل علامة تجارية استنادًا إلى دليلها
non_branded_directory_dist_revenue_df = pd.pivot_table (
main_df ،
الفهرس = "الدليل" ،
القيم = ["non_brand_revenue"] ،
aggfunc = {"non_brand_revenue": "sum"}،
)
pie_fig = px.pie (
non_branded_directory_dist_revenue_df ،
القيم = "non_brand_revenue" ،
الأسماء = non_branded_directory_dist_revenue_df.index ،
title = "الأرباح غير المتعلقة بعلامة تجارية استنادًا إلى أدلة مواقع الويب" ،
)
pie_fig.update_traces (textposition = "inside" ، textinfo = "percent + label")
pie_fig.show ()
تعرض هذه المؤامرة توزيع الاستعلامات غير المتعلقة بعلامة تجارية على IMPORTANT_DIRECTORIES الخاص بك.
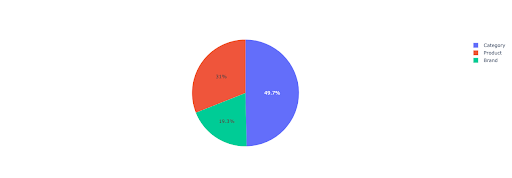
توزيع الاستفسارات غير المتعلقة بعلامات تجارية
بناءً على بيانات منحنى نسبة النقر إلى الظهور (CTR) الخاصة بي ، أرى أنه لا يمكنني الاعتماد على نسبة النقر إلى الظهور (CTR) للمواضع الأعلى من 5. ولهذا السبب ، أقوم بتصفية بياناتي بناءً على المركز.
يمكنك تعديل كتلة التعليمات البرمجية أدناه بناءً على بياناتك.
# بسبب دقة نسبة النقر إلى الظهور (CTR) في منحنى نسبة النقر إلى الظهور (CTR) لدينا ، أعتقد أنه يمكننا تخطي عمليات الهبوط بالموضع أكثر من 5. ولهذا السبب ، قمت بتصفية الصفحات المقصودة الأخرى main_df = main_df [main_df ["تسمية الموضع"] <6] .reset_index (إسقاط = صحيح)
4. حساب "عائد النقرة" (RPC)
هنا ، قمت بإنشاء مقياس مخصص وسميته "عائد كل نقرة" أو RPC. يوضح لنا هذا العائد الناتج عن كل نقرة غير متعلقة بعلامة تجارية.
يمكنك استخدام هذا المقياس بطرق مختلفة. لقد وجدت صفحة بها RPC عالية ، ولكن نقرات منخفضة. عندما راجعت الصفحة ، اكتشفت أنه تمت فهرستها قبل أقل من أسبوع ويمكننا استخدام طرق مختلفة لتحسين الصفحة.
# حساب الإيرادات المتولدة مع كل نقرة (RPC: Revenue Per Click)
main_df ["rpc"] = main_df.apply (
lambda x: x ["non_brand_revenue"] / x ["click_non_brand"] ، المحور = 1
)
5. توقع الإيرادات!
نحن نقترب من النهاية ، لقد انتظرنا حتى الآن للتنبؤ بإيراداتنا العضوية غير ذات العلامات التجارية.
لنقم بتشغيل آخر كتل التعليمات البرمجية.
# الوظيفة الرئيسية لحساب الإيرادات على أساس المواقف المختلفة
للفهرس ، row_values في main_df.iterrows ():
# التبديل بين قائمة الدلائل CTR
ctr_curve = directories_median_ctr_dict [row_values ["دليل"]]
# التكرار على الموضع 1 إلى 5 وحساب الإيرادات على أساس زيادة أو نقصان نسبة النقر إلى الظهور
بالنسبة لـ i في النطاق (1 ، 6):
إذا كان i == row_values ["تسمية الموضع"]:
main_df.loc [index، i] = row_values ["non_brand_revenue"]
آخر:
# main_df.loc [الفهرس ، i + 1] ==
main_df.loc [index، i] = (
row_values ["non_brand_revenue"]
* (ctr_curve [i - 1])
/ ctr_curve [int (row_values ["position label"] - 1)]
)
# حساب مقياس "N إلى 1". يوضح هذا زيادة الإيرادات عندما تنتقل مرتبتك من "N" إلى "1"
main_df.loc [index، "N to 1"] = main_df.loc [index، 1] - main_df.loc [index، row_values ["position label"]]
بالنظر إلى الناتج النهائي ، لدينا أعمدة جديدة. أسماء هذه الأعمدة هي "1" ، "2" ، "3" ، "4" ، "5".
ماذا تعني هذه الأسماء؟ على سبيل المثال ، لدينا صفحة في الموضع 3 ونريد توقع إيراداتها إذا حسنت وضعها ، أو نريد أن نعرف مقدار الخسارة إذا تراجعنا في الترتيب.
يُظهر العمودان "1" و "2" عائدات الصفحة عندما يتحسن متوسط موضع هذه الصفحة ويعرض العمودان "4" و "5" عائدات هذه الصفحة عندما نتراجع في الترتيب.
يُظهر العمود "3" في هذا المثال الإيرادات الحالية للصفحة.
أيضًا ، لقد أنشأت مقياسًا يسمى "N إلى 1". يوضح لك هذا ما إذا كان متوسط موضع هذه الصفحة قد تحرك من "3" (أو N) إلى "1" ومدى تأثير هذه الخطوة على الإيرادات.
تغليف
لقد غطيت الكثير في هذه المقالة والآن حان دورك لتلوث يديك وتتنبأ بإيرادات حركة المرور العضوية غير ذات العلامات التجارية.
هذه هي أبسط طريقة يمكننا من خلالها استخدام هذا التوقع. يمكننا جعل هذه الخوارزمية أكثر تعقيدًا ودمجها مع بعض نماذج ML ، لكن هذا سيجعل المقالة أكثر تعقيدًا.
أفضل حفظ هذه البيانات في ملف CSV وتحميلها إلى جدول بيانات Google. أو ، إذا كنت أخطط لمشاركته مع الأعضاء الآخرين في فريقي أو المنظمة ، فسأفتحه باستخدام Excel وتنسيق الأعمدة باستخدام الألوان حتى يسهل قراءتها.
بناءً على هذه البيانات ، يمكنك توقع عائد الاستثمار لحركة المرور العضوية غير ذات العلامات التجارية واستخدامها في عملية التفاوض الخاصة بك.