
التحكم في الزحف والفهرسة: دليل تحسين محركات البحث لملف robots.txt والعلامات
نشرت: 2019-02-19يعد تحسين ميزانية الزحف وحظر الروبوتات من فهرسة الصفحات مفاهيم مألوفة لدى العديد من مُحسّنات محرّكات البحث. لكن الشيطان يكمن في التفاصيل. خاصة وأن أفضل الممارسات قد تغيرت بشكل كبير خلال السنوات الأخيرة.
يمكن أن يكون لتغيير واحد صغير في ملف robots.txt أو علامات برامج الروبوت تأثير كبير على موقع الويب الخاص بك. لضمان أن يكون التأثير إيجابيًا دائمًا لموقعك ، سنتعمق اليوم في:
تحسين ميزانية الزحف
ما هو ملف Robots.txt
ما هي علامات Meta Robots
ما هي X-Robots-Tags
توجيهات الروبوتات وكبار المسئولين الاقتصاديين
قائمة مراجعة أفضل ممارسة للروبوتات
تحسين ميزانية الزحف
يحتوي عنكبوت محرك البحث على "بدل" لعدد الصفحات التي يمكنه الزحف إليها على موقعك ويريد الزحف إليها. يُعرف هذا باسم "ميزانية الزحف".
ابحث عن ميزانية الزحف لموقعك في تقرير "إحصائيات الزحف" في Google Search Console (GSC). لاحظ أن GSC عبارة عن إجمالي 12 روبوتًا ليست جميعها مخصصة لتحسين محركات البحث. كما أنه يجمع برامج AdWords أو AdSense التي تعد روبوتات SEA. وبالتالي ، تمنحك هذه الأداة فكرة عن ميزانية الزحف العالمية الخاصة بك ولكن ليس إعادة تقسيمها بدقة.
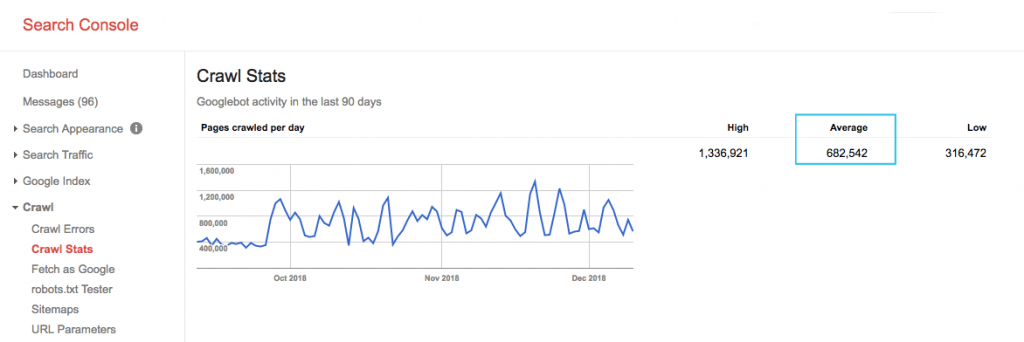
لجعل الرقم أكثر قابلية للتنفيذ ، قسّم متوسط الصفحات التي يتم الزحف إليها يوميًا على إجمالي الصفحات القابلة للزحف على موقعك - يمكنك أن تطلب من المطور الخاص بك العدد أو تشغيل زاحف غير محدود للموقع. سيعطيك هذا نسبة زحف متوقعة لكي تبدأ في التحسين.
هل تريد التعمق أكثر؟ احصل على توزيع أكثر تفصيلاً لنشاط Googlebot ، مثل الصفحات التي تتم زيارتها ، بالإضافة إلى إحصائيات برامج الزحف الأخرى ، عن طريق تحليل ملفات سجل خادم موقعك.
هناك العديد من الطرق لتحسين ميزانية الزحف ، ولكن من السهل البدء بالتحقق من تقرير "التغطية" في GSC لفهم سلوك Google الحالي في الزحف والفهرسة.
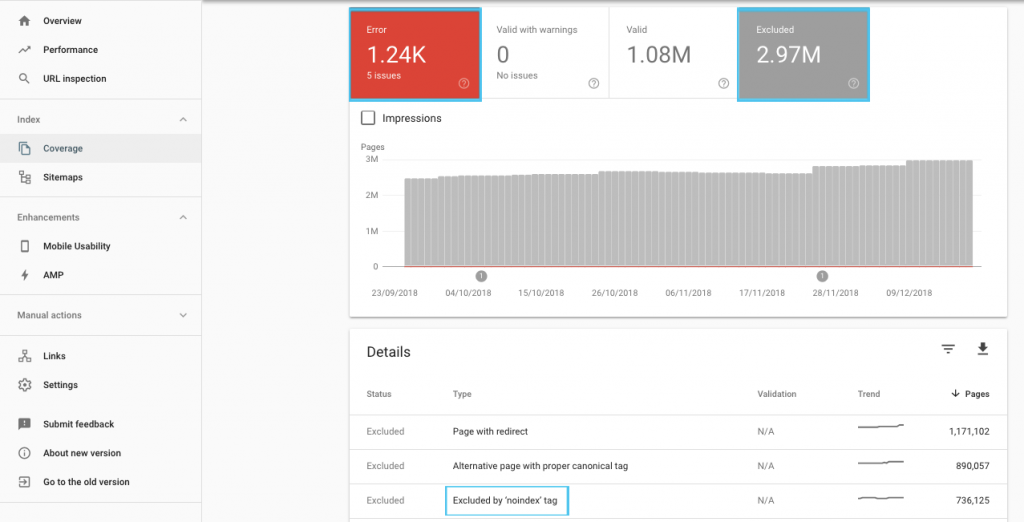
إذا رأيت أخطاء مثل "عنوان URL المُرسَل تم وضع علامة عليه" noindex "أو" عنوان URL المُرسل محظور بواسطة robots.txt "، فاعمل مع مطور البرامج لإصلاحها. بالنسبة إلى أي استثناءات للروبوتات ، تحقق منها لفهم ما إذا كانت استراتيجية من منظور تحسين محركات البحث.
