
الزحف والفهرسة و Python: كل ما تريد معرفته
نشرت: 2021-05-31أود أن أبدأ هذه المقالة بنوع بسيط جدًا من المعادلة: إذا لم يتم الزحف إلى صفحاتك ، فلن تتم فهرستها أبدًا ، وبالتالي ، سيعاني أداء تحسين محركات البحث (SEO) دائمًا (ورائحته كريهة).
نتيجة لذلك ، تحتاج مُحسّنات محرّكات البحث إلى السعي لإيجاد أفضل طريقة لجعل مواقعهم قابلة للزحف وتزويد Google بأهم صفحاتهم لفهرستها والبدء في الحصول على حركة المرور من خلالها.
لحسن الحظ ، لدينا العديد من الموارد التي يمكن أن تساعدنا في تحسين إمكانية الزحف إلى موقعنا مثل Screaming Frog أو Oncrawl أو Python. سأوضح لك كيف يمكن أن تساعدك Python في تحليل وتحسين مؤشرات سهولة الزحف والفهرسة. في معظم الأوقات ، تؤدي هذه الأنواع من التحسينات أيضًا إلى تصنيفات أفضل ، وظهور أعلى في SERPs ، وفي النهاية ، المزيد من المستخدمين يصلون إلى موقع الويب الخاص بك.
1. طلب الفهرسة ببايثون
1.1 لجوجل
يمكن طلب الفهرسة لـ Google بعدة طرق ، على الرغم من أنني للأسف لست مقتنعًا جدًا بأي منها. سأوجهك عبر ثلاثة خيارات مختلفة مع إيجابياتهم وسلبياتهم:
- السيلينيوم و Google Search Console: من وجهة نظري وبعد اختباره وباقي الخيارات ، هذا هو الحل الأكثر فعالية. ومع ذلك ، بعد عدد من المحاولات ، من الممكن أن تكون هناك نافذة منبثقة لـ captcha تؤدي إلى كسرها.
- Pinging a sitemap: من المؤكد أنه يساعد في جعل خرائط المواقع يتم الزحف إليها كما هو مطلوب ، ولكن ليس عناوين URL محددة ، على سبيل المثال في حالة إضافة صفحات جديدة إلى موقع الويب.
- Google Indexing API: إنها ليست موثوقة للغاية باستثناء المذيعين ومواقع منصات العمل. يساعد على زيادة معدلات الزحف ولكن ليس على فهرسة عناوين URL معينة.
بعد هذه النظرة العامة السريعة حول كل طريقة ، دعنا نتعمق فيها واحدة تلو الأخرى.
1.1.1. السيلينيوم و Google Search Console
بشكل أساسي ، ما سنفعله في هذا الحل الأول هو الوصول إلى Google Search Console من متصفح مع السيلينيوم وتكرار نفس العملية التي نتبعها يدويًا لإرسال العديد من عناوين URL للفهرسة باستخدام Google Search Console ، ولكن بطريقة آلية.
ملاحظة: لا تفرط في استخدام هذه الطريقة ولا ترسل صفحة للفهرسة إلا إذا تم تحديث محتواها أو إذا كانت الصفحة جديدة تمامًا.
تتمثل الحيلة في تسجيل الدخول إلى Google Search Console باستخدام السيلينيوم في الوصول إلى ملعب OUATH أولاً كما أوضحت في هذه المقالة حول كيفية أتمتة تنزيل تقرير إحصائيات زحف GSC.
# نحن نستورد هذه الوحدات
وقت الاستيراد
من السلينيوم استيراد webdriver
من webdriver_manager.chrome استيراد ChromeDriverManager
من selenium.webdriver.common.keys مفاتيح الاستيراد
# نقوم بتثبيت برنامج تشغيل السيلينيوم الخاص بنا
سائق = webdriver.Chrome (ChromeDriverManager (). install ())
# نصل إلى حساب ملعب OUATH لتسجيل الدخول إلى خدمات Google
driver.get ('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount؟redirect_uri=https٪3A٪2F٪2Fdevelopers.google.com٪2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent .com & domain = email & access_type = offline & flowName = GeneralOAuthFlow ')
# ننتظر قليلاً للتأكد من اكتمال العرض قبل تحديد العناصر باستخدام Xpath وتقديم عنوان بريدنا الإلكتروني.
time.sleep (10) الوقت.
form1 = driver.find_element_by_xpath ('// * [@]')
form1.send_keys ("<عنوان بريدك الإلكتروني>")
form1.send_keys (Keys.ENTER)
# نفس هنا ، ننتظر قليلاً ثم نقدم كلمة المرور الخاصة بنا.
time.sleep (10) الوقت.
form2 = driver.find_element_by_xpath ('// * [@] / div [1] / div / div [1] / input')
form2.send_keys ("<كلمة المرور>")
form2.send_keys (Keys.ENTER)
بعد ذلك ، يمكننا الوصول إلى عنوان URL الخاص بـ Google Search Console:
driver.get ("https://search.google.com/search-console؟resource_id=your_domain")
time.sleep (5) الوقت.
