
أ / ب اختبار الأهمية الإحصائية: كيف ومتى يتم إنهاء الاختبار
نشرت: 2020-05-22
في تحليلنا الأخير لـ 28304 تجربة يديرها عملاء التحويل ، وجدنا أن 20٪ فقط من التجارب تصل إلى مستوى الأهمية الإحصائية 95٪. اكتشفت Econsultancy اتجاهًا مشابهًا في تقرير التحسين لعام 2018. يرى ثلثا المستجيبين "فائزًا واضحًا وذو دلالة إحصائية" في 30٪ فقط أو أقل من تجاربهم.
لذا فإن معظم التجارب (70-80٪) إما غير حاسمة أو توقفت مبكرًا.
من بين هؤلاء ، توقف الأشخاص مبكرًا عن تقديم حالة غريبة حيث يأخذ المحسنون الدعوة لإنهاء التجارب عندما يرون ذلك مناسبًا. يفعلون ذلك عندما يستطيعون إما "رؤية" فائزًا واضحًا (أو خاسرًا) أو اختبارًا غير مهم بشكل واضح. عادة ، لديهم أيضًا بعض البيانات لتبرير ذلك.
قد لا يكون هذا مفاجئًا للغاية ، نظرًا لأن 50٪ من المحسِنين ليس لديهم "نقطة توقف" قياسية لتجاربهم. بالنسبة لمعظم الناس ، يعد القيام بذلك أمرًا ضروريًا ، وذلك بفضل الضغط الناتج عن الاضطرار إلى الحفاظ على سرعة اختبار معينة (XXX اختبارًا / شهرًا) والسباق للسيطرة على منافسيهم.
ثم هناك أيضًا احتمال أن تؤدي تجربة سلبية إلى الإضرار بالأرباح. أظهر بحثنا أن التجارب غير الفائزة ، في المتوسط ، يمكن أن تسبب انخفاضًا بنسبة 26٪ في معدل التحويل !
بعد كل ما قيل ، فإن إنهاء التجارب مبكرًا لا يزال محفوفًا بالمخاطر ...
... لأنه يترك الاحتمال الذي لو نفذت التجربة طوله المقصود ، مدعومًا بحجم العينة الصحيح ، فقد تكون نتيجتها مختلفة.
إذن كيف تعرف الفرق التي تنهي التجارب مبكرًا متى حان الوقت لإنهائها؟ بالنسبة لمعظم الناس ، تكمن الإجابة في وضع قواعد توقف تسرع عملية اتخاذ القرار ، دون المساومة على جودتها.
الابتعاد عن قواعد التوقف التقليدية
بالنسبة لتجارب الويب ، تعمل القيمة p البالغة 0.05 كمعيار. يساعد تحمل الخطأ بنسبة 5 في المائة أو مستوى الأهمية الإحصائية بنسبة 95 في المائة المحسّنين في الحفاظ على تكامل اختباراتهم. يمكنهم التأكد من أن النتائج هي نتائج فعلية وليست حظ.
في النماذج الإحصائية التقليدية لاختبار الأفق الثابت - حيث يتم تقييم بيانات الاختبار مرة واحدة فقط في وقت محدد أو في عدد محدد من المستخدمين المتفاعلين - ستقبل نتيجة مهمة عندما يكون لديك قيمة p أقل من 0.05. في هذه المرحلة ، يمكنك رفض فرضية العدم القائلة بأن تحكمك وعلاجك متماثلان وأن النتائج المرصودة ليست مصادفة.
على عكس النماذج الإحصائية التي تمنحك شرطًا لتقييم بياناتك أثناء جمعها ، تمنعك نماذج الاختبار هذه من النظر إلى بيانات تجربتك أثناء تشغيلها. يتم تثبيط هذه الممارسة - المعروفة أيضًا باسم النظرة الخاطفة - في مثل هذه النماذج لأن القيمة الاحتمالية تتقلب على أساس يومي تقريبًا. ستلاحظ أن التجربة ستكون مهمة يومًا ما وفي اليوم التالي ، سترتفع قيمتها الاحتمالية إلى درجة لم تعد مهمة فيها.