بشكل عام ، يجب أن تهدف مُحسنات محركات البحث إلى تقليل قيود الزحف على الروبوتات. يعد تحسين بنية موقع الويب الخاص بك لجعل عناوين URL مفيدة ويمكن الوصول إليها لمحركات البحث هي أفضل استراتيجية.
تلاحظ Google نفسها أن "بنية المعلومات القوية من المرجح أن تكون استخدامًا أكثر إنتاجية للموارد من التركيز على تحديد أولويات الزحف".
ومع ذلك ، من المفيد فهم ما يمكن فعله مع ملفات robots.txt وعلامات الروبوتات لتوجيه الزحف والفهرسة وتمرير حقوق الارتباط. والأهم من ذلك ، متى وكيف يمكن الاستفادة منها بشكل أفضل لتحسين محركات البحث الحديثة.
[دراسة حالة] إدارة زحف روبوت Google
 اقرأ دراسة الحالة
اقرأ دراسة الحالةما هو ملف Robots.txt
قبل أن يقوم محرك البحث عناكب أية صفحة ، فإنه سيفحص ملف robots.txt. يخبر هذا الملف الروبوتات بمسارات عناوين URL التي لديهم الإذن بزيارتها. لكن هذه الإدخالات هي فقط توجيهات وليست تفويضات.
لا يمكن لملف Robots.txt منع الزحف بشكل موثوق مثل جدار الحماية أو الحماية بكلمة مرور. إنه المكافئ الرقمي لإشارة "من فضلك ، لا تدخل" على باب مفتوح.
ستلتزم برامج الزحف المهذبة ، مثل محركات البحث الرئيسية ، بالتعليمات بشكل عام. برامج الزحف المعادية ، مثل برامج كاشط البريد الإلكتروني و spambots والبرامج الضارة والعناكب التي تبحث عن نقاط ضعف الموقع ، غالبًا ما لا تولي أي اهتمام.
علاوة على ذلك ، إنه ملف متاح للعامة . يمكن لأي شخص رؤية توجيهاتك.
لا تستخدم ملف robots.txt الخاص بك من أجل:
- لإخفاء المعلومات الحساسة. استخدم الحماية بكلمة مرور.
- لمنع الوصول إلى موقع التدريج و / أو التطوير. استخدم المصادقة من جانب الخادم.
- لمنع برامج الزحف المعادية بشكل صريح. استخدم حظر IP أو حظر وكيل المستخدم (المعروف أيضًا باسم منع وصول زاحف محدد بقاعدة في ملف .htaccess أو أداة مثل CloudFlare).
يجب أن يحتوي كل موقع على ملف robots.txt صالح مع تجميع توجيه واحد على الأقل. بدون واحد ، يتم منح جميع برامج الروبوت حق الوصول الكامل بشكل افتراضي - لذلك يتم التعامل مع كل صفحة على أنها قابلة للزحف. حتى لو كان هذا هو ما تنوي القيام به ، فمن الأفضل توضيح ذلك لجميع أصحاب المصلحة باستخدام ملف robots.txt. بالإضافة إلى ذلك ، بدون واحد ، ستكون سجلات الخادم مليئة بالطلبات الفاشلة لملف robots.txt.
هيكل ملف robots.txt
ليتم الاعتراف بواسطة برامج الزحف ، يجب أن يقوم ملف robots.txt الخاص بك بما يلي:
- كن ملفًا نصيًا باسم "robots.txt". اسم الملف حساس لحالة الأحرف. لن تعمل "Robots.TXT" أو الأشكال الأخرى.
- كن موجودًا في دليل المستوى الأعلى لنطاقك الأساسي ، وإذا كان ذلك مناسبًا ، في النطاقات الفرعية. على سبيل المثال ، للتحكم في الزحف على جميع عناوين URL أدناه https://www.example.com ، يجب وضع ملف robots.txt على https://www.example.com/robots.txt وللمجال الفرعي subdomain.example.com على subdomain.example.com/robots.txt.
- إرجاع حالة HTTP 200 موافق.
- استخدم بنية ملف robots.txt صالحة - تحقق من ذلك باستخدام أداة اختبار Google Search Console robots.txt.
يتكون ملف robots.txt من مجموعات من التوجيهات. تتكون الإدخالات في الغالب من:
- 1. وكيل المستخدم: يخاطب برامج الزحف المختلفة. يمكنك الحصول على مجموعة واحدة لجميع الروبوتات أو استخدام المجموعات لتسمية محركات بحث معينة.
