
أهمية الشبكة الدلالية لتحسين محركات البحث (SEO): إنشاء شبكات محتوى دلالية باستخدام قوالب الاستعلام والوثائق - دراسة حالة
نشرت: 2022-01-11ترتبط الشبكة الدلالية بمفهوم قاعدة المعرفة التي يمكن أن تمثل معلومات في العالم الحقيقي للأشياء التي لها روابط علائقية. يمكن أن تحتوي قاعدة المعرفة على آلاف أنواع العلاقات مع مليارات الكيانات وتريليونات الحقائق. يمكن إنشاء شبكة دلالية من أي وجود في العالم الحقيقي بسمات متبادلة مثل الوزن أو الحجم أو النوع أو الرائحة أو اللون. يتم إنشاء العلاقة بين الشبكات الدلالية والويب الدلالي بواسطة محركات البحث الدلالية والتحسين.
تُستخدم الشبكات الدلالية في التحليل الدلالي ، وإلغاء غموض معنى الكلمات ، وإنشاء WordNet ، ونظرية الرسم البياني ، ومعالجة اللغة الطبيعية ، والفهم ، والتوليد. يمكن استخدام منظور الشبكة الدلالية في تحسين محرك البحث الدلالي من خلال توفير شبكة محتوى دلالية.
في دراسة حالة تحسين محركات البحث هذه ، سيتم شرح موقعين مختلفين على الويب بطريقتين مختلفتين بنفس المنظور بناءً على قوالب الاستعلام والمستند والنية وأزواج سمات الكيان التي تقف وراءها.
باستخدام فهم كيفية تمثيل محركات البحث للمعرفة وكيفية توسيع تمثيلها للمعرفة ، يمكنني الاستفادة من ذلك لإنتاج نتائج تصنيف مذهلة. بمجرد فهمك للمفاهيم الأساسية ، سأشرح كيف قمت بتطبيقها على موقعين مختلفين ، وبعد ذلك سأفصل الطرق التي استخدمتها.
كيف يمكن للشبكات الدلالية أن تساعد في ترتيب موقع الويب الخاص بك؟
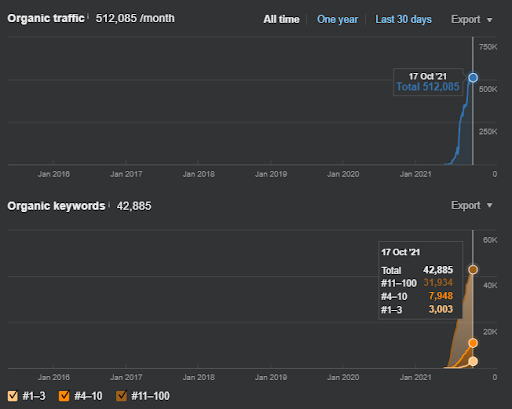
أدناه ، ستجد النتائج الأولية الإجمالية للمشروع الأول.
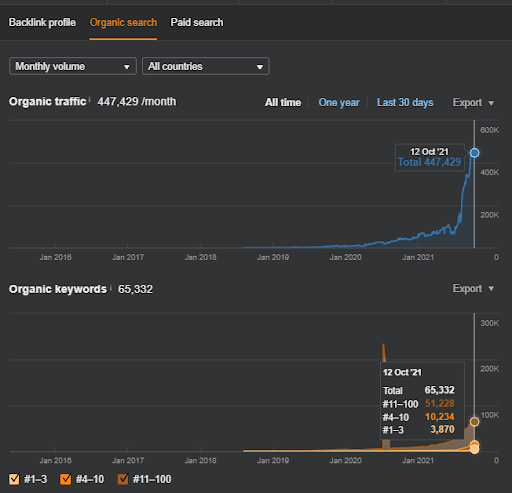
نتائج المشروع الأول وهو IstanbulBogaziciEnstitu.com. لإثبات أن "الشبكات الدلالية" يمكن استخدامها لتحسين محركات البحث مع قوالب الاستعلام والمستندات ، سأعرض شبكتي محتوى مختلفتين من Project One. سيحقق المشروع الأول نتائج أفضل بكثير في المستقبل القريب بفضل شبكة المحتوى الدلالية الثانية. سيكون العميل مسؤولاً عن نشر هذه الشبكة الثانية ، لكنني سأشرح منطقها أيضًا.
بعد 17 يومًا ، إليك التقدم المحرز في المشروع الأول: 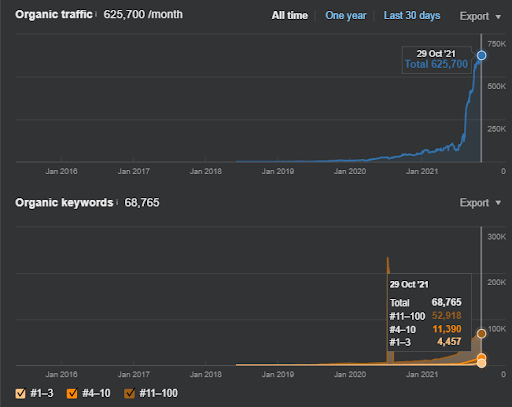
بعد 17 يومًا ، أصبحت عملية إعادة ترتيب شبكة المحتوى الدلالية أكثر وضوحًا.
تساعدنا مفاهيم شبكة المحتوى الدلالية على فهم قيمة الاستعلام ونية البحث والسلوك وقوالب المستندات للكيانات من نفس النوع. في دراسة حالة تحسين محركات البحث (SEO) التي تركز على الشبكة الدلالية ، سيتم تعميق السلطة الموضوعية السابقة ودراسة حالة تحسين محركات البحث الدلالية عبر موقعي الويب الجديدين اللذين يستخدمان شبكات محتوى تم إنشاؤها معنويًا حول نفس أنواع الكيانات.
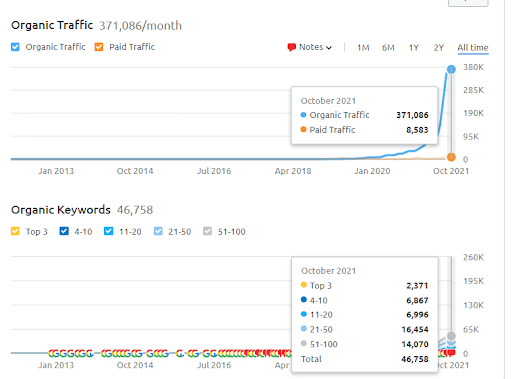
هذا هو رسم SEMRush للمشروع الأول. يجب أن أذكر أيضًا أن هذا الموقع قد فقد تحديث الخوارزمية الأساسية لشهر يونيو ، إذا لم يفقد "قابلية التصنيف" ، فستكون النتائج أفضل. بالنسبة لتحديث الخوارزمية واسع النطاق التالي ، مع وجود سلطة موضعية وتغطية وبيانات تاريخية أفضل ، يمكن استعادة "قابلية التصنيف" بسهولة.
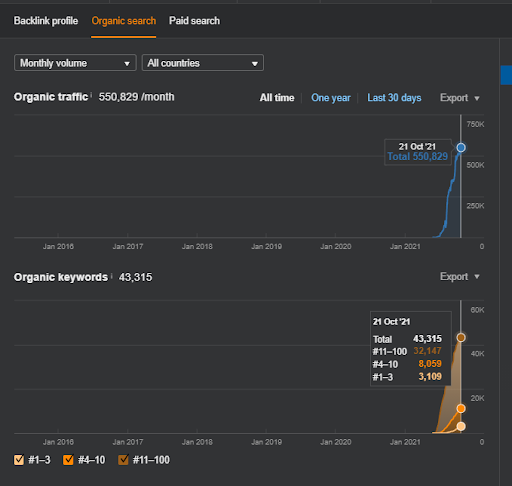
اسم المشروع الثاني هو Vizem.net. على عكس Project One ، يمكنك أن ترى أن Vizem.net لديه زيادة أبطأ ولكن ثابتة. ذلك لأنهم يستخدمون شبكات المحتوى الدلالية ذات وجهات نظر مختلفة قليلاً. أدناه ، يمكنك رؤية نتائج Ahrefs للمشروع الثاني.
تمثل نتائج المشروع الثاني "عملية إعادة ترتيب بطيئة" من خلال تحسين التغطية الموضوعية والسلطة تدريجياً. سيتم شرح المصطلحين "إعادة الترتيب" و "الترتيب الأولي" بعد المفاهيم المتعلقة بشبكات المحتوى الدلالي. إذا أدركت "الاستقرار" في الرسومات ، فذلك لأنني توقفت عن نشر محتوى جديد في المصدر. كما أنه يؤثر على عملية إعادة الترتيب كما تدرك من أعداد أهم 3 طلبات بحث. يمكن العثور على علاقات "الزخم" و "إعادة الترتيب" بعد تفسيرات المفاهيم الأساسية.
أدناه ، يمكنك العثور على نتائج SEMRush الخاصة بـ Vizem.net.
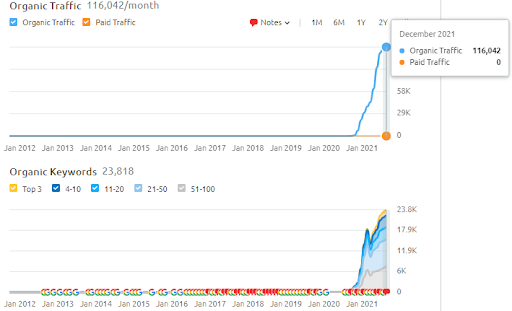
حركة المرور الفعلية لهذا الموقع هي 3 أضعاف الرقم المذكور في SEMRush. يمكنك أن تدرك نفس "الاستقرار" ومفاهيم "الزخم" في هذه الرسوم البيانية أيضًا.
أثناء كتابة دراسة حالة Topical Authority SEO ، شكرت Bill Slawski لتثقيفه وجهة نظري. أكرر ذلك أيضًا في دراسة حالة تحسين محركات البحث لشبكة المحتوى الدلالية. لفهم مفهومي "إعادة الترتيب" و "الترتيب الأولي" ، يجب قراءة "الطرق التي يمكن لمحركات البحث بها إعادة ترتيب نتائج البحث".
في 18 مارس 2021 ، نشرت Oncrawl و RankSense و Holistic SEO & Digital ندوة عبر الويب لـ Python SEO و Data Science. في الندوة عبر الإنترنت ، تم تسجيل SERP لتحريك اختلافات النتائج. يمكن ملاحظة أن محرك البحث يغير ترتيب بعض المصادر مع مصادر أخرى ذات تكرار مماثل.
قبل أن أكمل أكثر ، أعلم أن هذا مقال طويل. ولكن ، في الواقع هذا شرح موجز لمنهجية مُحسّنات محرّكات البحث شديدة التعقيد. تتطلب شبكات المحتوى الدلالية الكثير من التفكير أثناء تصميمها ، وشهورًا من التعليم للعملاء والمؤلفين ، بالإضافة إلى الإعداد. وبالتالي ، في هذه المقالة ، أود التركيز على تعاريف المفاهيم مع أفضل الاقتراحات الموجزة القابلة للتنفيذ الممكنة وجوجل المهم ، وبراءات اختراع محركات البحث الأخرى ، والأوراق البحثية جنبًا إلى جنب مع المفاهيم الخاصة بهم. في النسخة الطويلة (كتاب بشكل أساسي) ، ركزت على "الترتيب الأولي" و "إعادة الترتيب" لشبكات المحتوى الدلالية.
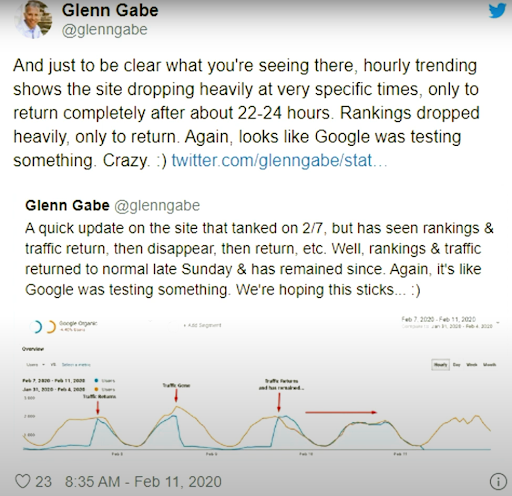
اعتبارًا من 11 فبراير 2020 ، يعد Glenn Gabe مثالًا جيدًا لمنهجية إعادة الترتيب والاختبار الخاصة بمحركات البحث بصريًا.
إذا كنت تريد معرفة المزيد ، فاقرأ "أهمية الترتيب الأولي وإعادة الترتيب لتحسين محركات البحث".
للتعمق في بيانات العالم الحقيقي لدراسة حالة تحسين محركات البحث ، يجب معالجة مفاهيم فهم شبكة المحتوى الدلالي من منظور فهم واتصالات محرك البحث.
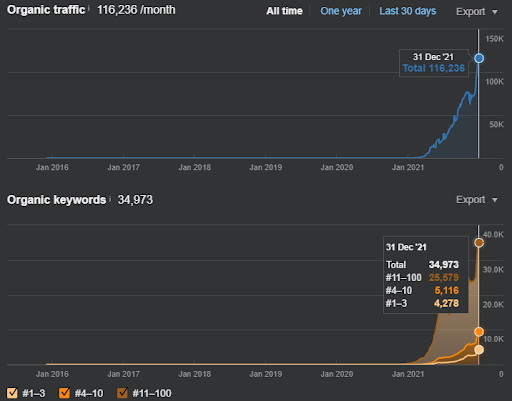
كمثال لإعادة ترتيب Vizem.net ، يمكن رؤية الوضع المحدث أعلاه. في الأقسام المستقبلية من دراسة حالة تحسين محركات البحث ، سيكون هناك المزيد من التفسيرات لخوارزميات إعادة الترتيب الخاصة بـ Google لـ SEO.
ما هي الشبكة الدلالية؟
يمكن استخدام الشبكة الدلالية لربط وتحليل إنترنت الأشياء. يمكن أن يكون مفيدًا للتعرف على المشترين المحتملين في سوق التكنولوجيا ، أو مجرد تحليل الكلمات المشتركة لإنشاءات شبكة الكلمات الرئيسية والتكتلات. يمكن استخدام الشبكة الدلالية لدعم الملاحة وكشف بنية العلاقات ، أو الأهمية النسبية لشيء ما لشيء آخر. تحتوي الشبكة الدلالية على المكونات التالية:
- الدلالات المعجمية: فهم الكلمة والمفهوم المرتبطين بأي منها ، مع أي اختلافات.
- المكون الهيكلي: فهم العقدة المتصلة بأي حافة بأي معلومات.
- المكون الدلالي: تعريف الحقائق.
- الجزء الإجرائي: يساعد على إنشاء مزيد من الروابط بين المكونات.
نظرًا لأن الشبكات الدلالية متعددة الأغراض ، يمكن أيضًا استخدام خوارزميات البرمجة اللغوية العصبية لأغراض متنوعة للغاية ، مثل المساعدة في تحديد المشكلات الصحية المعقدة. يمكن تنفيذ نفس بنية الشبكة الدلالية في مناطق أخرى متعددة طالما أن هذه المناطق الأخرى لها علاقة دلالية بين بعضها البعض.
