
Breadcrumb SEO و Python 3 و Oncrawl: في الطريق إلى الأتمتة!
نشرت: 2021-04-14دعنا نتعلم كيفية إنشاء تجزئة قائمة على مسار التنقل تلقائيًا باستخدام OnCrawl و Python 3.
ما هو التجزئة في Oncrawl؟
يستخدم Oncrawl التقسيمات لتقسيم مجموعة من الصفحات إلى مجموعات. هذا يجعل من السهل جدًا تحليل البيانات من تقارير الزحف وتحليل السجل وتقارير التحليل الشامل الأخرى التي تمزج بيانات الزحف مع Google Analytics أو Google Search Console أو AT Internet أو Adobe Analytics أو Majestic للروابط الخلفية.
لماذا من المهم إنشاء التقسيمات؟
بمجرد اكتمال الزحف الخاص بك ، فإن إنشاء تقسيم مخصص هو أهم شيء يجب القيام به. يتيح لك ذلك قراءة التحليلات من المنظور الذي يناسب موقعك وهيكله على أفضل وجه.
هناك طرق عديدة لتقسيم صفحات موقعك ، ولا توجد طريقة صحيحة أو خاطئة للقيام بذلك. على سبيل المثال ، من الممكن تتبع بنية موقعك بناءً على بنية عنوان URL.
على سبيل المثال ، يمكن تقسيم هذا النوع من عناوين URL " https://www.mydomain.com/news/canada/politics " بسهولة على النحو التالي:
- مجموعة لعزل الصفحة الرئيسية
- مجموعة لجميع الأخبار
- مجموعة فرعية لدليل كندا
- مجموعة فرعية لدليل السياسة
كما ترى ، من الممكن إنشاء ما يصل إلى 3 مستويات من العمق لأقسامك. يتيح لك ذلك التركيز على مجموعات أو مجموعات فرعية معينة في تحليل تحسين محركات البحث ، دون الحاجة إلى تبديل التقسيمات.
كيف أقوم بإنشاء تجزئة أساسية؟
يجب أن تعلم أن Oncrawl يعتني بإنشاء التجزئة الأولى ، كل ذلك من تلقاء نفسه. يعتمد هذا على "المسار الأول" أو الدليل الأول الذي تمت مواجهته في عناوين URL.
يتيح لك هذا الحصول على تحليل متاح بمجرد اكتمال الزحف.
قد يكون هذا التقسيم لا يعكس بنية موقعك ، أو أنك تريد تحليل الأشياء من زاوية مختلفة.
لذلك ستنشئ تقسيمًا جديدًا باستخدام ما نسميه OQL ، والتي تعني Oncrawl Query Language. إنه يشبه نوعًا ما SQL ، ولكنه أبسط بكثير وأكثر سهولة: 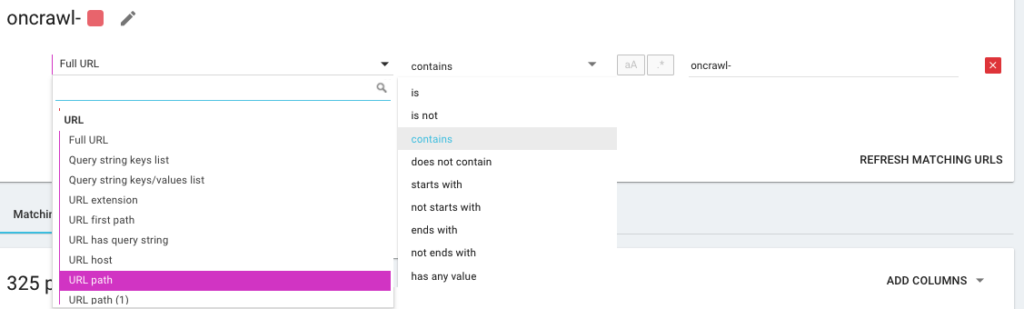
