
التعلم العميق مقابل التعلم الآلي - كيف تميّز الفرق؟
نشرت: 2020-03-10في السنوات الأخيرة ، أصبح التعلم الآلي والتعلم العميق والذكاء الاصطناعي كلمات رنانة. نتيجة لذلك ، يمكنك العثور عليها في جميع أنحاء المواد التسويقية وإعلانات المزيد والمزيد من الشركات.
ولكن ما هو التعلم الآلي والتعلم العميق؟ أيضا ، ما هي الاختلافات بينهما؟ في هذه المقالة ، سأحاول الإجابة على هذه الأسئلة ، وأريكم بعض حالات تطبيقات التعلم العميق والتعلم الآلي.
ما هو التعلم الآلي؟
يعد التعلم الآلي جزءًا من علوم الكمبيوتر الذي يتعامل مع تمثيل أحداث أو كائنات في العالم الحقيقي باستخدام نماذج رياضية ، استنادًا إلى البيانات. تم بناء هذه النماذج باستخدام خوارزميات خاصة تكيف الهيكل العام للنموذج بحيث يناسب بيانات التدريب. اعتمادًا على نوع المشكلة التي يتم حلها ، نحدد خوارزميات التعلم الآلي والتعلم الآلي الخاضعة للإشراف وغير الخاضعة للإشراف.
التعلم الآلي الخاضع للإشراف مقابل التعلم غير الخاضع للإشراف
يركز التعلم الآلي الخاضع للإشراف على إنشاء نماذج يمكنها نقل المعرفة التي لدينا بالفعل حول البيانات الموجودة إلى بيانات جديدة. البيانات الجديدة غير مرئية بواسطة خوارزمية بناء النموذج (التدريب) أثناء مرحلة التدريب. نحن نقدم خوارزمية ببيانات الميزات جنبًا إلى جنب مع القيم المقابلة التي يجب أن تتعلم الخوارزمية الاستنتاج منها (ما يسمى بالمتغير المستهدف).
في التعلم الآلي غير الخاضع للإشراف ، نوفر فقط الخوارزمية بالميزات. يسمح لها ذلك بمعرفة هيكلها و / أو تبعياتها من تلقاء نفسها. لا يوجد متغير هدف واضح محدد. قد يكون من الصعب فهم فكرة التعلم غير الخاضع للإشراف في البداية ، ولكن إلقاء نظرة على الأمثلة الواردة في الرسوم البيانية الأربعة أدناه يجب أن يوضح هذه الفكرة.
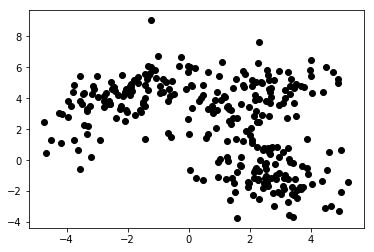
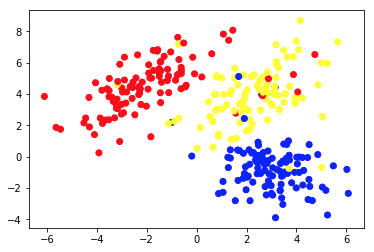

يقدم الرسم البياني 1 أ بعض البيانات الموصوفة بميزتين على المحورين x و y . يُظهر الشخص الذي تم وضع علامة عليه كـ 1b نفس البيانات الملونة. استخدمنا خوارزمية K- mean clustering لتجميع هذه النقاط في 3 مجموعات ، وقمنا بتلوينها وفقًا لذلك. هذا مثال على خوارزمية التعلم الآلي غير الخاضعة للرقابة . أعطيت الخوارزمية فقط الميزات ، وكان من المقرر معرفة الملصقات (أرقام المجموعات).