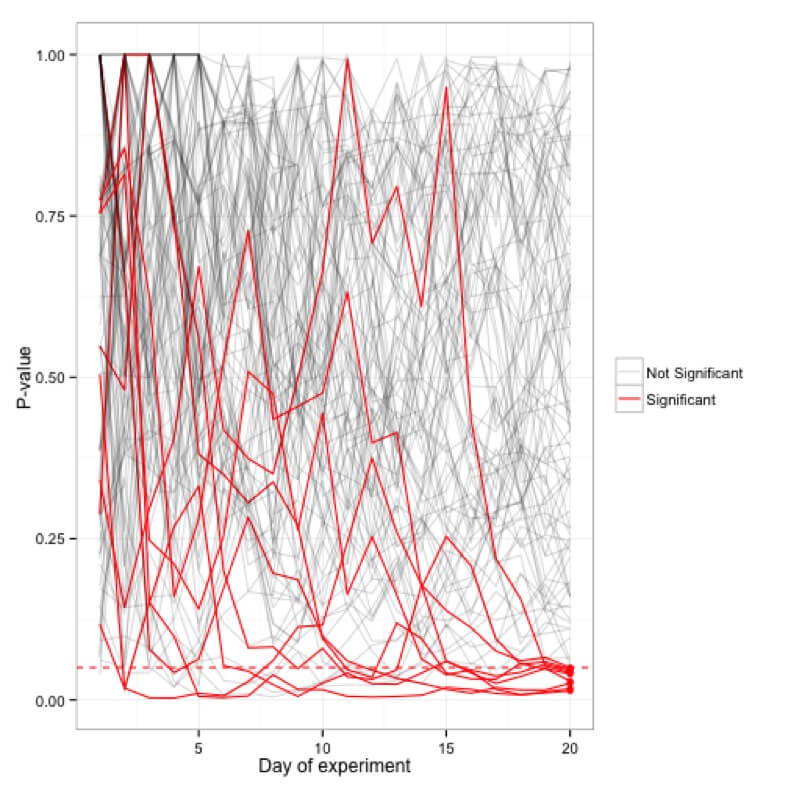
محاكاة قيم p المخططة لمائة (20 يومًا) تجربة ؛ فقط 5 تجارب فقط في نهاية المطاف تكون مهمة في علامة 20 يومًا بينما يصل الكثير من حين لآخر إلى <0.05 قطع في هذه الأثناء.
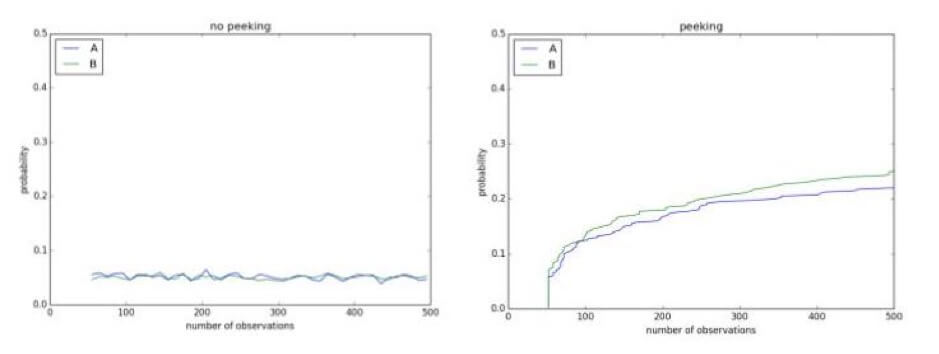
يمكن أن يؤدي إلقاء نظرة خاطفة على تجاربك في غضون ذلك إلى إظهار نتائج غير موجودة. على سبيل المثال ، يوجد أدناه اختبار A / A باستخدام مستوى أهمية 0.1. نظرًا لأنه اختبار A / A ، فلا فرق بين التحكم والعلاج. ومع ذلك ، بعد 500 ملاحظة أثناء التجربة الجارية ، هناك فرصة تزيد عن 50٪ لاستنتاج أنهما مختلفان وأنه يمكن رفض فرضية العدم:
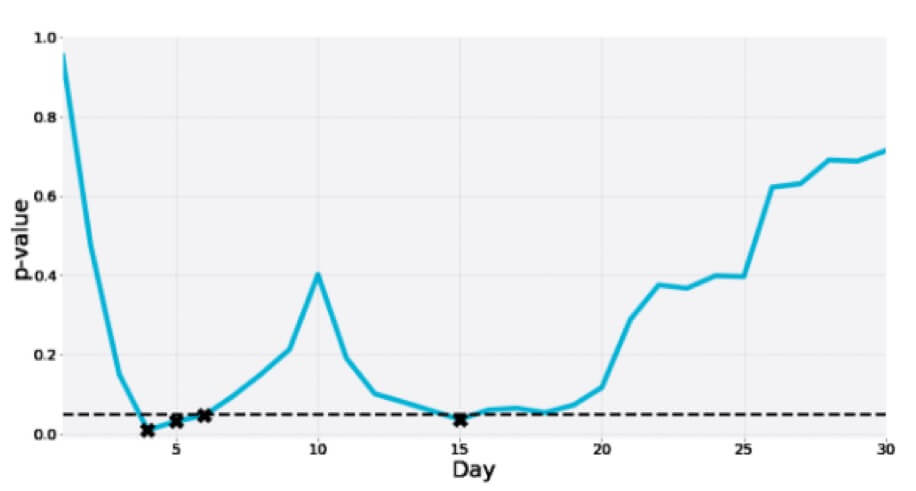
في ما يلي اختبار آخر من اختبار A / A لمدة 30 يومًا حيث تنخفض قيمة p إلى منطقة الأهمية عدة مرات في غضون ذلك فقط لتصبح أخيرًا أكثر بكثير من نقطة القطع:
الإبلاغ عن قيمة p بشكل صحيح من تجربة ذات أفق ثابت يعني أنك بحاجة إلى الالتزام المسبق بحجم عينة ثابت أو مدة اختبار. تضيف بعض الفرق أيضًا عددًا معينًا من التحويلات إلى معايير إيقاف هذه التجربة والطول المقصود.
ومع ذلك ، تكمن المشكلة هنا في أن وجود عدد كافٍ من زيارات الاختبار لتغذية كل تجربة على حدة من أجل التوقف الأمثل عن استخدام هذه الممارسة القياسية أمر صعب بالنسبة لمعظم مواقع الويب.
إليك المكان الذي يساعد فيه استخدام طرق الاختبار المتسلسلة التي تدعم قواعد التوقف الاختيارية.
التحرك نحو قواعد التوقف المرنة التي تتيح اتخاذ قرارات أسرع