box = driver.find_element_by_xpath ('/ html / body / div [7] / div [2] / header / div [2] / div [2] / div [2] / form / div / div / div / div / div / div [1] / input [2] ')
box.send_keys ("your_URL")
box.send_keys (Keys.ENTER)
time.sleep (5) الوقت.
indexation = driver.find_element_by_xpath ("/ html / body / div [7] / c-wiz [2] / div / div [3] / span / div / div [2] / span / div [2] / div / div / div [1] / span / div [2] / div / c-wiz [2] / div [3] / span / div / span / span / div / span / span [1] ")
indexation.click ()
time.sleep (120) الوقت.
لسوء الحظ ، كما هو موضح في المقدمة ، يبدو أنه بعد عدد من الطلبات ، تبدأ في طلب اختبار captcha اللغز لمتابعة طلب الفهرسة. نظرًا لأن الطريقة الآلية لا يمكنها حل اختبار CAPTCHA ، فهذا شيء يعيق هذا الحل.
1.1.2. تنفيذ أمر Ping على خريطة الموقع
يمكن تقديم عناوين URL لملفات Sitemap إلى Google باستخدام طريقة ping. بشكل أساسي ، ستحتاج فقط إلى تقديم طلب إلى نقطة النهاية التالية لتقديم عنوان URL لخريطة الموقع كمعامل:
http://www.google.com/ping?sitemap=URL/of/file
يمكن أتمتة هذا بسهولة شديدة باستخدام Python والطلبات كما أوضحت في هذه المقالة.
طلب استيراد urllib url = "http://www.google.com/ping؟sitemap=https://www.example.com/sitemap.xml" الاستجابة = urllib.request.urlopen (url)
1.1.3. جوجل فهرسة API
يمكن أن تكون واجهة برمجة تطبيقات Google Indexing API حلاً جيدًا لتحسين معدلات الزحف لديك ، ولكنها عادةً لا تكون طريقة فعالة جدًا لفهرسة المحتوى الخاص بك لأنه من المفترض أن يتم استخدامه فقط إذا كان موقع الويب الخاص بك يحتوي على JobPosting أو BroadcastEvent مضمنًا في VideoObject. ومع ذلك ، إذا كنت ترغب في تجربته واختباره بنفسك ، يمكنك اتباع الخطوات التالية.
بادئ ذي بدء ، لبدء استخدام واجهة برمجة التطبيقات هذه ، يلزمك الانتقال إلى Google Cloud Console ، وإنشاء مشروع وبيانات اعتماد حساب الخدمة. بعد ذلك ، ستحتاج إلى تمكين واجهة برمجة تطبيقات الفهرسة من المكتبة وإضافة حساب البريد الإلكتروني الذي يتم تقديمه مع بيانات اعتماد حساب الخدمة كمالك خاصية على Google Search Console. قد تحتاج إلى استخدام الإصدار القديم من Google Search Console لتتمكن من إضافة عنوان البريد الإلكتروني هذا كمالك للموقع.
بمجرد اتباع الخطوات السابقة ، ستتمكن من بدء طلب الفهرسة وإلغاء الفهرسة باستخدام واجهة برمجة التطبيقات هذه باستخدام الجزء التالي من الكود:
من oauth2client.service_account import ServiceAccountCredentials
استيراد HTplib2
SCOPES = ["https://www.googleapis.com/auth/indexing"]
ENDPOINT = "https://indexing.googleapis.com/v3/urlNotifications:publish"
client_secrets = "path_to_your_credentials.json"
بيانات الاعتماد = ServiceAccountCredentials.from_json_keyfile_name (client_secrets ، scopes = SCOPES)
إذا كانت بيانات الاعتماد بلا أو بيانات الاعتماد. غير صالحة:
أوراق الاعتماد = tools.run_flow (التدفق ، التخزين)
http = بيانات الاعتماد. التفويض (HTplib2.Http ())
list_urls = ["https://www.example.com" ، "https://www.example.com/test2/"]
للتكرار في النطاق (len (list_urls)):
المحتوى = "" {
'url': "" "+ str (list_urls [التكرار]) + '' '"،
"النوع": "URL_UPDATED"
} "
الاستجابة ، المحتوى = http.request (ENDPOINT ، الطريقة = "POST" ، الجسم = المحتوى)
طباعة (استجابة)
طباعة (محتوى)إذا كنت ترغب في طلب إلغاء الفهرسة ، فستحتاج إلى تغيير نوع الطلب من "URL_UPDATED" إلى "URL_DELETED". الجزء السابق من الكود سيطبع الردود من API مع أوقات الإخطار وحالاتها. إذا كانت الحالة 200 ، فسيتم تقديم الطلب بنجاح.
