
كيفية استخراج محتوى نصي ذي صلة من صفحة HTML؟
نشرت: 2021-10-13سياق
في قسم البحث والتطوير في Oncrawl ، نتطلع بشكل متزايد إلى إضافة قيمة إلى المحتوى الدلالي لصفحات الويب الخاصة بك. باستخدام نماذج التعلم الآلي لمعالجة اللغة الطبيعية (NLP) ، من الممكن تنفيذ المهام ذات القيمة المضافة الحقيقية لتحسين محركات البحث.
تشمل هذه المهام أنشطة مثل:
- صقل محتوى صفحاتك
- عمل ملخصات تلقائية
- إضافة علامات جديدة لمقالاتك أو تصحيح الموجود منها
- تحسين المحتوى وفقًا لبيانات Google Search Console
- إلخ.
تتمثل الخطوة الأولى في هذه المغامرة في استخراج المحتوى النصي لصفحات الويب التي ستستخدمها نماذج التعلم الآلي هذه. عندما نتحدث عن صفحات الويب ، فإن هذا يتضمن HTML ، و JavaScript ، والقوائم ، والوسائط ، والرأس ، والتذييل ، ... استخراج المحتوى تلقائيًا وبشكل صحيح ليس بالأمر السهل. أقترح من خلال هذا المقال استكشاف المشكلة ومناقشة بعض الأدوات والتوصيات لتحقيق هذه المهمة.
مشكلة
قد يبدو استخراج محتوى نصي من صفحة ويب أمرًا بسيطًا. مع بضعة أسطر من Python ، على سبيل المثال ، زوجان من التعبيرات العادية (regexp) ، ومكتبة تحليل مثل BeautifulSoup4 ، وقد تم ذلك.
إذا تجاهلت لبضع دقائق حقيقة أن المزيد والمزيد من المواقع تستخدم محركات عرض JavaScript مثل Vue.js أو React ، فإن تحليل HTML ليس معقدًا للغاية. إذا كنت ترغب في معالجة هذه المشكلة من خلال الاستفادة من زاحف JS الخاص بنا في عمليات الزحف الخاصة بك ، أقترح عليك قراءة "كيفية الزحف إلى موقع في JavaScript؟".
ومع ذلك ، نريد استخراج نص منطقي ، يكون مفيدًا قدر الإمكان. عندما تقرأ مقالًا عن آخر ألبوم لجون كولتراين بعد وفاته ، على سبيل المثال ، فإنك تتجاهل القوائم والتذييل ... ومن الواضح أنك لا تشاهد محتوى HTML بالكامل. تسمى عناصر HTML هذه التي تظهر في جميع صفحاتك تقريبًا باسم boilerplate. نريد التخلص منه والاحتفاظ بجزء فقط: النص الذي يحمل المعلومات ذات الصلة.
لذلك ، هذا هو النص فقط الذي نريد أن ننقله إلى نماذج التعلم الآلي للمعالجة. لهذا السبب من الضروري أن يكون الاستخراج نوعيًا قدر الإمكان.
حلول
بشكل عام ، نود التخلص من كل شيء "معلق" في النص الرئيسي: القوائم والأشرطة الجانبية الأخرى ، وعناصر الاتصال ، وروابط التذييل ، وما إلى ذلك. هناك عدة طرق للقيام بذلك. نحن مهتمون في الغالب بمشاريع مفتوحة المصدر في Python أو JavaScript.
jusText
jusText هو تطبيق مقترح في Python من أطروحة دكتوراه: "إزالة Boilerplate والمحتوى المكرر من Web Corpora". تسمح هذه الطريقة بتصنيف كتل النص من HTML على أنها "جيدة" ، "سيئة" ، "قصيرة جدًا" وفقًا لاستدلالات مختلفة. تعتمد هذه الاستدلالات في الغالب على عدد الكلمات ، ونسبة النص / الرمز ، ووجود أو عدم وجود روابط ، وما إلى ذلك. يمكنك قراءة المزيد حول الخوارزمية في التوثيق.
