
ما هو منحنى نسبة النقر إلى الظهور وكيفية حسابه باستخدام بايثون؟
نشرت: 2022-03-22منحنى نسبة النقر إلى الظهور (CTR) ، أو بعبارة أخرى نسبة النقر إلى الظهور العضوية بناءً على الموضع ، هي بيانات توضح لك عدد الروابط الزرقاء في صفحة نتائج محرك البحث (SERP) التي تحصل على نسبة النقر إلى الظهور بناءً على موضعها. على سبيل المثال ، في معظم الأوقات ، يحصل الرابط الأزرق الأول في SERP على أكبر نسبة نقر إلى ظهور.
في نهاية هذا البرنامج التعليمي ، سوف تكون قادرًا على حساب منحنى نسبة النقر إلى الظهور لموقعك استنادًا إلى الدلائل الخاصة به أو حساب نسبة النقر إلى الظهور العضوية استنادًا إلى استعلامات نسبة النقر إلى الظهور. ناتج كود Python الخاص بي هو مربع ثاقب ومخطط شريطي يصف منحنى CTR للموقع.
إذا كنت مبتدئًا ولا تعرف تعريف نسبة النقر إلى الظهور ، فسأشرح ذلك أكثر في القسم التالي.
ما هي نسبة النقر إلى الظهور العضوية أو نسبة النقر إلى الظهور العضوية؟
تأتي نسبة النقر إلى الظهور من تقسيم النقرات العضوية إلى مرات الظهور. على سبيل المثال ، إذا بحث 100 شخص عن "تفاحة" ونقر 30 شخصًا على النتيجة الأولى ، فإن نسبة النقر إلى الظهور للنتيجة الأولى هي 30/100 * 100 = 30٪.
هذا يعني أنه من بين كل 100 عملية بحث ، تحصل على 30٪ منها. من المهم أن تتذكر أن مرات الظهور في Google Search Console (GSC) لا تستند إلى ظهور رابط موقع الويب الخاص بك في إطار عرض الباحث. إذا ظهرت النتيجة على الباحث SERP ، فستحصل على ظهور واحد لكل عملية بحث.
ما هي استخدامات منحنى نسبة النقر إلى الظهور CTR؟
أحد الموضوعات المهمة في تحسين محركات البحث هو تنبؤات حركة المرور العضوية. لتحسين الترتيب في بعض مجموعات الكلمات الرئيسية ، نحتاج إلى تخصيص آلاف وآلاف الدولارات للحصول على المزيد من الأسهم. ولكن السؤال على مستوى تسويق الشركة غالبًا هو "هل من المناسب التكلفة بالنسبة لنا لتخصيص هذه الميزانية؟".
أيضًا ، إلى جانب موضوع مخصصات الميزانية لمشاريع تحسين محركات البحث ، نحتاج إلى الحصول على تقدير للزيادة أو النقصان في حركة المرور العضوية في المستقبل. على سبيل المثال ، إذا رأينا أحد منافسينا يحاول جاهدًا أن يحل محلنا في مرتبة SERP الخاصة بنا ، فكم سيكلفنا ذلك؟
في هذه الحالة أو في العديد من السيناريوهات الأخرى ، نحتاج إلى منحنى نسبة النقر إلى الظهور لموقعنا.
لماذا لا نستخدم دراسات منحنى نسبة النقر إلى الظهور (CTR) ونستخدم بياناتنا؟
الإجابة ببساطة ، لا يوجد أي موقع ويب آخر له خصائص موقعك في SERP.
هناك الكثير من الأبحاث حول منحنيات نسبة النقر إلى الظهور (CTR) في صناعات مختلفة وميزات مختلفة في SERP ، ولكن عندما تكون لديك بياناتك ، فلماذا لا تحسب مواقعك نسبة النقر إلى الظهور بدلاً من الاعتماد على مصادر خارجية؟
لنبدأ في فعل هذا.