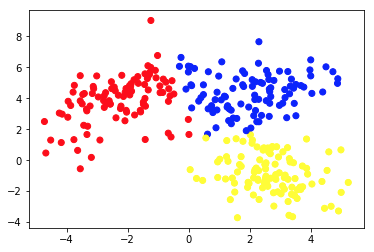
تُظهر الصورة الثانية الرسم البياني 2 أ ، والذي يقدم مجموعة مختلفة من البيانات المعنونة (والملونة وفقًا لذلك). نحن نعلم أن المجموعات التي تنتمي إليها كل نقطة من نقاط البيانات هي بداهة . نستخدم خوارزمية SVM للعثور على خطين مستقيمين يوضحان لنا كيفية تقسيم نقاط البيانات لتناسب هذه المجموعات بشكل أفضل. هذا التقسيم ليس مثاليًا ، لكن هذا هو أفضل ما يمكن القيام به باستخدام خطوط مستقيمة. إذا أردنا تعيين مجموعة إلى نقطة بيانات جديدة غير مسماة ، فنحن نحتاج فقط إلى التحقق من مكانها على المستوى. هذا مثال على تطبيق "التعلم الآلي" الخاضع للإشراف .
تطبيقات نماذج التعلم الآلي
يتم إنشاء خوارزميات تعلم الآلة القياسية لمعالجة البيانات في شكل جدول. هذا يعني أنه من أجل استخدامها نحتاج إلى نوع من الجدول. في مثل هذه الصفوف في الجدول يمكن اعتبارها أمثلة على الكائن على غرار (على سبيل المثال ، قرض). في الوقت نفسه ، ينبغي النظر إلى الأعمدة على أنها ميزات (خصائص) لهذه الحالة بالذات (على سبيل المثال ، السداد الشهري للقرض ، والدخل الشهري للمقترض).

هل تشعر بالفضول بشأن تطوير التعلم الآلي؟
يتعلم أكثرالجدول 1. مثال قصير جدًا على مثل هذه البيانات. بالطبع ، هذا لا يعني أن البيانات النقية نفسها يجب أن تكون مجدولة ومنظمة. ولكن إذا أردنا تطبيق خوارزمية تعلم الآلة القياسية على بعض مجموعات البيانات ، فعادةً ما يتعين علينا تنظيفها ومزجها وتحويلها إلى جدول. في التعلم الخاضع للإشراف ، يوجد أيضًا عمود خاص واحد يحتوي على القيمة المستهدفة (على سبيل المثال ، معلومات إذا كان القرض قد تعثر).
تحاول خوارزمية التدريب ملاءمة الهيكل العام للنموذج في هذه البيانات. تقوم الخوارزمية المذكورة بذلك عن طريق تعديل معلمات النموذج. ينتج عن ذلك نموذج يصف العلاقة بين البيانات المعطاة والمتغير المستهدف بأكبر قدر ممكن من الدقة.
من المهم ألا يناسب النموذج بيانات التدريب المقدمة جيدًا فحسب ، بل يكون قادرًا أيضًا على التعميم. يعني التعميم أنه يمكننا استخدام النموذج لاستنتاج الهدف للحالات التي لم يتم استخدامها أثناء التدريب. إنها أيضًا سمة مهمة لنموذج مفيد. إن بناء نموذج جيد التعميم ليس بالمهمة السهلة. غالبًا ما يتطلب تقنيات تحقق متطورة واختبار نموذج شامل.
| معرّف القرض | المستعير | الدخل شهريا | مبلغ القرض | الدفع الشهري | إفتراضي |
| 1 | 34 | 10000 | 100،000 | 1200 | 0 |
| 2 | 43 | 5700 | 25000 | 800 | 0 |
| 3 | 25 | 2500 | 24000 | 400 | 0 |
| 4 | 67 | 4600 | 40000 | 2000 | 1 |
| 5 | 38 | 35000 | 2500000 | 10000 | 0 |
الجدول 1. بيانات القرض في شكل جدول
يستخدم الأشخاص خوارزميات التعلم الآلي في مجموعة متنوعة من التطبيقات. يعرض الجدول 2. بعض حالات استخدام الأعمال التي تسمح بخوارزميات التعلم الآلي غير العميقة ونماذج الأجهزة. هناك أيضًا أوصاف مختصرة للبيانات المحتملة والمتغيرات المستهدفة والخوارزميات القابلة للتطبيق المختارة.