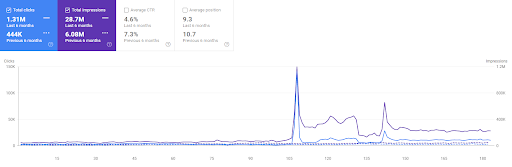
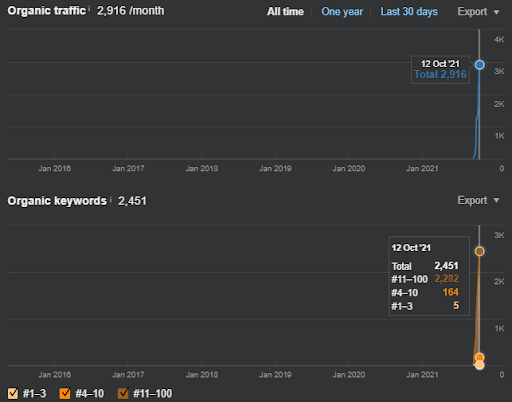
مقارنة آخر 6 أشهر للمشروع الأول.
ما هي قاعدة المعرفة؟
قاعدة المعرفة هي مكتبة معلومات ذات تصنيف في شكل يمكن قراءته آليًا. يمكن استخدام قاعدة المعرفة كموسوعة يمكن تضييقها وتعميقها بناءً على الاستعلام. يمكن تشكيل قاعدة المعرفة على أساس المقترحات واستخراج الحقائق واستخراج المعلومات. العلاقة بين الشبكة الدلالية وقاعدة المعرفة هي أن كل ما هو موجود في الشبكة الدلالية سيتم وضعه في قاعدة المعرفة أثناء استخراج الحقائق.
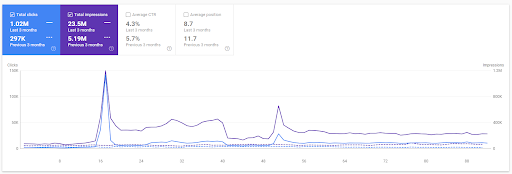
مقارنة آخر 3 أشهر للمشروع الأول
ما هي شبكة المحتوى الدلالية؟
تمثل شبكة المحتوى الدلالية شبكة محتوى تم إعدادها بناءً على مكونات الشبكة الدلالية والفهم. يمكن أن تتضمن شبكة المحتوى الدلالية سمات متعددة من كيان أو كيانات من نفس المجموعة من أجل توفير قاعدة معرفية بمزيد من التفاصيل.
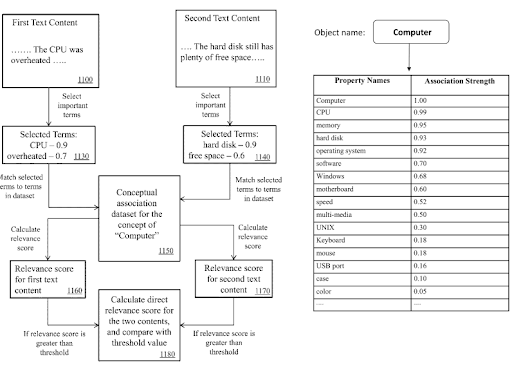
ضمن شبكة المحتوى الدلالي ، يمكن استخدام شروط مجال المعرفة والمضاعفات الثلاثية للإشارة إلى الغرض الرئيسي للوثيقة وأجزاء المحتوى المجاورة المحتملة.
يمكن لمحرك البحث مقارنة قاعدة المعرفة الخاصة به بقاعدة المعرفة التي يمكن إنشاؤها من محتوى موقع الويب. إذا كان موقع الويب يتمتع بمستوى عالٍ من الدقة والشمولية لطبقات سياقية مختلفة ، فيمكن لمحرك البحث تحسين قاعدة المعرفة الخاصة به من محتوى موقع الويب. إذا قام محرك بحث بتحسين وتوسيع قاعدة المعارف الخاصة به من مصدر آخر على شبكة الويب المفتوحة ، فإن ذلك يعد إشارة على مستوى عالٍ من الثقة القائمة على المعرفة.
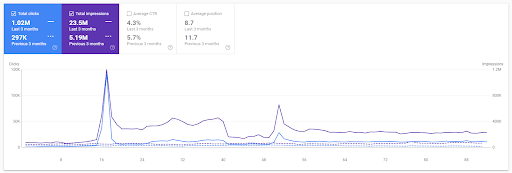
مقارنة على أساس سنوي لآخر 3 أشهر بناءً على المشروع الأول.
ما هي الثقة القائمة على المعرفة؟
تركز الثقة القائمة على المعرفة على شبكة الإنترنت المفتوحة على أساس "دقة المعلومات" ، وليس "نظام ترتيب الصفحات". إنها خوارزمية مشابهة لـ RankMerge. تتضمن الثقة القائمة على المعرفة ثلاثة توائم ، واستخراج الحقائق ، والتحقق من الدقة ، وفهم النص عن طريق إزالة غموض النص. يمكن اكتساب الثقة القائمة على المعرفة من خلال توفير شبكات المحتوى الدلالية التي تحتوي على مكونات مرتبطة بقوة داخل المقالة ، بناءً على طبقات سياقية مختلفة ولكنها ذات صلة.
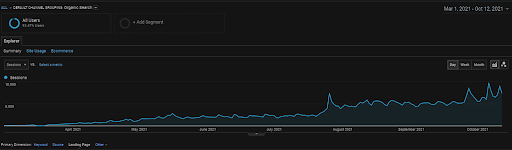
الجلسة العضوية لـ Vizem.net من GA لآخر 6 أشهر.
أدناه ، سترى مثالاً لعرض Trust-based Trust التقديمي من Luna Dong. يوضح كيف يمكن لمحرك البحث التركيز على "عوامل الترتيب الداخلية" بدلاً من عوامل الترتيب الخارجية. يوضح أن نظام ترتيب الصفحات المرتفع لا يمكن أن يمثل جودة عالية ودقة للمحتوى في حد ذاته. لذا ، فإن وجود KBT (الثقة القائمة على المعرفة) أمر مهم.
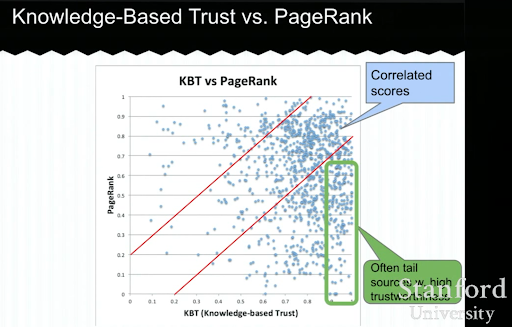
شكراً جزيلاً لـ Arnout Hellemans الذي شاركني هذه المحاضرة التعليمية أثناء محادثة SEO خاصة. إذا كنت تريد معرفة المزيد عن Trust-Based Trust: Stanford Seminar - Knowledge Vault and Knowledge-Based Trust
ما هي التغطية السياقية؟
التغطية السياقية والتغطية الموضوعية ليسا نفس مجال المعرفة والمجال السياقي ليسا متماثلين. تمثل التغطية السياقية زوايا معالجة المفهوم. يمكن معالجة المفهوم بناءً على النقاط المشتركة للأشياء الأخرى. على سبيل المثال ، إذا كان الكيان بلدًا ، فيمكن معالجة موقفه من الأزمة البيئية. إذا تمت معالجة البلدان الأخرى من نفس الزاوية ، فهذا يعني أننا نغطي مجالًا سياقيًا.

يبني محرك بحث Google أوراقه البحثية وبراءات الاختراع بمرور الوقت. الاقتباس الأيمن من القسم أعلاه هو سمة لـ "متجهات السياق" بينما القسم الأيسر هو سمة لـ "تصنيف العبارة". الشيء المثير للاهتمام هو أنه حتى المثال هو نفسه ، وهو "الكاميرا الرقمية".
تمثل التفاصيل والأجزاء الفرعية العميقة من هذه المجموعات الطبقات السياقية ضمن مجال سياقي. كل كيان سواء تم تسميته أم لا ، له العديد من المجالات السياقية. وبالتالي ، يستخرج Google المزيد من المجالات السياقية ويبحث المستخدمون عن استعلامات أطول كل عام. عندما يتم تطوير معالجة اللغة الطبيعية وفهم اللغة الطبيعية ، تتوسع الاستعلامات والمستندات معًا من حيث التفاصيل والسياق.
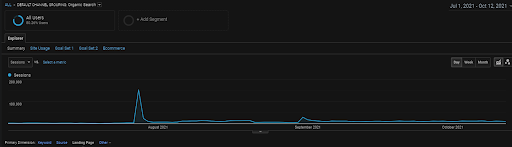
رسم جلسات GA العضوية للأشهر الأربعة الأخيرة من مشروع BogaziciEnstitu. نظرًا "لمرحلة الحصول على البيانات التاريخية" للمشروع ، فإن التفاصيل المتزايدة ليست واضحة حتى يمكن اعتبارها خطية.
يمكن فهم التغطية السياقية من خلال "محددات السياق". يمكن أن يكون مؤهل السياق صفة أو ظرفًا أو أي حرف جر آخر مثل العبارات التي تبدأ بـ "من أجل ، في ، في ، أثناء ، بينما". الأسئلة المتعلقة بالكيان أدناه ليست هي نفسها من حيث المجال السياقي:
- ما هي أكثر الفواكه فائدة للأطفال المصابين بالأرق؟
- ما هي أكثر الفواكه فائدة للأطفال الذين يعانون من القلق؟
الأسئلة المتعلقة بالكيان أدناه ليست هي نفسها من حيث الطبقة السياقية:
- ما هي أكثر الفواكه فائدة للأطفال الذين يعانون من الأرق الشديد فوق سن 6 سنوات؟
- ما هي الفاكهة الأكثر فائدة للأطفال الذين يعانون من قلق منخفض المستوى دون سن 6 سنوات؟
الأسئلة المتعلقة بالكيان أدناه ليست هي نفسها من حيث مجالات المعرفة:
- ما هي أكثر الكتب فائدة للأطفال الذين يعانون من الأرق الشديد فوق سن 6 سنوات؟
- ما هي الألعاب الأكثر فائدة للأطفال الذين يعانون من قلق منخفض المستوى دون سن 6 سنوات؟
ولكن يمكن أن تكون كل هذه الأسئلة في نفس شبكة المحتوى الدلالي لأنها تدور حول نفس "المفهوم" و "منطقة الاهتمام" مع نشاط بحث مماثل ونشاط في العالم الواقعي المرتبط بالبحث.
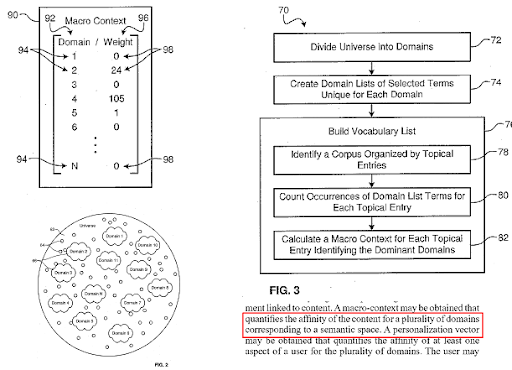
يقسم محرك البحث الويب إلى مجالات معرفة مختلفة ، ويحسب درجات السياق الكلي والجزئي لمصدر وصفحة ويب وقسم صفحة ويب في نفس الوقت.
أعلم أن لدي الكثير من المفاهيم الجديدة لك ، وبما أن هذه هي النسخة المختصرة من هذه المقالة ، فلن أتمكن من التحدث عن كل شيء هنا ، ولكن في دورة تحسين محركات البحث الدلالية المستقبلية ، سأقوم بمعالجة هذه الأشياء مثل الفرق بين "نشاط البحث" و "نشاط العالم الحقيقي المرتبط بالبحث".
دعونا نستمر قليلاً في الأمور الأكثر واقعية.
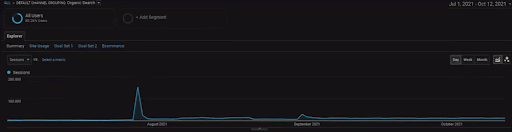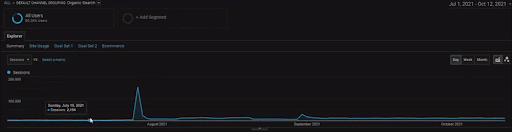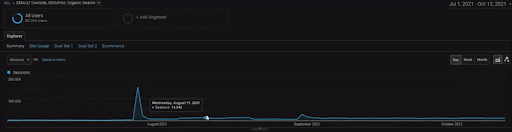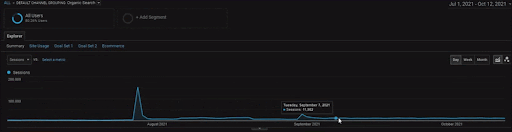
لإظهار تفاصيل مشروع BogaziciEnstitu ، يمكنك التحقق من إصدار الصورة التفاعلية. أصبحت عملية الاختبار وإعادة الترتيب لمحركات البحث أكثر وضوحًا في هذا المشروع بعد حدث مصدر البيانات التاريخي.
كيف ترتبط MuM بشبكات المحتوى الدلالية؟
يقوم التعلم متعدد المهام باستخدام محول موحد أو النموذج الموحد متعدد المهام بتدريب نماذج اللغة لتقييم المدخلات المرئية ، بالإضافة إلى النص. إنه قادر على إنشاء نص مع الفهم. بالإضافة إلى ذلك ، فإن MuM حيادي اللغة ، بمعنى آخر ، يعتمد SEO الدلالي على مهارة اللغة ، لكنه لا يقتصر على لغة. نظرًا لأن الكيانات ليس لها لغة ومعنى عالميًا ، فإن MuM تستفيد من المعلومات من لغات متعددة وسياقات متعددة في قاعدة معرفية واحدة.
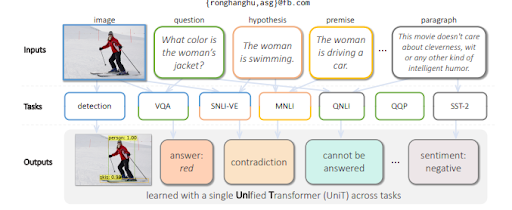
للإجابة على الأسئلة من الصورة المرئية ، يقوم MuM بإنشاء أسئلة بناءً على الكائنات المكتشفة داخل الصورة. في المستقبل القريب ، سيكون من الممكن أيضًا طرح الأسئلة المتعلقة بالصوت والفيديو.
يستخدم MuM مجالات مختلفة لاكتشاف الكائنات وفهم اللغة الطبيعية من خلال بنية وحدة فك ترميز المحولات. يأتي كل إدخال من منطقة مختلفة من الويب المفتوح بينما يتم تقييمهم جميعًا من وحدة فك ترميز مشتركة واحدة. أدناه ، سوف تكون قادرًا على رؤية مثال آخر من ورقة البحث.
كملاحظة ، يمكن أن يكون MuM أقوى 1000 مرة من BERT ، ولكن لا يزال يستخدم BERT داخل Text Encoder لـ MuM. الميزة الرئيسية لـ MuM هي أنه يمكن استخدامه للعناصر المرئية ، والصوت مباشرة ، ولهذا السبب يمكن تسميته نموذج "متعدد المهام". الميزة الثانية هي أنه يزيل كل حواجز اللغة بشكل مباشر. الميزة الثالثة هي أنه قادر على توصيل كل شيء بشيء آخر دون الحاجة إلى وسطاء إضافيين. الميزة الرابعة هي أن MuM يمكنه إنشاء نص أيضًا ، على عكس BERT.
العلاقة بين MuM وقاعدة المعرفة والشبكات الدلالية والتغطية السياقية هو أن محرك البحث قادر على العثور على مجال سياقي أكثر من خلال مؤهلات السياق ومجموعاتها مع مجالات المعرفة المحتملة. وبالتالي ، يمكن لشبكة المحتوى الدلالية جيدة التنظيم التي تم تشكيلها باستخدام خريطة موضوعية مناسبة وسياق المصدر تحسين ثقة قاعدة المعرفة ، جنبًا إلى جنب مع السلطة الموضوعية.