ترافيلاتورا
trafilatura ، الذي تم إنشاؤه أيضًا في Python ، يقدم إرشادات حول كل من نوع عنصر HTML ومحتواه ، على سبيل المثال ، طول النص ، موضع / عمق العنصر في HTML ، أو عدد الكلمات. تستخدم trafilatura أيضًا jusText لإجراء بعض المعالجة.
مقروئية
هل سبق لك أن لاحظت الزر في شريط عنوان URL لمتصفح Firefox؟ إنها طريقة عرض القارئ: تسمح لك بإزالة النموذج المعياري من صفحات HTML للاحتفاظ فقط بمحتوى النص الرئيسي. عملي جدًا لاستخدامه في المواقع الإخبارية. تمت كتابة الكود وراء هذه الميزة بلغة JavaScript ويسمى Mozilla قابلية القراءة. يعتمد على العمل الذي بدأه مختبر Arc90.
فيما يلي مثال على كيفية عرض هذه الميزة لمقال من موقع France Musique. 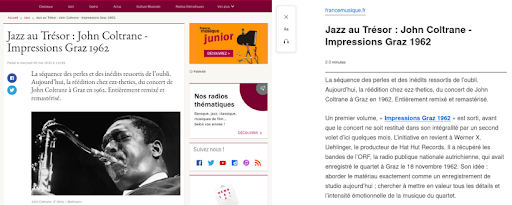
على اليسار ، هو مقتطف من المقال الأصلي. على اليمين ، هو عرض لميزة Reader View في Firefox.
آحرون
قادنا بحثنا حول أدوات استخراج محتوى HTML أيضًا إلى التفكير في أدوات أخرى:
- الصحيفة: مكتبة لاستخراج المحتوى مخصصة إلى حد ما للمواقع الإخبارية (Python). تم استخدام هذه المكتبة لاستخراج المحتوى من مجموعة OpenWebText2.
- boilerpy3 هو منفذ Python لمكتبة boilerpipe.
- مكتبة dragnet Python مستوحاة أيضًا من boilerpipe.
بيانات عند الزحف³
 يتعلم أكثر
يتعلم أكثرالتقييم والتوصيات
قبل تقييم الأدوات المختلفة ومقارنتها ، أردنا معرفة ما إذا كان مجتمع البرمجة اللغوية العصبية يستخدم بعض هذه الأدوات لإعداد مجموعاتهم (مجموعة كبيرة من المستندات). على سبيل المثال ، تحتوي مجموعة البيانات المسماة The Pile المستخدمة لتدريب GPT-Neo على +800 جيجابايت من النصوص الإنجليزية من Wikipedia و Openwebtext2 و Github و CommonCrawl وما إلى ذلك ، مثل BERT ، GPT-Neo هو نموذج لغة يستخدم محولات الكتابة. إنه يوفر تطبيقًا مفتوح المصدر مشابهًا لهندسة GPT-3.

يذكر مقال "The Pile: مجموعة بيانات 800GB للنص المتنوع لنمذجة اللغة" استخدام النص jusText لجزء كبير من مجموعاتهم من CommonCrawl. خططت هذه المجموعة من الباحثين أيضًا لإجراء اختبار معياري لأدوات الاستخراج المختلفة. لسوء الحظ ، لم يتمكنوا من القيام بالعمل المخطط له بسبب نقص الموارد. وتجدر الإشارة في استنتاجاتهم إلى ما يلي:
- يزيل jusText أحيانًا الكثير من المحتوى ولكنه لا يزال يقدم جودة جيدة. نظرًا لكمية البيانات التي لديهم ، لم تكن هذه مشكلة بالنسبة لهم.
- كان trafilatura أفضل في الحفاظ على بنية صفحة HTML ولكنه احتفظ بالكثير من الصيغة المعيارية.
لطريقة التقييم الخاصة بنا ، أخذنا حوالي ثلاثين صفحة ويب. استخرجنا المحتوى الرئيسي "يدويًا". ثم قمنا بمقارنة استخراج النص للأدوات المختلفة بما يسمى المحتوى "المرجعي". استخدمنا درجة ROUGE ، والتي تُستخدم بشكل أساسي لتقييم ملخصات النص التلقائية ، كمقياس.