| حالة الاستخدام | أمثلة البيانات | الهدف (النموذجي) القيمة | الخوارزمية / النموذج المستخدم |
| توصيات للمقالات على موقع بلوق | معرّفات المقالات التي قرأها المستخدمون ، والوقت الذي يقضيه في كل منها | تفضيلات المستخدمين تجاه المقالات | التصفية التعاونية باستخدام المربعات الصغرى المتناوبة |
| التصنيف الائتماني للرهون العقارية | تاريخ المعاملات والائتمان ، وبيانات الدخل لمقترض محتمل | تظهر القيمة الثنائية ما إذا كان سيتم سداد القرض بالكامل أم أنه سيتخلف عن السداد | LightGBM |
| توقع زخم المستخدمين المتميزين للعبة الهاتف المحمول | الوقت المستغرق في اللعب يوميًا ، الوقت منذ الإطلاق الأول ، التقدم في اللعبة | تظهر القيمة الثنائية ما إذا كان المستخدم سيلغي الاشتراك الشهر المقبل | XGBoost |
| كشف الاحتيال في بطاقة الائتمان | بيانات معاملات بطاقة الائتمان التاريخية - المبلغ والمكان والتاريخ والوقت | تظهر القيمة الثنائية ما إذا كانت معاملة بطاقة الائتمان احتيالية | غابة عشوائية |
| تقسيم عملاء متجر الإنترنت | تاريخ الشراء لأعضاء برنامج الولاء | رقم الجزء المخصص لكل عميل | K- يعني |
| الصيانة التنبؤية لحديقة الماكينات | بيانات من أجهزة استشعار الأداء ودرجة الحرارة والرطوبة وما إلى ذلك | أحد الفئات التالية - "جيد" ، "مراقبة" ، "يتطلب صيانة" | شجرة القرار |
الجدول 2. أمثلة على حالات استخدام التعلم الآلي
التعلم العميق والشبكات العصبية العميقة
التعلم العميق هو جزء من التعلم الآلي حيث نستخدم نماذج من نوع معين ، تسمى الشبكات العصبية الاصطناعية العميقة (ANNs). منذ ظهورها ، مرت الشبكات العصبية الاصطناعية بعملية تطور واسعة النطاق. أدى ذلك إلى عدد من الأنواع الفرعية ، بعضها معقد للغاية. ولكن من أجل تقديمهم ، من الأفضل شرح أحد أشكالهم الأساسية - الإدراك الحسي متعدد الطبقات (MPL).
متعدد الطبقات المستقبلات
ببساطة ، يحتوي MLP على شكل من أشكال الرسم البياني (شبكة) من الرؤوس (تسمى أيضًا الخلايا العصبية) والحواف (ممثلة بأرقام تسمى الأوزان). يتم ترتيب الخلايا العصبية في طبقات ، وتتصل الخلايا العصبية في طبقات متتالية مع بعضها البعض. تتدفق البيانات عبر الشبكة من المدخلات إلى طبقة الإخراج. ثم يتم تحويل البيانات عند الخلايا العصبية والحواف بينها. بمجرد مرور نقطة البيانات عبر الشبكة بأكملها ، تحتوي طبقة الإخراج على القيم المتوقعة في الخلايا العصبية الخاصة بها.
في كل مرة يمر جزء من بيانات التدريب عبر الشبكة ، نقارن التنبؤات بالقيم الحقيقية المقابلة. يتيح لنا ذلك تكييف معلمات (أوزان) النموذج لجعل التنبؤات أفضل. يمكننا القيام بذلك باستخدام خوارزمية تسمى backpropagation. بعد بعض التكرارات ، إذا كان هيكل النموذج مصممًا جيدًا خصيصًا لمعالجة مشكلة التعلم الآلي في متناول اليد.
الحصول على نموذج عالي الدقة
بمجرد مرور بيانات كافية عبر الشبكة عدة مرات ، نحصل على نموذج عالي الدقة. من الناحية العملية ، هناك الكثير من التحولات التي يمكن تطبيقها على الخلايا العصبية. هذا يجعل شبكات ANN مرنة وقوية للغاية. ومع ذلك ، فإن قوة شبكات ANN لها ثمن. عادة ، كلما كان هيكل النموذج أكثر تعقيدًا ، زادت البيانات والوقت اللازم لتدريبه على دقة عالية.
