
استخراج البيانات من Google Search Console API لتحليل البيانات في Python
نشرت: 2022-03-01تعد Google Search Console (GSC) بالتأكيد واحدة من أكثر الأدوات فائدة لمتخصصي تحسين محركات البحث ، حيث تتيح لك الحصول على معلومات حول تغطية الفهرس وخاصة الاستعلامات التي تقوم بترتيبها حاليًا. بمعرفة ذلك ، يقوم الكثير من الأشخاص بتحليل بيانات GSC باستخدام جداول البيانات وهو أمر جيد ، طالما أنك تدرك أن هناك مجالًا أكبر للتحسين باستخدام أدوات مثل لغات البرمجة.
لسوء الحظ ، فإن واجهة GSC محدودة جدًا من حيث الصفوف المعروضة (5000 فقط) والفترة الزمنية المتاحة ، 16 شهرًا فقط. من الواضح أن هذا يمكن أن يحد بشدة من قدرتك على الحصول على رؤى وأنه غير مناسب لمواقع الويب الأكبر حجمًا.
تتيح لك Python الحصول على بيانات GSC بسهولة وأتمتة العمليات الحسابية الأكثر تعقيدًا والتي تتطلب المزيد من الجهد في برامج جداول البيانات التقليدية.
هذا هو الحل لواحدة من أكبر المشاكل في Excel ، وهي تحديد الصفوف والسرعة. في الوقت الحاضر ، لديك بدائل أكثر لتحليل البيانات أكثر من ذي قبل ، وهنا يأتي دور Python.
لا تحتاج إلى أي معرفة برمجية متقدمة لمتابعة هذا البرنامج التعليمي ، فقط فهم بعض المفاهيم الأساسية وبعض الممارسات مع Google Colab.
الشروع في استخدام Google Search Console API
قبل أن نبدأ ، من المهم إعداد Google Search Console API. العملية بسيطة للغاية ، كل ما تحتاجه هو حساب Google. والخطوات هي كما يلي:
- أنشئ مشروعًا جديدًا على Google Cloud Platform. يجب أن يكون لديك حساب Google وأنا متأكد تمامًا من أن لديك حسابًا. انتقل إلى وحدة التحكم ثم ستجد خيارًا في الأعلى لإنشاء مشروع جديد.
- انقر فوق القائمة الموجودة على اليسار وحدد "API والخدمات" ، ستنتقل إلى شاشة أخرى.
- من شريط البحث في الجزء العلوي ، ابحث عن "Google Search Console API" وقم بتمكينها.
- ثم انتقل إلى علامة التبويب "بيانات الاعتماد" ، فأنت بحاجة إلى نوع من الإذن لاستخدام واجهة برمجة التطبيقات.
- قم بتكوين شاشة "الموافقة" ، لأن هذا إلزامي. لا يهم الاستخدام الذي سنقوم به سواء كان عامًا أم لا.
- يمكنك اختيار "تطبيق سطح المكتب" لنوع التطبيق
- سنستخدم OAuth 2.0 في هذا البرنامج التعليمي ، يجب عليك تنزيل ملف json والآن انتهيت.
هذا هو في الواقع الجزء الأصعب بالنسبة لمعظم الناس ، خاصةً الذين لم يعتادوا على Google APIs. لا تقلق ، ستكون الخطوات التالية أسهل بكثير وأقل إشكالية.
الحصول على البيانات من Google Search Console API مع Python
توصيتي أن تستخدم دفتر ملاحظات مثل Jupyter Notebook أو Google Colab. هذا الأخير أفضل حيث لا داعي للقلق بشأن المتطلبات. لذلك ، ما سأشرحه يعتمد على Google Colab.
قبل أن نبدأ ، قم بتحديث ملف json الخاص بك إلى Google Colab بالشفرة التالية:
من ملفات استيراد google.colab files.upload ()
بعد ذلك ، دعنا نثبِّت جميع المكتبات التي سنحتاجها لتحليلنا ودعنا نجعل تصورًا أفضل للجدول باستخدام مقتطف الشفرة هذا:
٪٪إلتقاط # تحميل ما هو مطلوب ! pip install git + https: //github.com/joshcarty/google-searchconsole استيراد الباندا كما pd استيراد numpy كـ np استيراد matplotlib.pyplot كـ PLT من google.colab استيراد data_table ! git clone https://github.com/jroakes/querycat.git ! pip install -r querycat / requirements_colab.txt ! pip install umap-learn data_table.enable_dataframe_formatter () # للحصول على تصور أفضل للجدول
أخيرًا ، يمكنك تحميل مكتبة وحدة البحث ، والتي توفر أسهل طريقة للقيام بذلك دون الاعتماد على الوظائف الطويلة. قم بتشغيل الكود التالي باستخدام الوسائط التي أستخدمها وتأكد من أن client_config له نفس اسم ملف json الذي تم تحميله.
استيراد searchconsole account = searchconsole.authenticate (client_config = 'client_secret_.json' ، تسلسل = 'dataentials.json' ، flow = 'console')
ستتم إعادة توجيهك إلى صفحة Google لترخيص التطبيق ، حدد حساب Google الخاص بك ، ثم انسخ والصق الرمز الذي ستحصل عليه في شريط Google Colab.