- 2. Disallow: يحدد الملفات أو الأدلة التي سيتم استبعادها من الزحف إليها بواسطة وكيل المستخدم أعلاه. يمكن أن يكون لديك واحد أو أكثر من هذه الخطوط في كل كتلة.
للحصول على قائمة كاملة بأسماء وكلاء المستخدم والمزيد من الأمثلة التوجيهية ، راجع دليل robots.txt على Yoast.
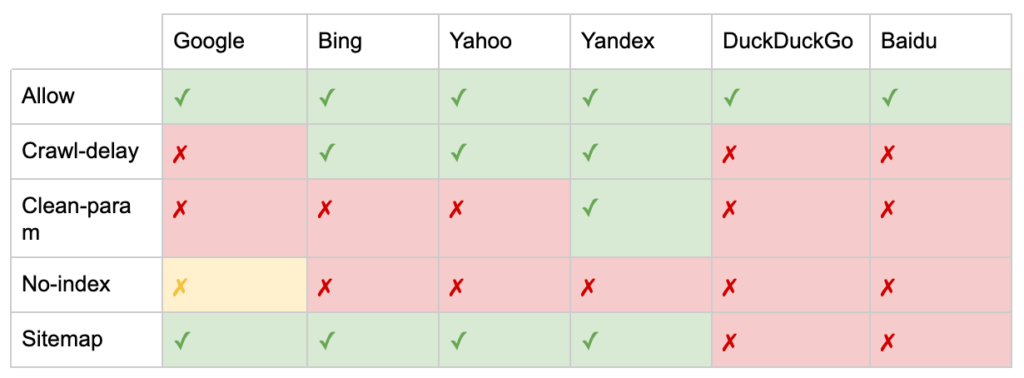
بالإضافة إلى توجيهات "User-agent" و "Disallow" ، هناك بعض التوجيهات غير القياسية:
- Allow: حدد استثناءات لتوجيه عدم السماح بدليل رئيسي.
- تأخير الزحف: خنق برامج الزحف الثقيلة بإخبار الروبوتات بعدد الثواني التي يجب أن تنتظرها قبل زيارة الصفحة. إذا كنت تحصل على عدد قليل من الجلسات العضوية ، فيمكن أن يؤدي تأخير الزحف إلى توفير النطاق الترددي للخادم. لكنني لا أستثمر جهدي إلا إذا كانت برامج الزحف تتسبب في حدوث مشكلات في تحميل الخادم. لا تقر Google بهذا الأمر ، وتوفر خيارًا لتقييد معدل الزحف في Google Search Console.
- Clean-param: تجنب إعادة الزحف إلى المحتوى المكرر الذي تم إنشاؤه بواسطة المعلمات الديناميكية.
- بدون فهرس: مصمم للتحكم في الفهرسة بدون استخدام أي ميزانية للزحف. لم يعد مدعومًا رسميًا من قِبل Google. في حين أن هناك دليلًا على أنه قد يكون لا يزال له تأثير ، إلا أنه لا يمكن الاعتماد عليه ولا يوصي به خبراء مثل جون مولر.
maxxeightgoogleDeepCrawl كنت أتجنب استخدام noindex هناك.
- ؟؟؟؟ يوحنا ؟؟؟؟ (JohnMu) 1 سبتمبر 2015
- خريطة الموقع: الطريقة المثلى لإرسال خريطة موقع XML الخاصة بك هي عبر Google Search Console وأدوات مشرفي المواقع الأخرى لمحركات البحث. ومع ذلك ، فإن إضافة توجيه خريطة الموقع في قاعدة ملف robots.txt الخاص بك يساعد برامج الزحف الأخرى التي قد لا تقدم خيار إرسال.
حدود ملف robots.txt لتحسين محركات البحث
نحن نعلم بالفعل أن ملف robots.txt لا يمكنه منع الزحف لجميع برامج الروبوت. وبالمثل ، فإن عدم السماح لبرامج الزحف من الصفحة لا يمنع تضمينها في صفحات نتائج محرك البحث (SERPs).
إذا كانت الصفحة المحظورة تحتوي على إشارات ترتيب قوية أخرى ، فقد تعتبرها Google ذات صلة لتظهر في نتائج البحث. على الرغم من عدم الزحف إلى الصفحة.
نظرًا لأن محتوى عنوان URL هذا غير معروف لمحرك البحث Google ، فإن نتيجة البحث تبدو على النحو التالي:

لمنع صفحة ما بشكل نهائي من الظهور في SERPs ، تحتاج إلى استخدام العلامة الوصفية لبرامج الروبوت "noindex" أو رأس X-Robots-Tag HTTP.
في هذه الحالة ، لا تمنع الصفحة في ملف robots.txt ، لأنه يجب الزحف إلى الصفحة حتى يمكن رؤية علامة "noindex" والامتثال لها. إذا تم حظر عنوان URL ، فستكون جميع علامات برامج الروبوت غير فعالة.
علاوة على ذلك ، إذا كانت الصفحة قد جمعت الكثير من الروابط الواردة ، ولكن تم حظر Google من الزحف إلى هذه الصفحات عن طريق ملف robots.txt ، بينما تكون الروابط معروفة لجوجل ، يتم فقد قيمة الارتباط .