ما هو سياق المصدر؟
يمثل سياق المصدر شيئين. إنترنت البحث المركزي للمصدر ، ونشاط البحث المركزي الذي يمكن إجراؤه باستخدام نشاط البحث ذي الصلة. بالنسبة إلى موقع ويب للتجارة الإلكترونية ، فإن سياق المصدر هو شراء منتج معين أو نوع معين من المنتجات. إذا كان موقعًا للسفر ، فإن سياق المصدر ينتقل إلى مكان ما من مكان آخر لأنواع مختلفة من الأطعمة أو المناظر الطبيعية أو الأعمال فقط. بناءً على سياق المصدر ، سيحتاج تصميم شبكة المحتوى الدلالي وخريطة الموضوع إلى مزيد من التهيئة. يتطلب هذا اختيار الأقسام المركزية داخل الخريطة الموضعية ، والأقسام التكميلية داخل الخريطة الموضعية.
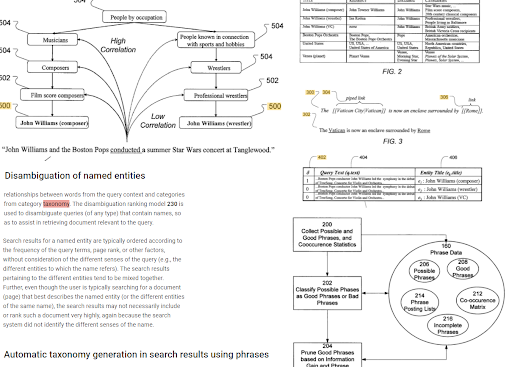
ترتبط الفهرسة المبنية على العبارة وفهم البحث الموجه للكيان ببعضهما البعض بناءً على الدلالات. أعلاه ، يمكن رؤية "توضيح الكيان المحدد" و "إنشاء التصنيف التلقائي في نتائج البحث باستخدام العبارات" معًا لتحديد "السياق". ستساعد العبارات الجيدة والمعلومات الفريدة والمترابطة لموضوع ما في تحسين الترتيب الأولي وإعادة الترتيب.
مرة أخرى ، بعض هذه المفاهيم ، "تكوين الخريطة الموضعية" ، "تصميم شبكة المحتوى الدلالي" لم يتم تحديدها بعد ، وهذا ليس المكان المناسب لذلك. ولكن ، تم شرح نشاط البحث ذي الصلة جنبًا إلى جنب مع هدف البحث الأساسي والعبارات التمثيلية لأهداف البحث الأساسية هذه.
خلفية دراسة حالة SEO المركزة على الشبكة الدلالية
بناءً على المفاهيم المذكورة أعلاه ، استخدمت الشبكات الدلالية لإنشاء دراسة حالة لتحسين محركات البحث. سنلقي نظرة على مشروعي موقع الويب اللذين ذكرتهما في بداية هذه المقالة ونفحص النتائج ، وكيف قمت بتنفيذ الشبكات الدلالية لإنتاجها.
لإعطائك فكرة عن مدى قوة هذه الشبكات ، يتم سرد النتائج المتعلقة بـ SEO لدراسة حالة SEO التي تركز على الشبكة الدلالية أدناه.
- يعد فهم الشبكة الدلالية ضرورة لإنشاء خريطة موضوعية مناسبة.
- بالنسبة لكلا المشروعين ، لا يتم استخدام Technical SEO من أجل عزل تأثيرات SEO الدلالية.
- لا يتم استخدام "تحسين سرعة الصفحة" لنفس السبب.
- لا يتم استخدام التصميم وتحسين WUX (تجربة مستخدم موقع الويب).
- لا يتم استخدام الروابط الخلفية (المراجع الخارجية وتدفق نظام ترتيب الصفحات).
- كلا العلامتين التجاريتين ليس لديهما بيانات تاريخية. Vizem.net جديد تمامًا ، لدى BogaziciEnstitusu تاريخ قديم ولكنه كان أقل من الشركة الفعلية.
- لا يتم استخدام OnPage SEO أو أي قطاعات أخرى من SEO.
- تتمتع كلتا العلامتين التجاريتين بخادم أفضل من مثال دراسة حالة السلطة الموضوعية السابقة.
ستساعد دراسة حالة تحسين محركات البحث (SEO) التي تركز على الشبكة الدلالية الأشخاص الذين يرغبون في تحسين منظور SEO الخاص بهم من خلال منهجيتين ومفاهيم مختلفة تركز على موقعين مختلفين.
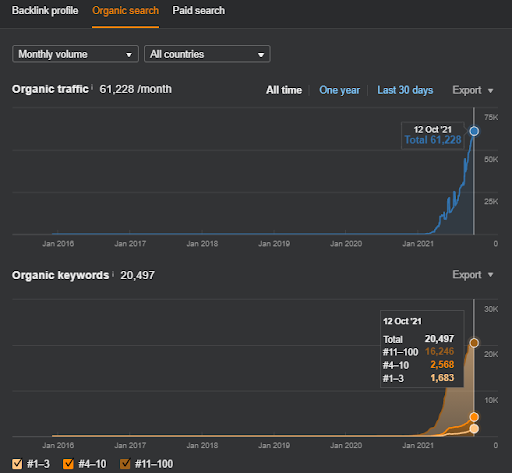
المشروع الثاني: يركز Vizem.net على عملية طلب التأشيرة. قبل كتابة هذه المشاريع أو نشرها أو حتى إطلاقها ، قمت بعرض هذين الموقعين عدة مرات لعملائي أو شركائي الآخرين. وقد بدأت Vizem.net رحلتها "Topical Authority" مؤخرًا.
تمت كتابة دراسة حالة تحسين محركات البحث استنادًا إلى دراسة حالة الشبكات الدلالية في نسختين مختلفتين. إذا كنت ترغب في قراءة جميع براءات الاختراع والأوراق البحثية ذات الصلة والفحوصات التفصيلية للغاية والتفسيرات من وجهة نظر محرك البحث أثناء فهم أشجار قرارات محركات البحث بشكل أكبر ، يمكنك قراءة أهمية التصنيف الأولي وإعادة ترتيب تحسين محركات البحث مقالة دراسة حالة أطول من 30.000 كلمة. إذا لم يكن لديك ما يكفي من المعرفة النظرية لتحسين محركات البحث والخلفية التاريخية ، يمكنك الاستمرار في قراءة الملخص التنفيذي.
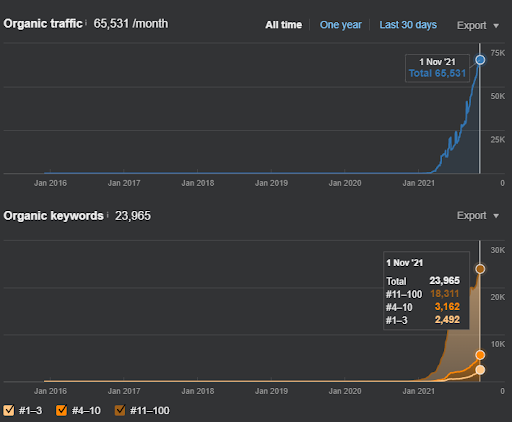
أدناه ، يمكنك رؤية رسم المشروع الثاني (Vizem.net) من SEMRush.
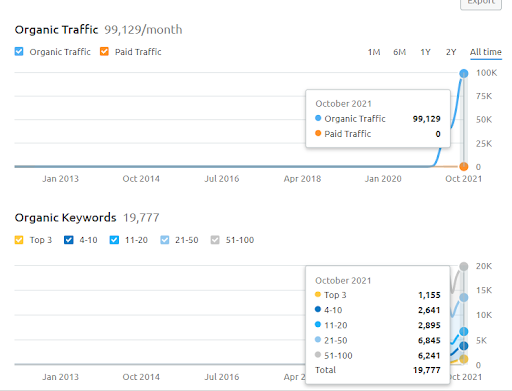
رسم SEMRush للموقع الثاني. Vizem.net هو مصدر جديد تمامًا يستهدف الصناعات ذات المستوى العالي من المنافسين المتجذرين مثل "طلب التأشيرة". على وجه الخصوص ، بسبب الأحداث الأخيرة في تركيا ، فإن مستوى المنافسة في الصناعة آخذ في الازدياد. وبالتالي ، يعد استخدام منظور الشبكة الدلالية لإنشاء شبكة محتوى مفيدًا.
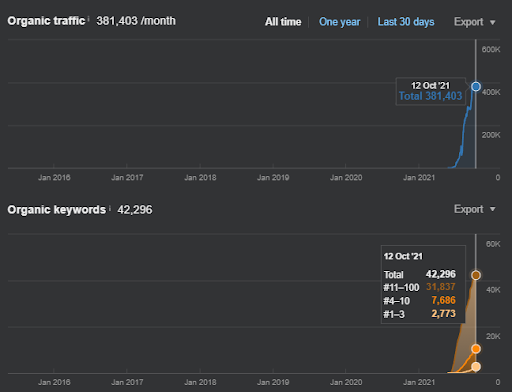
المشروع الأول: Istanbul Bogazici Enstitusu: زيادة بنسبة 600٪ في النقرات العضوية في 3 أشهر - البيانات التاريخية المعززة والترتيب الأولي
IstanbulBogazici Enstitusu هي واحدة من أصعب دراسات حالة تحسين محركات البحث التي أجريتها ، ليس بسبب محركات البحث ، ولكن بسبب الأشخاص ومشكلاتي الصحية. وبالتالي ، تركت المشروع ولم أنشر شبكة المحتوى الدلالية الثالثة المصممة لإكمال العلاقات الدلالية بناءً على سياق المصدر. حتى إذا لم يكن يحتوي على مصطلحات مجال المعرفة ، وتم تنفيذ العبارات السياقية بشكل صحيح ، فقد تم تكوينه بمستويات كافية من الاتصالات الدلالية والدقة ، للسماح بأداء بحث عضوي شامل لأكثر من ثلاثة ملايين جلسة شهريًا إذا كانت شبكة المحتوى الثالثة تم نشره في المستقبل ، وهو ما يمثل التأثير المتزايد لشبكة المحتوى الدلالية الثانية أيضًا.
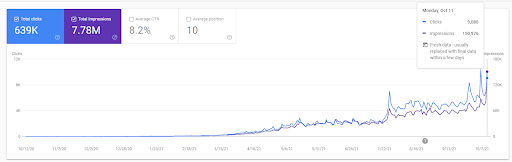
أدناه ، سترى الرسومات المتغيرة لـ IstanbulBogazici Enstitusu على GSC خلال الأشهر الـ 12 الماضية. تم إطلاق المشروع في مايو 2021 بطريقة مناسبة وانتهى في سبتمبر 2021 من خلال نشر شبكتي محتوى دلالي.
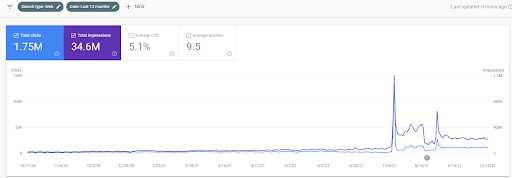
أدناه يمكنك رؤية النسخة الأكثر تفصيلاً. من 1400 نقرة يوميًا إلى 140000 نقرة ، وبعد ذلك يمكن رؤية أكثر من 10.000 نقرة يوميًا ضمن أداء البحث المجاني
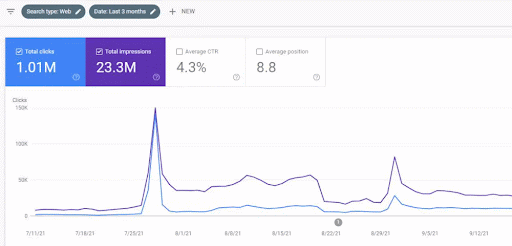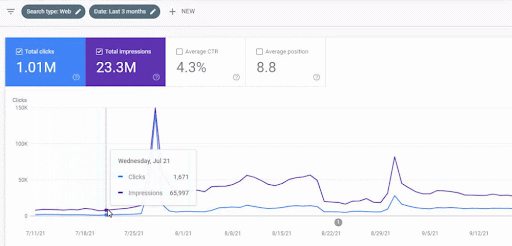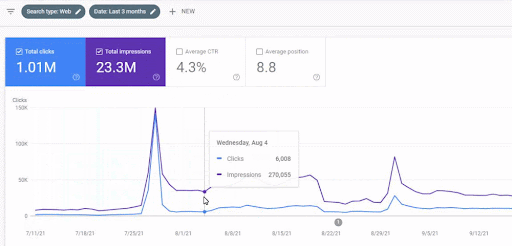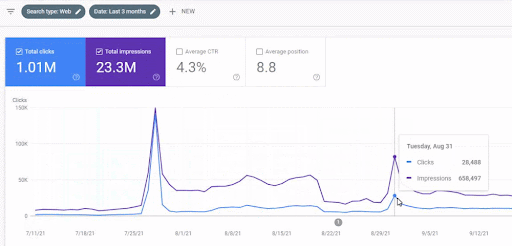
يمكن رؤية زيادة حركة المرور لشبكة المحتوى الأولى بعد الإطلاق أدناه.
تُظهر لقطة الشاشة هذه الشهر الرابع من أول شبكة محتوى دلالية.
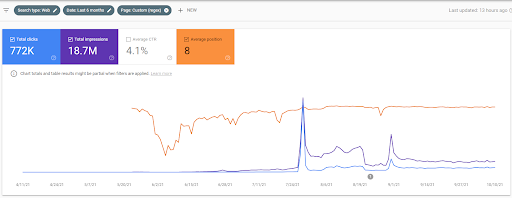
كما ترون من الرسم البياني ، فإن حركة المرور الإجمالية للموقع بالكامل قد هيمنت عليها وتأثرت بشبكة المحتوى الدلالية الأولى التي تركز على "الفروع التعليمية". يمكن رؤية شبكة المحتوى الثانية التي أطلقتها مع موقع الويب هذا أدناه من Google Search Console. لقطة الشاشة أدناه مأخوذة من اليوم السادس عشر من شبكة المحتوى الدلالية الثانية.
تم استخدام الترتيب الأولي وإعادة الترتيب داخل المقالة لأنها تحدد مراحل خوارزميات الترتيب جنبًا إلى جنب مع أنواعها وأغراضها قبل اختبار المصدر ، وصفحة ويب من المصدر داخل SERP للاستعلامات الأكثر أهمية التي تحظى بشعبية .
ما هي أول شبكة محتوى دلالي للمشروع الأول التي ركز عليها؟
تستخدم "شبكة المحتوى الدلالي" شبكة دلالية من قاعدة معرفية لشرح العلاقات الرئيسية والثانوية والثالثية بين الأشياء داخل قاعدة المعرفة. وبالتالي ، فإن إنشاء شبكة محتوى دلالي يتطلب تصميم شبكة المحتوى الدلالية التالية بناءً على سياق المصدر الذي يمثل الوظيفة الرئيسية لموقع الويب. في هذا السياق ، ركزت شبكة المحتوى الدلالية الأولى على "أقسام الجامعة ، والفروع التعليمية ، وضرورات التعليم الجامعي داخل مؤسسة وفرع معينين."
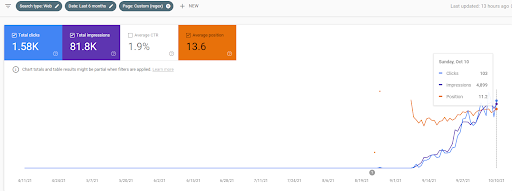
أدناه ، ستجد Ahrefs Graphic الأول لشبكة المحتوى الدلالي.
هذا بعد خمسة أيام من لقطة الشاشة السابقة.
"الجذر: istanbulbogazicienstitu.com/bolum" ، بعد مرحلة التصنيف الأولي الأولى ، أصبحت عملية إعادة التصنيف أكثر كفاءة وإنتاجية.