1.2 لبينج
في كثير من الأحيان عندما نتحدث عن مُحسّنات محرّكات البحث ، لا نفكر إلا في Google ، لكن لا يمكننا أن ننسى أنه في بعض الأسواق توجد محركات بحث أخرى سائدة و / أو محركات بحث أخرى لها حصة سوقية محترمة مثل Bing.
من المهم أن نذكر منذ البداية أن Bing لديه بالفعل ميزة ملائمة جدًا في أدوات مشرفي المواقع من Bing والتي تمكنك من طلب إرسال ما يصل إلى 10000 عنوان URL يوميًا في معظم الحالات. في بعض الأحيان ، قد تكون حصتك اليومية أقل من 10000 عنوان URL ولكن لديك خيار طلب زيادة الحصة إذا كنت تعتقد أنك ستحتاج إلى حصة أكبر لتلبية احتياجاتك. يمكنك قراءة المزيد عن هذا في هذه الصفحة.
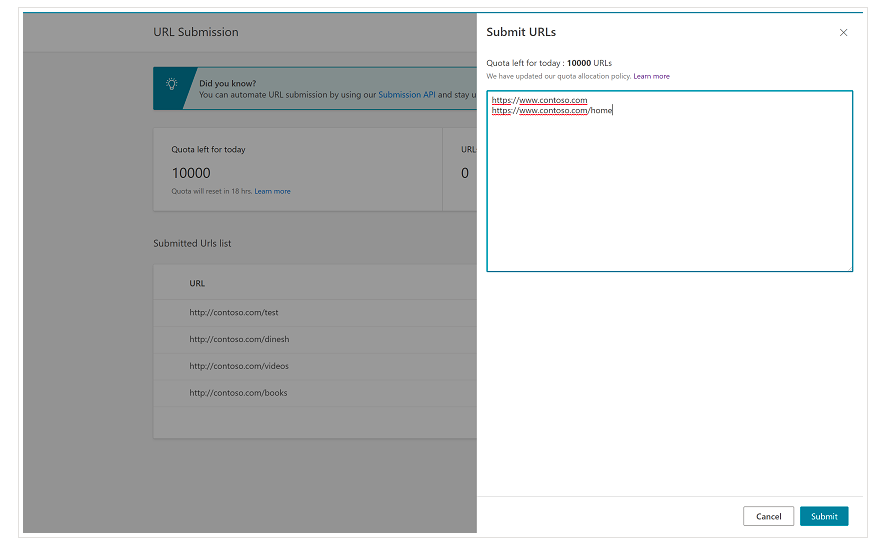
هذه الميزة مناسبة جدًا بالفعل لعمليات إرسال عناوين URL المجمعة حيث ستحتاج فقط إلى تقديم عناوين URL الخاصة بك في سطور مختلفة في أداة إرسال عنوان URL من الواجهة العادية لأدوات مشرفي المواقع في Bing.
1.2.1. واجهة برمجة تطبيقات فهرسة Bing
يمكن استخدام Bing Indexing API مع مفتاح API الذي يجب تقديمه كمعامل. يمكن الحصول على مفتاح API هذا من Bing Webmaster Tools ، والانتقال إلى قسم الوصول إلى API وبعد ذلك ، إنشاء مفتاح API.
بمجرد الحصول على مفتاح API ، يمكننا التلاعب بواجهة برمجة التطبيقات باستخدام الجزء التالي من الكود (ستحتاج فقط إلى إضافة مفتاح API وعنوان URL لموقعك):
طلبات الاستيراد
list_urls = ["https://www.example.com"، "https: //www.example/test2/"]
من أجل y في list_urls:
url = 'https://ssl.bing.com/webmaster/api.svc/json/SubmitUrlbatch؟apikey=yourapikey'
myobj = '{"siteUrl": "https://www.example.com"، "urlList": ["' + str (y) + '"]}'
headers = {'Content-type': 'application / json؛ charset = utf-8 '}
x = request.post (url، data = myobj، headers = headers)
طباعة (str (y) + ":" + str (x))سيؤدي هذا إلى طباعة عنوان URL ورمز الاستجابة الخاص به في كل تكرار. على عكس Google Indexing API ، يمكن استخدام واجهة برمجة التطبيقات هذه لأي نوع من مواقع الويب.
[دراسة حالة] زيادة الرؤية عن طريق تحسين إمكانية الزحف إلى موقع الويب لبرنامج Googlebot
 اقرأ دراسة الحالة
اقرأ دراسة الحالة2. تحليل خرائط المواقع وإنشائها وتحميلها
كما نعلم جميعًا ، تعد خرائط المواقع عناصر مفيدة جدًا لتزويد روبوتات محركات البحث بعناوين URL التي نرغب في الزحف إليها. من أجل السماح لروبوتات محرك البحث بمعرفة مكان خرائط مواقعنا ، من المفترض تحميلها على Google Search Console وأدوات مشرفي المواقع Bing وإدراجها في ملف robots.txt لبقية برامج الروبوت.