ما هي علامات Meta Robots
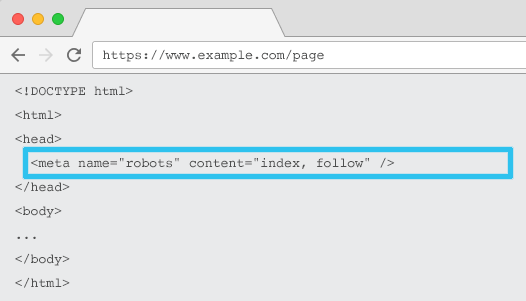
عند وضعه في HTML لكل عنوان URL ، يخبر meta name = "robots" برامج الزحف بما إذا كان يجب "فهرسة" المحتوى وكيفية "متابعة" (أي الزحف) إلى جميع الروابط الموجودة على الصفحة ، مع تمرير حقوق الارتباط.
باستخدام meta name العام = "robots" ، يتم تطبيق التوجيه على جميع برامج الزحف. يمكنك أيضًا تحديد وكيل مستخدم معين. على سبيل المثال ، meta name = ”googlebot”. ولكن من النادر أن تحتاج إلى استخدام علامات تعريف روبوتات متعددة لتعيين إرشادات لعناكب معينة.
هناك نوعان من الاعتبارات الهامة عند استخدام العلامات الوصفية لبرامج الروبوت:
- على غرار ملف robots.txt ، فإن العلامات الوصفية عبارة عن توجيهات وليست تفويضات ، لذلك قد يتم تجاهلها من قبل بعض برامج الروبوت.
- ينطبق التوجيه nofollow لبرامج الروبوت على الروابط الموجودة في تلك الصفحة فقط. من الممكن أن يتبع الزاحف الرابط من صفحة أو موقع ويب آخر بدون nofollow. لذلك قد يستمر الروبوت في الوصول إلى صفحتك غير المرغوب فيها وفهرستها.
فيما يلي قائمة بجميع توجيهات العلامات الوصفية لبرامج الروبوت:
- الفهرس: يخبر محركات البحث بإظهار هذه الصفحة في نتائج البحث. هذه هي الحالة الافتراضية إذا لم يتم تحديد توجيه.
- noindex: تخبر محركات البحث بعدم إظهار هذه الصفحة في نتائج البحث.
- تابع: يطلب من محركات البحث متابعة جميع الروابط الموجودة في هذه الصفحة وتمرير حقوق الملكية ، حتى لو لم تتم فهرسة الصفحة. هذه هي الحالة الافتراضية إذا لم يتم تحديد توجيه.
- nofollow: يخبر محركات البحث بعدم اتباع أي رابط في هذه الصفحة أو تمرير حقوق الملكية.
- الكل: يعادل "index، follow".
- لا شيء: يعادل "noindex، nofollow".
- noimageindex: يخبر محركات البحث بعدم فهرسة أي صور في هذه الصفحة.
- noarchive: يخبر محركات البحث بعدم إظهار ارتباط مخبأ لهذه الصفحة في نتائج البحث.
- nocache: مثل noarchive ، لكن يستخدمه فقط Internet Explorer و Firefox.
- nosnippet: يخبر محركات البحث بعدم إظهار وصف تعريفي أو معاينة فيديو لهذه الصفحة في نتائج البحث.
- notranslate: يخبر محرك البحث بعدم تقديم ترجمة لهذه الصفحة في نتائج البحث.
- unavailable_after: أخبر محركات البحث بعدم فهرسة هذه الصفحة بعد تاريخ محدد.
- noodp: تم إهماله الآن ، فقد منع محركات البحث ذات مرة من استخدام وصف الصفحة من DMOZ في نتائج البحث.
- noydir: تم إهماله الآن ، فقد منع Yahoo مرة واحدة من استخدام وصف الصفحة من دليل Yahoo في نتائج البحث.
- noyaca: يمنع Yandex من استخدام وصف الصفحة من دليل Yandex في نتائج البحث.
كما هو موثق من قبل Yoast ، لا تدعم جميع محركات البحث جميع العلامات الوصفية لبرامج الروبوت ، أو حتى توضح ما تفعله وما لا تدعمه.