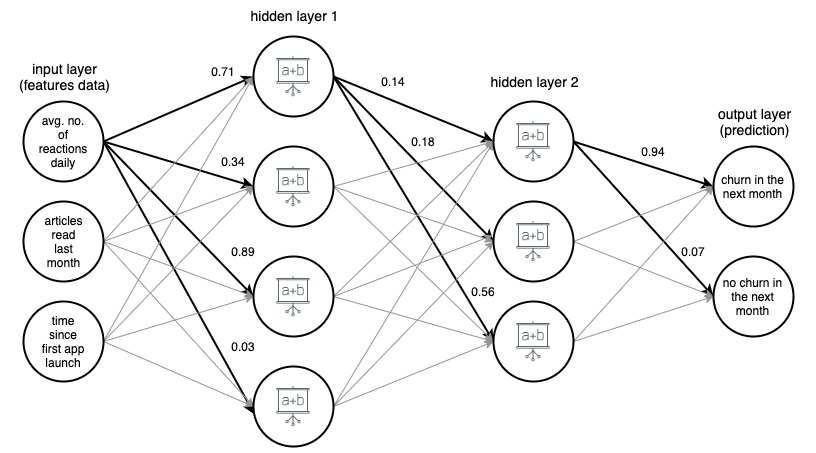
الصورة 1. (draw.io) هيكل لشبكة عصبية اصطناعية مكونة من 4 طبقات ، تتنبأ بما إذا كان مستخدم تطبيق الأخبار سيتوقف عن العمل الشهر المقبل ، بناءً على ثلاث ميزات بسيطة.
من أجل الوضوح ، تم تحديد الأوزان فقط لحواف محددة (غامقة) ، لكن كل حافة لها وزنها الخاص. تتدفق البيانات من طبقة الإدخال إلى طبقة الإخراج ، مروراً بطبقتين مخفيتين في المنتصف. على كل حافة ، يتم ضرب قيمة الإدخال بوزن الحافة ، وينتقل المنتج الناتج إلى العقدة التي تنتهي عندها الحافة. ثم ، في كل نقطة من العقد في الطبقات المخفية ، يتم تلخيص الإشارات الواردة من الحواف ثم تحويلها ببعض الوظائف. ثم يتم التعامل مع نتيجة هذه التحويلات كمدخل للطبقة التالية.
في طبقة المخرجات ، يتم تلخيص البيانات الواردة وتحويلها مرة أخرى ، مما يؤدي إلى النتيجة في شكل رقمين - احتمالية أن يخرج المستخدم من التطبيق في الشهر التالي ، واحتمال عدم حدوث ذلك.
الأنواع المتقدمة من الشبكات العصبية
في الشبكات العصبية ذات الأنواع الأكثر تقدمًا ، تتمتع الطبقات ببنية أكثر تعقيدًا. فهي لا تتكون فقط من طبقات كثيفة بسيطة ذات خلايا عصبية أحادية العملية معروفة من MLPs ، ولكن أيضًا طبقات أكثر تعقيدًا ومتعددة العمليات مثل الطبقات التلافيفية والمتكررة.
الطبقات التلافيفية والمتكررة
تستخدم الطبقات التلافيفية في الغالب في تطبيقات رؤية الكمبيوتر . وهي تتكون من مصفوفات صغيرة من الأرقام التي تنزلق فوق تمثيل البكسل للصورة. يتم ضرب قيم البكسل في هذه الأرقام ثم يتم تجميعها ، مما ينتج عنه تمثيل جديد ومكثف للصورة.
تُستخدم الطبقات المتكررة لنمذجة البيانات المتسلسلة المرتبة مثل السلاسل الزمنية أو النص . يطبقون تحويلات معقدة متعددة الوسائط على البيانات الواردة ، في محاولة لمعرفة التبعيات بين عناصر التسلسل. ومع ذلك ، بغض النظر عن نوع الشبكة وهيكلها ، هناك دائمًا بعض (واحد أو أكثر) طبقات الإدخال والإخراج ، والمسارات والاتجاهات المحددة بدقة التي تتدفق فيها البيانات عبر الشبكة.
بشكل عام ، الشبكات العصبية العميقة هي شبكات ANN ذات طبقات متعددة. تُظهر الصور 1 و 2 و 3 أدناه بنيات شبكات عصبية اصطناعية عميقة مختارة. تم تطويرها جميعًا وتدريبها في Google ، وإتاحتها للجمهور. يقدمون فكرة عن مدى تعقيد الشبكات الاصطناعية العميقة عالية الدقة المستخدمة اليوم.