تتيح لك طرق الاختبار المتسلسلة الاستفادة من بيانات تجاربك كما تظهر واستخدام نماذج الأهمية الإحصائية الخاصة بك لتحديد الفائزين في وقت أقرب ، مع قواعد إيقاف مرنة.
غالبًا ما تضع فرق التحسين على أعلى مستويات النضج CRO منهجياتها الإحصائية الخاصة لدعم مثل هذا الاختبار. بعض أدوات اختبار A / B تحتوي أيضًا على هذا ويمكن أن تشير إلى ما إذا كان الإصدار يبدو أنه يفوز. ويمنحك البعض تحكمًا كاملاً في كيفية حساب الدلالة الإحصائية الخاصة بك ، باستخدام قيمك المخصصة والمزيد. حتى تتمكن من إلقاء نظرة خاطفة وتحديد الفائز حتى في تجربة جارية.

خبير إحصائي ومؤلف ومدرب لدورة CXL الشهيرة حول إحصائيات اختبار A / B ، جورجي جورجييف هو كل شيء لطرق الاختبار المتسلسلة التي تسمح بالمرونة في عدد وتوقيت التحليلات المؤقتة:
" يسمح لك الاختبار التسلسلي بمضاعفة الأرباح عن طريق النشر المبكر للمتغير الفائز ، بالإضافة إلى إيقاف الاختبارات التي لديها احتمالية ضئيلة لإنتاج فائز في أقرب وقت ممكن. يقلل هذا الأخير من الخسائر بسبب المتغيرات السفلية ويسرع الاختبار عندما يكون من غير المحتمل ببساطة أن تتفوق المتغيرات على عنصر التحكم. يتم الحفاظ على الدقة الإحصائية في جميع الحالات. "
لقد عمل جورجيف حتى على آلة حاسبة تساعد الفرق على التخلص من نماذج اختبار العينة الثابتة لنموذج يمكنه اكتشاف فائز أثناء استمرار التجربة. يقدم نموذجه الكثير من الإحصائيات ويساعدك على إجراء اختبارات أسرع بحوالي 20-80٪ من حسابات الدلالة الإحصائية القياسية ، دون التضحية بالجودة.