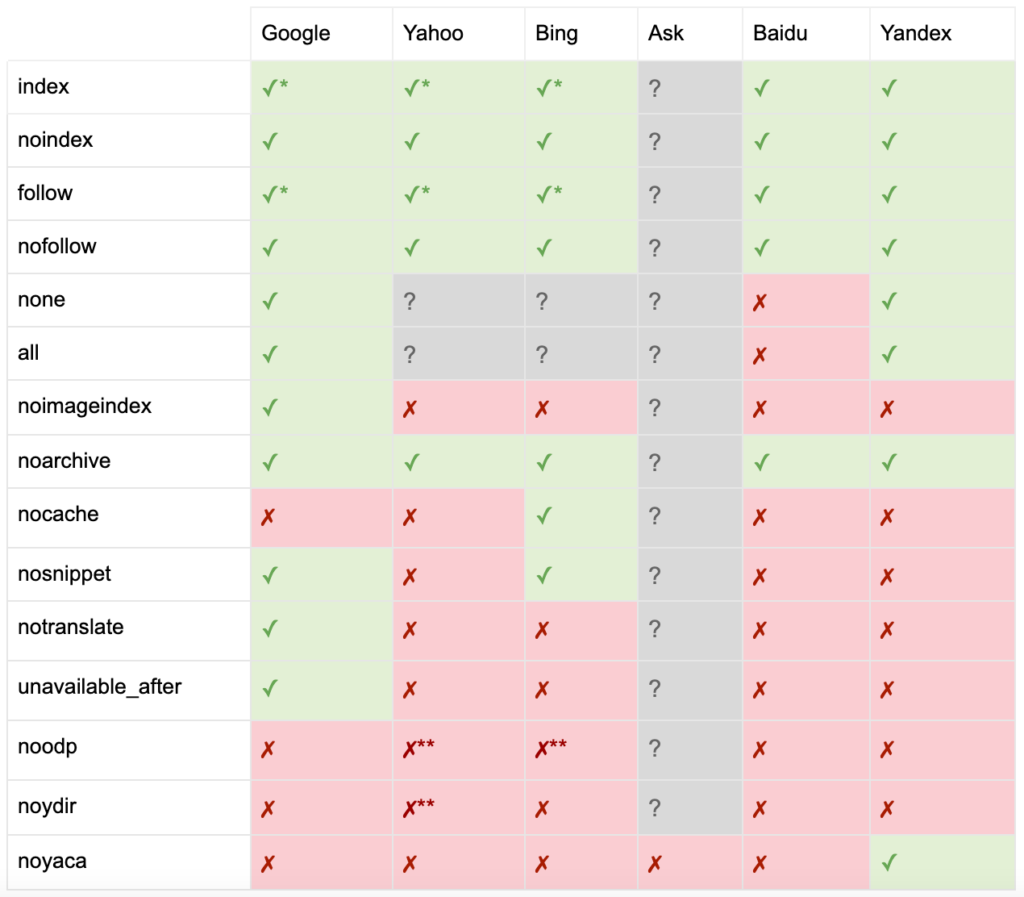
* معظم محركات البحث ليس لديها وثائق محددة لهذا ، ولكن من المفترض أن دعم استبعاد المعلمات (على سبيل المثال ، nofollow) يعني دعم المكافئ الإيجابي (على سبيل المثال ، متابعة).
** بينما قد تظل سمات noodp و noydir "مدعومة" ، لم تعد الدلائل موجودة ، ومن المحتمل أن هذه القيم لا تفعل شيئًا.

بشكل عام ، سيتم تعيين علامات برامج الروبوت على "فهرسة ، متابعة". يرى بعض مُحسّنات محرّكات البحث إضافة هذه العلامة في HTML على أنها زائدة عن الحاجة لأنها العلامة الافتراضية. الحجة المضادة هي أن تحديدًا واضحًا للتوجيهات قد يساعد في تجنب أي ارتباك بشري.
قم بالملاحظة: سيتم الزحف إلى عناوين URL التي تحتوي على علامة "noindex" بشكل أقل تكرارًا ، وإذا كانت موجودة لفترة طويلة ، فستؤدي في النهاية إلى جعل Google لا يتبع روابط الصفحة.
من النادر العثور على حالة استخدام لـ "nofollow" مع جميع الروابط الموجودة على صفحة بعلامة meta robots. من الشائع أكثر مشاهدة إضافة "nofollow" إلى الروابط الفردية باستخدام سمة الارتباط rel = ”nofollow”. على سبيل المثال ، قد ترغب في إضافة سمة rel = ”nofollow” إلى التعليقات التي ينشئها المستخدم أو الروابط المدفوعة.
من النادر وجود حالة استخدام مُحسّنات محرّكات البحث (SEO) لتوجيهات علامات برامج الروبوت التي لا تتناول الفهرسة الأساسية وتتبع السلوك ، مثل التخزين المؤقت وفهرسة الصور ومعالجة المقتطفات ، وما إلى ذلك.
يتمثل التحدي في علامات meta robots في أنه لا يمكن استخدامها لملفات بخلاف ملفات HTML مثل الصور أو الفيديو أو مستندات PDF. هذا هو المكان الذي يمكنك فيه الرجوع إلى X-Robots-Tags.
ما هي X-Robots-Tags
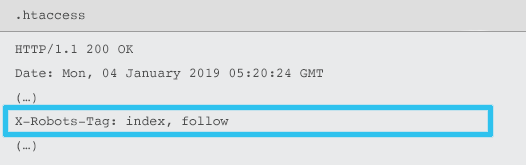
يتم إرسال X-Robots-Tag بواسطة الخادم كعنصر في رأس استجابة HTTP لعنوان URL محدد باستخدام ملفات .htaccess و httpd.conf.
يمكن أيضًا تحديد أي توجيه للعلامة الوصفية لبرامج الروبوت كعلامة X-Robots-Tag. ومع ذلك ، توفر علامة X-Robots-Tag بعض المرونة والوظائف الإضافية في الأعلى.
يمكنك استخدام X-Robots-Tag بدلاً من العلامات الوصفية لبرامج الروبوت إذا كنت تريد:
- التحكم في سلوك الروبوتات للملفات التي ليست بتنسيق HTML ، بدلاً من ملفات HTML وحدها.