هذه الشبكات لها أحجام هائلة. على سبيل المثال ، يظهر جزئيًا في الصورة 3 InceptionResNetV2 به 572 طبقة ، وأكثر من 55 مليون معلمة في المجموع! لقد تم تطويرها جميعًا كنماذج تصنيف للصور (حيث تقوم بتعيين ملصق ، على سبيل المثال "سيارة" لصورة معينة) ، وتم تدريبها على الصور من مجموعة ImageNet ، والتي تتكون من أكثر من 14 مليون صورة معنونة.

الصورة 2. هيكل NASNetMobile (حزمة keras)

الصورة 3. هيكل XCeption (حزمة keras)

الصورة 4. هيكل جزء (حوالي 25٪) من InceptionResNetV2 (حزمة keras)
في السنوات الأخيرة ، لاحظنا تطورًا كبيرًا في التعلم العميق وتطبيقاته. العديد من الميزات "الذكية" لهواتفنا الذكية وتطبيقاتنا هي ثمرة هذا التقدم. على الرغم من أن فكرة الشبكات العصبية الاصطناعية ليست جديدة ، إلا أن هذا الازدهار الأخير هو نتيجة تلبية بعض الشروط. بادئ ذي بدء ، اكتشفنا إمكانات حوسبة GPU. تعد بنية وحدات المعالجة الرسومية رائعة بالنسبة للحسابات المتوازية ، وهي مفيدة جدًا في التعلم العميق الفعال.
علاوة على ذلك ، أدى ظهور خدمات الحوسبة السحابية إلى جعل الوصول إلى الأجهزة عالية الكفاءة أسهل بكثير وأرخص ثمناً وممكناً على نطاق أوسع بكثير. أخيرًا ، القوة الحسابية لأحدث الأجهزة المحمولة كبيرة بما يكفي لتطبيق نماذج التعلم العميق ، مما يخلق سوقًا ضخمًا من المستخدمين المحتملين للميزات التي تحركها DNN.
تطبيقات نماذج التعلم العميق
عادةً ما يتم تطبيق نماذج التعلم العميق على المشكلات التي تتعامل مع البيانات التي لا تحتوي على هيكل بسيط لأعمدة الصفوف ، مثل تصنيف الصور أو ترجمة اللغة ، حيث إنها رائعة في العمل على بيانات هيكلية غير منظمة ومعقدة تتعامل معها هذه المهام - الصور والنص ، والصوت. هناك مشاكل في التعامل مع البيانات من هذه الأنواع والأحجام باستخدام خوارزميات التعلم الآلي الكلاسيكية ، وقد تسبب إنشاء وتطبيق بعض الشبكات العصبية العميقة على هذه المشكلات في تطورات هائلة في مجالات التعرف على الصور والتعرف على الكلام وتصنيف النص وترجمة اللغة في السنوات القليله الماضيه.
كان تطبيق التعلم العميق على هذه المشكلات ممكنًا نظرًا لحقيقة أن DNNs تقبل جداول أرقام متعددة الأبعاد ، تسمى الموترات ، كمدخلات ومخرجات ، ويمكنها تتبع العلاقات المكانية والزمانية بين عناصرها. على سبيل المثال ، يمكننا تقديم صورة على شكل موتر ثلاثي الأبعاد ، حيث يمثل البعد الأول والثاني دقة الصورة الرقمية (لذلك يكون حجم عرض الصورة وارتفاعها ، على التوالي) ، ويمثل البعد الثالث لون RGB ترميز كل بكسل (لذا فإن البعد الثالث بحجم 3).
هذا لا يسمح لنا فقط بتمثيل جميع المعلومات حول الصورة في موتر ولكن أيضًا الحفاظ على العلاقات المكانية بين البكسلات ، والتي تبين أنها حاسمة في تطبيق ما يسمى بالطبقات التلافيفية ، وهي حاسمة في تصنيف الصور الناجح وشبكات التعرف.
تساعد مرونة الشبكة العصبية في هياكل الإدخال والإخراج أيضًا في مهام أخرى ، مثل ترجمة اللغة . عند التعامل مع البيانات النصية ، نقوم بتغذية الشبكات العصبية العميقة بتمثيل رقمي للكلمات ، مرتبة حسب مظهرها في النص. يتم تمثيل كل كلمة بواسطة متجه من مائة أو بضع مئات من الأرقام ، محسوبة (عادةً باستخدام شبكة عصبية مختلفة) بحيث تحاكي العلاقات بين المتجهات المقابلة للكلمات المختلفة علاقات الكلمات نفسها. يمكن إعادة استخدام هذه التمثيلات اللغوية الموجهة ، التي تسمى حفلات الزفاف ، بمجرد تدريبها ، في العديد من البنى ، وهي تشكل لبنة أساسية لنماذج لغة الشبكة العصبية.