حساب منحنى نسبة النقر إلى الظهور (CTR) باستخدام بايثون: الشروع في العمل
قبل أن نتعمق في عملية حساب معدل النقر على Google استنادًا إلى الموضع ، تحتاج إلى معرفة بنية Python الأساسية والحصول على فهم أساسي لمكتبات Python الشائعة ، مثل Pandas. سيساعدك هذا على فهم الكود بشكل أفضل وتخصيصه على طريقتك.
بالإضافة إلى ذلك ، بالنسبة لهذه العملية ، أفضل استخدام دفتر Jupyter.
لحساب نسبة النقر إلى الظهور العضوية بناءً على الموضع ، نحتاج إلى استخدام مكتبات بايثون هذه:
- الباندا
- مؤامرة
- كاليدو
أيضًا ، سنستخدم مكتبات Python القياسية هذه:
- نظام التشغيل
- json
كما قلت ، سوف نستكشف طريقتين مختلفتين لحساب منحنى نسبة النقر إلى الظهور. بعض الخطوات هي نفسها في كلتا الطريقتين: استيراد حزم Python ، وإنشاء مجلد إخراج صور مؤامرة ، وتعيين أحجام مؤامرة الإخراج.
# استيراد المكتبات اللازمة لعمليتنا استيراد نظام التشغيل استيراد json استيراد الباندا كما pd استيراد plotly.express كـ بكسل استيراد plotly.io مثل بيو استيراد كاليدو
هنا نقوم بإنشاء مجلد إخراج لحفظ صور المؤامرة الخاصة بنا.
# إنشاء مجلد إخراج صور مؤامرة
إذا لم يكن os.path.exists (". / إخراج صور مؤامرة"):
os.mkdir (". / صور مؤامرة الإخراج")
يمكنك تغيير ارتفاع وعرض الصور الناتجة أدناه.
# ضبط عرض وارتفاع صور الرسم الناتج pio.kaleido.scope.default_height = 800 pio.kaleido.scope.default_width = 2000
لنبدأ بالطريقة الأولى التي تستند إلى استعلامات نسبة النقر إلى الظهور.
الطريقة الأولى: حساب منحنى نسبة النقر إلى الظهور (CTR) لموقع ويب بأكمله أو لقاعدة خاصية URL معينة بناءً على نسبة النقر إلى الظهور لطلبات البحث
بادئ ذي بدء ، نحتاج إلى الحصول على جميع استفساراتنا من خلال نسبة النقر إلى الظهور ومتوسط موضع الإعلان ومرات الظهور. أفضل استخدام بيانات شهر كامل من الشهر الماضي.
من أجل القيام بذلك ، أحصل على بيانات استعلامات من مصدر بيانات ظهور موقع GSC في Google Data Studio. بدلاً من ذلك ، يمكنك الحصول على هذه البيانات بأي طريقة تفضلها ، مثل GSC API أو "Search Analytics for Sheets" على سبيل المثال إضافة جداول بيانات Google. بهذه الطريقة ، إذا كانت صفحات المدونة أو المنتج الخاصة بك تحتوي على خاصية URL مخصصة ، فيمكنك استخدامها كمصدر بيانات في GDS.
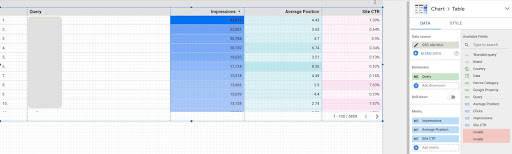
1. الحصول على بيانات الاستفسارات من Google Data Studio (GDS)
لفعل هذا:
- قم بإنشاء تقرير وإضافة مخطط جدول إليه
- أضف مصدر بيانات "ظهور الموقع" إلى التقرير
- اختر "طلب البحث" للبُعد بالإضافة إلى "ctr" و "متوسط موضع الإعلان" و "مرات الظهور" للمقياس
- تصفية الاستعلامات التي تحتوي على اسم العلامة التجارية عن طريق إنشاء عامل تصفية (الاستعلامات التي تحتوي على علامات تجارية سيكون لها نسبة نقر إلى ظهور أعلى ، مما يقلل من دقة بياناتنا)
- انقر بزر الماوس الأيمن على الجدول وانقر على تصدير
- احفظ الإخراج بتنسيق CSV
2. تحميل بياناتنا وتسمية الاستفسارات على أساس موقفهم
لمعالجة ملف CSV الذي تم تنزيله ، سنستخدم Pandas.
