
التنبؤ بحركة سيو مع نبي وبايثون
نشرت: 2021-03-16يعد تحديد الأهداف وتقييم الإنجاز بمرور الوقت تمرينًا ممتعًا للغاية لفهم ما يمكننا تحقيقه وما إذا كانت الإستراتيجية التي نستخدمها فعالة أم لا. ومع ذلك ، ليس من السهل عادةً تحديد هذه الأهداف لأننا سنحتاج أولاً إلى وضع توقعات.
إن إنشاء توقعات ليس بالأمر السهل ولكن بفضل بعض إجراءات التنبؤ المتاحة ووحدة المعالجة المركزية وبعض مهارات البرمجة ، يمكننا تقليل تعقيدها كثيرًا. في هذا المنشور ، سأوضح لك كيف يمكننا عمل تنبؤات دقيقة وكيف يمكنك تطبيق ذلك على مُحسّنات محرّكات البحث باستخدام Python و Library Prophet ودون الحاجة إلى امتلاك قوى خارقة في العرافة.
إذا لم تسمع عن النبي من قبل ، فقد تتساءل ما هو عليه. باختصار ، النبي هو إجراء للتنبؤ تم إصداره بواسطة فريق علوم البيانات الأساسية في Facebook والمتوفر بلغتي Python و R والذي يتعامل مع القيم المتطرفة والتأثيرات الموسمية بشكل جيد للغاية
تقديم تنبؤات دقيقة وسريعة.
عندما نتحدث عن التنبؤ ، يجب أن نأخذ في الاعتبار شيئين:
- كلما زادت البيانات التاريخية التي لدينا ، كان نموذجنا أكثر دقة وبالتالي ستكون توقعاتنا.
- لن يكون النموذج التنبئي صالحًا إلا إذا بقيت العوامل الداخلية كما هي ولم تكن هناك عوامل خارجية تؤثر عليه. هذا يعني أنه على سبيل المثال ، إذا كنا ننشر منشورًا واحدًا كل أسبوع ونبدأ في نشر منشورين في الأسبوع ، فقد لا يكون هذا النموذج صالحًا للتنبؤ بنتيجة تغيير هذه الإستراتيجية. من ناحية أخرى ، إذا كان هناك تحديث للخوارزمية ، فقد لا يكون النموذج صالحًا أيضًا. ضع في اعتبارك أن النموذج مبني على أساس البيانات التاريخية.
لتطبيق هذا على مُحسّنات محرّكات البحث ، ما سنفعله هو توقع جلسات تحسين محركات البحث للشهر القادم باتباع الخطوات التالية:
- الحصول على بيانات من Google Analytics حول الجلسات العضوية لفترة زمنية محددة.
- تدريب نموذجنا.
- التنبؤ بحركة تحسين محركات البحث (SEO) للشهر القادم.
- تقييم مدى جودة نموذجنا بمتوسط الخطأ المطلق.
هل تريد التعرف على المزيد حول كيفية عمل إجراء التنبؤ هذا؟ لنبدأ بعد ذلك!
الحصول على البيانات من Google Analytics
يمكننا التعامل مع استخراج البيانات من Google Analytics بطريقتين: تصدير ملف Excel من الواجهة العادية أو استخدام واجهة برمجة التطبيقات لاسترداد هذه البيانات.
استيراد البيانات من ملف إكسل
أسهل طريقة للحصول على هذه البيانات من Google Analytics هي الانتقال إلى قسم القنوات في الشريط الجانبي ، والنقر على "عضوي" وتصدير البيانات باستخدام الزر الموجود أعلى الصفحة. تأكد من تحديد المتغير الذي ترغب في تحليله ، في هذه الحالة "الجلسات" في القائمة المنسدلة أعلى الرسم البياني.