لم ننتهي بعد ، يجب عليك تحديد العقار الذي ستحتاج إلى بيانات عنه. يمكنك بسهولة التحقق من ممتلكاتك عبر account.webproperties لمعرفة ما يجب عليك اختياره.
property_name = input ('أدخل اسم موقع الويب الخاص بك كما هو مدرج في GSC:')
webproperty = الحساب [str (property_name)]
بمجرد الانتهاء ، ستقوم بتشغيل وظيفة مخصصة لإنشاء كائن يحتوي على بياناتنا.
def extract_gsc_data (موقع الويب ، البدء ، التوقف ، * args):
إذا لم تكن خاصية الويب بلا:
طباعة (f'Extracting data for {webproperty} ')
gsc_data = webproperty.query.range (بدء ، إيقاف) .dimension (* args) .get ()
إرجاع gsc_data
آخر:
طباعة ("موقع الويب غير موجود ، يرجى تحديد الموقع الصحيح")
عودة لا شيء
تتمثل فكرة الوظيفة في أخذ الخاصية التي حددتها من قبل والإطار الزمني ، في شكل تواريخ البدء والانتهاء ، جنبًا إلى جنب مع الأبعاد.
يعد اختيار القدرة على تحديد الأبعاد أمرًا بالغ الأهمية لمتخصصي تحسين محركات البحث لأنه يسمح لك بفهم ما إذا كنت بحاجة إلى مستوى معين من الدقة. على سبيل المثال ، قد لا تكون مهتمًا بالحصول على بُعد التاريخ ، في بعض الحالات.
اقتراحي هو اختيار الاستعلام والصفحة دائمًا ، حيث يمكن لواجهة Google Search Console تصديرهما بشكل منفصل ومن المزعج جدًا دمجهما في كل مرة. هذه ميزة أخرى لواجهة برمجة تطبيقات Search Console.
في حالتنا ، يمكننا أيضًا الحصول على بُعد التاريخ مباشرةً ، لإظهار بعض السيناريوهات المثيرة للاهتمام حيث تحتاج إلى أخذ الوقت في الاعتبار.
مثال = extract_gsc_data (موقع الويب ، '2021-09-01' ، '2021-12-31' ، 'استعلام' ، 'صفحة' ، 'تاريخ')
حدد إطارًا زمنيًا مناسبًا ، مع الأخذ في الاعتبار أنه بالنسبة للعقارات الأكبر ، ستحتاج إلى الانتظار كثيرًا. في هذا المثال ، أفكر فقط في مدى زمني مدته 3 أشهر وهو ما يكفي للحصول على رؤى قيمة من معظم مجموعات البيانات ، في المتوسط.
يمكنك تحديد حتى أسبوع واحد إذا كنت تتعامل مع كمية هائلة من البيانات ، ما يهمنا هو العملية.
ما سأعرضه لكم هنا إما على أساس بيانات تركيبية أو بيانات حقيقية معدلة من أجل أن تكون مناسبة للأمثلة. نتيجة لذلك ، ما تراه هنا واقعي تمامًا ويمكن أن يعكس سيناريوهات العالم الحقيقي.
تنظيف البيانات
بالنسبة لأولئك الذين لا يعرفون ، لا يمكننا استخدام بياناتنا كما هي ، فهناك بعض الخطوات الإضافية للتأكد من أننا نعمل بشكل صحيح. بادئ ذي بدء ، يتعين علينا تحويل كائننا إلى إطار بيانات Pandas ، وهي بنية بيانات يجب أن تكون على دراية بها لأنها أساس تحليل البيانات في Python.
df = pd.DataFrame (بيانات = مثال) df.head ()
يمكن أن تعرض طريقة الرأس الصفوف الخمسة الأولى من مجموعة البيانات الخاصة بك ، ومن السهل جدًا إلقاء نظرة على شكل بياناتك. يمكننا حساب عدد الصفحات التي لدينا باستخدام وظيفة بسيطة.
طريقة جيدة لإزالة التكرارات هي تحويل كائن إلى مجموعة ، لأن المجموعات لا يمكن أن تحتوي على عناصر مكررة.
بعض مقتطفات الشفرة مستوحاة من دفتر ملاحظات هاملت باتيستا وآخر من ماساكي أوكازاوا.
إزالة المصطلحات ذات العلامات التجارية
أول شيء يجب فعله هو إزالة الكلمات الرئيسية ذات العلامات التجارية ، فنحن نبحث عن تلك الاستعلامات التي لا تحتوي على مصطلحات ذات علامة تجارية خاصة بنا. يعد هذا أمرًا بسيطًا جدًا فيما يتعلق بوظيفة مخصصة وسيكون لديك عادةً مجموعة من المصطلحات ذات العلامات التجارية.