أمثلة على استخدام نماذج التعلم العميق
يحتوي الجدول 3. على أمثلة لتطبيق نماذج التعلم العميق لمشاكل الحياة الواقعية. كما ترى ، فإن المشكلات التي يتم معالجتها وحلها بواسطة خوارزميات التعلم العميق هي أكثر تعقيدًا بكثير من المهام التي يتم حلها بواسطة تقنيات التعلم الآلي القياسية ، مثل تلك المعروضة في الجدول 1.
ومع ذلك ، من المهم أن نتذكر أن العديد من حالات الاستخدام التي يمكن أن تساعد التعلم الآلي في الأعمال التجارية اليوم لا تتطلب مثل هذه الأساليب المعقدة ، ويمكن حلها بشكل أكثر كفاءة (وبدقة أعلى) من خلال النماذج القياسية. يعطي الجدول 3. أيضًا فكرة عن عدد الأنواع المختلفة لطبقات الشبكات العصبية الاصطناعية ، وعدد البنى المفيدة المختلفة التي يمكن إنشاؤها باستخدامها.
| حالة الاستخدام | بيانات | الهدف / نتيجة النموذج | الخوارزمية / النموذج المستخدم |
| تصنيف الصورة | الصور | تسمية مخصصة لصورة | الشبكة العصبية التلافيفية (CNN) |
| كشف الصور عن طريق السيارات ذاتية القيادة | الصور | التسميات والمربعات المحيطة حول الكائنات المحددة في الصور | سريع R-CNN |
| المشاعر تحليل التعليقات في متجر على الإنترنت | نص التعليقات عبر الإنترنت | تسمية المشاعر (على سبيل المثال ، إيجابية ، محايدة ، سلبية) مخصصة لكل تعليق | شبكة الذاكرة طويلة المدى ثنائية الاتجاه (LSTM) |
| مواءمة اللحن | ملف MIDI مع لحن | تنسيق ملف MIDI مع هذا اللحن | شبكة الخصومة التوليدية |
| توقع الكلمة التالية في عبر الانترنت البريد الإلكتروني محرر | نص كبير جدًا (على سبيل المثال ، تفريغ جميع مقالات ويكيبيديا باللغة الإنجليزية) | كلمة تتناسب مع الكلمة التالية التي كتب بها النص حتى الآن | الشبكة العصبية المتكررة (RNN) مع طبقة التضمين |
| ترجمة النص إلى لغة أخرى | نص باللغة البولندية | نفس النص مترجم إلى اللغة الإنجليزية | التشفير - شبكة فك التشفير مبنية مع طبقات الشبكة العصبية المتكررة (RNN) |
| نقل نمط مونيه إلى أي صورة | مجموعة صور للوحات مونيه ومجموعة صور أخرى | تم تعديل الصور لتبدو كما رسمها مونيه | شبكة الخصومة التوليدية |
الجدول 3. أمثلة على حالات استخدام التعلم العميق
مزايا نماذج التعلم العميق
شبكات الخصومة التوليدية
جاء أحد أكثر التطبيقات إثارة للإعجاب للشبكات العصبية العميقة مع ظهور شبكات الخصومة التوليدية (GANs). تم تقديمها في عام 2014 بواسطة Ian Goodfellow ، ومنذ ذلك الحين تم دمج فكرته في العديد من الأدوات ، بعضها حقق نتائج مذهلة.
تعد شبكات GAN مسؤولة عن وجود التطبيقات التي تجعلنا نبدو أكبر سنًا في الصور ، وتحول الصور بحيث تبدو كما لو كانت رسمها فان جوخ ، أو حتى تنسيق الألحان لنطاقات آلات متعددة. أثناء تدريب GAN ، تتنافس شبكتان عصبيتان. تولد شبكة المولد ناتجًا من الإدخال العشوائي ، بينما يحاول المُميِّز التمييز بين الحالات التي تم إنشاؤها من تلك الحقيقية. أثناء التدريب ، يتعلم المولد كيفية "خداع" أداة التمييز بنجاح ، وفي النهاية يكون قادرًا على إنشاء مخرجات تبدو كما لو كانت حقيقية.