من الممكن أيضًا استخدام عوامل تشغيل الحالة AND / OR لتكون دقيقة قدر الإمكان: 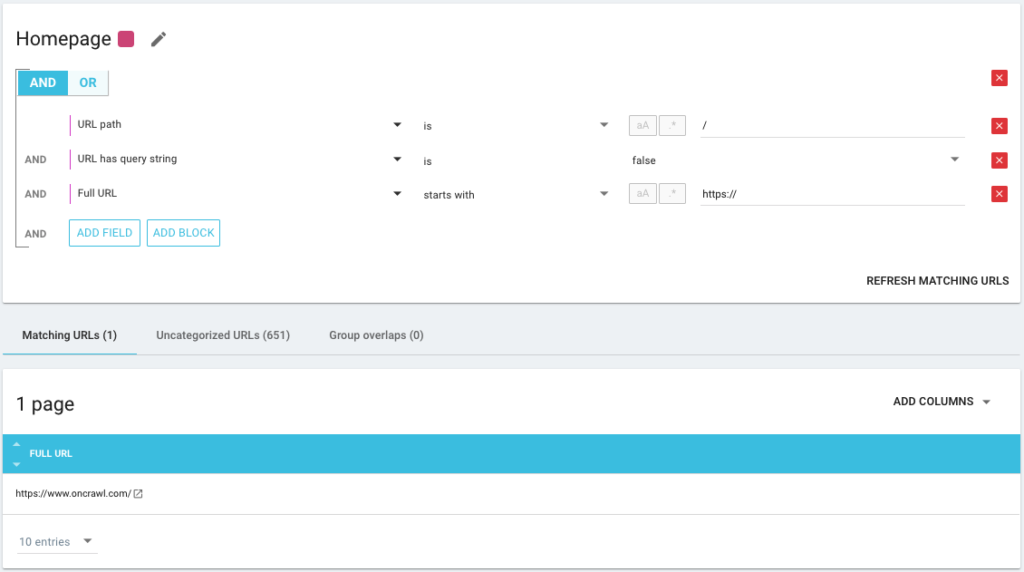
تجزئة صفحاتي باستخدام طرق مختلفة
استخدام مؤشرات الأداء الرئيسية الأخرى
تعتبر التقسيمات المستندة إلى عناوين URL جيدة ، ولكن سيكون الأمر مثاليًا إذا تمكنا أيضًا من الجمع بين مؤشرات الأداء الرئيسية الأخرى ، مثل تجميع عناوين URL التي تبدأ بـ / car-Rental / والتي تحتوي H1 على التعبير " وكالات تأجير السيارات " ومجموعة أخرى حيث سيكون H1 " وكالات تأجير المرافق " ، هل هذا ممكن؟
انه من الممكن! أثناء إنشاء التقسيمات الخاصة بك ، لديك تحت تصرفك جميع مؤشرات الأداء الرئيسية التي نستخدمها ، وليس فقط تلك من الزاحف ، ولكن أيضًا من الموصلات. هذا يجعل إنشاء التقسيمات أمرًا قويًا للغاية ويسمح لك بالحصول على زوايا تحليل مختلفة تمامًا!
على سبيل المثال ، أحب إنشاء تقسيم باستخدام متوسط موضع عناوين URL بفضل موصل Google Search Console.
بهذه الطريقة ، يمكنني بسهولة تحديد عناوين URL في عمق بنيتي التي لا تزال تعمل ، أو عناوين URL القريبة من صفحتي الرئيسية الموجودة في الصفحة 2 من Google.
يمكنني معرفة ما إذا كانت هذه الصفحات تحتوي على محتوى مكرر ، أو علامة عنوان فارغة ، وإذا كانت تتلقى روابط كافية ... يمكنني أيضًا معرفة كيف يتصرف Googlebot على هذه الصفحات. هل تردد الزحف جيد أم سيئ؟ باختصار ، إنه يساعدني في تحديد الأولويات واتخاذ القرارات التي سيكون لها تأثير حقيقي على مُحسّنات محرّكات البحث الخاصة بي وعائد استثماري.
بيانات عند الزحف³
 يتعلم أكثر
يتعلم أكثراستخدام استيعاب البيانات
إذا لم تكن على دراية بميزة "استيعاب البيانات" الخاصة بنا ، فأنا أدعوك لقراءة هذه المقالة حول هذا الموضوع أولاً. هذه أداة أخرى قوية للغاية تسمح لك بإضافة مصادر بيانات خارجية إلى Oncrawl.
على سبيل المثال ، يمكنك إضافة بيانات من SEMrush و Ahrefs و Babbar.tech ... الميزة هي أنه يمكنك تجميع صفحاتك وفقًا لمقاييس مأخوذة من هذه الأدوات وإجراء تحليلك بناءً على البيانات التي تهمك ، حتى لو لم تكن كذلك أصلا في Oncrawl.