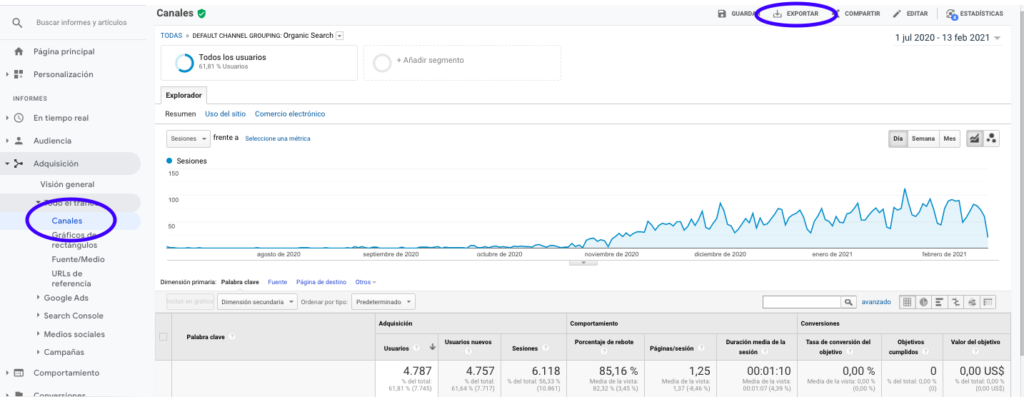
بعد تصدير البيانات كملف Excel ، يمكننا استيرادها إلى دفتر ملاحظاتنا باستخدام Pandas. لاحظ أن ملف Excel الذي يحتوي على مثل هذه البيانات سيحتوي على علامات تبويب مختلفة ، لذلك يجب تحديد علامة التبويب التي تحتوي على حركة المرور الشهرية كوسيطة في جزء الكود الموجود أدناه. نقوم أيضًا بمسح الصف الأخير لأنه يحتوي على إجمالي عدد الجلسات ، مما قد يؤدي إلى تشويه نموذجنا.
استيراد الباندا كما pd
df = pd.read_excel ('.xlsx'، sheet_name = "")
df = df.drop (لين (مدافع) - 1)
يمكننا رسم شكل البيانات باستخدام Matplotlib:
من matplotlib استيراد pyplot
df ["Sesiones"]. مؤامرة (العنوان = "Sesiones")
pyplot.show () 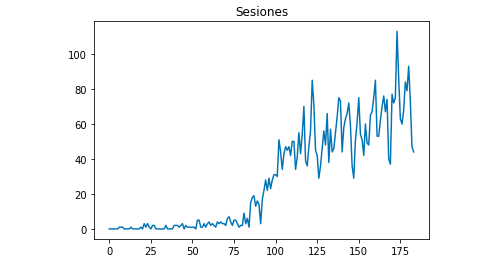
باستخدام Google Analytics API
بادئ ذي بدء ، من أجل الاستفادة من Google Analytics API ، نحتاج إلى إنشاء مشروع على وحدة تحكم مطوري Google ، وتمكين خدمة إعداد التقارير في Google Analytics والحصول على بيانات الاعتماد. يشرح Jean-Christophe Chouinard جيدًا في هذا المقال كيفية إعداد هذا.
بمجرد الحصول على بيانات الاعتماد ، نحتاج إلى المصادقة قبل تقديم طلبنا. يجب إجراء المصادقة باستخدام ملف بيانات الاعتماد الذي تم الحصول عليه في البداية من وحدة تحكم مطوري Google. سنحتاج أيضًا إلى كتابة معرف عرض GA من الموقع الذي نرغب في استخدامه في الكود الخاص بنا.
من apiclient.discovery استيراد بناء
من oauth2client.service_account import ServiceAccountCredentials
SCOPES = ['https://www.googleapis.com/auth/analytics.readonly']
KEY_FILE_LOCATION = "
رأي_
بيانات الاعتماد = ServiceAccountCredentials.from_json_keyfile_name (KEY_FILE_LOCATION ، SCOPES)
التحليلات = البناء ('analyticsreporting' ، 'v4' ، بيانات الاعتماد = بيانات الاعتماد)بعد المصادقة ، نحتاج فقط إلى تقديم الطلب. الشيء الذي نحتاج إلى استخدامه للحصول على بيانات حول الجلسات العضوية لكل يوم هو:
response = analytics.reports (). batchGet (body = {
'reportRequests': [{
"viewId": VIEW_ID ،
'dateRanges': [{'startDate': '2020-09-01'، 'endDate': '2021-01-31'}]،
"المقاييس": [
{"تعبير": "ga: Session"}
]، "أبعاد": [
{"الاسم": "ga: date"}
] ،
"عوامل التصفية": "ga: channelGrouping = ~ عضوي"،
"includeEmptyRows": "true"
}]}).نفذ - اعدم()لاحظ أننا نختار النطاق الزمني في نطاقات التاريخ. في حالتي ، سأستعيد البيانات من الأول من أيلول (سبتمبر) حتى 31 كانون الثاني (يناير): [{'startDate': '2020-09-01'، 'endDate': '2021-01-31'}]
بعد ذلك ، نحتاج فقط إلى إحضار ملف الردود لإلحاق قائمة الأيام بجلساتهم العضوية:
list_values = [] بالنسبة إلى x استجابةً ["التقارير"] [0] ["البيانات"] ["الصفوف"]: list_values.append ([x ["أبعاد"] [0] ، x ["مقاييس"] [0] ["قيم"] [0]])
كما ترى ، فإن استخدام Google Analytics API بسيط للغاية ويمكن استخدامه للعديد من الأهداف. في هذه المقالة ، شرحت كيف يمكنك استخدام Google Analytics API لإنشاء تنبيهات لاكتشاف الصفحات ذات الأداء الضعيف.