لأغراض توضيحية ، لا تحتاج إلى تصفية كل منهم ، ولكن يرجى القيام بذلك لتحليلات حقيقية. إنها إحدى أهم خطوات تنظيف البيانات في تحسين محركات البحث ، وإلا فإنك تخاطر بتقديم نتائج مضللة.
domain_name = str (input ('أدخل مصطلحات العلامة التجارية مفصولة بفاصلة:')). استبدل ('،'، '|')
إعادة الاستيراد
domain_name = re.sub (r "\ s +"، ""، domain_name)
طباعة ("إزالة كافة المسافات باستخدام RegEx: \ n")
df ['علامة تجارية / بدون علامة تجارية'] = np.where (
df ['query']. str.contains (domain_name) ، 'Brand' ، 'Non-branded'
)
سنقوم بإضافة عمود جديد إلى مجموعة البيانات الخاصة بنا للتعرف على الفرق بين الفئتين. يمكننا أن نتخيل من خلال الجداول أو المخططات الشريطية مقدار ما تمثله من إجمالي عدد الاستفسارات.
لن أريكم barplot لأنه بسيط للغاية وأعتقد أن الجدول أفضل لهذه الحالة.
brand_count_df = df ['Brand / Non-branded']. value_counts (). rename_axis ('cats'). to_frame ('counts')
brand_count_df ['النسبة المئوية'] = brand_count_df ['counts'] / sum (brand_count_df ['counts'])
pd.options.display.float_format = '{: .2٪}' تنسيق
brand_count_df
يمكنك أن ترى بسرعة النسبة بين الكلمات الرئيسية الخاصة بالعلامة التجارية والكلمات الرئيسية غير المتعلقة بعلامة تجارية للحصول على فكرة عن المبلغ الذي ستزيله من مجموعة البيانات الخاصة بك. لا توجد نسبة مثالية هنا ، على الرغم من أنك تريد بالتأكيد الحصول على نسبة مئوية أعلى من الكلمات الرئيسية غير المتعلقة بعلامة تجارية.
بعد ذلك ، يمكننا فقط إسقاط جميع الصفوف المميزة بعلامة تجارية والمضي قدمًا في الخطوات الأخرى.
# فقط حدد الكلمات الرئيسية غير المتعلقة بعلامة تجارية df = df.loc [df ['علامة تجارية / غير ذات علامة تجارية'] == "بدون علامة تجارية"]
ملء القيم المفقودة والخطوات الأخرى
إذا كانت مجموعة البيانات الخاصة بك تحتوي على قيم مفقودة (أو NAs في المصطلحات) ، فلديك عدة خيارات. الأكثر شيوعًا هو إما إفلاتهم جميعًا أو تعبئتهم بقيمة عنصر نائب مثل 0 أو متوسط هذا العمود.
لا توجد إجابة صحيحة وكلا النهجين لهما إيجابيات وسلبيات ، بالإضافة إلى المخاطر. بالنسبة إلى بيانات Google Search Console ، فإن أفضل نصيحتي هو وضع قيمة عنصر نائب مثل 0 ، للتقليل من تأثير بعض المقاييس.
df.fillna (0، inplace = صحيح)
قبل أن ننتقل إلى تحليل البيانات الفعلي ، نحتاج إلى تعديل ميزاتنا ، أي أعمدة مجموعة البيانات الخاصة بنا. الموضع مهم بشكل خاص ، حيث نريد استخدامه لبعض الجداول المحورية الرائعة.
يمكننا تقريب الموضع ليكون عددًا صحيحًا ، وهذا يخدم غرضنا.
df ['position'] = df ['position']. round (0) .astype ('int64')
يجب عليك اتباع جميع خطوات التنظيف الأخرى الموضحة أعلاه ثم ضبط عمود التاريخ.
نحن نستخرج شهورًا وسنوات بمساعدة الباندا. لست بحاجة إلى أن تكون بهذا التحديد إذا كنت تعمل ضمن إطار زمني أقصر ، فهذا مثال يأخذ في الحسبان نصف عام.
#convert التاريخ إلى التنسيق الصحيح df ['date'] = pd.to_datetime (df ['date']) #extract الشهور df ['month'] = df ['date']. dt.month #extract سنوات df ['year'] = df ['date']. dt.year
[كتاب إلكتروني] تحسين محركات البحث للبيانات: المغامرة الكبرى التالية
 اقرأ الكتاب الإلكتروني
اقرأ الكتاب الإلكترونيتحليل البيانات استكشافية
الميزة الرئيسية في Python هي أنه يمكنك القيام بنفس الأشياء التي تقوم بها في Excel ولكن مع العديد من الخيارات والأسهل. لنبدأ بشيء يعرفه كل محلل جيدًا: الجداول المحورية.