يمكنك رؤية الإصدار بعد أربعة أيام على النحو التالي لدعم طبيعة "إعادة الترتيب".
ما هي شبكة المحتوى الدلالي الثانية للمشروع الأول التي ركز عليها؟
ركزت شبكة المحتوى الدلالية الثانية على المهن والوظائف والمهارات والتعليم اللازم لهذه المهارات أو الروتين. استنادًا إلى شبكة المحتوى الدلالية الأولى ، تم دعم شبكة المحتوى الدلالية الثانية. ووفقًا لـ "قوالب نوايا قوالب الاستعلام" ، يتم إنشاء شبكتين مختلفتين للمحتوى الفرعي الدلالي ووضعهما مع "الاتصالات العلائقية" أثناء الاتصال بالمستويات الهرمية المماثلة العليا.
أعلم أن هذه الأقسام معقدة بالنسبة لك لأنك لم ترَ تعريفًا للأشياء أدناه ، حتى الآن.
- شبكة المحتوى الدلالي
- سياق المصدر
- شبكة المحتوى الفرعي الدلالي
- قاعدة المعرفة
- العلاقات العلائقية
- الترتيب الأولي
- إعادة الترتيب
- التغطية السياقية
- ترتيب المقارنة
- استخراج الحقائق
بعد شرح الموقع الثاني ، سيكون من الأسهل فهم هذه المفاهيم والجمل.
Vizem.net: من 0 إلى 9.000+ نقرة يومية في اليوم في 6 أشهر - ترتيب مقارن معزز مع تغطية سياقية
يمكنك مشاهدة الرسم البياني لـ Vizem.net للأشهر الـ 12 الماضية. بالنسبة لهذا المشروع ، بسبب Covid-19 ، واجهنا الكثير من المشاكل الاقتصادية لأن المستثمر من صناعة الصالة الرياضية. وبالتالي ، يمكنني القول أن المشكلات الاقتصادية أبطأت المشروع ، وتسببت في بعض التأخير في "عمليات إعادة الترتيب".
لفهم الترتيب الأولي وإعادة الترتيب قليلاً ، يمكنك استخدام الرسم البياني أدناه.
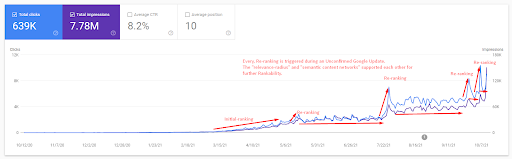
يمكن العثور أدناه على بعض التعريفات المتعلقة بالترتيب الأولي وإعادة الترتيب من الرسم أعلاه.
- حدثت قفزات كبيرة في الترتيب خلال تحديثات Google غير المؤكدة. أعطت بعض الاختبارات بعض المقتطفات المميزة ، وطرح الأشخاص أسئلة أيضًا.
- أدت بعض الاختبارات من Google إلى إزالة أرباح FS و PAA.
- في كل مرة ، كان الجدول الزمني بين عمليتي إعادة الترتيب أقصر.
- حسنت عمليات إعادة الترتيب من تصنيف المصدر في كل مرة.
- قام المصدر دائمًا بتحسين نصف قطر مدى ملاءمته أثناء توسيع مجموعات الاستعلام.
كمجرد ملاحظة ، يمكنني ترك جملة أدناه.
إذا قام محرك البحث بفهرسة صفحة الويب الخاصة بك ، فهذا لا يعني أن محرك البحث قد فهم صفحة الويب. تحدث الفهرسة بشكل أسرع من الفهم ، وفي معظم الأحيان ، يصنف محرك البحث صفحة ويب مع تنبؤات ، "مبدئيًا". بعد الفهم ، يحدث "إعادة الترتيب". 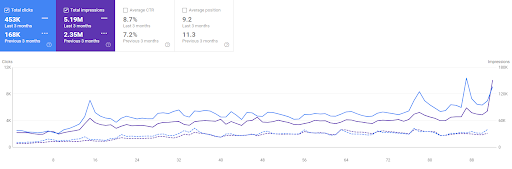
مقارنة آخر 3 أشهر لـ Vizem.net
كيف هي شبكة المحتوى الدلالي الخاصة بـ Vizem.net؟
أتذكر أنه بالنسبة للعديد من عملائي أو أصدقائي أو مجموعات تحسين محركات البحث السرية ، خلال الاجتماعات ، فقد عرضت هذين الموقعين بالقول ، "سوف ينفجران". وأثناء كتابة هذا المقال ، أقول لك هذا:
شاهد "istanbulbogazicienstitu.com/meslek" شبكة المحتوى الدلالية ، لأنها ستنفجر. ويمكنك العثور على مقطع فيديو قمت بنشره قبل كتابة هذا المقال أثناء عرض "البيانات التاريخية" من حدث موسمي وتأثيرها على العمليات الأولية وإعادة الترتيب. يمكنك رؤيتها بالأسفل.
بناءً على ذلك ، فإن شبكة المحتوى الدلالي الخاصة بـ Vizem.net ليست مشابهة لشبكة IstanbulBogazici Enstitusu ، وبالتالي ، لم أستخدم "مستوى مكثفًا من التغطية الموضوعية وزيادة البيانات التاريخية" ، كنت بحاجة إلى إنشاء السلطة المتعلقة ببعض أنواع الكيانات وخصائصها والإجراءات المحتملة وراء الاستعلامات لأزواج سمات الكيان هذه. ليس لدى Vizem.net "فروع جامعية تعليمية" فقط ، أو "مهن ودورات عبر الإنترنت" بداخلها. لديها "دول لطلبات التأشيرة". وبالتالي ، فإن إنشاء مستوى كافٍ من السلطة الموضوعية يتطلب الاتساق بمرور الوقت مع ما لا يقل عن 190 شبكة محتوى دلالي مختلفة.
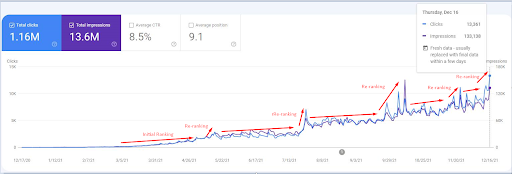
لقطة شاشة من 18 ديسمبر 2021. يمكنك مشاهدة إعادة الترتيب المستمرة وزيادة مرات الظهور والنقرات ، بعد 4 أسابيع من لقطة الشاشة السابقة.
لمشاهدة أحداث إعادة الترتيب ، يمكنك مقارنة النسخة المجردة من رسم أداء البحث العضوي الذي يوضح تأثير SEO الدلالي. 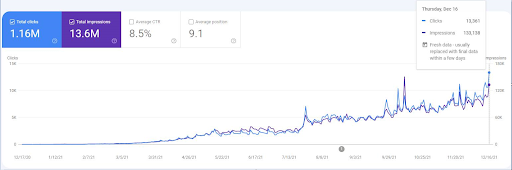
يتم تشكيل شبكات المحتوى الدلالية الـ 190 المختلفة هذه بناءً على "الدولة" نفسها ، ويتم وضع البلدان في مركز الخريطة الموضعية مع كل طبقة سياقية ممكنة لتحسين تغطية نشاط البحث.
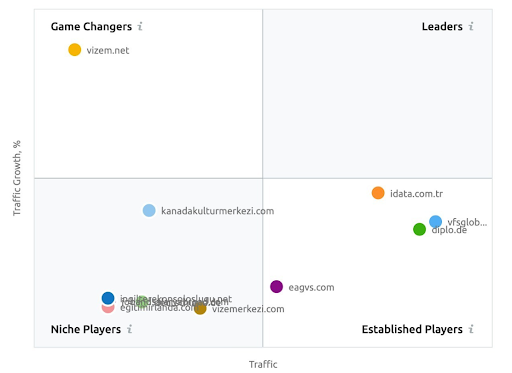
لقطة شاشة من SEMRush تُظهر تصورهم لـ Vizem.net على عكس لاعبي الصناعة الآخرين.
لقد نشرت أيضًا مقطع فيديو آخر لـ Vizem.net فقط. في هذا الفيديو ، الوضع الأخير للموقع غير موجود ، وبالتالي ، أعتقد أنه يوفر أيضًا مقارنة لطيفة بين اليوم وتلك اليوم.
أخيرًا ، يمكن أن يؤدي نشر أشياء غير ذات صلة داخل مقالة أو جزء موقع ويب أو مصدر غير ذي صلة إلى تقليل الصلة العامة لكيان الويب بمجال المعرفة المحدد. سيُظهر Vizem.net قيمته الحقيقية ، وستكون قابلية التصنيف في المستقبل أفضل بكثير.
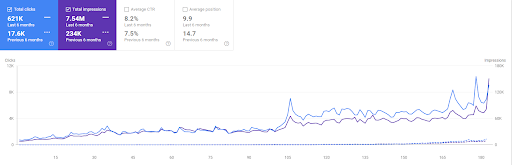
مقارنة آخر 6 أشهر لـ Vizem.net.
قبل أن أكمل أكثر ، أعلم أن هذا مقال طويل. ولكن ، في الواقع هذا شرح موجز لمنهجية مُحسّنات محرّكات البحث شديدة التعقيد. تتطلب شبكات المحتوى الدلالية الكثير من التفكير أثناء تصميمها ، وشهورًا من التعليم للعملاء والمؤلفين ، بالإضافة إلى الإعداد. وبالتالي ، في هذه المقالة ، أود التركيز على تعاريف المفاهيم مع أفضل الاقتراحات الموجزة القابلة للتنفيذ الممكنة وجوجل المهم ، وبراءات اختراع محركات البحث الأخرى ، والأوراق البحثية جنبًا إلى جنب مع المفاهيم الخاصة بهم. في النسخة الطويلة (كتاب بشكل أساسي) ، ركزت على "الترتيب الأولي" و "إعادة الترتيب" لشبكات المحتوى الدلالية.
إذا كنت تريد معرفة المزيد ، فاقرأ "أهمية الترتيب الأولي وإعادة الترتيب لتحسين محركات البحث".
حتى الآن ، قمنا بمعالجة الأشياء أدناه.
- الشبكة الدلالية
- قاعدة المعرفة
- شبكة المحتوى الدلالي
- الثقة القائمة على المعرفة
- التغطية السياقية
- المجال السياقي والطبقات
- صلة MuM بشبكات المحتوى الدلالية
- سياق المصدر
تهدف هذه المفاهيم إلى فهم كيفية عمل شبكات المحتوى الدلالية ، وكيف يمكن استخدامها مع خريطة موضوعية. ستكون الأقسام التالية حول كيفية تصنيف محرك البحث لشبكات المحتوى الدلالية في البداية وبعد ذلك ، التعديل. في هذا السياق ، ستتم معالجة الأشياء أدناه.
- الترتيب الأولي
- إعادة الترتيب
- قالب الاستعلام
- قالب المستند
- نموذج نية البحث
- ما يجب عليك فعله للاستفادة من شبكات المحتوى الدلالية
ما هو الترتيب الأولي لـ SEO؟
هذا مصطلح ومفهوم جديد لكبار المسئولين الاقتصاديين ، ولكنه مصطلح قديم لمحركات البحث. تركز النسخة الطويلة من "دراسة حالة تحسين محركات البحث (SEO) المركزة على الشبكة الدلالية" على خوارزميات التصنيف بناءً على خوارزميات تعتمد على الاستعلام ، وتعتمد على المستندات ، وتعتمد على المصدر ، وبراءات اختراع متعددة. تحاول خوارزميات استرجاع المعلومات التنبؤية أو التصنيف التنبئي تقليل تكلفة الحساب. وحتى إذا حدثت الفهرسة في يوم واحد ، فقد يستغرق فهم المستند شهورًا أو حتى سنوات. وبالتالي ، فإن حساب الترتيب الأولي هو وسيلة لتحسين جودة SERP مع تقليل التكلفة. تتمتع بعض المهام المتعلقة بمحرك البحث بأولوية أعلى من غيرها للحفاظ على الفهرس نشطًا وجديدًا وجودة عالية بما يكفي.

يظهر مصطلح التصنيف الأولي في عشرات الآلاف من براءات اختراع Google المختلفة والأوراق البحثية لأنه منظور كلاسيكي بين بناة محركات البحث. وهكذا ، أعلاه ، يمكنك رؤية وثائق براءات مختلفة مع استمرار نفس الفقرات ، وشروط مع تغييرات طفيفة حول مصطلح التصنيف الأولي.
يمثل الترتيب الأولي رتبة المستند على SERP فور فهرسته. يمثل الترتيب الأولي للمستند السلطة العامة وملاءمة المصدر للموضوع المحدد ، قالب الاستعلام ، وهدف البحث. يمكن تصنيف المحتوى نفسه بشكل مختلف من حيث الترتيب الأولي بين المصادر المختلفة. يعد الترتيب الأولي مهمًا أثناء استخدام شبكات المحتوى الدلالية لمعرفة الجودة الشاملة وزيادة سلطة المصدر. يزيد كل مستند جديد من ترتيبه الأولي مع تقليل تأخير الفهرسة إذا كان تصميم شبكة المحتوى الدلالي منظمًا بشكل صحيح.
يدعم الترتيب الأولي عملية إعادة التصنيف وكفاءته بالنسبة للمصدر. ويجب معالجة "تصنيف المصدر" بهاتين المصطلحين ، الأولي وإعادة الترتيب.
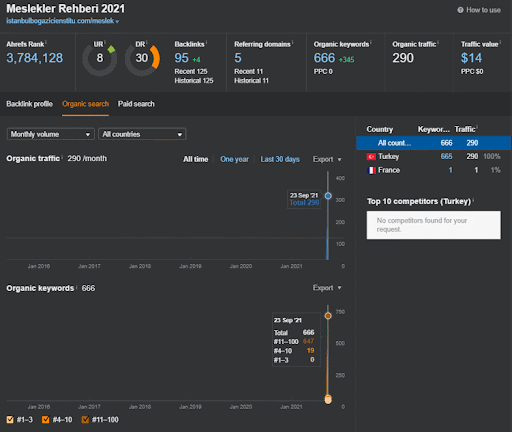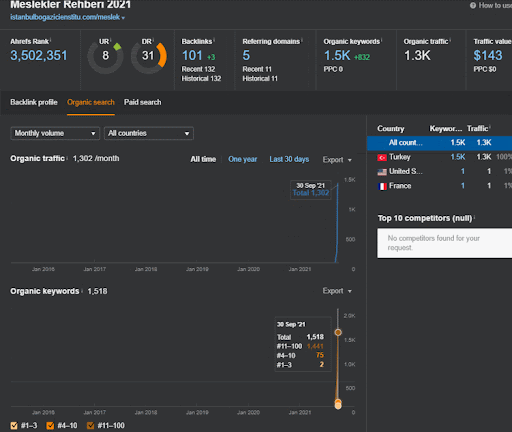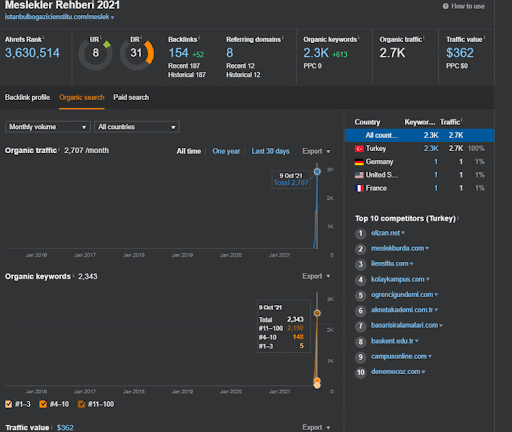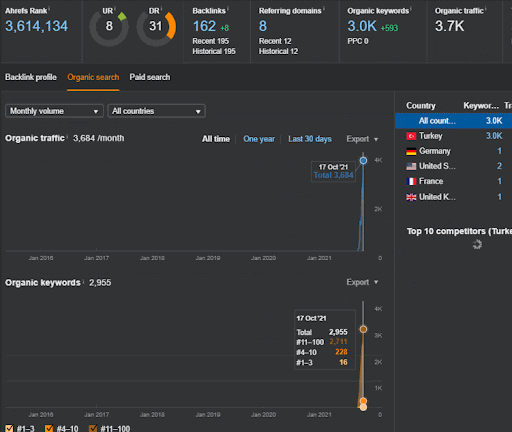
يمكنك مشاهدة أول 20 يومًا من التغيير العضوي للأداء الثاني لشبكة المحتوى من المشروع الأول.