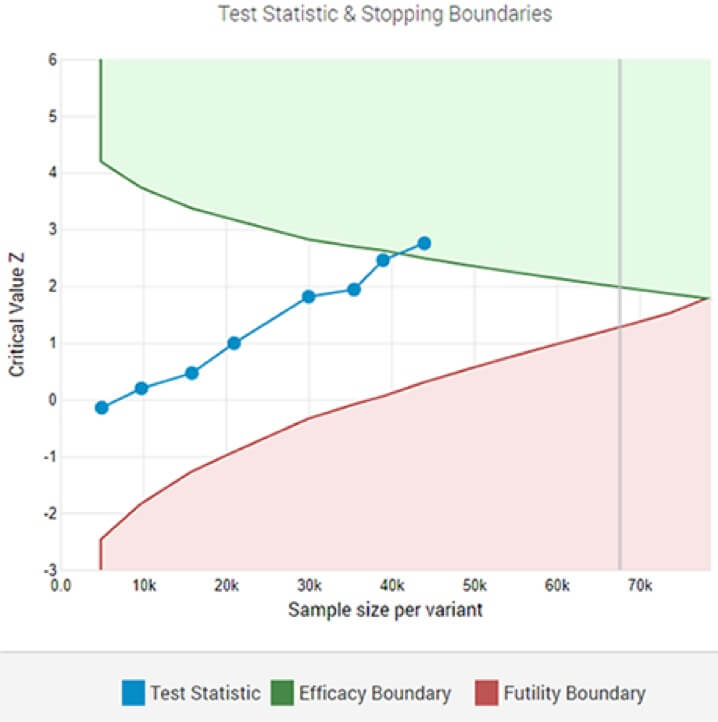
يُظهر اختبار A / B التكيفي فائزًا ذا دلالة إحصائية عند عتبة الأهمية المحددة بعد التحليل المؤقت الثامن.
بينما يمكن لمثل هذا الاختبار تسريع عملية اتخاذ القرار لديك ، هناك جانب واحد مهم يحتاج إلى معالجة: التأثير الفعلي للتجربة . قد يؤدي إنهاء التجربة في غضون ذلك إلى المبالغة في تقديرها.
يحذر جورجيف من أن النظر إلى التقديرات غير المعدلة لحجم التأثير يمكن أن يكون خطيرًا. لتجنب ذلك ، يستخدم نموذجه طرقًا لتطبيق التعديلات التي تأخذ في الاعتبار التحيز الناتج عن المراقبة المؤقتة. يشرح كيف يعمل تحليل أجايل على تعديل التقديرات "اعتمادًا على مرحلة التوقف والقيمة المرصودة للإحصاء (التجاوز ، إن وجد)". أدناه ، يمكنك رؤية التحليل للاختبار أعلاه: (لاحظ كيف أن المصعد المقدر أقل من الملحوظ ولا يتركز الفاصل الزمني حوله.)