- التحكم في فهرسة عنصر معين من الصفحة ، وليس الصفحة ككل.
- أضف قواعد إلى ما إذا كان يجب فهرسة الصفحة أم لا. على سبيل المثال ، إذا كان المؤلف لديه أكثر من 5 مقالات منشورة ، فقم بفهرسة صفحة ملفه الشخصي.
- تطبيق الفهرس واتباع التوجيهات على مستوى الموقع بالكامل ، بدلاً من تحديد الصفحة.
- استخدم التعبيرات العادية.
تجنب استخدام كل من meta robots و x-robots-tag في نفس الصفحة - سيكون القيام بذلك زائدًا عن الحاجة.
لعرض علامات X-Robots-Tags ، يمكنك استخدام ميزة "الجلب مثل Google" في Google Search Console.
توجيهات الروبوتات وكبار المسئولين الاقتصاديين
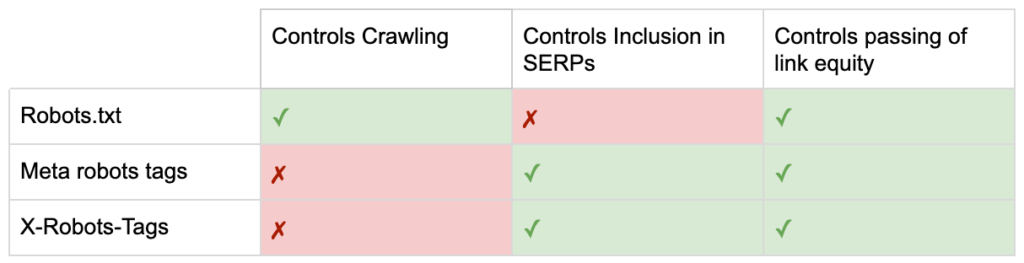
الآن أنت تعرف الاختلافات بين توجيهات الروبوتات الثلاثة.
يركز ملف robots.txt على حفظ ميزانية الزحف ، ولكنه لن يمنع ظهور الصفحة في نتائج البحث. إنه بمثابة حارس البوابة الأول لموقع الويب الخاص بك ، حيث يوجه الروبوتات بعدم الوصول قبل طلب الصفحة.
يركز كلا النوعين من علامات برامج الروبوت على التحكم في الفهرسة وتمرير حقوق الارتباط. لا تكون العلامات الوصفية لبرامج الروبوت فعالة إلا بعد تحميل الصفحة . بينما توفر رؤوس X-Robots-Tag مزيدًا من التحكم الدقيق وتكون فعالة بعد استجابة الخادم لطلب الصفحة.
من خلال هذا الفهم ، يمكن لتحسين محركات البحث تطوير الطريقة التي نستخدم بها توجيهات الروبوتات لحل تحديات الزحف والفهرسة.
منع الروبوتات لحفظ النطاق الترددي للخادم
المشكلة: عند تحليل ملفات السجل ، سترى العديد من وكلاء المستخدم يستهلكون النطاق الترددي ولكنهم يعيدون القليل من القيمة.
- زواحف تحسين محركات البحث ، مثل MJ12bot (من Majestic) أو Ahrefsbot (من Ahrefs).
- الأدوات التي تحفظ المحتوى الرقمي في وضع عدم الاتصال ، مثل Webcopier أو Teleport.
- محركات البحث غير المناسبة لسوقك ، مثل Baiduspider أو Yandex.
الحل دون الأمثل: حظر هذه العناكب باستخدام ملف robots.txt لأنه ليس مضمونًا ليتم تكريمه وهو إعلان عام إلى حد ما ، والذي يمكن أن يمنح الأطراف المهتمة رؤى تنافسية.
نهج أفضل الممارسات: التوجيه الأكثر دقة لحظر وكيل المستخدم. يمكن تحقيق ذلك بطرق مختلفة ، ولكن يتم إجراؤه عادةً عن طريق تحرير ملف .htaccess لإعادة توجيه أي طلبات عنكبوت غير مرغوب فيها إلى صفحة 403 - محظورة.
صفحات البحث في الموقع الداخلي تستخدم ميزانية الزحف
المشكلة: في العديد من مواقع الويب ، يتم إنشاء صفحات نتائج بحث الموقع الداخلي ديناميكيًا على عناوين URL الثابتة ، والتي تستهلك بعد ذلك ميزانية الزحف وقد تتسبب في محتوى ضعيف أو مشكلات محتوى مكررة إذا تمت فهرستها.
الحل دون الأمثل: عدم السماح بالدليل باستخدام ملف robots.txt. على الرغم من أن هذا قد يمنع مصائد الزاحف ، إلا أنه يحد من قدرتك على الترتيب لعمليات بحث العملاء الرئيسية ولمثل هذه الصفحات لتمرير ملكية الارتباط.
نهج أفضل الممارسات: تعيين الاستعلامات ذات الصلة عالية الحجم إلى عناوين URL الموجودة في محرك البحث. على سبيل المثال ، إذا كنت أبحث عن "هاتف سامسونج" ، بدلاً من إنشاء صفحة جديدة لـ / search / samsung-phone ، أعد التوجيه إلى / phones / samsung.