في هذا السياق ، كلما نشرت Vizem.net مستندًا جديدًا ، أو كلما نشرت IstanbulBogazici Enstitu شبكة محتوى دلالية جديدة ، يكون الترتيب الأولي أفضل من ذي قبل بينما تتم فهرسة المحتوى بشكل أسرع.
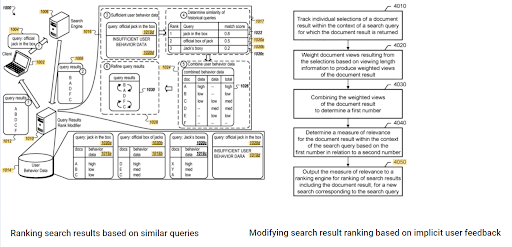
يمكن رؤية بروز الترتيب الأولي والبيانات التاريخية بين هاتين البراءات التكميلية من Google. أحدهما مخصص للمستندات الأولية وإعادة الترتيب بناءً على ملاحظات المستخدم الضمنية. The other one is for doing the same if enough level of user data doesn't exist, based on the similar queries. The similar queries are also the point that relate the Semantics. Creating a Semantic Content Network will decrease the energy for reading the mind of the website owner from the search engine's point of view.
What is Re-ranking for SEO?
The re-ranking is the process of changing a document's ranking on the SERP based on the feedback of the users, or relevance, and quality evaluation algorithms. Re-ranking frequency can signal an algorithm update, or an update on the document, or a site-wide update for a source. Re-ranking is affected by the historical data which is explained in the previous SEO Case Study that focuses on the Topical Authority. Examining the re-ranking processes and the feedback from the search engines help for the configuration of the semantic content network design. Re-ranking timelines can be shortened with the help of the actual traffic, as well as with historical data if the contextual and topical coverage is improved.
The re-ranking processes are affected by the initial ranking and the quality of the neighborhood content. The neighborhood content will affect the ranking of any strongly connected components. Re-ranking processes can signal the weak spots, and the ability of the search engine to understand certain sections of the semantic content network. If the design is correctly created, the semantic content network will continue to rise and rise in terms of organic search performance over time, and any Google Updates will confirm these processes.
Below, you can see the comparison of the Semantic Content Network 1 and Semantic Content Network 2 of the IstanbulBogazici Enstitu in terms of the initial and re-ranking. 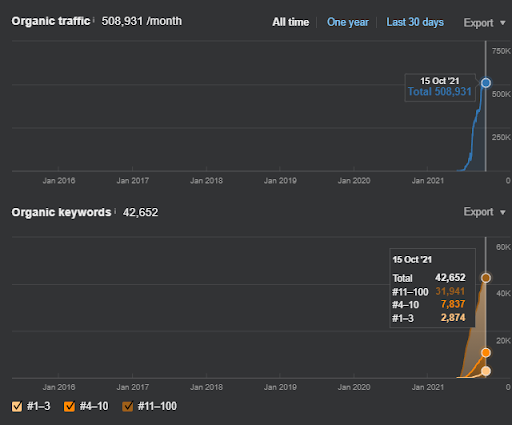
15 October 2021, performance of the first semantic content network of the IstanbulBogaziciEnstitusu which is the 124th day of the launch. 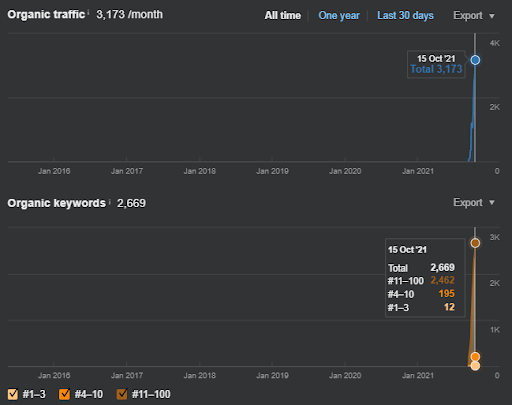
15 October 2021, performance of the Second Semantic Content Network of IstanbulBogazici Enstitu which is the 19th day of the launch. 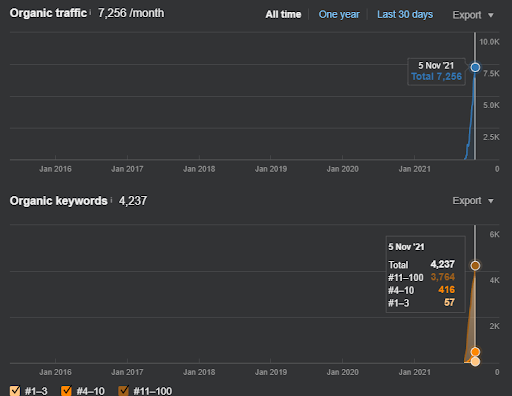
As you see, the second content network increases the organic query count and the rankings much faster than the first one. The Semantic Content Network 1 has the benefit of the “seasonal SEO” which gives enough level of historical data in a positive way. If there is a seasonal SEO event, the search engine will re-rank the pages, and assign the new relevance-radius and search activity coverage scores to the documents and the sources. Thus, I have chosen to use a “sudden launch” for the “university branches” first. It was the first step of the Topical Authority Building which is equal to the “historical data * topical coverage”. 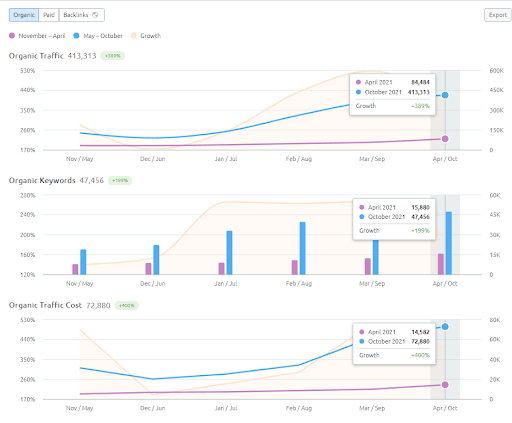
The 6 Months of Growth Comparison of the IstanbulBogazici Enstitu from SEMRush.
Note: To compensate for weaknesses in the execution, I designed a Semantic Content Network 3 to unite the first two using conceptual connections by providing the source's context. If I launched it, you would see that the source would acquire more than 1,2M organic traffic based on the Ahrefs graphic, in reality, it can be more than 2M. You can see my prediction's validity from the performance of the Second Content Network. Whenever you check it, you will see that it has thousands of new queries with higher rankings.

In the first Semantic Content Network, the first 3 ranking queries appeared after 2 months' for the second one, they appeared on the 15th day. You can imagine the increase in authority. Since the knowledge base of the website is left partially incomplete, after the source loses its momentum for semantic network completion, the search engine can prioritize other sources, and it can decrease the re-ranking positivity along with the relevance-radius and Rankability.
Implementing Semantic Networks on these sites makes use of a few concepts and “templates” used by search engines. Before I tell you about the method for setting up a Semantic Network, you should also understand what these templates are and how they work. This will help you understand how search patterns and document structure impact ranking, and therefore why the method I used in this case study is so effective.
The Initial Ranking, and Re-ranking are two different ranking algorithm types for a search engine based on timing. Search engines have other types of ranking algorithms such as query-dependent, query-independent, content-based, link-based, usage-based. To be able to understand the ranking systems, and clustering-associating technology of the search engines, the query-document-intent templates, and their relation to each other should be understood.
بيانات عند الزحف³
 يتعلم أكثر
يتعلم أكثرWhat is a query template?
A query template represents a search pattern with ordered phrases that cover an entity for seeking factual information. A query template can have a question format, a proposition format, or an order of word types such as one adjective and one noun. A query template is useful for generating seed and synthetic queries from the point of view of a search engine. A seed query can help a search engine to choose centroids for the query clusters while helping the clustering web page documents, their types, and possible search activities for them. 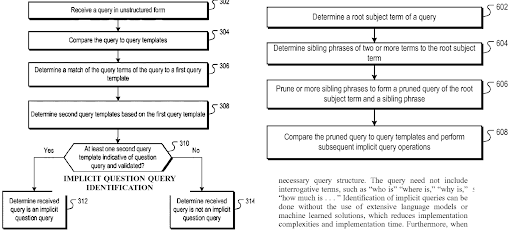
Another Google Patent about “Implicit Question Query Identification” which Nitin Gupta invented along with Steven Baker. “Implicit Question Query Identification” is also related to the question generation which is connected to the “K2Q System”.
In this context, a query template can be used for feeding the search engines' historical data for creating trust. Even if a search engine doesn't understand all aspects of a query, or a document for it, still some certain sources can be ranked earlier and better than others because of the document templates. If a source satisfies queries from a template, the search engine will rank the specific source for these types of queries from the same template better initially and during the re-ranking processes. Thus, on the web, we have sources that only focus on a single vertical with a single query template, like Wikihow, or GiftIdeas. 
“Query Suggestion Templates” is one of the documents that explains how a search engine can generate query templates based on query logs. Since, Nitin Gupta is one of the inventors of this patent, it has more value for me.
A query template can be used for creating a successful semantic content network, but in page contextual domains, and connections should be configured properly for connecting multiple semantic content networks for multiple query templates.
Note: The topic Query Templates, Intent Templates and the Document Templates are closely related, and another SEO Case Study will be published to demonstrate further details about it. 
A section from the Representation Learning for Information Extraction
from Form-like Documents of Google for extracting information from templatic content.
What is a document template?
A document template can signal the purpose of a web page based on the design elements, or even the request size, count and types. If a web page has too much JS, it can be a js-dependent website, or the interactivity needs can be higher than others. This can be confirmed easily by just checking the event-listeners on the web page, or input types, and API endpoints. When it comes to thinking like a search engine, remember that the web is a chaotic place. And, everything possible for understanding the users, especially if the users are Markovian , meaning that they are more influenced by the current page than their history of navigation. 
A section that explains how a search engine can use the document templates to see a user's interest area.
Did you know that Prabhakar Raghavan, the VP of Search on Google, also has a research that asks the same question? “Are Web Users Markovian?”. 
A section from the “Are web users Markovian?” research paper.
نعم إنهم هم. يعد الترتيب الاحتمالي وترتيب الصلة المتدهور الأعمدة الرئيسية لمحرك البحث الدلالي لفهم المستخدمين ، وخلق أفضل جودة ممكنة من SERP يتم إعدادها لحالات الاحتمالات. 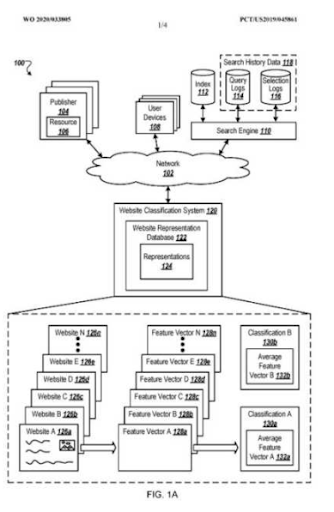
في السابق ، لجعل "تصميم موقع الويب ، والشكل ، أو الدرجة اللونية" حجة لتعلم التمثيل لمواقع الويب ، كتب Bill Slawski "متجهات تمثيل موقع الويب".
ما هو قالب نية البحث؟
يمكن تمثيل قالب هدف البحث بالحاجة وراء قالب الاستعلام. يمكن توحيد قالب مستند الاستعلام بناءً على قالب النية. سيساعد وجود نموذج هدف البحث مع "تصنيف الصلة المتدهور" وفهم "الترتيب الاحتمالي" في إنشاء أفضل نشاط بحث ممكن وتغطية هدف البحث بالترتيب الصحيح. أثناء إنشاء شبكة المحتوى الدلالي ، فإن أهم شيء هو تعديل قالب نية استعلام المستند استنادًا إلى سياق المصدر لإكمال شبكة دلالية تعتمد على مجال المعرفة من خلال تحسين التغطية السياقية لتحسين الثقة القائمة على المعرفة والسلطة الموضوعية . 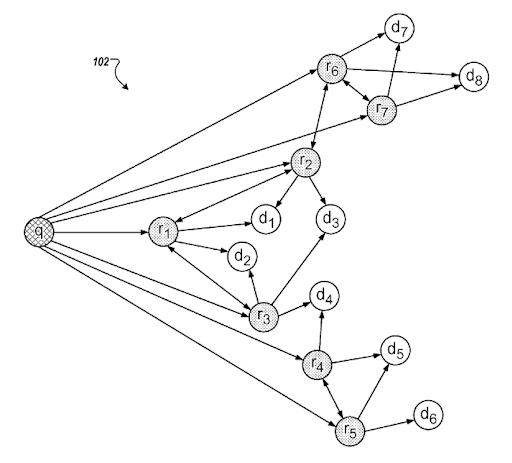
قسم من "تنقيحات طلب البحث استنادًا إلى النية المستنبطة". إنه يعمل من خلال مجموعات الاستعلام وقوالب النوايا مع الاتصالات الدلالية. يمكنك تجربتها على مستويات مختلفة من تصنيف العبارات.
قبل الانتقال إلى بعض الأمثلة الملموسة والاقتراحات لمساعدتك في إنشاء شبكة محتوى دلالية أفضل ، يجب أن أخبرك أنه حتى الإصدار البسيط من دراسة حالة تحسين محركات البحث هذه يتطلب مستوى عالٍ من فهم محرك البحث ومهارات الاتصال. وبالتالي ، على الرغم من أنني أشعر أنني أعطي معلومات عالية المستوى ، فأنا أعلم أن دورة Semantic SEO التي سأقوم بإنشائها ستعرض لك بعض الأمثلة الملموسة أكثر وأفضل. 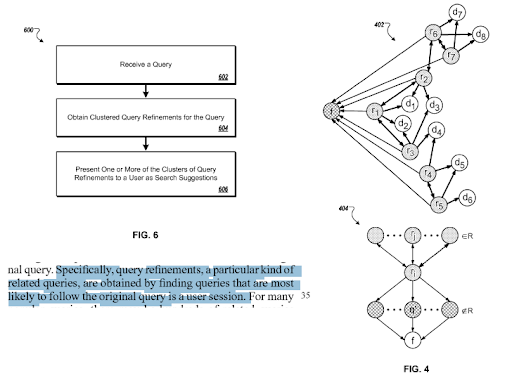
تشرح نفس براءة الاختراع الروابط المناسبة بين "مسارات الاستعلام" المختلفة و "تحولات السياق".
ما الذي يجب أن تعرفه عن الاستفادة من شبكات المحتوى الدلالية؟
لإنشاء شبكة محتوى دلالية ، في بعض الأحيان ، قد يستغرق تصميم موجز وتصميم بسيط للمحتوى الدلالي ساعة واحدة ، إذا وضعت كل التفاصيل ذات الصلة بناءً على الدلالات المعجمية ، أو أنواع العلاقات بين الكيانات والعبارات. باستخدام زوايا متعددة في نفس الوقت ، مثل الفهرسة المستندة إلى العبارة ، ومتجهات الكلمات ، أو متجهات السياق لحساب الصلة السياقية للمحتوى بشكل عام بمجال سياقي ، أو مدى ملاءمته بناءً على أنواع المحتوى الفرعي الفردية ، يتطلب مستوى عاليًا من الفهم الدلالي لمحركات البحث.