باستخدام Python ، يمكننا العمل بشكل أساسي على ثلاثة جوانب مختلفة تتعلق بخرائط المواقع: تحليلها وإنشائها وتحميلها وحذفها من Google Search Console.
2.1. استيراد ملفات Sitemap وتحليلها باستخدام Python
Advertools هي مكتبة رائعة أنشأها Elias Dabbas والتي يمكن استخدامها لاستيراد خريطة الموقع بالإضافة إلى العديد من مهام تحسين محركات البحث الأخرى. ستتمكن من استيراد خرائط المواقع إلى Dataframes فقط باستخدام:
sitemap_to_df('https://example.com/robots.txt', recursive=False)
تدعم هذه المكتبة خرائط مواقع XML العادية وخرائط مواقع الأخبار وخرائط مواقع الفيديو.
من ناحية أخرى ، إذا كنت مهتمًا فقط باستيراد عناوين URL من خريطة الموقع ، فيمكنك أيضًا استخدام طلبات المكتبة و BeautifulSoup.
طلبات الاستيراد
من bs4 استيراد BeautifulSoup
r = request.get ("https://www.example.com/your_sitemap.xml")
xml = r.text
حساء = شوربة جميلة (xml)
urls = soup.find_all ("loc")
urls = [[x.text] لـ x في عناوين url]
بمجرد استيراد ملف Sitemap ، يمكنك التلاعب بعناوين URL المستخرجة وإجراء تحليل للمحتوى كما أوضح Koray Tugberk في هذه المقالة.
2.2. إنشاء ملفات Sitemap باستخدام Python
يمكنك أيضًا استخدام Python لإنشاء sitemaps.xml من قائمة عناوين URL كما أوضح JC Chouinard في هذه المقالة. يمكن أن يكون هذا مفيدًا بشكل خاص لمواقع الويب الديناميكية جدًا التي تتغير عناوين URL الخاصة بها بسرعة ، بالإضافة إلى طريقة ping الموضحة أعلاه ، يمكن أن يكون حلاً رائعًا لتزويد Google بعناوين URL الجديدة والحصول على الزحف إليها وفهرستها بسرعة.
في الآونة الأخيرة ، أنشأ Greg Bernhardt أيضًا تطبيقًا باستخدام Streamlit و Python لإنشاء خرائط مواقع.
2.3 تحميل وحذف خرائط المواقع من Google Search Console
تحتوي Google Search Console على واجهة برمجة تطبيقات يمكن استخدامها بشكل أساسي بطريقتين مختلفتين: لاستخراج البيانات حول أداء الويب والتعامل مع خرائط المواقع. في هذا المنشور ، سنركز على خيار تحميل خرائط المواقع وحذفها.
أولاً ، من المهم إنشاء أو استخدام مشروع حالي من Google Cloud Console للحصول على بيانات اعتماد OUATH وتمكين خدمة Google Search Console. يشرح JC Chouinard جيدًا الخطوات التي تحتاج إلى اتباعها للوصول إلى Google Search Console API باستخدام Python وكيفية تقديم طلبك الأول في هذه المقالة. في الأساس ، يمكننا الاستفادة تمامًا من الكود الخاص به ولكن فقط من خلال إدخال تغيير ، سنضيف في النطاقات "https://www.googleapis.com/auth/webmasters" بدلاً من "https://www.googleapis.com /auth/webmasters.readonly "لأننا سنستخدم واجهة برمجة التطبيقات ليس فقط لقراءة خرائط المواقع ولكن لتحميلها وحذفها.

بمجرد الاتصال بواجهة برمجة التطبيقات ، يمكننا البدء في اللعب بها وإدراج جميع خرائط المواقع من خصائص Google Search Console مع الجزء التالي من الكود:
لعناوين URL الخاصة بـ site_url في مواقع_عناوين URL التي تم التحقق منها:
طباعة (site_url)
# استرداد قائمة خرائط المواقع المرسلة
sitemaps = webmasters_service.sitemaps (). list (siteUrl = site_url) .execute ()
إذا "خريطة الموقع" في خرائط المواقع:
sitemap_urls = [s ['path'] لـ s في ملفات sitemap ['sitemap']]
طباعة ("" + "\ n". الانضمام (sitemap_urls))
عندما يتعلق الأمر بخرائط مواقع محددة ، يمكننا القيام بثلاث مهام سنشرحها بالتفصيل في الأقسام التالية: تحميل المعلومات وحذفها وطلبها.
2.3.1. تحميل خريطة الموقع
لتحميل خريطة موقع باستخدام Python ، نحتاج فقط إلى تحديد عنوان URL للموقع ومسار خريطة الموقع وتشغيل هذا الجزء من الكود:
موقع الويب = 'yourGSCproperty' SITEMAP_PATH = "https://www.example.com/page-sitemap.xml" webmasters_service.sitemaps (). submit (siteUrl = WEBSITE، feedpath = SITEMAP_PATH) .execute ()
2.3.2. حذف خريطة الموقع
الجانب الآخر من العملة هو عندما نرغب في حذف خريطة موقع. يمكننا أيضًا حذف خرائط المواقع من Google Search Console باستخدام Python باستخدام طريقة "حذف" بدلاً من "إرسال".