أفضل ممارسة لهيكل مجلد مشروعنا هو أن يكون لديك مجلد "بيانات" حيث نقوم بحفظ جميع بياناتنا.
هنا ، من أجل السلاسة في البرنامج التعليمي ، لم أفعل هذا.
query_df = pd.read_csv ('./ download_data.csv')
ثم نقوم بتسمية استفساراتنا بناءً على موقفهم. لقد أنشأت حلقة "for" لتمييز المواضع من 1 إلى 10.
على سبيل المثال ، إذا كان متوسط موضع الاستعلام هو 2.2 أو 2.9 ، فسيتم تسميته "2". من خلال التلاعب بمتوسط نطاق المركز ، يمكنك تحقيق الدقة التي تريدها.
بالنسبة لـ i في النطاق (1 ، 11):
query_df.loc [(query_df ['متوسط الموضع']> = i) & (
query_df ["متوسط الموضع"] <i + 1) ، "تسمية الموضع"] = i
الآن ، سنقوم بتجميع الاستعلامات بناءً على موقفهم. يساعدنا هذا في معالجة بيانات طلبات البحث عن موضع بطريقة أفضل في الخطوات التالية.
query_grouped_df = query_df.groupby (['تسمية الموقع'])
3. تصفية الاستعلامات بناءً على بياناتها لحساب منحنى نسبة النقر إلى الظهور (CTR)
أسهل طريقة لحساب منحنى نسبة النقر إلى الظهور (CTR) هي استخدام جميع بيانات الاستعلامات وإجراء الحساب. لكن؛ لا تنس التفكير في هذه الاستعلامات مع انطباع واحد في الموضع الثاني في بياناتك.
هذه الاستفسارات ، بناءً على تجربتي ، تحدث فرقًا كبيرًا في النتيجة النهائية. لكن أفضل طريقة هي أن تجربها بنفسك. بناءً على مجموعة البيانات ، قد يتغير هذا.
قبل أن نبدأ هذه الخطوة ، نحتاج إلى إنشاء قائمة لإخراج مخطط الشريط الخاص بنا و DataFrame لتخزين استعلاماتنا التي تم التلاعب بها.
# إنشاء DataFrame لتخزين بيانات 'query_df' التي تم التلاعب بها modified_df = pd.DataFrame () # قائمة لحفظ كل مركز تعني مخططنا الشريطي mean_ctr_list = []
بعد ذلك ، نقوم بإجراء حلقة عبر مجموعات query_grouped_df وإلحاق أعلى 20٪ من الاستعلامات بناءً على مرات الظهور بإطار DataFrame modified_df .
إذا لم يكن حساب نسبة النقر إلى الظهور استنادًا إلى أعلى 20٪ من الاستعلامات التي لها أكبر عدد من مرات الظهور هو الأفضل بالنسبة لك ، فيمكنك تغييره.
للقيام بذلك ، يمكنك your_optimal_number أو .quantile(q=your_optimal_number, interpolation='lower')] عن طريق معالجة.
على سبيل المثال ، إذا كنت تريد الحصول على أعلى 30٪ من طلبات البحث ، your_optimal_num هو الفرق بين 1 و 0.3 (0.7).
بالنسبة لـ i في النطاق (1 ، 11):
# محاولة باستثناء التعامل مع تلك المواقف التي لا يحتوي الدليل على أي بيانات لبعض المواضع
محاولة:
tmp_df = query_grouped_df.get_group (i) [query_grouped_df.get_group (i) ['مرات الظهور']> = query_grouped_df.get_group (i) ['مرات الظهور']
. الكمية (q = 0.8، الاستيفاء = "أقل")]
mean_ctr_list.append (tmp_df ['ctr']. يعني ())
updated_df = modified_df.append (tmp_df، ignore_index = True)
باستثناء KeyError:
mean_ctr_list.append (0)
# حذف "tmp_df" DataFrame لتقليل استخدام الذاكرة
ديل [tmp_df]
4. رسم مربع مؤامرة
هذه الخطوة هي ما كنا ننتظره. لرسم المخططات ، يمكننا استخدام Matplotlib ، seaborn كغلاف لـ Matplotlib ، أو Plotly.