وبالتالي ، فإن استخدام منهجية توليدية سيجعل كل شيء أسهل مع المفاهيم التي شرحتها لك أعلاه ، لأنه حتى لو قمت بإعداد كل جزء من شبكة المحتوى الدلالي بشكل مثالي ، فلن يتمكن المؤلفون والكتاب من كتابته ، أو مديري المحتوى لن تكون قادرة على متابعة رؤيتك. وبالتالي ، قد يتعبك هذا بدون مقابل ، ويجعلك تترك مشروعًا كما فعلت مع بعض مشاريع دراسة حالة تحسين محركات البحث هذه بعد أن أثبت المفهوم بطريقة كافية وحيوية وقابلة للتدقيق.
الاقتراحات الواردة أدناه ستكون فقط من أجل خطوات سهلة قابلة للتنفيذ ومختصرة من شأنها أن تساعدك.
1. لا تستخدم ارتباطات الشريط الجانبي الثابتة من كل شبكات شبكة المحتوى الدلالية
يجب أن يحتوي كل رابط على وصف اتصال بين وثيقتين للنص التشعبي مثل كل كلمة في صفحة الويب. يمكن أن يساعد استخدام HTML الدلالي في تحديد موضع ووظيفة المستند على صفحة الويب مع مساعدة محركات البحث على وزن الأقسام بشكل مختلف من حيث السياق.
في مثال Vizem.net ، لم أستخدم نفس تصميم الشريط الجانبي. لم يُظهر الشريط الجانبي آخر المنشورات أو المنشورات الأكثر أهمية. تظهر الأشرطة الجانبية فقط سمات الكيانات المركزية ، وهي ليست ثابتة ، فهي ديناميكية. بمعنى آخر ، بناءً على التسلسل الهرمي داخل الخريطة الموضعية ، تتغير شبكات شبكة المحتوى الدلالية حتى لو كانت في الشريط الجانبي. 
يمكن أن يساعد التفكير في نماذج Surfer المعقولة والمتصفح الحذرة مُحسِّن محركات البحث في إنشاء صلة أفضل بين مستندات النص التشعبي المختلفة.
بالإضافة إلى ذلك ، يتدفق الارتباط من حيث الشهرة ، ويجب أن تتبع الشعبية سياق المصدر من أفضل الاتصالات الممكنة. أدناه ، يمكنك رؤية أقسام الشريط الجانبي مع أكواد HTML الدلالية المعدلة. 
وفقًا للتسلسل الهرمي للمقالة النشطة في جلسة المستخدم ، ستتغير علامات التبويب وترتيب علامات التبويب والروابط الموجودة داخل علامات التبويب. المثال أعلاه مأخوذ من التسلسل الهرمي لمسار التنقل أدناه. ![]()
2. دعم شبكات المحتوى الدلالية مع PageRank
حتى لو لم يكن نظام ترتيب الصفحات الخارجي ضروريًا من المصادر الخارجية ، إذا كنت قادرًا على استخدامه ، فسوف تدرك أن الترتيب الأولي وإعادة الترتيب سيكونان أفضل. في كلا المشروعين ، لم أستخدمهما ، لكن هذه المرة ، لم يكن هذا هو الغرض. بالنسبة إلى Vizem.net ، كانت هناك مشكلات اقتصادية ، ولم أرغب في إنفاق الميزانية على العلاقات العامة الرقمية والتواصل. بالنسبة إلى Istanbul BogaziciEnstitusu ، قمت بترتيب اثنين من "المصادر المترابطة محليًا" لدعم مصداقية المصدر للموضوع المحدد ، ولكن مرة أخرى ، لم تتمكن الشركة من تنفيذ ذلك بسبب مشكلات الميزانية والانضباط التنظيمي. 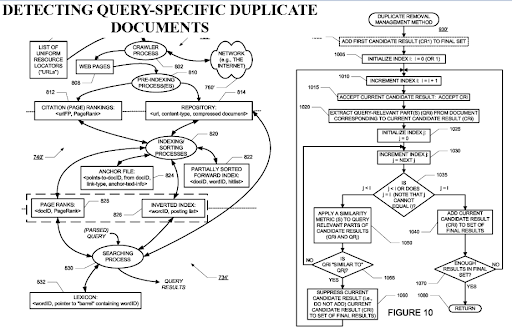
يعد اكتشاف المستندات المكررة الخاصة بالاستعلام منظورًا مهمًا من محركات البحث ، لأن نظام ترتيب الصفحات يمكن أن يساعد في تصفية المستند باعتباره ذا قيمة حتى إذا تم تكراره. نظرًا لأن شبكات المحتوى الدلالية عالية التنظيم يمكن أن تكون متشابهة مع بعضها البعض ، فإن تدفق PageRank والبيانات التاريخية مفيد.
عندما يتعلق الأمر باختيار نقطة تدفق PageRank الخارجية لهذه الأنواع من شبكات المحتوى الدلالية ، استخدم المصادر مع البيانات التاريخية. في حالتي ، كنت قد رتبت نقاط نهاية PageRank هذه مسبقًا ، قبل إطلاق ونشر أول شبكة محتوى دلالية. بهذه الطريقة ، تمكنت من أخذ مراجع خارجية من المنافسين المباشرين ، لكن عندما نشرت شبكة المحتوى الدلالية ، تخلى المنافسون عن ربط المصدر لأنهم رأوا الزيادة الجماعية للمصدر كمنافس.
يقودنا هذا الوضع إلى الاقتراح الثالث. إذا تمكنا من استخدام تدفق PageRank من المراجع الخارجية ، فستكون عملية إعادة الترتيب أسرع ، وسيكون الترتيب الأولي أعلى.
3. استخدم نصوص ربط مختلفة من التذييل والعنوان والمحتوى الرئيسي لأجزاء شبكة المحتوى الدلالية البارزة
تشير نصوص الربط أو "نص الرابط" من وجهة نظر محرك البحث إلى أهمية وثيقة النص التشعبي بآخر. وفقًا للمستند الأصلي لنظام ترتيب الصفحات ، يتناسب عدد الروابط مع تدفق نظام ترتيب الصفحات. ولكن ، غيّرت Google هذا لاحقًا لمنع "حشو الروابط" وقيدت الروابط التي يمكنها تجاوز نظام ترتيب الصفحات. بناءً على ذلك ، تم تطوير TrustRank أو Cautious Surfer أو Hilltop Algorithm أو Reasonable Surfer Models. 
هذان رابطان لشبكتي محتوى دلالي مختلفين لـ BogaziciEnstitusu ، ولكن نظرًا لأنني لم أقم بتطبيق تحسينات تقنية لتحسين محركات البحث أو UX ، يمكنك إدراك "رخيصة" تصميمات الأزرار.
وفقًا لـ Google ، لا يمكن للرابط نفسه تمرير PageRank مرة أخرى إلى صفحة ويب أخرى ، بينما سيتم تمرير PageRank من الرابط الأول فقط. وفي الشكل الأصلي لخوارزمية PageRank ، يمكن أن يربط مستند النص التشعبي نفسه لتحسين نظام ترتيب الصفحات ، أو يمكن استخدام عمليات إعادة التوجيه 301 لأخذ نظام ترتيب الصفحات من المستند الهدف للرابط. خلقت كلتا الحالتين تقنيات Black Hat قديمة مثل إعادة توجيه صفحة ويب إلى صفحة أخرى بشكل مؤقت لمجرد أخذ PageRank. كان هذا من الأيام التي تمكنت فيها مُحسّنات محرّكات البحث من رؤية PageRank لصفحة ويب من Google Search Console أو SERP. في وقت لاحق ، بدأت Google في تثبيط PageRank مع كل إعادة توجيه بينما أوضح Danny Sullivan أن عمليات إعادة التوجيه 301 ستجتاز نظام PageRank بالكامل. إلى جانب كل هذه التغييرات ، الشيء المهم هنا هو أنه حتى لو لم يجتاز الرابط الثاني نظام ترتيب الصفحات ، فإنه لا يزال يمرر أهمية نص الرابط. 
تم ربط الأقسام البارزة في شبكة المحتوى الدلالي من الصفحة الرئيسية استنادًا إلى "تنقيحات الاستعلام الأوسط" التي تتضمن "الأفعال ، أو المسندات" ، أو "أنشطة الباحث".
وبالتالي ، يجب ربط الأقسام البارزة في شبكة المحتوى الدلالية من قائمة الرأس والتذييل بأقسام التصنيف الأعلى ، ويجب أن تكون نصوص الارتباط مختلفة عن بعضها البعض. في هذه الأمثلة ، استخدمت روابط الرأس مع نصوص الروابط البارزة ولكن القصيرة بينما احتفظت بأمثلة التذييل لفترة أطول. 
قسم من "فهرسة علامات الارتساء في نظام متتبع ارتباطات الويب" ، يلخص أهمية نص الرابط ونص التعليق التوضيحي لوضع صفحة ويب ضمن مجموعات الاستعلام ومجموعات صفحات الويب.
إذا كان قسم شبكة المحتوى الدلالي بارزًا جدًا ، لتمرير PageRank والزحف على الأولوية بشكل صحيح ، فقد قمت بربط الأقسام الأكثر أهمية بنصوص الروابط المناسبة ، والفقرات التفسيرية التي تتضمن السمات البارزة مع أشكال مختلفة من N-Grams ذات الصلة. 
هذه هي المنطقة المرتبطة الثانية من الصفحة الرئيسية لـ Vizem.net ، وهي خلف الأكورديون ، وتركز على البلدان ضمن الاستعلامات ، وتربط القسم الأوسط من شبكة المحتوى الدلالية.
ملاحظة: حول نصوص الربط ، تم دائمًا استخدام "نص التعليق التوضيحي" المخطط لتحسين دقة الغرض من الارتباط.
4. الحد من تقييد عدد الروابط ومطابقة ارتباطات سطح المكتب والجوال والمحتوى الرئيسي
كلا المشروعين مقيدان بحيث يحتويان على أقل من 150 رابطًا داخليًا لكل صفحة ويب. بمساعدة لغة HTML الدلالية ، يتم توضيح أماكن الروابط ووظائف الروابط إلى برامج الزحف. كان لدى IstanbulBogazici Enstitusu أكثر من 450 رابطًا لكل صفحة ويب ، وكان بعضها عبارة عن روابط ذاتية (رابط من نفس الصفحة إلى نفس الصفحة). أسوأ جزء هو أن نصف هذه الروابط لم تكن موجودة في نسخة الهاتف المحمول من المحتوى. 
يمكن استخدام نقاط الاحتفاظ بعنوان URL ، ونقاط الزحف ، وأنواع أخرى من الدرجات لتحديد مدى بروز الرابط داخل خريطة عنوان URL الداخلية ، ويمكن استخدام علامات تعريف المستند ضمن المستويات المختلفة لفرز الفهرس استنادًا إلى درجات الصلة المستقلة عن الاستعلام.
نظرًا لأن Google تستخدم الفهرسة للجوال فقط ، إذا لم يكن المحتوى موجودًا في إصدار الهاتف المحمول ، فسيتم تجاهله ، ولن يتم استخدامه لتقييم الملاءمة ولأغراض الترتيب. وبالتالي ، فقد تم تكوين محتوى الهاتف المحمول وسطح المكتب بحيث يتطابق مع بعضهما البعض. حتى إذا كانت Google تتسامح مع عدم تطابق المحتوى بين إصدارات سطح المكتب والجوال ، فإنها لا تزال تجعل فهم صفحة الويب وتصنيفها أكثر صعوبة لمحركات البحث. 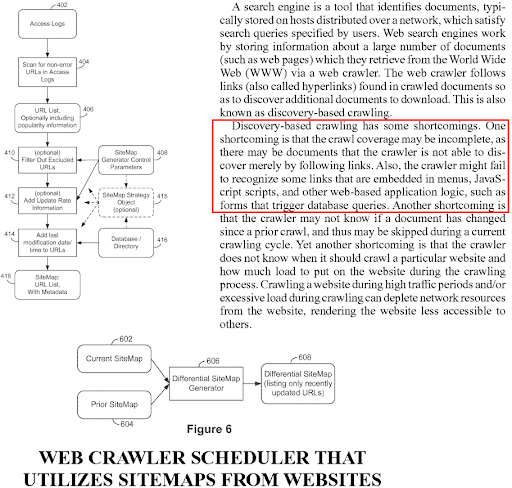
يمكن لمحرك البحث إنشاء خريطة موقع لموقع الويب ، ويمكن إعادة إنشاء خريطة الموقع هذه في حلقة ، إذا كانت الروابط والبيانات الوصفية لعناوين URL غير متطابقة بين وكلاء المستخدم أو الخطوط الزمنية. وبالتالي ، من المهم الحفاظ على مسار الزحف قصيرًا ، وقائمة انتظار تتبع الزحف ، واتساق الروابط الداخلية.
إلى جانب الروابط بين صفحات الويب المختلفة ، تُستخدم أيضًا روابط الأقسام الفرعية لصفحات الويب مع "جدول المحتوى" و "أجزاء عنوان URL". تستهدف أجزاء URL هذه قسمًا فرعيًا محددًا من صفحة الويب أثناء تسميتها بشكل صحيح ، وقد تم وضع القسم المحدد في علامة قسم بعلامة h2. بمساعدة أجزاء URL مع "روابط التنقل في الصفحة" ، كان نقل مستخدم من SERP إلى قسم معين من صفحة الويب أسهل ، بينما أصبحت الأقسام السفلية من المحتوى أكثر بروزًا لتلبية الحاجة وراء استفسار.
5. احصل على مستوى انضباط عسكري لمشاريع تحسين محركات البحث الخاصة بك
هذا موضوع آخر تمامًا ويمكن كتابة مقال آخر لتحديد ما يعنيه الانضباط على المستوى العسكري ، أو لماذا يكون مفيدًا لمشروع تحسين محركات البحث. ولكن ، يجب أن أخبرك أنه خلال هذين الشهرين الماضيين ، قمت بتدريب الكثير من الرؤساء التنفيذيين ومُحسنات محركات البحث من الوكالات الأخرى جنبًا إلى جنب مع فرقهم لمعرفة ما إذا كان تصميم الدورة التدريبية الخاص بي سيعمل بشكل جيد أم لا.
كلما رأيت نجاحًا ومستوى عالٍ من الإمساك بالجلسات التعليمية التي أقوم بها ، أكون هناك إرادة قوية ومثابرة. تكمن المشكلة الرئيسية في أن السيو الدلالي أصعب بكثير من قطاعات تحسين محركات البحث الأخرى. تعتبر تقنية تحسين محركات البحث (Technical SEO) عالمية ، وقد كتبت أدلة إرشادية لكل خطوة. يمكن تتبع OnPage SEO أو WUX and Layout Design باستخدام قياسات رقمية. عندما يتعلق الأمر بالدلالات ، فإن ممارسة توحيد منظور الآلة التي تعمل على أساس نظام تكيفي معقد مع الإنسان العاقل الذي لا يفهم كيف تعمل الآلة.
يتطلب هذا التمييز أرضية صلبة يجب وضعها من اليوم الأول للمشروع. في معظم الأحيان ، أستخدم القواعد أدناه.
- لا يجب أن تكون تصميمات المحتوى وشبكة المحتوى الدلالية منطقية بالنسبة لمؤلف أو كاتب.
- تتمثل مهمة مدير المحتوى في تدقيق توافق المحتوى مع تصميم المحتوى.
- مهمة المؤلف هي كتابة المحتوى بالمعلومات ذات الصلة التي تتضمن مستوى عالٍ من الدقة والتفاصيل.