تكييف القوائم مع أطر البيانات
للاستفادة من النبي ، نحتاج إلى إدخال إطار بيانات بعمودين يجب تسميتهما: "ds" و "y". إذا كنت قد قمت باستيراد البيانات من ملف Excel ، فلديناها بالفعل كإطار بيانات ، لذلك ستحتاج فقط إلى تسمية العمودين "ds" و "y":
df.columns = ['ds'، 'y']
في حالة استخدامك لواجهة برمجة التطبيقات لاسترداد البيانات ، فإننا نحتاج إلى تحويل القائمة إلى إطار بيانات وتسمية الأعمدة على النحو المطلوب:
من الباندا استيراد DataFrame df_sessions = DataFrame (list_values ، الأعمدة = ['ds'، 'y'])
تدريب النموذج
بمجرد أن نحصل على Dataframe بالتنسيق المطلوب ، يمكننا تحديد نموذجنا وتدريبه بسهولة شديدة باستخدام:
استيراد fbprophet من fbprophet استيراد النبي النموذج = النبي () model.fit (df_sessions)
جعل توقعاتنا
أخيرًا بعد تدريب نموذجنا ، يمكننا البدء في التنبؤ! من أجل المضي قدمًا في التنبؤات ، سنحتاج أولاً إلى إنشاء قائمة بنطاق الوقت الذي نرغب في التنبؤ به وتعديل تنسيق التاريخ والوقت:
من استيراد الباندا to_datetime توقعات_أيام = [] لـ x في النطاق (1 ، 28): التاريخ = "2021-02-" + str (x) Forecast_days.append ([التاريخ]) توقعات_الأيام = إطار البيانات (يوم_التوقع) Forecast_days.columns = ['ds'] Forecast_days ['ds'] = to_datetime (Forecast_days ['ds'])
في هذا المثال ، أستخدم حلقة ستنشئ إطار بيانات يحتوي على جميع الأيام من فبراير. والآن يتعلق الأمر فقط باستخدام النموذج الذي تم تدريبه مسبقًا:
التنبؤ = model.predict (Forecast_days)
يمكننا رسم مخطط يوضح الفترة الزمنية المتوقعة:
من matplotlib استيراد pyplot model.plot (تنبؤ) pyplot.show ()
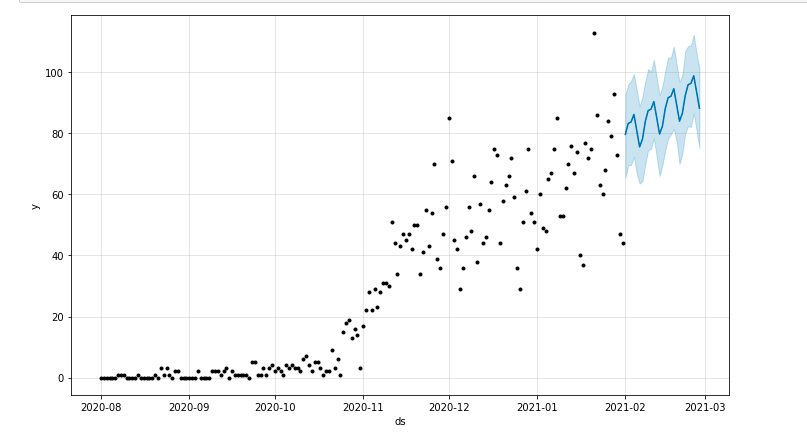
تقييم النموذج
أخيرًا ، يمكننا تقييم مدى دقة نموذجنا من خلال حذف بعض الأيام من البيانات المستخدمة لتدريب النموذج ، والتنبؤ بجلسات تلك الأيام وحساب متوسط الخطأ المطلق.