أنا شخصياً أعتقد أن استخدام Plotly هو أحد أفضل الخيارات المناسبة للمسوقين الذين يحبون استكشاف البيانات.
بالمقارنة مع Mathplotlib ، فإن Plotly سهل الاستخدام وببضعة أسطر من التعليمات البرمجية ، يمكنك رسم مخطط جميل.
# 1.مؤامرة مربع
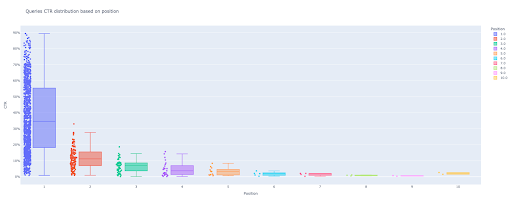
box_fig = px.box (modified_df، x = 'position label'، y = 'Site CTR'، title = 'Queries CTR Distribution بناءً على الموضع'،
النقاط = 'الكل' ، اللون = 'تسمية الموضع' ، الملصقات = {'تسمية الموضع': 'الموضع' ، 'نسبة النقر إلى الظهور للموقع': 'نسبة النقر إلى الظهور'})
# إظهار كل علامات التجزئة العشرة لمحاور x
box_fig.update_xaxes (tickvals = [i for i in range (1، 11)])
# تغيير تنسيق علامة المحاور y إلى نسبة مئوية
box_fig.update_yaxes (tickformat = ". 0٪")
# حفظ المؤامرة في دليل "إخراج الصور المؤامرة"
box_fig.write_image ('. / صور رسم الإخراج / رسم مربع الاستعلامات CTR curve.png')
باستخدام هذه الأسطر الأربعة فقط ، يمكنك الحصول على مخطط مربع جميل والبدء في استكشاف بياناتك.
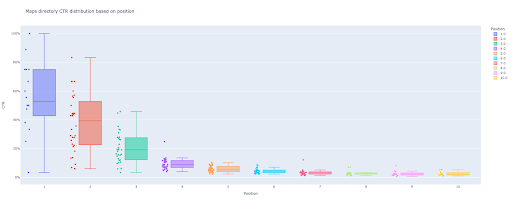
إذا كنت تريد التفاعل مع هذا العمود ، في تشغيل خلية جديدة:
box_fig.show ()
الآن ، لديك مخطط مربع جذاب في الإخراج يكون تفاعليًا.
عندما تحوم فوق مؤامرة تفاعلية في خلية الإخراج ، فإن الرقم المهم الذي تهتم به هو "الرجل" في كل موضع.
يوضح هذا متوسط نسبة النقر إلى الظهور لكل موضع. نظرًا للأهمية المتوسطة ، كما تتذكر ، نقوم بإنشاء قائمة تحتوي على متوسط كل منصب. بعد ذلك ، سننتقل إلى الخطوة التالية لرسم مخطط شريطي بناءً على متوسط كل موضع.
5. رسم مخطط شريط
مثل مخطط الصندوق ، يكون رسم مخطط الشريط أمرًا سهلاً للغاية. يمكنك تغيير title المخططات عن طريق تعديل وسيطة title في px.bar() .