- الروابط ، التعريفات ، الأدلة ، المقارنات ، الافتراضات ، المراجع يجب أن تكون بأمثلة ملموسة ، وليس مع زغب.
- كل كلمة غير ضرورية هي تمييع للسياق والمفهوم.
عندما تقرأ ، قد يبدو الأمر سهلاً في التنفيذ ، لكنه ليس بهذه السهولة. وبالتالي ، يمكنني القول أنني كنت على وشك طرد بعض موظفيي. أنا سعيد لأنني لم أفعل ، على الأقل في الوقت الحالي. في الظروف العادية ، سيكون هناك الكثير من الأسئلة التي سيتم طرحها عليك ، إذا لم يكن مالك السؤال أحد كبار المسئولين الاقتصاديين أو مالك الشركة ، فلا تجيب. وفر طاقتك في تخزين بيانات محرك البحث الذي سيخزن ملاحظاتك الإيجابية ، وليس التعليقات الزائدة عن الحاجة وغير ذات الصلة بالتصنيفات.
6. قم بتوسيع المصدر مع الصلة بالسياق
يدور هذا القسم تمامًا حول فهم حاجة Google لإنشاء MuM. عندما تقوم بتصميم خريطة موضوعية ، فإنها ستتضمن الكثير من شبكات المحتوى الدلالية التي ستوفر قاعدة معرفية أفضل على مستوى الموقع. وبالتالي ، أثناء نشر هذه الأقسام الفرعية ، يجب أن يكونوا قادرين على الاتصال بسياق المصدر ، أو يمكنه تغيير كيفية رؤية محرك البحث للمصدر ، ويمكن لموضوع موقع الويب التبديل إلى مجال معرفة آخر. على سبيل المثال ، يتطلب ربط الأشياء حول المفاهيم ومجالات الاهتمام بالإجراءات الممكنة فهم روابط المعاني المعقدة ببعضها البعض. إن جعل هذه الاتصالات واضحة للمستخدم والكاتب وأيضًا آلة في نفس الوقت هي عملية إنشاء شبكة المحتوى الدلالية. 
لتحقيق ذلك ، يجب أن يكون كل قسم جديد في الموقع قادرًا على الاتصال بالقسم المركزي من الخريطة الموضعية. يمكن رؤية هذه الجسور السياقية من تصميم وتفسير LaMDA الخاص بـ Google.
أواجه الكثير من الأسئلة مثل "هل يجب أن أكتب عن موضوع آخر" ، "إذا كان لدي مجالان مختلفان ، فهل سيضر ذلك؟". إذا قمت بتوصيل كل هذه الأقسام الفرعية ، وأجزاء موقع الويب كمكونات مترابطة بقوة ، فإن شبكات المحتوى الدلالية هذه ستدعم بعضها البعض للحصول على تصنيفات أفضل بدلاً من تقسيم هوية العلامة التجارية ، والسلطة الموضوعية لموضوعين مختلفين وغير ذي صلة.
7. إنشاء حركة المرور الفعلية والتدقيق باستخدام التقسيم المخصص لبرنامج Google Analytics
ترتبط حركة المرور الفعلية بـ RankMerge بنفس الطريقة التي يتم بها ربط الثقة القائمة على المعرفة بـ PageRank. وسرعان ما أفكر في كتابة مقال آخر بعنوان "عندما يكذب نظام ترتيب الصفحات ..." لشرح سبب محاولة محرك البحث التأثير على نظام ترتيب الصفحات باستخدام الإشارات الجانبية. في الواقع ، لا يعد نظام ترتيب الصفحات إشارة نهائية تُظهر سلطة المصدر وخبرته وموثوقيته. يمكن أن يكون إشارة للترتيب وعاملاً ، لكن لا يمكن الوثوق به بمفرده. RankMerge هي عملية توحيد حركة مرور موقع الويب و PageRank بطريقة تجعل موقع الويب مفيدًا لمحرك البحث. يمكن أن يشير ارتفاع نظام ترتيب الصفحات وحركة المرور المنخفضة إلى "حركة المرور غير الشعبية" أو "معالجة نظام ترتيب الصفحات".
وبالتالي ، لتحسين البيانات التاريخية للمصدر ، فقد استخدمت أحداث تحسين محركات البحث الموسمية ، وقمت بزيادة استعلامات "العلامة التجارية + المصطلح العام". يتم زيادة حركة المرور المباشرة وصفحات الويب التي تم وضع إشارة مرجعية عليها مع حركة المرور الفعلية والحقيقية.
تساعد هذه الأنواع من البيانات محرك البحث على الوثوق به لترتيبه أعلى وأعلى في SERP.
لتكون قادرًا على تدقيق حركة المرور الفعلية التي تأتي من شبكة المحتوى الدلالية ، يمكن لكبار المسئولين الاقتصاديين إنشاء شريحة مخصصة من Google Analytics لمعرفة كيف تأتي كزيارات مباشرة. أيضًا ، يمكن إنشاء أهداف مخصصة مثل إنشاء رحلة بحث محتملة من شبكة المحتوى الدلالية الأولى إلى شبكة المحتوى الثانية. هذا هو دليل على المفهوم القائل بأن الشبكة الدلالية مبنية حول الاهتمامات والمفاهيم والإجراءات المحتملة المتعلقة بالبحث.
أدناه ، ستجد مثالًا واحدًا فقط لواحدة من صفحات الويب التي تم وضعها ضمن شبكة المحتوى الدلالية الأولى لتوضيح حركة المرور المباشرة المكتسبة عبر حركة المرور العضوية. 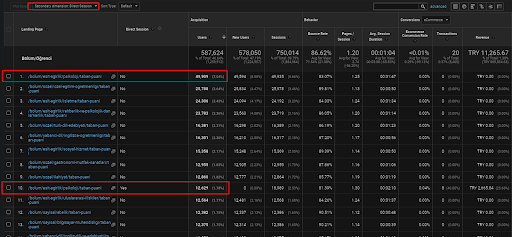
في الأشهر الثلاثة الماضية ، تم استخدام صفحة ويب واحدة فقط من شبكة المحتوى الدلالية الأولى بواسطة 49.000 مستخدم عضوي. وقد جاء 12.900 مستخدم إضافي كحركة مرور مباشرة تم الحصول عليها من خلال البحث العضوي لأول مرة. وتكون مقاييس الجلسة / الصفحة ومتوسط مدة الجلسة أعلى لشرائح المستخدمين هذه.
كما ذكرنا من قبل ، يمكن لمحرك البحث تجميع الاستعلامات والوثائق والنوايا والمفاهيم والاهتمامات والإجراءات ، ولكن يمكنه أيضًا تجميع المستخدمين. إذا تركت مجموعة مستخدمين تعليقات إيجابية أثناء إنشاء قيمة علامة تجارية عن طريق إضافة صفحات الويب هذه إلى الإشارات المرجعية ، وكتابة شريط العنوان مباشرةً ، والبحث عن المصطلحات العامة جنبًا إلى جنب مع اسم العلامة التجارية ، فهذا يوضح أن المصدر يحسن سلطته ومحرك البحث قادر على التعرف على كل شيء من SERP و Chrome وعناوين DNS الخاصة به. 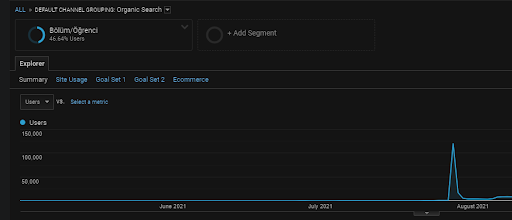
أعلاه ، يمكنك مشاهدة شريحة مستخدمي شبكة المحتوى الأولى. يمكنك إنشاء شريحة مستخدم لكل شبكة محتوى دلالية بأهداف مخصصة ، كما يمكنك إضافة مقاطع مستخدم فرعية لشبكات المحتوى الفرعي الدلالية أيضًا.
8. دعم شبكات المحتوى الدلالية بأقسام فرعية تستند إلى أنشطة البحث
يدور هذا القسم أيضًا حول تحليل سمات الكيان والتحليل وهو موضوع آخر. ولكن ، ببساطة ، يجب وضع بعض سمات هذه الكيانات بناءً على المجالات السياقية في تسلسل هرمي أدنى ، وليس في التسلسل الهرمي العلوي. في هذه الحالة ، يمكن أن تقدم "Vizem.net" مثالًا أفضل ، بينما بالنسبة لـ Bogazici Enstitusu ، يمكن إثبات ذلك من خلال "رواتب المهن" و "نقاط امتحانات الجامعات". تم وضع هاتين السمتين البارزتين بناءً على قوالب الاستعلام والمستندات لشبكات المحتوى الفرعي الدلالية. 
تحديد الوحدات الدلالية من داخل استعلام بحث هو براءة اختراع أخرى من Google تقسم العبارات إلى فئات دلالية مختلفة ، وتجمع أهمية المستند بناءً على قربه من جميع أشكال الاستعلام.
في دراسة حالة سابقة لتحسين محركات البحث ، لم أتبع هذا النوع من البنية ، لقد أنشأت مسارًا للزحف على أساس "التسلسل الزمني" والروابط الداخلية المحدودة للغاية. في هذه المقالات ، يكون مقدار الارتباط الداخلي الموضوع للمحتوى الرئيسي أعلى من المبلغ السابق.
9. استخدم الكلمات المواضيعية داخل عناوين URL
إذا واجهت Google عنواني URL مختلفين لهما نفس المحتوى بدون أي إشارة لتحديد عنوان URL ، فإنها تختار العنوان القصير باعتباره العنوان الأساسي. لأن عناوين URL القصيرة أسهل في التحليل والحل والطلب. عندما يكون لديك تريليونات من صفحات الويب التي تقوم بتحديثها مليارات المرات كل يوم ، يمكن حتى للأحرف الموجودة في عناوين URL إظهار "توازن التكلفة / الجودة" لموقع الويب. كما قلت من قبل ، يجب أن تكون "تكلفة الاسترداد" أقل من "تكلفة عدم الاسترداد". إذا كنت تريد أن يفهمك محرك البحث ، فيجب عليك وضع "إشارات السياق المرتبة والمتكاملة" في كل مستوى ، بما في ذلك عناوين URL. 
قسم من الترتيب "القائم على الأدلة" عبر تجميع الأدلة. يشرح كيف يمكن مطابقة الإجابة بسؤال.
في هذا السياق ، في معظم الأحيان ، أستخدم كلمة واحدة في عنوان URL. يمكن أن تعكس هذه التسلسل الهرمي وهيكل شبكة المحتوى الدلالية. لا يزال البعض يعتقد أن "عدد الطبقات" داخل عنوان URL يؤثر على معدل الزحف ، قبل عام 2019 ، كان هذا صحيحًا. ولكن طالما أن المحتوى منطقي ويرضي المستخدمين من موضوع شائع أو بارز ، فلن يتأثر بمثل هذا الموقف.
لإثبات ذلك ، يمكنك اتباع المثال أدناه.
- مجال الجذر / شبكة المحتوى الدلالي 1 / النوع 1 / شبكة المحتوى الفرعي جزء للنوع 1
- مجال الجذر / شبكة المحتوى الدلالي 2 / النوع 2 / شبكة المحتوى الفرعي جزء للنوع 2
يمكن لشبكتي المحتوى الدلاليين ربط بعضهما البعض من نفس التسلسل الهرمي ، ويمكنهما ربط أنفسهما بناءً على الصلة أيضًا. هناك المزيد من الأشياء التي يمكننا التحدث عنها هنا مثل "محتويات Grouper Entity - Hub Type Content" ، ولكن موضوع يوم آخر.
ملاحظة: يمكن أيضًا معالجة شبكة المحتوى الدلالي الثالثة المخطط لها باعتبارها "شبكة محتوى للهامور المفاهيمي". وإذا تم نشره ، بتأثير شبكة المحتوى الدلالية الثانية ، يمكن أن يصل إجمالي عدد الزيارات العضوية إلى أكثر من 3 ملايين جلسة في الشهر.
10. فهم الفرق بين التعشيش والتوصيل
كاختلاف منهجي عملي ، فإن الاتصال هو ربط الأشياء المتشابهة ببعضها البعض بناءً على مجال سياقي ، في حين أن التداخل هو تجميع المحتوى المماثل لنفس الغرض معًا. سيساعد هذا التجميع محرك البحث في العثور على محتوى مشابه لبعضه البعض بشكل أسرع وإنشاء نقاط جودة مصدر لهذه المجموعات ، أو ستكون هذه المحتويات المتداخلة القائمة على شبكة دلالية أسهل. 
تخيل أن هناك مسارين مختلفين للزحف على النحو التالي.
- مسار الزحف 1: يواجه عناوين URL بشكل عشوائي ، بدون نموذج أو تشابه أو صلة بالسياق.
- مسار الزحف 2: يواجه عناوين URL المنطقية حتى من عنوان URL نفسه ، مع قالب ومستوى عالٍ من التشابه والأهمية بناءً على السياق.
إذا كان المحتوى منطقيًا حتى من مسار الزحف ، فسيكون "الترتيب الأولي" و "إعادة الترتيب" أفضل بفضل "بدء إعادة التصنيف استنادًا إلى فهم تغطية محرك البحث".
ملاحظة: يعد استخدام الروابط الداخلية مع تصنيف العبارات بطريقة مناسبة أمرًا مهمًا للتداخل والاتصال.
يقودنا هذا إلى مشاركة المنهجيتين العمليتين الأخيرتين بإيجاز. وهذا القسم مرتبط مرة أخرى بالمستوى العالي من الانضباط والاكتفاء التنظيمي. 
براءة اختراع من Trystan Upstill و Steven D. Baker للتعرف على المصطلحات المتزامنة في قوائم HTML. تكمن أهمية براءة الاختراع هذه في أنها تظهر قيمة قائمة HTML واحدة لتحديد قوائم المصطلحات المتزامنة لموضوع ما ، أو جزء من تصنيف العبارة.
11. افهم متى تنشر شبكة محتوى دلالية بتردد معدل
لقد تم شرح ذلك من قبل ، ولكن في أحد مشاريع دراسة حالة تحسين محركات البحث هذه ، قمت بنشر ما يقرب من 400 جزء من المحتوى في يوم واحد. عندما يتعلق الأمر بالمحتوى الآخر ، فقد بدأت في نشر 10-15 محتوى فقط فجأة ، ثم قمت بزيادة السرعة بمرور الوقت بثبات حتى تبدأ المشكلات الاقتصادية المتعلقة بـ Covid.
إذا أنشأ مصدر جديد شبكة محتوى دلالية جديدة ، فقد يكون نشرها في اليوم الأول أصعب قليلاً مما تعتقد ، وفحص جميع الروابط الداخلية والقواعد النحوية والمعلومات على صفحة الويب ليس بهذه السهولة. ولكن ، إذا كان كل المحتوى من موضوع واحد فقط ، ونموذج استعلام ، وإذا لم يكن للمصدر أي سجل حول هذا الموضوع ، فإن نشر جزء كبير من شبكة المحتوى الدلالي له مزايا مثل الفهرسة الأسرع والفهم و إعادة الترتيب.
في وضعي ، كان هناك أيضًا حدث تاريخي موسمي. لذلك ، كان هدفي هو الحصول على مستوى كافٍ من متوسط موضع الإعلان حتى أتمكن من الاختبار بواسطة محرك البحث للكيانات وأنشطة البحث المحددة مقابل المصادر القديمة. وبالتالي ، فقد قمت بنشر أول شبكة محتوى دلالية بمستوى عالٍ من الإعداد قبل 45 يومًا من الحدث الموسمي.