شبكات عصبية عميقة قوية في تطبيقات الأجهزة المحمولة
من المهم ملاحظة أنه على الرغم من أن تدريب شبكة عصبية عميقة يعد مهمة مكلفة للغاية من الناحية الحسابية ويمكن أن يستغرق وقتًا طويلاً ، إلا أن تطبيق شبكة مدربة للقيام بمهمة معينة لا يجب أن يكون كذلك ، خاصةً إذا تم تطبيقه على واحد أو عدد قليل من الحالات في وقت واحد. في الواقع ، نحن اليوم قادرون على تشغيل شبكات عصبية عميقة قوية في تطبيقات الهاتف المحمول على هواتفنا الذكية.
حتى أن هناك بعض بنى الشبكات المصممة خصيصًا لتكون فعالة عند تطبيقها على الأجهزة المحمولة (على سبيل المثال ، NASNetMobile المعروضة في الصورة 1). على الرغم من أنها أصغر حجمًا مقارنةً بأحدث الشبكات ، إلا أنها لا تزال قادرة على الحصول على أداء تنبؤ عالي الدقة.
نقل التعلم
ميزة أخرى قوية جدًا للشبكات العصبية الاصطناعية ، والتي تتيح الاستخدام الواسع لنماذج التعلم العميق ، هي نقل التعلم . بمجرد أن يكون لدينا نموذج مُدرَّب على بعض البيانات (سواء تم إنشاؤه بواسطة أنفسنا أو تنزيله من مستودع عام) ، يمكننا البناء عليه بالكامل أو جزء منه للحصول على نموذج يحل حالة الاستخدام الخاصة بنا. على سبيل المثال ، يمكننا استخدام نموذج NASNetLarge الذي تم تدريبه مسبقًا ، والمُدرب على مجموعة بيانات ImageNet الضخمة ، والذي يقوم بتعيين تسمية للصورة ، وإجراء بعض التعديلات الصغيرة على الجزء العلوي من هيكلها ، وتدريبها بشكل أكبر باستخدام مجموعة جديدة من الصور المصنفة ، و استخدمه لتسمية نوع معين من الكائنات (مثل أنواع الشجرة بناءً على صورة أوراقها).
اكراميات نقل التعلم
يعد التعلم عن طريق النقل مفيدًا للغاية ، حيث عادة ما يتطلب تدريب شبكة عصبية عميقة تؤدي بعض المهام العملية والمفيدة كميات هائلة من البيانات وقوة حسابية ضخمة. قد يعني هذا غالبًا تشغيل الملايين من مثيلات البيانات المصنفة ومئات من وحدات معالجة الرسومات (GPU) لأسابيع.
لا يستطيع الجميع تحمل مثل هذه الأصول أو الوصول إليها ، مما يجعل من الصعب جدًا إنشاء حل مخصص عالي الدقة من البداية لتصنيف الصور ، على سبيل المثال. لحسن الحظ ، كانت بعض النماذج المدربة مسبقًا (خاصة شبكات تصنيف الصور ومصفوفات التضمين المدربة مسبقًا لنماذج اللغة) مفتوحة المصدر ومتاحة مجانًا في شكل قابل للتطبيق بسهولة (على سبيل المثال ، نموذج في Keras ، نموذج عصبي. API الشبكات).
كيفية اختيار وبناء نموذج التعلم الآلي المناسب لتطبيقك
عندما تريد تطبيق "التعلم الآلي" لحل مشكلة العمل ، فربما لا تحتاج إلى تحديد نوع النموذج على الفور. عادة ما يكون هناك عدد قليل من الأساليب التي يمكن اختبارها. غالبًا ما يكون من المغري البدء بأكثر النماذج تعقيدًا في البداية ، لكن الأمر يستحق البدء ببساطة ، وزيادة تعقيد النماذج المطبقة تدريجيًا. عادةً ما تكون النماذج الأبسط أرخص من حيث الإعداد ووقت الحساب والموارد. علاوة على ذلك ، تعد نتائجهم معيارًا رائعًا لتقييم الأساليب الأكثر تقدمًا.