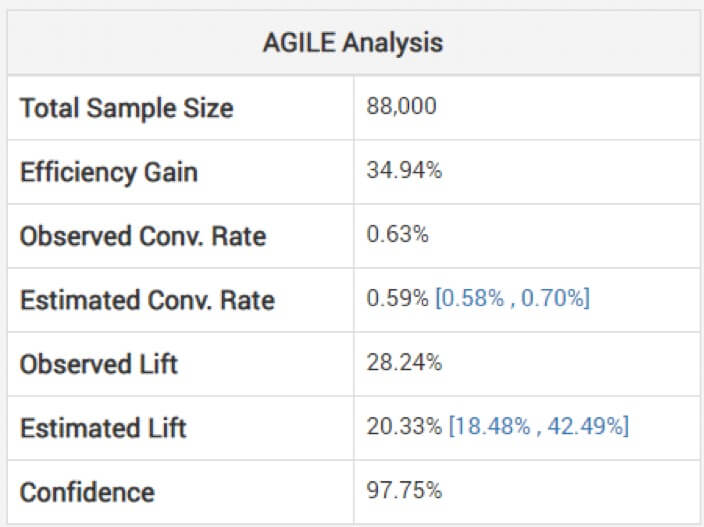
لذلك قد لا يكون الفوز كبيرًا كما يبدو بناءً على تجربتك الأقصر من المقصود.
يجب أيضًا أخذ الخسارة في الاعتبار ، لأنك ربما انتهى بك المطاف بالخطأ في الاتصال بالفائز في وقت مبكر جدًا. لكن هذا الخطر موجود حتى في اختبار الأفق الثابت. ومع ذلك ، قد تكون الصلاحية الخارجية مصدر قلق أكبر عند استدعاء التجارب في وقت مبكر مقارنة باختبار الأفق الثابت الذي يعمل لفترة أطول. ولكن هذا ، كما يشرح جورجييف ، " نتيجة بسيطة لصغر حجم العينة وبالتالي مدة الاختبار. "
في النهاية ... لا يتعلق الأمر بالفائزين أو الخاسرين ...
... ولكن بشأن قرارات العمل الأفضل ، كما يقول كريس ستوتشيو.
أو كما يؤكد توم ريدمان (مؤلف كتاب "البيانات الموجهة: الاستفادة من أهم أصول عملك) في الأعمال التجارية:" غالبًا ما تكون هناك معايير أكثر أهمية من الأهمية الإحصائية. السؤال المهم هو: " هل تصمد النتيجة في السوق ولو لفترة وجيزة؟ "
ويلاحظ جورجيف ، على الأرجح ، وليس لفترة وجيزة فقط ، " إذا كان ذا دلالة إحصائية وتم التعامل مع اعتبارات الصلاحية الخارجية بطريقة مرضية في مرحلة التصميم."
الجوهر الكامل للتجربة هو تمكين الفرق لاتخاذ قرارات أكثر استنارة. لذا ، إذا كان بإمكانك تمرير النتائج - التي تشير إليها بيانات تجاربك - في وقت أقرب ، فلماذا لا؟
قد تكون تجربة واجهة مستخدم صغيرة لا يمكنك عمليًا الحصول على حجم عينة "كافي" لها. قد تكون أيضًا تجربة حيث يسحق منافسك النسخة الأصلية ويمكنك فقط أن تأخذ هذا الرهان!
كما كتب جيف بيزوس في رسالته إلى مساهمي أمازون ، فإن التجارب الكبيرة تدفع الكثير من الوقت:
" إذا أعطيت فرصة بنسبة 10٪ لمكافأة 100 مرة ، يجب أن تأخذ هذا الرهان في كل مرة. لكنك ستظل مخطئًا تسع مرات من أصل عشرة. نعلم جميعًا أنه إذا كنت تتأرجح نحو الأسوار ، فستضرب كثيرًا ، لكنك ستضرب أيضًا بعض الركض في المنزل. ومع ذلك ، فإن الاختلاف بين لعبة البيسبول والأعمال هو أن لعبة البيسبول لها توزيع مبتور للنتائج. عندما تتأرجح ، بغض النظر عن مدى اتصالك بالكرة جيدًا ، فإن أكبر عدد يمكنك الحصول عليه هو أربعة. في مجال الأعمال ، بين الحين والآخر ، عندما تصعد إلى اللوحة ، يمكنك تسجيل 1000 نقطة. هذا التوزيع طويل الذيل للعائدات هو سبب أهمية التحلي بالجرأة. الفائزون الكبار يدفعون مقابل العديد من التجارب. "
إن إجراء التجارب في وقت مبكر ، إلى حد كبير ، يشبه إلقاء نظرة خاطفة على النتائج يوميًا والتوقف عند نقطة تضمن رهانًا جيدًا.