# 2.مؤامرة شريط
bar_fig = px.bar (x = [pos for pos in range (1، 11)]، y = mean_ctr_list، title = "الاستعلامات تعني توزيع نسبة النقر إلى الظهور استنادًا إلى الموضع" ،
labels = {'x': 'Position'، 'y': 'CTR'}، text_auto = True)
# إظهار كل علامات التجزئة العشرة لمحاور x
bar_fig.update_xaxes (tickvals = [i for i in range (1، 11)])
# تغيير تنسيق علامة المحاور y إلى نسبة مئوية
bar_fig.update_yaxes (tickformat = '. 0٪')
# حفظ المؤامرة في دليل "إخراج الصور المؤامرة"
bar_fig.write_image ('. / صور رسم الإخراج / رسم شريط الاستعلامات CTR curve.png')
عند الإخراج نحصل على هذه المؤامرة:
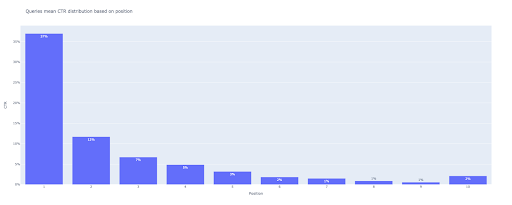
كما هو الحال مع مخطط الصندوق ، يمكنك التفاعل مع هذه المؤامرة عن طريق تشغيل bar_fig.show() .
هذا هو! من خلال بضعة أسطر من التعليمات البرمجية ، نحصل على معدل النقر من خلال العضوية استنادًا إلى الموضع مع بيانات الاستفسارات الخاصة بنا.

إذا كان لديك موقع URL لكل من النطاقات الفرعية أو الأدلة ، يمكنك الحصول على استعلامات خصائص عناوين URL هذه وحساب منحنى نسبة النقر إلى الظهور (CTR) لها.
[دراسة حالة] تحسين التصنيف والزيارات العضوية والمبيعات من خلال تحليل ملفات السجل
 اقرأ دراسة الحالة
اقرأ دراسة الحالةالطريقة الثانية: حساب منحنى نسبة النقر إلى الظهور (CTR) بناءً على عناوين URL للصفحات المقصودة لكل دليل
في الطريقة الأولى ، قمنا بحساب نسبة النقر إلى الظهور العضوية الخاصة بنا بناءً على نسبة النقر إلى الظهور لطلبات البحث ، ولكن باستخدام هذا النهج ، نحصل على جميع بيانات صفحاتنا المقصودة ثم نحسب منحنى نسبة النقر إلى الظهور (CTR) للأدلة التي اخترناها.
أنا أحب هذه الطريقة. كما تعلم ، تختلف نسبة النقر إلى الظهور لصفحات منتجاتنا كثيرًا عن تلك الموجودة في منشورات المدونة أو الصفحات الأخرى. كل دليل له نسبة النقر إلى الظهور الخاصة به بناءً على الموضع.
بطريقة أكثر تقدمًا ، يمكنك تصنيف كل صفحة دليل والحصول على معدل النقرات العضوية من Google استنادًا إلى موضع مجموعة من الصفحات.
1. الحصول على بيانات الصفحات المقصودة
تمامًا مثل الطريقة الأولى ، هناك عدة طرق للحصول على بيانات Google Search Console (GSC). في هذه الطريقة ، فضلت الحصول على بيانات الصفحات المقصودة من GSC API explorer على: https://developers.google.com/webmaster-tools/v1/searchanalytics/query.
لما هو مطلوب في هذا النهج ، لا توفر GDS بيانات صلبة للصفحة المقصودة. أيضًا ، يمكنك استخدام الوظيفة الإضافية "Search Analytics for Sheets" في جداول بيانات Google.
لاحظ أن Google API Explorer مناسب تمامًا لتلك المواقع التي تحتوي على أقل من 25 ألف صفحة من البيانات. بالنسبة للمواقع الأكبر حجمًا ، يمكنك الحصول على بيانات الصفحات المقصودة جزئيًا وربطها معًا ، أو كتابة نص برمجي Python مع حلقة "for" لإخراج جميع بياناتك من GSC ، أو استخدام أدوات الطرف الثالث.