موقع الويب = 'yourGSCproperty' SITEMAP_PATH = "https://www.example.com/page-sitemap.xml" webmasters_service.sitemaps (). delete (siteUrl = WEBSITE، feedpath = SITEMAP_PATH) .execute ()
2.3.3. طلب معلومات من خرائط المواقع
أخيرًا ، يمكننا أيضًا طلب معلومات من خريطة الموقع باستخدام طريقة "get".
موقع الويب = 'yourGSCproperty' SITEMAP_PATH = "https://www.example.com/page-sitemap.xml" webmasters_service.sitemaps (). get (siteUrl = WEBSITE، feedpath = SITEMAP_PATH) .execute ()
سيؤدي هذا إلى عرض رد بتنسيق JSON مثل: 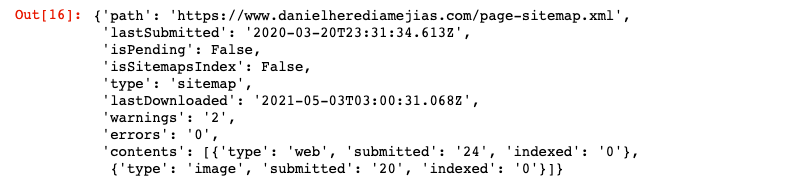
3. تحليل الروابط الداخلية والفرص
يعد وجود بنية ربط داخلية مناسبة مفيدًا جدًا لتسهيل برامج الروبوت لمحركات البحث من الزحف إلى موقع الويب الخاص بك. بعض المشكلات الرئيسية التي واجهتها من خلال تدقيق عدد من مواقع الويب ذات الإعدادات الفنية المتطورة للغاية هي:
- الروابط المقدمة مع أحداث عند النقر: باختصار ، لا ينقر Googlebot على الأزرار ، لذلك إذا تم إدراج روابطك بحدث عند النقر ، فلن يتمكن Googlebot من متابعتها.
- الروابط المعروضة من جانب العميل: على الرغم من أن Googlebot ومحركات البحث الأخرى أصبحت أفضل بكثير في تنفيذ JavaScript ، إلا أنه لا يزال يمثل تحديًا كبيرًا بالنسبة لهم ، لذلك من الأفضل بكثير عرض هذه الروابط من جانب الخادم وتقديمها في HTML الخام إلى روبوتات محركات البحث بدلاً من توقعها لتنفيذ نصوص جافا سكريبت.
- النوافذ المنبثقة لتسجيل الدخول و / أو البوابة العمرية: يمكن للنوافذ المنبثقة لتسجيل الدخول والبوابات العمرية أن تمنع روبوتات محرك البحث من الزحف إلى المحتوى الموجود خلف هذه "العوائق".
- الإفراط في استخدام سمة Nofollow: سيؤدي استخدام العديد من سمات nofollow التي تشير إلى صفحات داخلية قيّمة إلى منع روبوتات محرك البحث من الزحف إليها.
- Noindex والمتابعة: من الناحية الفنية ، يجب أن تسمح تركيبة noindex والتوجيهات المتبعة لروبوتات محرك البحث بالزحف إلى الروابط الموجودة في تلك الصفحة. ومع ذلك ، يبدو أن Googlebot يتوقف عن الزحف إلى تلك الصفحات باستخدام أوامر noindex بعد فترة.
باستخدام Python ، يمكننا تحليل هيكل الارتباط الداخلي الخاص بنا والعثور على فرص ربط داخلية جديدة في الوضع المجمع.