قمنا أيضًا بمقارنة هذه الأدوات بأداة "محلية الصنع" استنادًا إلى قواعد تحليل HTML. اتضح أن trafilatura و jusText وأداتنا محلية الصنع أفضل من معظم الأدوات الأخرى لهذا المقياس.
فيما يلي جدول بالمتوسطات والانحرافات المعيارية لدرجة ROUGE:
| أدوات | يعني | الأمراض المنقولة جنسيا |
|---|---|---|
| ترافيلاتورا | 0.783 | 0.28 |
| أونكراول | 0.779 | 0.28 |
| jusText | 0.735 | 0.33 |
| المرجل 3 | 0.698 | 0.36 |
| مقروئية | 0.681 | 0.34 |
| شبكة السحب | 0.672 | 0.37 |
في ضوء قيم الانحرافات المعيارية ، لاحظ أن جودة الاستخراج يمكن أن تختلف اختلافًا كبيرًا. الطريقة التي يتم بها تنفيذ HTML ، واتساق العلامات ، والاستخدام المناسب للغة يمكن أن يسبب الكثير من الاختلاف في نتائج الاستخراج.
الأدوات الثلاثة الأفضل أداءً هي trafilatura ، وهي أداة داخلية تسمى "oncrawl" للمناسبة و jusText. نظرًا لاستخدام jusText كخيار احتياطي بواسطة trafilatura ، فقد قررنا استخدام trafilatura كخيارنا الأول. ومع ذلك ، عندما يفشل هذا الأخير ويستخرج الكلمات الصفرية ، فإننا نستخدم قواعدنا الخاصة.
لاحظ أن كود trafilatura يقدم أيضًا معيارًا في عدة مئات من الصفحات. يقوم بحساب درجات الدقة ودرجة f1 والدقة بناءً على وجود أو عدم وجود عناصر معينة في المحتوى المستخرج. تبرز أداتان: trafilatura و goose3. قد ترغب أيضًا في قراءة:
- اختيار الأداة الصحيحة لاستخراج المحتوى من الويب (2020)
- مستودع جيثب: معيار استخراج المقالات: مكتبات مفتوحة المصدر وخدمات تجارية
الاستنتاجات
جودة كود HTML وعدم تجانس نوع الصفحة يجعل من الصعب استخراج محتوى عالي الجودة. كما وجد باحثو EleutherAI - الذين يقفون وراء The Pile و GPT-Neo - ، لا توجد أدوات مثالية. هناك مفاضلة بين المحتوى المبتور في بعض الأحيان والتشويش المتبقي في النص عندما لا تتم إزالة كل النموذج المعياري.
ميزة هذه الأدوات أنها خالية من السياق. هذا يعني أنهم لا يحتاجون إلى أي بيانات بخلاف HTML للصفحة لاستخراج المحتوى. باستخدام نتائج Oncrawl ، يمكننا تخيل طريقة هجينة تستخدم ترددات ظهور كتل HTML معينة في جميع صفحات الموقع لتصنيفها على أنها نموذج معياري.
بالنسبة لمجموعات البيانات المستخدمة في المعايير التي صادفناها على الويب ، فغالبًا ما تكون من نفس نوع الصفحة: المقالات الإخبارية أو منشورات المدونات. لا تشمل بالضرورة مواقع التأمين ووكالات السفر والتجارة الإلكترونية وما إلى ذلك حيث يكون استخراج المحتوى النصي أكثر تعقيدًا في بعض الأحيان.
فيما يتعلق بمعيارنا وبسبب نقص الموارد ، فإننا ندرك أن ثلاثين صفحة أو نحو ذلك ليست كافية للحصول على عرض أكثر تفصيلاً للنتائج. من الناحية المثالية ، نود أن يكون لدينا عدد أكبر من صفحات الويب المختلفة لتحسين قيمنا المعيارية. ونود أيضًا تضمين أدوات أخرى مثل goose3 أو html_text أو inscriptis.