للحصول على البيانات من Google API Explorer:
- انتقل إلى "تحليلات البحث: استعلام" صفحة وثائق GSC API: https://developers.google.com/webmaster-tools/v1/searchanalytics/query
- استخدم مستكشف API الموجود على الجانب الأيمن من الصفحة
- في حقل "siteUrl" ، أدخل عنوان خاصية URL ، مثل
https://www.example.com. يمكنك أيضًا إدراج ملكية المجال الخاص بك على النحو التاليsc-domain:example.com - في حقل "نص الطلب" ، أضف
startDateendDate. أفضل الحصول على بيانات الشهر الماضي. تنسيق هذه القيم هوYYYY-MM-DD - أضف
dimensionوقم بتعيين قيمه علىpage - أنشئ "DimFilterGroups" وتصفية الاستعلامات بأسماء مختلفة للعلامات التجارية (مع استبدال
brand_variation_namesبأسماء علامتك التجارية RegExp) - أضف
rawLimitعلى 25000 - في النهاية اضغط على الزر "تنفيذ"
يمكنك أيضًا نسخ نص الطلب ولصقه أدناه:
{
"تاريخ البدء": "2022-01-01"،
"endDate": "2022-02-01"،
"أبعاد": [
"صفحة"
] ،
"DimFilterGroups": [
{
"الفلاتر": [
{
"البعد": "QUERY" ،
"تعبير": "brand_variation_names"،
"عامل التشغيل": "EXCLUDING_REGEX"
}
]
}
] ،
"rowLimit": 25000
}
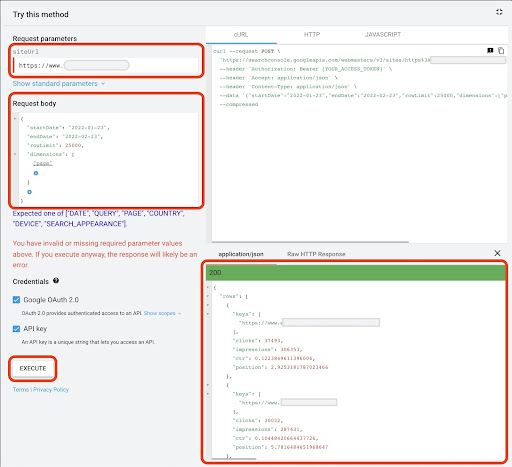
بعد تنفيذ الطلب ، نحتاج إلى حفظه. بسبب تنسيق الاستجابة ، نحتاج إلى إنشاء ملف JSON ، ونسخ جميع استجابات JSON ، وحفظه باستخدام اسم الملف الذي تم downloaded_data.json data.json.
إذا كان موقعك صغيرًا ، مثل موقع شركة SASS ، وكانت بيانات صفحتك المقصودة أقل من 1000 صفحة ، فيمكنك بسهولة تعيين تاريخك في GSC وتصدير بيانات الصفحات المقصودة لعلامة التبويب "PAGES" كملف CSV.
2. تحميل بيانات الصفحات المقصودة
من أجل هذا البرنامج التعليمي ، سأفترض أنك تحصل على بيانات من Google API Explorer وتحفظها في ملف JSON. لتحميل هذه البيانات علينا تشغيل الكود أدناه:
# إنشاء DataFrame للبيانات التي تم تنزيلها
بفتح ('./ download_data.json') مثل json_file:
landings_data = json.loads (json_file.read ()) ['صفوف']
landings_df = pd.DataFrame (landings_data)
بالإضافة إلى ذلك ، نحتاج إلى تغيير اسم العمود لمنحه معنى أكبر وتطبيق وظيفة للحصول على عناوين URL للصفحة المقصودة مباشرةً في عمود "الصفحة المقصودة".
# إعادة تسمية عمود "المفاتيح" إلى عمود "الصفحة المقصودة" وتحويل قائمة "الصفحة المقصودة" إلى عنوان URL
landings_df.rename (الأعمدة = {'keys': 'landing page'}، inplace = True)
landings_df ['الصفحة المقصودة'] = landings_df ["الصفحة المقصودة"]. تنطبق (lambda x: x [0])
3. الحصول على كافة الدلائل الجذرية للصفحات المقصودة
بادئ ذي بدء ، نحتاج إلى تحديد اسم موقعنا.
# تحديد اسم موقعك بين الاقتباسات. على سبيل المثال ، "https://www.example.com/" أو "http://mydomain.com/" site_name = "
ثم نقوم بتشغيل وظيفة على عناوين URL للصفحة المقصودة للحصول على أدلة الجذر الخاصة بهم ورؤيتهم في الإخراج لاختيارهم.