3.1 تحليل الارتباط الداخلي ببايثون
منذ بضعة أشهر ، كتبت مقالًا حول كيفية استخدام Python والمكتبة Networkx لإنشاء رسوم بيانية لعرض بنية الارتباط الداخلية بطريقة مرئية للغاية:
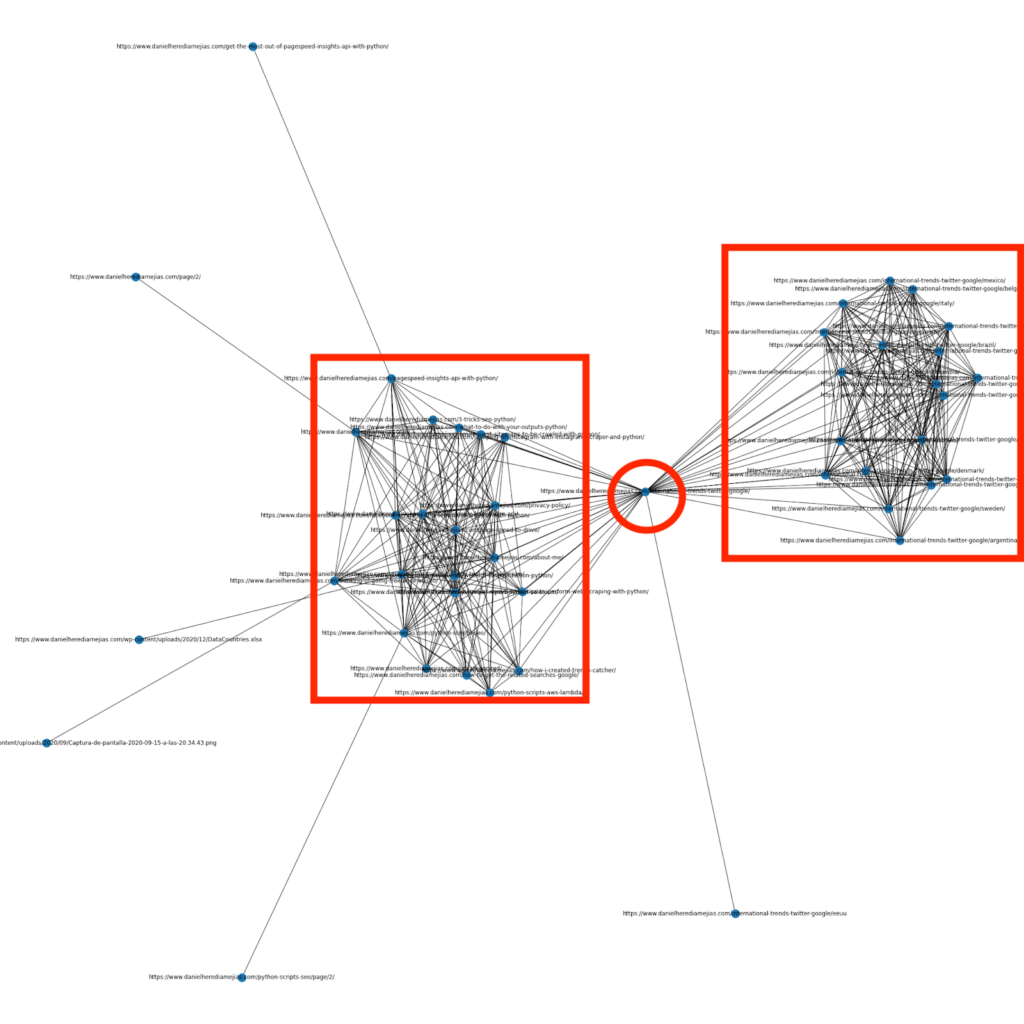
هذا شيء مشابه جدًا لما يمكنك الحصول عليه من Screaming Frog ، ولكن ميزة استخدام Python لهذا النوع من التحليلات هي أنه يمكنك أساسًا اختيار البيانات التي ترغب في تضمينها في هذه الرسوم البيانية والتحكم في معظم عناصر الرسم البياني مثل كالألوان أو أحجام العقد أو حتى الصفحات التي ترغب في إضافتها.
3.2 البحث عن فرص ربط داخلية جديدة باستخدام Python
بصرف النظر عن تحليل هياكل الموقع ، يمكنك أيضًا الاستفادة من Python للعثور على فرص ربط داخلية جديدة من خلال توفير عدد من الكلمات الرئيسية وعناوين URL والتكرار عبر عناوين URL هذه التي تبحث عن المصطلحات المتوفرة في أجزاء المحتوى الخاصة بها.
هذا شيء يمكن أن يعمل جيدًا مع صادرات Semrush أو Ahrefs من أجل العثور على روابط داخلية سياقية قوية من بعض الصفحات التي تم تصنيفها بالفعل للكلمات الرئيسية ، وبالتالي ، لديها بالفعل نوع من السلطة.
يمكنك قراءة المزيد عن هذه الطريقة هنا.
4. سرعة الموقع ، 5xx وصفحات أخطاء لينة
كما ذكرت Google في هذه الصفحة حول ما تعنيه ميزانية الزحف لـ Google ، فإن جعل موقعك أسرع يحسن تجربة المستخدم ويزيد من معدل الزحف. من ناحية أخرى ، هناك أيضًا عوامل أخرى قد تؤثر على ميزانية الزحف مثل صفحات الأخطاء الناعمة والمحتوى منخفض الجودة والمحتوى المكرر في الموقع.
4.1 سرعة الصفحة وبايثون
4.2.1 تحليل سرعة موقع الويب الخاص بك باستخدام Python
تعد Page Speed Insights API مفيدة للغاية لتحليل أداء موقع الويب الخاص بك من حيث سرعة الصفحة وللحصول على الكثير من البيانات حول العديد من مقاييس سرعة الصفحة المختلفة (تقريبًا 50) بالإضافة إلى Core Web Vitals.