تحليل متوسط نسبة النقر إلى الظهور لكل مجموعة موضع
تحليل متوسط تعد نسبة النقر إلى الظهور لكل موضع من أكثر الأنشطة ثاقبة لأنها تتيح لك فهم الموقف العام لموقع الويب. قم بتطبيق المحور ثم دعنا نرسمه.
pd.options.display.float_format = '{: .2٪}' تنسيق
query_analysis = df.pivot_table (الفهرس = ['position'] ، القيم = ['ctr'] ، aggfunc = ['mean'])
query_analysis.sort_values (بواسطة = ['position'] ، تصاعدي = True) .head (10)
ax = query_analysis.head (10) .plot (النوع = 'شريط')
ax.set_xlabel ("متوسط الموضع")
ax.set_ylabel ("نسبة النقر إلى الظهور")
ax.set_title ("نسبة النقر إلى الظهور حسب متوسط الموضع")
ax.grid ('on')
ax.get_legend (). remove ()
plt.xticks (دوران = 0)
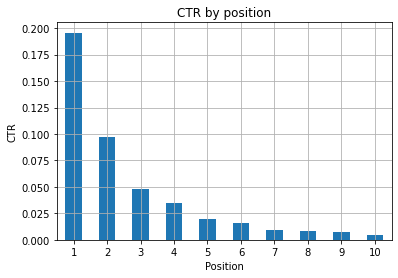
الشكل 1: تمثيل نسبة النقر إلى الظهور حسب الموضع لاكتشاف الحالات الشاذة.
السيناريو المثالي هنا هو الحصول على نسبة نقر إلى ظهور أفضل على الجانب الأيسر من الرسم البياني ، حيث يجب أن تظهر النتائج في الموضع 1 عادةً نسبة نقر إلى ظهور أعلى بكثير. كن حذرًا ، فقد ترى بعض الحالات حيث تكون نسبة النقر إلى الظهور في أول 3 نقاط أقل من المتوقع ، وعليك التحقيق.
من فضلك ، ضع في اعتبارك حالات الحافة أيضًا ، على سبيل المثال تلك التي يكون فيها الموضع 11 أفضل من المركز الأول. كما هو موضح في وثائق Google الخاصة بـ Search Console ، فإن هذا المقياس لا يتبع الترتيب الذي قد تعتقده في البداية.
علاوة على ذلك ، يضيف أن هذا المقياس متوسط ، حيث يتغير موضع الارتباط في كل مرة ومن المستحيل الحصول على دقة بنسبة 100٪.
أحيانًا تحتل صفحاتك مرتبة عالية ولكنها غير مقنعة بدرجة كافية ، لذا يمكنك محاولة إصلاح العنوان. نظرًا لأن هذه نظرة عامة عالية المستوى ، فلن ترى اختلافات دقيقة ، لذلك توقع أن تتصرف بسرعة إذا كانت هذه المشكلة على نطاق واسع.
كن على علم أيضًا عندما يكون لدى مجموعة من الصفحات في مواضع أدنى متوسط نسبة نقر إلى ظهور أعلى من تلك الموجودة في مواضع أفضل.
لهذا السبب ، قد ترغب في تمديد تحليلك إلى الموضع 15 أو أكثر ، لاكتشاف الأنماط الغريبة.
عدد الاستعلام لكل موقع وقياس جهود تحسين محركات البحث
دائمًا ما تكون الزيادة في طلبات البحث التي تُرتب من أجلها إشارة جيدة ، إلا أنها لا تعني بالضرورة ترتيبًا أفضل في المستقبل. عدد الاستعلامات هو عملية حساب عدد الاستعلامات التي تقوم بترتيبها وهي واحدة من أهم المهام التي يمكنك القيام بها باستخدام بيانات GSC.
تعد الجداول المحورية مساعدة كبيرة مرة أخرى ، ويمكننا رسم النتائج.
Rank_queries = df.pivot_table (index = ['position'] ، القيم = ['query'] ، aggfunc = ['count']) Rank_queries.sort_values (بواسطة = ['position']). head (10)
ما تريده بصفتك متخصصًا في تحسين محركات البحث (SEO) هو أن يكون لديك عدد استعلام أعلى في أقصى الجانب الأيسر ، أي المراكز العليا. السبب طبيعي تمامًا ، حيث تحصل المراكز العليا على نسبة نقر إلى ظهور أفضل في المتوسط ، وهو ما يمكن أن يترجم إلى نقر المزيد من الأشخاص على صفحتك.
ax = rating_queries.head (10) .plot (النوع = 'bar')
ax.set_ylabel ("عدد الاستعلامات")
ax.set_xlabel ("الموضع")
ax.set_title ("توزيع الترتيب")
ax.grid ('on')
ax.get_legend (). remove ()
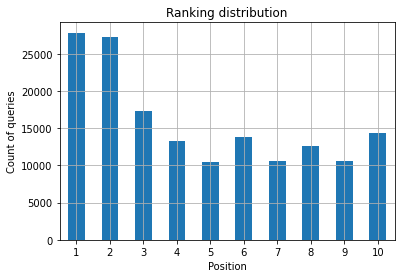
الشكل 2: كم عدد الاستفسارات التي لدي حسب الموقع؟
ما يهمك هو زيادة عدد طلبات البحث في المواضع العليا مع مرور الوقت.
اللعب مع البعد التاريخ
دعونا نرى كيف تتباين النقرات في فترة زمنية معينة ، دعنا نحصل على مجموع النقرات أولاً:
click_sum = df.groupby ('التاريخ') ['النقرات']. sum ()
نقوم بتجميع البيانات حسب بُعد التاريخ ونحصل على مجموع النقرات لكل منها ، إنه نوع من التلخيص.

نحن الآن جاهزون لرسم ما حصلنا عليه ، ستكون الشفرة طويلة جدًا فقط لتحسين التصور ، لا تخف من ذلك.