عندما لا يكون ذلك ممكنًا ، قم بإنشاء عنوان URL يعتمد على معلمة. يمكنك بعد ذلك بسهولة تحديد ما إذا كنت تريد الزحف إلى المعلمة أم لا داخل Google Search Console.
إذا سمحت بالزحف ، فقم بتحليل ما إذا كانت هذه الصفحات ذات جودة عالية بما يكفي لترتيبها. إذا لم يكن الأمر كذلك ، فقم بإضافة "noindex ، اتبع" التوجيه كحل قصير المدى أثناء وضع إستراتيجية لكيفية تحسين جودة النتائج لمساعدة كل من تحسين محركات البحث وتجربة المستخدم.
منع المعلمات مع الروبوتات
المشكلة: معلمات سلسلة الاستعلام ، مثل تلك التي تم إنشاؤها بواسطة التنقل أو التتبع ذات الأوجه ، تشتهر باستهلاك ميزانية الزحف ، وإنشاء عناوين URL مكررة للمحتوى وتقسيم إشارات الترتيب.
الحل دون الأمثل: عدم السماح بالزحف إلى المعلمات باستخدام ملف robots.txt أو باستخدام العلامة الوصفية لبرامج الروبوت "noindex" ، حيث إن كليهما (الأول على الفور ، والآخر على مدى فترة أطول) سيمنع تدفق قيمة الروابط.
نهج أفضل الممارسات: تأكد من وجود سبب واضح لكل معلمة لوجود قواعد الطلب وتنفيذها ، والتي تستخدم المفاتيح مرة واحدة فقط وتمنع القيم الفارغة. أضف سمة ارتباط rel = canonical إلى صفحات المعلمات المناسبة للجمع بين القدرة على الترتيب. ثم قم بتهيئة جميع المعلمات في Google Search Console ، حيث يوجد خيار أكثر دقة لتوصيل تفضيلات الزحف. لمزيد من التفاصيل ، راجع دليل معالجة معلمات Search Engine Journal.
حظر مناطق الإدارة أو الحساب
المشكلة: منع محرك البحث من الزحف إلى أي محتوى خاص وفهرسته.
الحل دون الأمثل: استخدام ملف robots.txt لحظر الدليل لأن هذا غير مضمون لإبقاء الصفحات الخاصة خارج SERPs.
نهج أفضل الممارسات: استخدم الحماية بكلمة مرور لمنع برامج الزحف من الوصول إلى الصفحات وتراجع توجيه "noindex" في رأس HTTP.
حظر الصفحات المقصودة للتسويق وصفحات الشكر
المشكلة: غالبًا ما تحتاج إلى استبعاد عناوين URL غير المخصصة للبحث العضوي ، مثل البريد الإلكتروني المخصص أو الصفحات المقصودة لحملة تكلفة النقرة. بالمثل ، لا تريد أن يزور الأشخاص الذين لم يتحولوا صفحات الشكر الخاصة بك عبر SERPs.
الحل دون الأمثل: عدم السماح للملفات باستخدام ملف robots.txt لأن هذا لن يمنع تضمين الارتباط في نتائج البحث.
نهج أفضل الممارسات: استخدم العلامة الوصفية "noindex".
إدارة المحتوى المكرر في الموقع
المشكلة: تحتاج بعض مواقع الويب إلى نسخة من محتوى معين لأسباب تتعلق بتجربة المستخدم ، مثل نسخة مناسبة للطباعة من الصفحة ، ولكنك تريد التأكد من التعرف على الصفحة الأساسية ، وليس الصفحة المكررة ، بواسطة محركات البحث. في مواقع الويب الأخرى ، يرجع المحتوى المكرر إلى ممارسات التطوير السيئة ، مثل عرض العنصر نفسه للبيع على عناوين URL متعددة الفئات.
الحل دون الأمثل: سيؤدي عدم السماح بعناوين URL باستخدام ملف robots.txt إلى منع الصفحة المكررة من تمرير أي إشارات ترتيب. Noindexing للروبوتات ، سيؤدي في النهاية إلى تعامل Google مع الروابط على أنها "nofollow" أيضًا ، مما سيمنع الصفحة المكررة من تمرير أي ملكية ارتباط.
نهج أفضل الممارسات: إذا لم يكن للمحتوى المكرر سبب لوجوده ، فقم بإزالة المصدر وإعادة التوجيه 301 إلى عنوان URL المناسب لمحرك البحث. إذا كان هناك سبب للوجود ، فأضف السمة rel = canonical link التي تدمج إشارات الترتيب.
محتوى ضعيف للصفحات ذات الصلة بالحساب الذي يمكن الوصول إليه
المشكلة: الصفحات المتعلقة بالحساب مثل تسجيل الدخول أو التسجيل أو عربة التسوق أو الخروج أو نماذج الاتصال ، غالبًا ما تكون خفيفة المحتوى ولا تقدم قيمة تذكر لمحركات البحث ، ولكنها ضرورية للمستخدمين.
الحل دون الأمثل: عدم السماح للملفات باستخدام ملف robots.txt لأن هذا لن يمنع تضمين الارتباط في نتائج البحث.