يعد العمل باستخدام Page Speed Insights مع Python أمرًا سهلاً للغاية ، ولا يلزم سوى مفتاح API والطلبات للاستفادة منه. علي سبيل المثال:
طلب استيراد urllib.request ، json url = "https://www.googleapis.com/pagespeedonline/v5/runPagespeed؟url=your_URL&strategy=mobile&locale=en&key=yourAPIKey" # لاحظ أنه يمكنك إدخال عنوان URL الخاص بك مع عنوان URL للمعلمة ويمكنك أيضًا تعديل معلمة الجهاز إذا كنت ترغب في الحصول على البيانات لسطح المكتب. الاستجابة = urllib.request.urlopen (url) البيانات = json.loads (response.read ())
بالإضافة إلى ذلك ، يمكنك أيضًا التنبؤ باستخدام حاسبة Python و Lighthouse Scoring إلى أي مدى ستتحسن نتيجة الأداء الإجمالية في حالة إجراء التغييرات المطلوبة لتحسين سرعة صفحتك كما هو موضح في هذه المقالة.
4.2.2 تحسين الصورة وتغيير حجمها باستخدام بايثون
فيما يتعلق بسرعة موقع الويب ، يمكن أيضًا استخدام Python لتحسين الصور وضغطها وتغيير حجمها كما هو موضح في هذه المقالات التي كتبها Koray Tugberk و Greg Bernhardt:
- أتمتة ضغط الصور باستخدام Python عبر FTP.
- تغيير حجم الصور باستخدام Python بكميات كبيرة.
- تحسين الصور عبر Python لـ SEO و UX.
4.2 5xx واستخراج أخطاء كود الاستجابة الأخرى باستخدام Python
قد تشير أخطاء رمز استجابة 5xx إلى أن خادمك ليس سريعًا بما يكفي للتعامل مع جميع الطلبات التي يتلقاها. يمكن أن يكون لهذا تأثير سلبي للغاية على معدل الزحف الخاص بك ويمكن أن يضر أيضًا بتجربة المستخدم.
للتأكد من أن موقع الويب الخاص بك يعمل كما هو متوقع ، يمكنك أتمتة تنزيل تقرير إحصائيات الزحف باستخدام Python و Selenium ويمكنك مراقبة ملفات السجل الخاصة بك عن كثب.
4.3 استخراج صفحات الأخطاء اللينة باستخدام بايثون
نشر خوسيه لويس هيرناندو مؤخرًا مقالًا على شرف هاملت باتيستا حول كيفية أتمتة استخراج تقرير التغطية باستخدام Node.js. يمكن أن يكون هذا حلاً رائعًا لاستخراج صفحات الأخطاء البرمجية وحتى أخطاء استجابة 5xx التي قد تؤثر سلبًا على معدل الزحف لديك.
يمكننا أيضًا تكرار هذه العملية نفسها مع Python من أجل تجميع جميع عناوين URL التي يوفرها Google Search Console في علامة تبويب Excel واحدة على أنها خاطئة وصالحة مع تحذيرات وصالحة ومستبعدة.
أولاً ، نحتاج إلى تسجيل الدخول إلى Google Search Console كما هو موضح سابقًا في هذه المقالة باستخدام Python مع السيلينيوم. بعد ذلك ، سنحدد جميع مربعات حالة عنوان URL ، وسنضيف ما يصل إلى 100 صف لكل صفحة وسنبدأ في التكرار عبر جميع أنواع عناوين URL التي أبلغت عنها GSC وتنزيل كل ملف Excel واحد.
وقت الاستيراد
من السلينيوم استيراد webdriver
من webdriver_manager.chrome استيراد ChromeDriverManager
من selenium.webdriver.common.keys مفاتيح الاستيراد
سائق = webdriver.Chrome (ChromeDriverManager (). install ())
driver.get ('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount؟redirect_uri=https٪3A٪2F٪2Fdevelopers.google.com٪2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent .com & domain = email & access_type = offline & flowName = GeneralOAuthFlow ')
time.sleep (5) الوقت.
searchBox = driver.find_element_by_xpath ('// * [@]')
searchBox.send_keys ("<youremailaddress>")
searchBox.send_keys (Keys.ENTER)
time.sleep (5) الوقت.
searchBox = driver.find_element_by_xpath ('// * [@] / div [1] / div / div [1] / input')
searchBox.send_keys ("<yourpassword>")
searchBox.send_keys (Keys.ENTER)
time.sleep (5) الوقت.