على سبيل المثال ، ما سأفعله هو حذف آخر 12 يومًا من إطار البيانات الأصلي من كانون الثاني (يناير) ، والتنبؤ بجلسات كل يوم ومقارنة حركة المرور الفعلية بالحركة المتوقعة.
أولاً ، نحذف من إطار البيانات الأصلي الـ 12 يومًا الأخيرة مع pop وننشئ إطار بيانات جديدًا سيتضمن فقط تلك الـ 12 يومًا التي سيتم استخدامها للتنبؤ:
القطار = df_sessions.drop (df_sessions.index [-12:]) Future = df_sessions.loc [df_sessions ["ds"]> train.iloc [len (train) -1] ["ds"]] ["ds"]
الآن نقوم بتدريب النموذج ، ونقوم بالتنبؤ ونحسب متوسط الخطأ المطلق. في النهاية ، يمكننا رسم مخطط يوضح الفرق بين القيم الفعلية المتوقعة والقيم الحقيقية. هذا شيء تعلمته من هذا المقال الذي كتبه جيسون براونلي.
من sklearn.metrics استيراد mean_absolute_error
استيراد numpy كـ np
من مصفوفة الاستيراد المعقدة
# نحن ندرب النموذج
النموذج = النبي ()
model.fit (قطار)
# تكييف إطار البيانات المستخدم لأيام التنبؤ بالصيغة النبوية المطلوبة.
المستقبل = قائمة (المستقبل)
المستقبل = DataFrame (المستقبل)
المستقبل = future.rename (الأعمدة = {0: 'ds'})
# نحن نتوقع
التنبؤ = model.predict (المستقبل)
# نحسب MAE بين القيم الفعلية والقيم المتوقعة
y_true = df_sessions ['y'] [- 12:]. قيم
y_pred = توقع قيم ['yhat']
mae = mean_absolute_error (y_true، y_pred)
# نرسم الناتج النهائي لفهم بصري
y_true = np.stack (y_true) .astype (عائم)
pyplot.plot (y_true، label = "فعلي")
pyplot.plot (y_pred، label = "متوقع")
pyplot.legend ()
pyplot.show ()
طباعة (ماي) 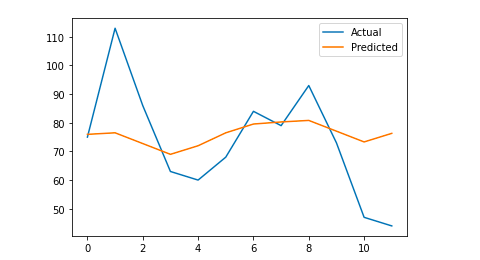
الخطأ المطلق المتوسط لدي هو 13 ، مما يعني أن نموذجي المتوقع يخصص لكل يوم 13 جلسة أكثر من الجلسات الحقيقية ، والذي يبدو أنه خطأ مقبول.
هذا كل ما لدي أيها الناس! آمل أن تكون هذه المقالة مثيرة للاهتمام ويمكنك البدء في عمل تنبؤات تحسين محركات البحث الخاصة بك من أجل تحديد الأهداف.
للمضي قدمًا: مختبرات OnCrawl
إذا كنت قد استمتعت بالتنبؤ بحركة المرور الخاصة بك باستخدام هذه الطريقة ، فستكون مهتمًا أيضًا بمختبرات OnCrawl وعلوم البيانات ومختبر التعلم الآلي في OnCrawl الذي يقدم مشاريع مشفرة مسبقًا لسير عمل تحسين محركات البحث لديك.
في توقع تحسين محركات البحث ، ستساعدك مختبرات OnCrawl على تحسين توقعات تحسين محركات البحث الخاصة بك:
- اكتساب فهم أفضل للنظريات والعملية الكامنة وراء خوارزمية Facebook Prophet
- تحليل شريحة من حركة المرور ، مثل حركة المرور على الكلمات الرئيسية الطويلة فقط ، أو الكلمات الرئيسية ذات العلامات التجارية فقط ...
- اتبع عملية خطوة بخطوة لإعداد الأحداث التاريخية ، وتعديل تأثيرها واحتمال تكررها.