نهج أفضل الممارسات: بالنسبة لمعظم مواقع الويب ، يجب أن تكون هذه الصفحات قليلة جدًا من حيث العدد وقد لا ترى تأثير مؤشرات الأداء الرئيسية لتنفيذ التعامل مع الروبوتات. إذا شعرت بالحاجة ، فمن الأفضل استخدام أمر "noindex" ، ما لم تكن هناك استعلامات بحث عن مثل هذه الصفحات.
ضع علامة على الصفحات باستخدام ميزانية الزحف
المشكلة: تستهلك العلامات غير الخاضعة للرقابة ميزانية الزحف وغالبًا ما تؤدي إلى مشكلات تتعلق بالمحتوى الرقيق.
الحلول دون المستوى الأمثل: عدم السماح باستخدام ملف robots.txt أو إضافة علامة "noindex" ، لأن كلاهما سيعوق العلامات ذات الصلة لتحسين محركات البحث (على الفور أو في النهاية) ويمنع تمرير ملكية الرابط.
نهج أفضل الممارسات: قم بتقييم قيمة كل علامة من علاماتك الحالية. إذا أظهرت البيانات أن الصفحة تضيف القليل من القيمة لمحركات البحث أو المستخدمين ، فأعد توجيههم 301. بالنسبة للصفحات التي نجت من الإعدام ، اعمل على تحسين العناصر الموجودة على الصفحة حتى تصبح ذات قيمة لكل من المستخدمين وبرامج التتبُّع.
الزحف إلى JavaScript و CSS
المشكلة: في السابق ، لم تتمكن برامج الروبوت من الزحف إلى جافا سكريبت ومحتويات الوسائط الغنية الأخرى. لقد تغير هذا ويوصى بشدة الآن بالسماح لمحركات البحث بالوصول إلى ملفات JS و CSS من أجل عرض الصفحات اختياريًا.
الحل دون الأمثل: قد يؤدي عدم السماح لملفات JavaScript و CSS باستخدام ملف robots.txt لحفظ ميزانية الزحف إلى فهرسة رديئة ويؤثر سلبًا على التصنيفات. على سبيل المثال ، قد يُنظر إلى حظر وصول محرك البحث إلى جافا سكريبت الذي يقدم إعلانًا بينيًا أو إعادة توجيه المستخدمين على أنه إخفاء هوية.
منهج أفضل الممارسات: تحقق من وجود أي مشكلات في العرض باستخدام أداة "الجلب مثل Google" أو احصل على نظرة عامة سريعة على الموارد المحظورة من خلال تقرير "الموارد المحظورة" ، وكلاهما متاح في Google Search Console. إذا تم حظر أي موارد قد تمنع محركات البحث من عرض الصفحة بشكل صحيح ، فقم بإزالة ملف robots.txt disallow.
زاحف Oncrawl SEO
 يتعلم أكثر
يتعلم أكثرقائمة مراجعة أفضل ممارسة للروبوتات
من الشائع بشكل مخيف أن تتم إزالة موقع ويب عن طريق الخطأ من Google عن طريق التحكم في الروبوتات بالخطأ.
ومع ذلك ، يمكن أن يكون التعامل مع الروبوتات إضافة قوية لترسانة تحسين محركات البحث الخاصة بك عندما تعرف كيفية استخدامها. فقط تأكد من المضي قدما بحكمة وحذر.
للمساعدة ، إليك قائمة تحقق سريعة:
- تأمين المعلومات الخاصة باستخدام الحماية بكلمة مرور
- حظر الوصول إلى مواقع التطوير باستخدام المصادقة من جانب الخادم
- تقييد برامج الزحف التي تأخذ نطاقًا تردديًا ولكنها تقدم القليل من القيمة مرة أخرى مع حظر وكيل المستخدم
- تأكد من احتواء النطاق الأساسي وأي نطاقات فرعية على ملف نصي باسم "robots.txt" في دليل المستوى الأعلى والذي يعرض الرمز 200
- تأكد من احتواء ملف robots.txt على كتلة واحدة على الأقل مع سطر وكيل مستخدم وسطر منع
- تأكد من احتواء ملف robots.txt على سطر موقع واحد على الأقل ، تم إدخاله كسطر أخير
- تحقق من صحة ملف robots.txt في أداة اختبار GSC robots.txt
- تأكد من أن كل صفحة قابلة للفهرسة تحدد توجيهات علامات برامج الروبوت الخاصة بها
- تأكد من عدم وجود توجيهات متناقضة أو زائدة عن الحاجة بين ملف robots.txt والعلامات الوصفية لبرامج الروبوت وعلامات X-Robots و X-Robots-Tags وملف .htaccess ومعالجة معلمات GSC
- أصلح أخطاء "عنوان URL المُرسل الذي تم وضع علامة عليه" noindex "أو" عنوان URL المُرسل محظور بواسطة ملف robots.txt "في تقرير تغطية GSC
- افهم سبب أي استثناءات متعلقة بالروبوتات في تقرير تغطية GSC
- تأكد من عرض الصفحات ذات الصلة فقط في تقرير "الموارد المحظورة" الخاص بـ GSC
اذهب للتحقق من التعامل مع الروبوتات الخاصة بك وتأكد من أنك تقوم بذلك بشكل صحيح.