yourdomain = str (input ("أدخل هنا موقع http أو نطاقك. إذا كان نطاقًا ، فقم بتضمين: 'sc-domain':"))
driver.get ("https://search.google.com/search-console/index؟resource_https://search.google.com/search-console/index؟resource_Tabla")
listvalues = [list_problems [x] لـ i في النطاق (len (df1 ["URL"]))]
df1 ['Type'] = listvalues
list_results = df1.values.tolist ()
آخر:
df2 = pd.read_excel (yourdomain.replace ("sc-domain:"، ""). استبدل ("/"، "_"). استبدل (":"، "_") + "-Coverage-Drilldown-" + اليوم + "(" + str (x) + ") .xlsx"، "Tabla")
listvalues = [list_problems [x] لـ i في النطاق (len (df2 ["URL"]))]
df2 ['Type'] = listvalues
list_results = list_results + df2.values.tolist ()
df = pd.DataFrame (قائمة_النتائج ، الأعمدة = ["URL" ، "الطابع الزمني" ، "النوع"])
df.to_csv ('<filename> .csv'، header = True، index = False، encoding = "utf-8")
الناتج النهائي يبدو كما يلي: 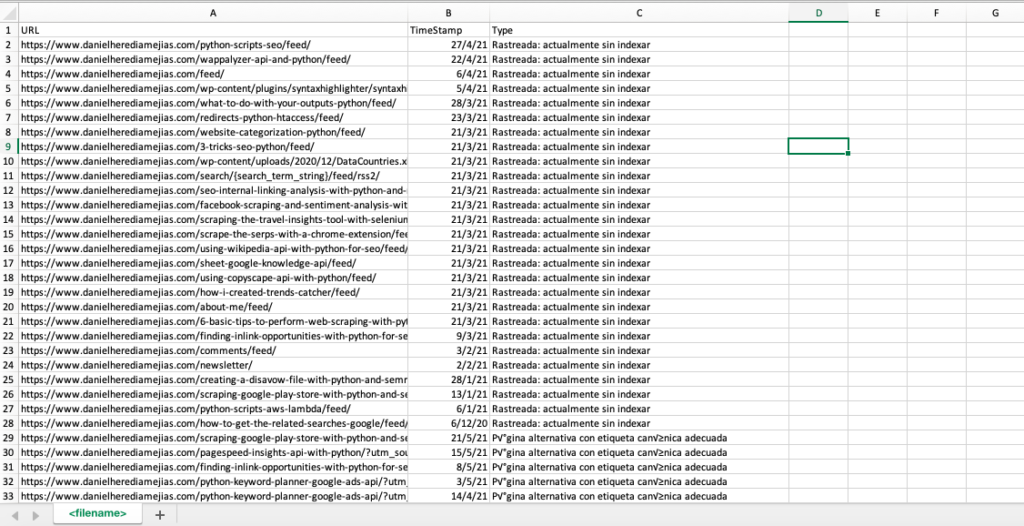
4.4 تحليل ملف السجل باستخدام بايثون
بالإضافة إلى البيانات المتوفرة في تقرير إحصائيات الزحف من Google Search Console ، يمكنك أيضًا تحليل ملفاتك الخاصة باستخدام Python للحصول على مزيد من المعلومات حول كيفية قيام روبوتات محرك البحث بالزحف إلى موقع الويب الخاص بك. إذا لم تكن تستخدم بالفعل محلل سجلات لـ SEO ، فيمكنك قراءة هذه المقالة من SEO Garden حيث يتم شرح تحليل السجل باستخدام Python.
[كتاب إلكتروني] أربع حالات استخدام للاستفادة من تحليل سجل تحسين محركات البحث
تنزيل مجاني5. الاستنتاجات النهائية
لقد رأينا أن Python يمكن أن تكون مصدرًا رائعًا لتحليل وتحسين الزحف إلى مواقعنا الإلكترونية وفهرستها بعدة طرق مختلفة. لقد رأينا أيضًا كيف نجعل الحياة أسهل بكثير من خلال أتمتة معظم المهام الشاقة واليدوية التي تتطلب آلاف الساعات من وقتك.
يجب أن أقول إنه لسوء الحظ لست مقتنعًا تمامًا بالحلول التي تقدمها Google في الوقت الحالي لطلب فهرسة عدد كبير من عناوين URL ، على الرغم من أنني أستطيع أن أفهم إلى حد ما خوفها من تقديم حل أفضل: قد تميل العديد من مُحسّنات محرّكات البحث إلى لإفراط في استخدامه.
على النقيض من ذلك ، هناك Bing ، الذي يقدم حلولاً استثنائية وملائمة لطلب فهرسة URL عبر واجهة برمجة التطبيقات وحتى من خلال الواجهة العادية في أدوات Bing Webmaster.
نظرًا لحقيقة أن واجهة برمجة تطبيقات فهرسة Google لديها مجال للتحسين ، فإن العناصر الأخرى مثل وجود خريطة موقع يمكن الوصول إليها ومحدثة في مكانها ، والارتباط الداخلي الخاص بك ، وسرعة صفحتك ، وصفحات الأخطاء اللينة والمحتوى المكرر والمنخفض الجودة تصبح أكثر أهمية لضمان أن موقع الويب الخاص بك يتم الزحف إليه بشكل صحيح وفهرسة أهم صفحاتك.