يمكن أن يساعد وجود مثل هذه المعايير علماء البيانات على تقييم ما إذا كان الاتجاه الذي يطورون فيه نماذجهم هو الاتجاه الصحيح. ميزة أخرى هي إمكانية إعادة استخدام بعض النماذج المبنية سابقًا ، ودمجها مع أحدث النماذج ، وإنشاء ما يسمى بنموذج المجموعة. غالبًا ما ينتج عن خلط النماذج من أنواع مختلفة مقاييس أداء أعلى من كل من النماذج المدمجة وحدها. تحقق أيضًا مما إذا كانت هناك بعض النماذج المدربة مسبقًا التي يمكن استخدامها وتكييفها مع حالة عملك من خلال نقل التعلم.
المزيد من النصائح العملية
أولاً وقبل كل شيء ، بغض النظر عن النموذج الذي تستخدمه ، تأكد من التعامل مع البيانات بشكل صحيح. ضع في اعتبارك قاعدة "إدخال القمامة ، إخراج القمامة". إذا كانت بيانات التدريب المقدمة إلى النموذج منخفضة الجودة أو لم يتم تصنيفها وتنظيفها بشكل صحيح ، فمن المحتمل جدًا أن يكون أداء النموذج الناتج ضعيفًا أيضًا. تأكد أيضًا من أن النموذج - مهما كانت درجة تعقيده - قد تم التحقق منه على نطاق واسع خلال مرحلة النمذجة ، وفي النهاية تم اختباره إذا كان معممًا جيدًا للبيانات غير المرئية.
من الناحية العملية ، تأكد من أن الحل الذي تم إنشاؤه يمكن تنفيذه في الإنتاج على البنية التحتية المتاحة. وإذا كان بإمكان عملك جمع المزيد من البيانات التي يمكن استخدامها لتحسين نموذجك في المستقبل ، فيجب إعداد خط أنابيب لإعادة التدريب لضمان سهولة تحديثه. يمكن إعداد خط الأنابيب هذا لإعادة تدريب النموذج تلقائيًا بتردد زمني محدد مسبقًا.
افكار اخيرة
لا تنسَ تتبع أداء النموذج وقابليته للاستخدام بعد نشره في الإنتاج ، لأن بيئة الأعمال ديناميكية للغاية. قد تتغير بعض العلاقات داخل بياناتك بمرور الوقت ، ويمكن أن تظهر ظواهر جديدة. وبالتالي ، يمكنهم تغيير كفاءة النموذج الخاص بك ، ويجب التعامل معها بشكل صحيح. بالإضافة إلى ذلك ، يمكن اختراع أنواع جديدة وقوية من النماذج. من ناحية ، يمكنهم جعل الحل الخاص بك ضعيفًا نسبيًا ، ولكن من ناحية أخرى ، يمنحك الفرصة لتحسين عملك بشكل أكبر والاستفادة من أحدث التقنيات.
علاوة على ذلك ، يمكن أن تساعدك نماذج التعلم الآلي والتعلم العميق في بناء أدوات قوية لعملك وتطبيقاتك ومنح عملائك تجربة استثنائية . على الرغم من أن إنشاء هذه الميزات "الذكية" يتطلب جهدًا كبيرًا ، إلا أن الفوائد المحتملة تستحق العناء. فقط تأكد من قيامك أنت وفريق علوم البيانات بتجربة النماذج المناسبة واتباع الممارسات الجيدة ، وستكون على المسار الصحيح لتمكين عملك وتطبيقاتك من خلال حلول التعلم الآلي المتطورة.
مصادر:
- https://en.wikipedia.org/wiki/Unsupervised_learning
- https://keras.io/
- https://developer.nvidia.com/deep-learning
- https://keras.io/applications/
- https://arxiv.org/abs/1707.07012
- http://yifanhu.net/PUB/cf.pdf
- https://towardsdatascience.com/detecting-financial-fraud-using-machine-learning-three-ways-of-winning-the-war-against-imbalanced-a03f8815cce9
- https://scikit-learn.org/stable/modules/tree.html
- https://aws.amazon.com/deepcomposer/
- https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
- https://keras.io/examples/nlp/bidirectional_lstm_imdb/
- https://towardsdatascience.com/how-do-self-driving-cars-see-13054aee2503
- https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e
- https://towardsdatascience.com/building-a-next-word-predictor-in-tensorflow-e7e681d4f03f
- https://keras.io/applications/
- https://arxiv.org/pdf/1707.07012.pdf