# مجموع النقرات عبر الفترة
٪ config InlineBackend.figure_format = "شبكية العين"
من الشكل استيراد matplotlib.pyplot
الشكل (حجم الشكل = (8 ، 6) ، نقطة في البوصة = 80)
الفأس = click_sum.plot (اللون = "أحمر")
ax.grid ('on')
ax.set_ylabel ("مجموع النقرات")
ax.set_xlabel ("شهر")
ax.set_title ("كيف تتنوع النقرات على أساس شهري")
xlab = ax.xaxis.get_label ()
ylab = ax.yaxis.get_label ()
xlab.set_style ("مائل")
xlab.set_size (10)
ylab.set_style ("مائل")
ylab.set_size (10)
ttl = ax.title
ttl.set_weight ("غامق")
ax.spines ['right']. set_color ((. 8، .8، .8))
ax.spines ['top']. set_color ((. 8، .8، .8))
ax.yaxis.set_label_coords (- .15، .50)
ax.fill_between (click_sum.index، click_sum.values، facecolor = 'yellow')
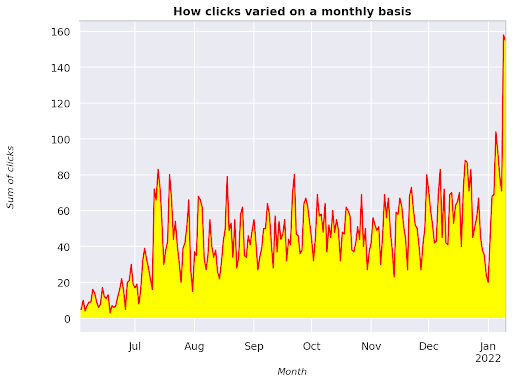
الشكل 3: رسم مجموع النقرات فيما يتعلق بمتغير الشهر
هذا مثال يبدأ من يونيو 2021 وينتقل مباشرة إلى نصف يناير 2022. جميع الأسطر التي تراها أعلاه لها دور في جعل هذا التصور أجمل ، يمكنك محاولة اللعب به لترى ما سيحدث.
عدد الاستعلام لكل موقف ، لقطة شهرية
التصور الرائع الآخر الذي يمكننا رسمه في Python هو خريطة الحرارة ، والتي تعد مرئية أكثر من مجرد barplot. سأوضح لك كيفية عرض عدد الاستعلام بمرور الوقت ووفقًا لموقعه.
استيراد seaborn as sns sns.set_theme () df_new = df.loc [(df ['position'] <= 10) & (df ['year']! = 2022) ،:] # قم بتحميل نموذج مجموعة بيانات الرحلات الجوية وقم بالتحويل إلى نموذج طويل df_heat = df_new.pivot_table (index = "position" ، الأعمدة = "month" ، القيم = "query" ، aggfunc = 'count') # ارسم خريطة حرارية بالقيم الرقمية في كل خلية f ، ax = plt.subplots (حجم الشكل = (20 ، 12)) x_axis_labels = ["سبتمبر" ، "أكتوبر" ، "نوفمبر" ، "ديسمبر"] sns.heatmap (df_heat، annot = True، linewidths = .5، ax = ax، fmt = 'g'، cmap = sns.cm.rocket_r، xticklabels = x_axis_labels) ax.set (xlabel = 'شهر'، ylabel = 'Position'، title = 'كيف يتغير عدد الاستعلام لكل موضع بمرور الوقت') #rotate تسميات الموضع لجعلها أكثر قابلية للقراءة plt.yticks (دوران = 0)
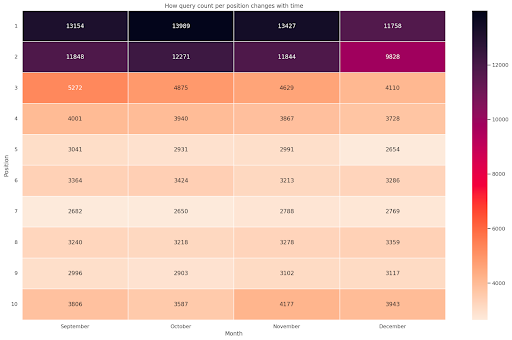
الشكل 4: خريطة التمثيل اللوني توضح التقدم المحرز في عدد الاستعلام وفقًا للموضع والشهر.
هذه واحدة من المفضلة لدي ، يمكن أن تكون خرائط الحرارة فعالة جدًا لعرض الجداول المحورية ، كما في هذا المثال. تمتد الفترة على مدى 4 أشهر ، وإذا قرأتها أفقيًا ، يمكنك أن ترى كيف يتغير عدد الاستعلام مع مرور الوقت. بالنسبة إلى الموضع 10 ، ستحصل على زيادة طفيفة من سبتمبر إلى ديسمبر ، ولكن بالنسبة إلى الموضع 2 لديك انخفاض مذهل ، كما يتضح من اللون الأرجواني.
في السيناريو التالي لديك غالبية الاستعلامات في المواقع العليا والتي قد تكون غير عادية بشكل لافت للنظر. إذا حدث ذلك ، فقد ترغب في العودة وتحليل إطار البيانات ، والبحث عن مصطلحات ذات علامة تجارية محتملة ، إن وجدت.