# الحصول على دليل كل صفحة مقصودة (URL)
landings_df ['directory'] = landings_df ['الصفحة المقصودة']. str.extract (pat = f '(((؟ <= {site_name}) [^ /] +)')
# للحصول على جميع الأدلة في المخرجات ، نحتاج إلى معالجة خيارات Pandas
pd.set_option ("display.max_rows" ، بلا)
# أدلة الموقع
landings_df ['دليل']. value_counts ()
بعد ذلك ، نختار الدلائل التي نحتاج إلى الحصول على منحنى نسبة النقر إلى الظهور لها.
أدخل الدلائل في متغير الدلائل important_directories .
على سبيل المثال ، product,tag,product-category,mag . افصل قيم الدليل بفاصلة.
أدلة_مهمة = "
important_directories = important_directories.split ('،')
4. وصف الصفحات المقصودة وتجميعها
مثل الاستعلامات ، نقوم أيضًا بتصنيف الصفحات المقصودة بناءً على متوسط موضعها.
# تسمية موقف الصفحات المقصودة
بالنسبة لـ i في النطاق (1 ، 11):
landings_df.loc [(landings_df ['position']> = i) & (
landings_df ['position'] <i + 1)، 'position label'] = i
بعد ذلك ، نقوم بتجميع الصفحات المقصودة بناءً على "دليلها".
# تجميع الصفحات المقصودة بناءً على قيمة "الدليل" landings_grouped_df = landings_df.groupby (['دليل'])
5. إنشاء مخططات مربعة وشريطية لأدلةنا
في الطريقة السابقة ، لم نستخدم وظيفة لإنشاء المؤامرات. لكن؛ لحساب منحنى نسبة النقر إلى الظهور (CTR) للصفحات المقصودة المختلفة تلقائيًا ، نحتاج إلى تحديد وظيفة.
# وظيفة إنشاء وحفظ كل مخططات الدليل
def each_dir_plot (dir_df ، مفتاح):
# تجميع الصفحات المقصودة للدليل بناءً على قيمة "تسمية الموضع"
dir_grouped_df = dir_df.groupby (["تسمية الموقع"])
# إنشاء إطار بيانات لتخزين البيانات التي تمت معالجتها 'dir_grouped_df'
updated_df = pd.DataFrame ()
# قائمة لحفظ كل مركز تعني مخططنا الشريطي
mean_ctr_list = []
""
التكرار على مجموعات "query_grouped_df" وإلحاق أهم 20٪ من الاستعلامات بناءً على مرات الظهور في DataFrame "modified_df".
إذا لم يكن حساب نسبة النقر إلى الظهور استنادًا إلى أعلى 20٪ من الاستعلامات التي لها أكبر عدد من مرات الظهور هو الأفضل بالنسبة لك ، فيمكنك تغييره.
لتغييره ، يمكنك زيادته أو إنقاصه عن طريق معالجة '. quantile (q = your_optimal_number، interpolation =' less ')]'.
يجب أن يكون "you_optimal_number" بين 0 إلى 1.
على سبيل المثال ، إذا كنت تريد الحصول على أعلى 30٪ من طلبات البحث ، فإن "your_optimal_num" هو الفرق بين 1 و 0.3 (0.7).