بعد ذلك ، يمكنك أن ترى كيف اختبر محرك البحث المصدر بشكل متكرر على النحو التالي. 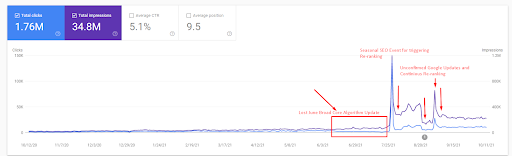
يمكن العثور على شرح أكثر تفصيلاً أدناه. 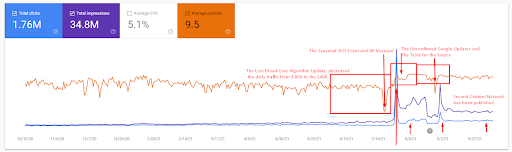
يمكن العثور أدناه على فحص سريع للحقائق للحصول على شرح لقطة الشاشة أعلاه.
- أدى تحديث الخوارزمية الأساسية العريضة إلى تقليل حركة المرور على الموقع بأكثر من 200٪.
- كما فقد الموقع أكثر من 15.000 استفسار.
- أثر هذا على الفهرسة العامة للمصدر لشبكة المحتوى الدلالية الجديدة كما هو موضح في مقالة دراسة حالة تحسين محركات البحث التفصيلية.
- بفضل حدث SEO الموسمي ، تمت إعادة الترتيب في وقت سابق ، وبعد حدث SEO الموسمي ، قام محرك البحث بتطبيع ترتيب المصدر بناءً على حركة المرور الفعلية أثناء التحديثات غير المؤكدة.
- تمت حماية الاستفسارات والتصنيفات التي تم الحصول عليها بفضل شبكة المحتوى الدلالية الأولى والحدث الموسمي وتحسينها بشكل أكبر.
- كما دعمت شبكة المحتوى الدلالية الأولى شبكة المحتوى الدلالية الجديدة والثانية.
يمكن أيضًا رؤية خسارة الاستعلام ومتوسط فقدان الترتيب من Ahrefs على النحو التالي. يمكنك التحقق من تأثير تحديث خوارزمية Google Broad Core لشهر يونيو 2021 (GBCAU) جنبًا إلى جنب مع تأثير التحديث غير المؤكد. 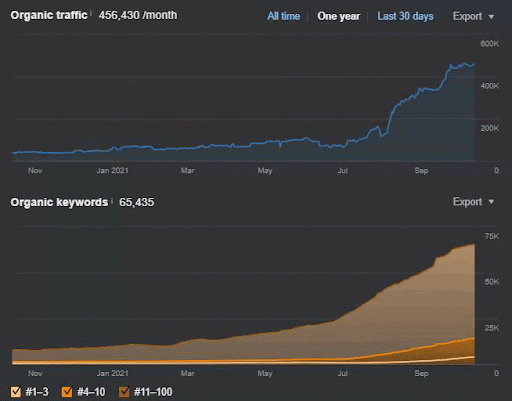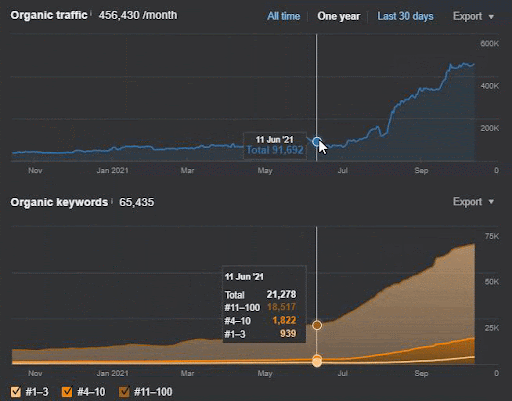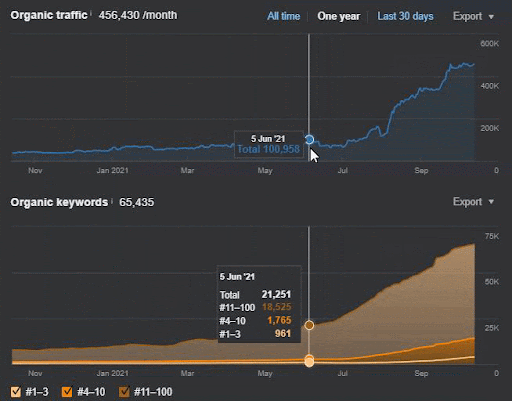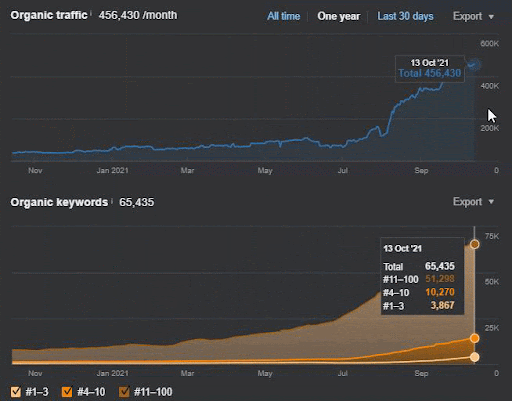
وبالتالي ، فإن استخدام شبكة المحتوى الدلالي مع العديد من الإستراتيجيات الممكنة يعد أمرًا ضروريًا. حتى في حالة فقدان GCBAU ، فلا يزال بفضل العوامل الأخرى المتعلقة بمحرك البحث natura يمكن أن تساعد مُحسّنات محرّكات البحث. وبالتالي ، قد تتخيل لماذا يكون شرح هذه الأشياء للمؤلف أو العميل أصعب من Technical SEO. لا يستخدم SEO الدلالي القيم الرقمية ، بل يستخدم المعرفة النظرية التي تأتي من فهم محرك البحث عبر براءات الاختراع والأوراق البحثية والخبرة والإعلانات التاريخية.
12. استخدم تحسين الجملة في الصفحة للحصول على بنية حقائق أفضل
لكي نكون صادقين ، حتى القائمة العاشرة هي موضوع جديد تمامًا ويمكن أن تتطلب حتى كتابة 20.000 كلمة هنا. لكني سأبدأ بمثال بسيط.
- X هي Y.
- Y هي X.
للحصول على أمثلة الجمل أعلاه ، يمكنك فهم الأشياء أدناه.
- الجمل أعلاه ليست مكررة المحتوى.
- المقترحات أعلاه مكررة.
- التفسيرات العلائقية بين جملتين هي نفسها.
- تسميات الأدوار الدلالية مختلفة بنسبة 100٪.
- إخراج التعرف على الكيانات المسماة 100٪ هو نفسه.
يرتبط تحسين الجملة في الصفحة بخوارزميات إنشاء الأسئلة وتقنيات إقران الأسئلة والإجابات. يتطلب تنسيق السؤال نوعًا معينًا من الجملة. ويجب الإجابة على أنواع معينة من الأسئلة بأنواع معينة من الجمل. سيتأثر تنسيق المحتوى و NER و Fact Extraction من تحسين بنية الجملة. 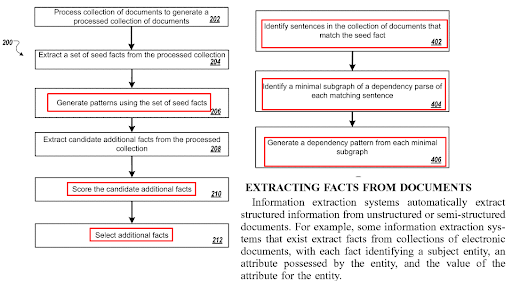
يمكن استخراج الثلاثة توائم (كائن واحد ، موضوعان) والتحقق من دقتها بشكل أسرع. جملتان متشابهتان لا تعنيان أنهما مكررتان ، فهذا يعني أنهما قريبان من بعضهما البعض من حيث بنية الجملة. طالما أن الاقتراح مختلف ، فإن استخدام جمل متشابهة بين قوالب المستندات المتشابهة لأزواج مختلفة من الاستفسار والهدف هو أمر ضروري لإنشاء شبكة المحتوى الدلالية. 
تعد تراكيب الجمل الواضحة ذات النمط المناسب مفيدة لجعل الأجزاء النصية أكثر صلة ببعضها البعض بينما تساعد محرك البحث في التعرف على الكيانات المسماة والموضوعات والسمات بالإضافة إلى قيمها لبعضها البعض.
سيساعد أيضًا في معرفة أي قسم من المقالة يمكن تحسينه ، وفي شبكات المواضيع ، حيث يتم ترتيب المحتوى الخاص بك بشكل أفضل لأنواع أزواج الكلمات ، ونواقل الكلمات والنوايا. لأنه إذا كان من الممكن ملاحظة أنواع معينة من تراكيب الجمل لأنواع معينة من الأسئلة عبر صفحات ويب متعددة ، فسوف يساعد ذلك في اختبارات A / B المتقدمة لتحسين محركات البحث مع كميات لا حصر لها من عينات البيانات وعينات الاختبار. يمكنك إنشاء تصميمات جمل متعددة في الصفحة للتحقق من كيفية استخلاص محرك البحث للحقائق لمقارنتها. 
عندما يتعلق الأمر بتقديم الحقائق ، يجب تذكر "قبو المعرفة" ولونا دونغ.
13. إعطاء معلومات واقعية عن العالم بدقة واتساق وليس آراء مع زغب
الدقة هنا تعني القدرة على المقارنة مع القيم الرقمية ، أو العلاقات الملموسة المفاهيمية. الاتساق يعني أنك تحمي موقفك من الاقتراح المحدد. على سبيل المثال ، لا تقل أن "منتج X هو الأفضل لـ Y" لكل مراجعة للمنتج تتعلق بـ Y. لا تقدم مقترحات متناقضة على مستوى الموقع. وإذا كان المنتج هو الأفضل فما الدليل على ذلك؟ المادة أم الحجم أم اللون والرائحة؟ تعني كلمة Fluff في النص أنك تستخدم كلمات جسر غير ضرورية ، أو لا تخبر أشياء لا يمكن إثباتها أو مناقضتها للحقيقة.
في سياق هذه الإرشادات غير التعريفية التي تدعمها بعض الأمثلة ، يمكنك التحقق من أحد نماذج اللغة في Google وهو KeALM.
إنه لتوليد نص من قاعدة بيانات بنماذج تحويل البيانات إلى نص ، وللتحقق من دقة المحتوى. 
KELM هو مثال على تدقيق الدقة للمقترحات باستخدام طرق تحويل النص إلى بيانات.
هذا أيضًا يتعلق قليلاً بتعريف "Triplet" و "Open Information Extraction for Unknown Entities" ، ولكن كما تعلم ، هذه هي النسخة المختصرة ، وأعتقد ، لقد قلت بما فيه الكفاية. بشكل أساسي ، عندما تقدم معلومات خاطئة على موقع الويب الخاص بك ، تأكد من أن Google قادرة على فهمها لتقليل الثقة القائمة على المعرفة للمصدر. هنا ، قد تحتاج أيضًا إلى معرفة أنه نظرًا لأنك قادر على توسيع قاعدة المعرفة ، يمكن لمحرك البحث تغيير قاعدة المعرفة الخاصة به بناءً على معلوماتك ، إذا كان لديك مصدر مرتبط بنظام PageRank وثقة قاعدة المعرفة بدقة عالية وثلاثة توائم فريدة.
14. فهم شجرة التبعية الدلالية للكيانات
تعني شجرة التبعية الدلالية أن السمات التي تشير إلى العلاقات مع الكيانات الأخرى لها تبعية هرمية فيما بينها. يمكن ملاحظة شجرة التبعية الدلالية عن طريق التحقق من ملفات تعريف وزوايا كيانات متعددة مثل بلد ما يمكن أن يكون عضوًا في منظمة ، وككيان آخر ، يمكن أن يكون لهذه المنظمة بعض السمات الأخرى التي يمكن أن تُعزى إلى البلدان المتصلة ذات العلاقات المستنتجة.
أدناه ، سوف تكون قادرًا على رؤية مثال بسيط من محرك البحث مباشرةً. 
REALM هي طريقة تستخدم أشجار التبعية الدلالية لاستخراج المعلومات من نص غامض.
على الويب المفتوح ، يمكن لاستخراج المعلومات المفتوحة التعرف على الكيانات المسماة الجديدة ، واستخراج هذه الكيانات نفسها التي تحدث مع كيانات أخرى. يمكن لهذه التكرارات المشتركة والسمات المتبادلة داخل المقالة تعيين سياق ونوع علاقة المرشح بين الكيانات. بناءً على الاتصالات ونوع الكيان ، يمكن إنشاء شجرة التبعية الدلالية. يحدث نفس المنطق مع معجم المعاني أيضًا. لكلمة "ولد" بعض المعاني الممكنة وبعض المعاني الأخرى الدقيقة. مثل ، الصبي ذكر ، وربما مراهق غير متزوج. يمكن استخدامه بالقرب من الطالب أيضًا. من ناحية أخرى ، تتضمن كلمة "ملكة" معاني جانبية ودقيقة أخرى مثل "أنثى" و "كونها حاكمة". وبالتالي ، فإن وجود شيء ما يمكن التحكم فيه هو تسلسل هرمي لشجرة التبعية الدلالية الطبيعية الذي يمكن أن يشير إلى بعض أنواع قوالب الاستعلام مثل "ملكة ..." أو "من أجل كوين". These contextual layers with context qualifiers should be united naturally with contextual domains and knowledge domains for improving the topical and contextual coverage together. 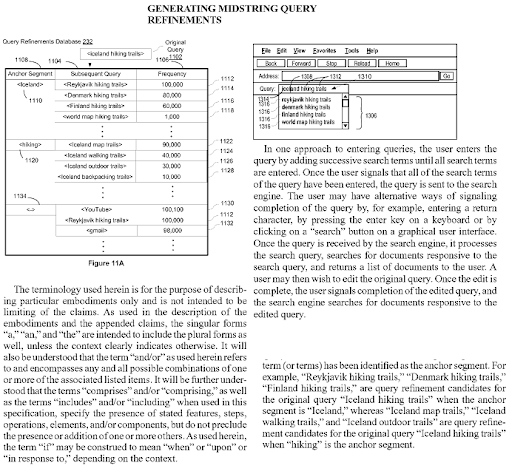
Generating Midstring Query Refinements is another Google Patent that shows the Semantic Content Network's connections to each other. Every midstring query refinement is a part of the topic's sub-topical net. A semantic content network that focuses on all these query refinement candidates with the correct semantic annotations will have the advantage of better re-ranking and initial ranking.
Last Thoughts on Semantic Content Network
I know that this content was highly technical in terms of Semantic SEO. And, before publishing my Semantic SEO Course, I still want to increase the knowledge, so that the first theoretical lessons can be digested by our minds faster than usual. The Semantic Content Networks can be defined as the sum of topical map, and individual content designs that include all of the headings, questions, heading levels, anchor texts, content hierarchy, and positions within the site-tree, or anything related to the content piece, including the featured images and in-page detailed images.
Here, besides the in-page sentence structure designs, or question-answer formats, or synonym sentence formats, we can also talk about the contextual vectors, contextual hierarchies, sequential sentences with bridged contexts, or evidence-based ranking by evidence aggregation. All these things would make this SEO Case Study and Guide more complicated but yet detailed. Thus, like in the previous, Importance of Topical Authority SEO Case Study and Guide, explaining Semantic Networks would make that article more complicated but yet detailed.
The future SEO Case Studies will include more and more details by supporting the previous ones. Lastly, I have gotten lots of screenshots and thank you messages from all of you that show the positive results that you have gotten thanks to Topical Authority understanding. I hope, Initial-ranking, and Re-ranking along with the Semantic Content Network understanding help you further.
See you in the next SEO Case Studies.
“The acquisition of knowledge is always of use to
the intellect, because it may thus drive out useless
things and retain the good. For nothing can be
loved or hated unless it is first known.”
– Leonardo da Vinci.