كما ترى من الكود ، ليس من الصعب إنشاء حبكات معقدة ، طالما أنك تدعم المنطق.
يجب أن يزيد عدد طلبات البحث بمرور الوقت إذا كنت تقوم بالأشياء "الصحيحة" ويمكننا رسم الفرق عبر إطارين زمنيين مختلفين. في المثال الذي قدمته ، من الواضح أن الأمر ليس كذلك ، خاصة بالنسبة للمواضع العليا ، حيث من المفترض أن يكون لديك نسبة نقر إلى ظهور أعلى.
تقديم بعض المفاهيم الأساسية في البرمجة اللغوية العصبية
تعد معالجة اللغة الطبيعية (NLP) بمثابة هبة من السماء لكبار المسئولين الاقتصاديين ولا تحتاج إلى أن تكون خبيرًا لتطبيق الخوارزميات الأساسية. تعد N-grams واحدة من أقوى الأفكار ولكنها بسيطة والتي يمكن أن تمنحك رؤى باستخدام بيانات GSC.
N-grams هي سلاسل متجاورة من الحروف أو المقاطع أو الكلمات. بالنسبة لتحليلنا ، ستكون كلماتنا هي وحدة القياس. يُطلق على n-gram اسم bigram عندما تكون العناصر المتجاورة اثنان (زوج) و trigram إذا كانتا ثلاثة ، وهكذا. أقترح عليك أن تختبر بتركيبات مختلفة وأن تزيد حتى 5 جرامات على الأكثر.
بهذه الطريقة ، يمكنك تحديد الجمل الأكثر شيوعًا في صفحات منافسيك أو تقييم الجمل الخاصة بك. نظرًا لأن Google قد تعتمد على الفهرسة القائمة على العبارات ، فمن الأفضل تحسين الجمل بدلاً من الكلمات الرئيسية الفردية ، كما هو موضح في براءات اختراع Google المتعلقة بهذا الموضوع.
كما هو مذكور في الصفحة أعلاه بواسطة Bill Slawski نفسه ، فإن قيمة فهم المصطلحات ذات الصلة لها قيمة كبيرة في التحسين وللمستخدمين.
مكتبة nltk مشهورة جدًا بتطبيقات البرمجة اللغوية العصبية وتمنحنا إمكانية إزالة كلمات التوقف في لغة معينة ، مثل اللغة الإنجليزية. اعتبرها بمثابة ضوضاء تريد إزالتها ، في الواقع ، لا تضيف المقالات والكلمات المتكررة أي قيمة في فهم النص.
استيراد nltk
nltk.download ("Stopwords")
من كلمات إيقاف استيراد nltk.corpus
stoplist = stopwords.words ("الإنجليزية")
من sklearn.feature_extraction.text استيراد CountVectorizer
c_vec = CountVectorizer (stop_words = stoplist، ngram_range = (2،3))
# مصفوفة ngrams
ngrams = c_vec.fit_transform (df ['استعلام'])
# عدد مرات تكرار ngrams
count_values = ngrams.toarray (). sum (محور = 0)
# قائمة ngrams
المفردات = c_vec.vocabulary_
df_ngram = pd.DataFrame (تم الفرز ([(count_values [i]، k) لـ k ، i في vocab.items ()] ، reverse = True)
) .rename (الأعمدة = {0: 'frequency'، 1: 'bigram / trigram'})
df_ngram.head (20) .style.background_gradient ()
نحن نأخذ عمود الاستعلام ونحسب عدد مرات تكرار bi-grams لإنشاء إطار بيانات يخزن bi-grams وعدد مرات حدوثها.
هذه الخطوة مهمة جدًا في الواقع لتحليل مواقع المنافسين أيضًا. يمكنك فقط كشط النص الخاص بهم والتحقق من أكثر n-grams شيوعًا ، من خلال ضبط n في كل مرة لمعرفة ما إذا كنت قد لاحظت أنماطًا مختلفة عبر الصفحات عالية الترتيب.
إذا فكرت في ذلك لثانية ، سيكون الأمر أكثر منطقية ، لأن الكلمة الأساسية الفردية لا تخبرك بأي شيء عن السياق.
ثمار معلقة منخفضة
من أجمل الأشياء التي يجب القيام بها هو فحص الثمار المنخفضة ، تلك الصفحات التي يمكنك تحسينها بسهولة لرؤية نتائج جيدة في أقرب وقت ممكن. هذا أمر بالغ الأهمية في الخطوات الأولى لكل مشروع لتحسين محركات البحث لإقناع أصحاب المصلحة. لذلك ، إذا كانت هناك فرصة للاستفادة من مثل هذه الصفحات ، فافعل ذلك!