""
بالنسبة لـ i في النطاق (1 ، 11):
# محاولة باستثناء التعامل مع تلك المواقف التي لا يحتوي الدليل على أي بيانات لبعض المواضع
محاولة:
tmp_df = dir_grouped_df.get_group (i) [dir_grouped_df.get_group (i) ['impressions']> = dir_grouped_df.get_group (i) ['مرات الظهور']
. الكمية (q = 0.8، الاستيفاء = "أقل")]
mean_ctr_list.append (tmp_df ['ctr']. يعني ())
updated_df = modified_df.append (tmp_df، ignore_index = True)
باستثناء KeyError:
mean_ctr_list.append (0)
# 1.مؤامرة مربع
box_fig = px.box (modified_df، x = 'position label'، y = 'ctr'، title = f '{key} توزيع CTR للدليل استنادًا إلى الموضع' ،
النقاط = 'الكل' ، اللون = 'تسمية الموضع' ، الملصقات = {'تسمية الموضع': 'الموضع' ، 'ctr': 'CTR'})
# إظهار كل علامات التجزئة العشرة لمحاور x
box_fig.update_xaxes (tickvals = [i for i in range (1، 11)])
# تغيير تنسيق علامة المحاور y إلى نسبة مئوية
box_fig.update_yaxes (tickformat = ". 0٪")
# حفظ المؤامرة في دليل "إخراج الصور المؤامرة"
box_fig.write_image (f './ output plot images / {key} directory-Box plot CTR curve.png')
# 2.مؤامرة شريط
bar_fig = px.bar (x = [pos for pos in range (1، 11)]، y = mean_ctr_list، title = f '{key} directory يعني توزيع نسبة النقر إلى الظهور استنادًا إلى الموضع' ،
labels = {'x': 'Position'، 'y': 'CTR'}، text_auto = True)
# إظهار كل علامات التجزئة العشرة لمحاور x
bar_fig.update_xaxes (tickvals = [i for i in range (1، 11)])
# تغيير تنسيق علامة المحاور y إلى نسبة مئوية
bar_fig.update_yaxes (tickformat = '. 0٪')
# حفظ المؤامرة في دليل "إخراج الصور المؤامرة"
bar_fig.write_image (f './ output plot images / {key} directory-Bar plot CTR curve.png')
بعد تحديد الوظيفة أعلاه ، نحتاج إلى حلقة "for" للتكرار فوق بيانات الدلائل التي نريد الحصول على منحنى CTR لها.
# التكرار على الدلائل وتنفيذ وظيفة "each_dir_plot"
للمفتاح ، عنصر في landings_grouped_df:
إذا كان المفتاح في الدلائل الهامة:
each_dir_plot (عنصر ، مفتاح)
في الإخراج ، نحصل على المؤامرات في مجلد output plot images .
نصيحة متقدمة!
يمكنك أيضًا حساب منحنيات CTR للأدلة المختلفة باستخدام صفحة الاستعلامات المقصودة. مع بعض التغييرات في الوظائف ، يمكنك تجميع الاستعلامات بناءً على أدلة الصفحات المقصودة.
يمكنك استخدام نص الطلب أدناه لتقديم طلب API في API Explorer (لا تنسَ حد 25000 صف):
{
"تاريخ البدء": "2022-01-01"،
"endDate": "2022-02-01"،
"أبعاد": [
"استفسار"،
"صفحة"
] ،
"DimFilterGroups": [
{
"الفلاتر": [
{
"البعد": "QUERY" ،
"تعبير": "brand_variation_names"،
"عامل التشغيل": "EXCLUDING_REGEX"
}
]
}
] ،
"rowLimit": 25000
}
نصائح لتخصيص حساب منحنى نسبة النقر إلى الظهور (CTR) باستخدام بايثون
للحصول على بيانات أكثر دقة لحساب منحنى نسبة النقر إلى الظهور ، نحتاج إلى استخدام أدوات الطرف الثالث.
على سبيل المثال ، إلى جانب معرفة الاستعلامات التي تحتوي على مقتطف مميز ، يمكنك استكشاف المزيد من ميزات SERP. أيضًا ، إذا كنت تستخدم أدوات جهات خارجية ، فيمكنك الحصول على زوج من الاستعلامات بترتيب الصفحة المقصودة لهذا الاستعلام ، بناءً على ميزات SERP.
بعد ذلك ، قم بتسمية الصفحات المقصودة بدليل الجذر (الأصل) ، وتجميع الاستعلامات بناءً على قيم الدليل ، مع مراعاة ميزات SERP ، وأخيراً تجميع الاستعلامات بناءً على الموضع. بالنسبة لبيانات نسبة النقر إلى الظهور ، يمكنك دمج قيم نسبة النقر إلى الظهور من GSC إلى استعلامات نظرائهم.