معاييرنا للنظر في الصفحة على هذا النحو هي الكميات لمرات الظهور ونسبة النقر إلى الظهور. بعبارة أخرى ، نقوم بتصفية الصفوف التي تقع في أعلى 80٪ من مرات الظهور ولكنها ضمن 20٪ التي تتلقى أدنى نسبة نقر إلى ظهور. ستحصل هذه الصفوف على نسبة نقر إلى ظهور أسوأ من 80٪ من الباقي.
top_impressions = df [df ['مرات الظهور']> = df ['مرات الظهور']. الكمية (0.8)]
(top_impressions ['ctr'] <= top_impressions ['ctr']. quantile (0.2)]. sort_values ('مرات الظهور' ، تصاعدي = خطأ))
الآن لديك قائمة بجميع الفرص مرتبة حسب مرات الظهور بترتيب تنازلي.
يمكنك التفكير في معايير أخرى لتحديد ما هي الفاكهة المتدلية ، وفقًا لاحتياجات موقع الويب الخاص بك وحجمه.
بالنسبة إلى مواقع الويب الأصغر ، قد تفكر في البحث عن نسب أعلى ، بينما في مواقع الويب الكبيرة ، يجب أن تحصل بالفعل على الكثير من المعلومات بالمعايير التي أستخدمها.
[كتاب إلكتروني] تحسين محركات البحث الفنية للمفكرين غير التقنيين
 اقرأ الكتاب الإلكتروني
اقرأ الكتاب الإلكترونيإدخال استعلام: التصنيف والجمعيات
Querycat هي مكتبة بسيطة لكنها قوية تتميز باستخراج قواعد الجمعيات لتجميع الكلمات الرئيسية وأكثر من ذلك بكثير. سأريكم فقط الارتباطات لأنها أكثر قيمة في هذا النوع من التحليل.
يمكنك معرفة المزيد حول هذه المكتبة الرائعة من خلال إلقاء نظرة على مستودع Querycat GitHub.
مقدمة قصيرة عن تعلم قواعد الجمعيات
تعلم قواعد الرابطة هو طريقة للعثور على القواعد التي تحدد الارتباطات والتواجد المشترك عبر مجموعات من العناصر. هذا يختلف قليلاً عن طريقة التعلم الآلي الأخرى غير الخاضعة للرقابة ، والتي تسمى التجميع.
الهدف النهائي هو نفسه ، مع ذلك ، الحصول على مجموعات من الكلمات الرئيسية لفهم كيفية عمل موقعنا على الإنترنت لبعض الموضوعات.
يمنحك Querycat إمكانية الاختيار بين خوارزميتين: Apriori و FP-Growth. سنختار الأخير للحصول على أداء أفضل ، لذا يمكنك تجاهل الأول.
FP-Growth هو نسخة محسنة من Apriori للعثور على أنماط متكررة في مجموعات البيانات. يعد تعلم قواعد الجمعيات مفيدًا جدًا لمعاملات التجارة الإلكترونية أيضًا ، فقد تكون مهتمًا بفهم ما يشتريه الأشخاص معًا ، على سبيل المثال.
في هذه الحالة ، ينصب تركيزنا بالكامل على الاستعلامات ، ولكن التطبيق الآخر الذي ذكرته يمكن أن يكون فكرة أخرى مفيدة لبيانات Google Analytics.
يعد شرح هذه الخوارزميات من منظور بنية البيانات أمرًا صعبًا للغاية وفي رأيي ليس ضروريًا لمهام تحسين محركات البحث الخاصة بك. سأشرح فقط بعض المفاهيم الأساسية لفهم ما تعنيه المعلمات.
العناصر الثلاثة الرئيسية للخوارزميتين هي:
- الدعم - يعبر عن شعبية عنصر أو مجموعة عناصر. بكلمات تقنية ، هو عدد المعاملات التي يظهر فيها الاستعلام X والاستعلام Y معًا مقسومًا على العدد الإجمالي للمعاملات.
علاوة على ذلك ، يمكن استخدامه كعتبة لإزالة العناصر النادرة. مفيد جدا لزيادة الدلالة الإحصائية والأداء. تعيين حد أدنى جيد من الدعم جيد جدًا. - الثقة - يمكنك التفكير في الأمر على أنه احتمال التواجد المشترك للمصطلحات.
- الرفع - النسبة بين دعم (المصطلح 1 والمصطلح 2) ودعم المصطلح 1. يمكننا النظر إلى قيمتها للحصول على نظرة ثاقبة للعلاقة بين المصطلحات. إذا كان أكبر من 1 المصطلحات مترابطة ؛ إذا كان المصطلح أقل من 1 من غير المحتمل أن يكون له ارتباط: إذا كان المصعد 1 بالضبط (أو قريبًا) فلا توجد علاقة مهمة.
يتم توفير مزيد من التفاصيل في هذه المقالة حول الاستعلام الذي كتبه مؤلف المكتبة.
الآن نحن على استعداد للانتقال إلى الجزء العملي.
استيراد الاستعلام
query_cat = querycat.Categorize (df، 'query'، min_support = 10، alg = 'fpgrowth')
dfgrouped = df.groupby ('category'). agg (sumclicks = ('click'، 'sum')). sort_values ('sumclicks' ، تصاعدي = خطأ)
# إنشاء مجموعة لتصفية الفئات بأقل من 15 نقرة (رقم عشوائي)
filtergroup = dfgrouped [dfgrouped ['sumclicks']> 15]
مجموعة التصفية
# تطبيق عامل التصفية
df = df.merge (filtergroup، on = ['category'، 'category'] ، كيف = 'الداخلية')
لقد قمنا بتصفية الفئات الأقل تكرارًا في هذه العملية ، واخترت 15 كمعيار في حالتي. إنه مجرد رقم عشوائي ، ولا يوجد معيار وراءه.
دعنا نتحقق من فئاتنا بالمقتطف التالي:
df ['category']. value_counts ()
ماذا عن الفئات العشر الأكثر نقرًا؟ دعنا نتحقق من عدد الاستعلامات التي لدينا لكل منها.
df.groupby ('الفئة'). sum () ['النقرات']. sort_values (تصاعدي = خطأ) .head (10)
الرقم الذي تريد اختياره عشوائي ، تأكد من اختيار رقم يقوم بتصفية نسبة جيدة من المجموعات. تتمثل إحدى الأفكار المحتملة في الحصول على متوسط مرات الظهور وإسقاط أقل 50٪ ، بشرط أنك تريد استبعاد مجموعات صغيرة.
الحصول على الكتل وماذا تفعل مع الإخراج
توصيتي بتصدير إطار البيانات الجديد الخاص بك لتجنب تشغيل FP-Growth مرة أخرى ، يرجى القيام بذلك لتوفير الوقت المفيد.
بمجرد أن يكون لديك مجموعات تريد معرفة النقرات ومرات الظهور لكل منها من أجل تقييم المناطق التي تحتاج إلى معظم التحسينات.
grouped_df = df.groupby ('category') [['النقرات'، 'مرات الظهور']]. agg ('sum')
من خلال بعض التلاعب بالبيانات ، يمكننا تحسين نتائج الارتباط والحصول على نقرات ومرات ظهور لكل مجموعة.
group_ex = df.groupby (['category']) ['استعلام']. تطبيق ('|'. انضم) .reset_index ()
# إزالة الاستعلامات المكررة ثم فرزها أبجديًا
group_ex ['query'] = group_ex ['query']. تطبيق (lambda x: '|' .join (تم الفرز (list (set (x.split ('|'))))))
df_final = group_ex.merge (grouped_df، on = ['category'، 'category'] ، كيف = 'الداخلية')
df_final.head ()
لديك الآن ملف CSV مع كل مجموعات الكلمات الرئيسية إلى جانب النقرات ومرات الظهور.
# حفظ ملف csv وتنزيله على جهازك المحلي. إذا كنت تستخدم Safari ، فالرجاء التفكير في التبديل إلى Chrome لتنزيل هذه الملفات لأنها قد لا تعمل.
df_final.to_csv ("clusters_queries.csv")
files.download ("clusters_queries.csv")
في الواقع ، هناك طرق أفضل للتجميع ، وهذا مجرد مثال على كيفية استخدام الاستعلام لأداء مهام متعددة للاستخدام الفوري. الهدف الرئيسي هنا هو الحصول على أكبر عدد ممكن من الأفكار ، خاصة للمواقع الجديدة التي لا تمتلك فيها الكثير من المعرفة.
في الوقت الحالي ، تشتمل أفضل الأساليب على الدلالات ، لذلك إذا كنت تريد التركيز على التجميع ، أقترح عليك التفكير في تعلم الرسوم البيانية أو حفلات الزفاف.
ومع ذلك ، فهذه موضوعات متقدمة إذا كنت مبتدئًا ويمكنك ببساطة تجربة بعض تطبيقات Streamlit المبنية مسبقًا والمتاحة عبر الإنترنت.
بيانات عند الزحف³
 يتعلم أكثر
يتعلم أكثرالخلاصة وماذا بعد
يمكن أن تقدم Python مساعدة كبيرة في تحليل موقع الويب الخاص بك ويمكن أن تساعدك في الجمع بين تنظيف البيانات والتصور والتحليل في مكان واحد. من المؤكد أن استخراج البيانات من GSC API مطلوب للقيام بمهام أكثر تقدمًا وهو مقدمة "لطيفة" لأتمتة البيانات.
بينما يمكنك إجراء الكثير من العمليات الحسابية المتقدمة باستخدام Python ، فإن توصيتي هي التحقق مما هو منطقي من حيث قيمة تحسين محركات البحث.
على سبيل المثال ، يعد عدد الاستعلامات أكثر أهمية ككل على المدى الطويل ، حيث تريد أن يتم النظر في موقع الويب الخاص بك لمزيد من الاستفسارات.
يعد استخدام أجهزة الكمبيوتر المحمولة مساعدة كبيرة في تعبئة التعليمات البرمجية بالتعليقات وهذا هو السبب الرئيسي الذي يجعلني أقترح عليك التعود على Google Colab.
هذه مجرد بداية لما يمكن أن يقدمه تحليل البيانات لك ، حيث تأتي أفضل الأفكار من دمج مجموعات البيانات المختلفة.
تعد Google Search Console في حد ذاتها أداة قوية وهي مجانية تمامًا ، وكمية المعلومات العملية التي يمكنك الحصول عليها منها تكاد تكون غير محدودة في أيد أمينة.