عملت مؤخرًا مع مجموعة فنادق عالمية. يستخدمون طريقة تسجيل النتائج الداخلية لمعرفة ما إذا كانت سجلات الفندق ممتلئة بشكل صحيح ، وما إذا كانت تحتوي على صور ومقاطع فيديو ومحتوى ، وما إلى ذلك ... فهي تحدد النسبة المئوية للاكتمال ، والتي استخدمناها لتحليل بيانات الزحف وملف السجل.
تسمح لنا النتيجة بمعرفة ما إذا كان Googlebot يقضي وقتًا أطول على الصفحات المملوءة بشكل صحيح ، لمعرفة ما إذا كانت بعض الصفحات التي تزيد عن 90٪ عميقة جدًا ، ولا تتلقى روابط كافية ... فهي تتيح لنا إظهار أنه كلما ارتفع النتيجة ، كلما زاد عدد الزيارات التي تتلقاها الصفحات ، زاد استكشافها بواسطة Google ، وكان موقعها أفضل في Google SERP. حجة لا يمكن وقفها لتشجيع أصحاب الفنادق لملء قائمة الفنادق الخاصة بهم!
قم بإنشاء تجزئة بناءً على مسار التنقل الخاص بـ SEO
هذا هو موضوع هذا المقال ، لذا دعنا ننتقل إلى لب الموضوع. يصعب أحيانًا تقسيم صفحات موقعك ، إذا كانت بنية عناوين URL لا تربط الصفحات بدليل معين. هذا هو الحال غالبًا مع مواقع التجارة الإلكترونية ، حيث تكون جميع صفحات المنتج في الجذر. لذلك من المستحيل معرفة المجموعة التي تنتمي إليها الصفحة من خلال عنوان URL.
من أجل تجميع الصفحات معًا ، يتعين علينا إيجاد طريقة لتحديد المجموعة التي ينتمون إليها. لذلك كانت لدينا فكرة استرداد مسار التنقل SEO لكل عنوان URL وتصنيفها بناءً على القيم الموجودة في SEO بفتات التنقل ، باستخدام وظيفة Scraper التي تقدمها Oncrawl.
SEO Breadcrumb Scraping with Oncrawl
كما رأينا أعلاه ، سنضع قاعدة كشط لاسترداد مسار التنقل. في معظم الأحيان يكون الأمر بسيطًا جدًا لأنه يمكننا الذهاب واسترداد المعلومات في div ، ثم تكون حقول كل مستوى في
قوائم ul و li : 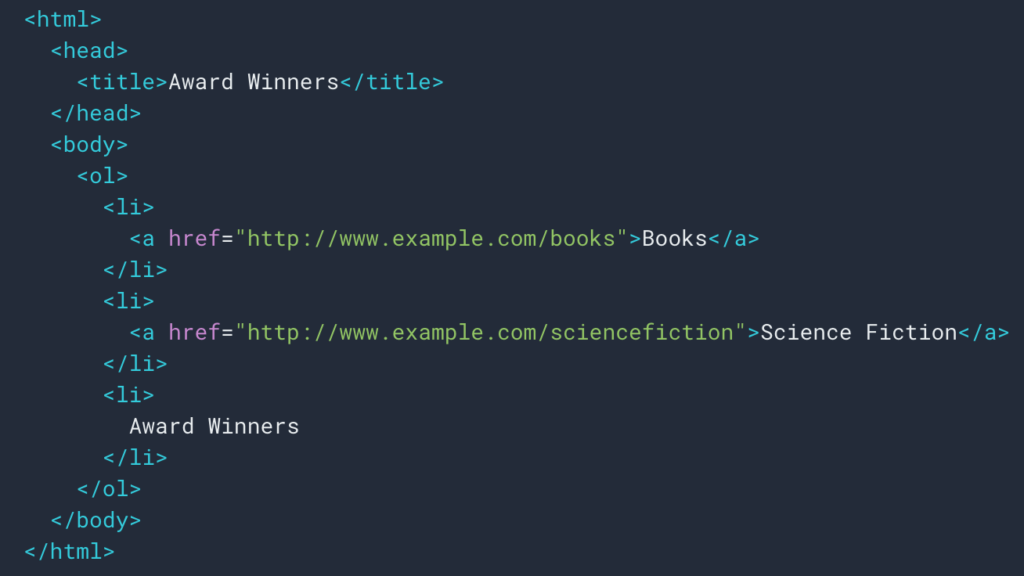
في بعض الأحيان يمكننا أيضًا استرداد المعلومات بسهولة بفضل نوع البيانات المنظمة Breadcrumb. لذلك سيكون من السهل استرجاع قيمة حقل "الاسم" لكل مركز. 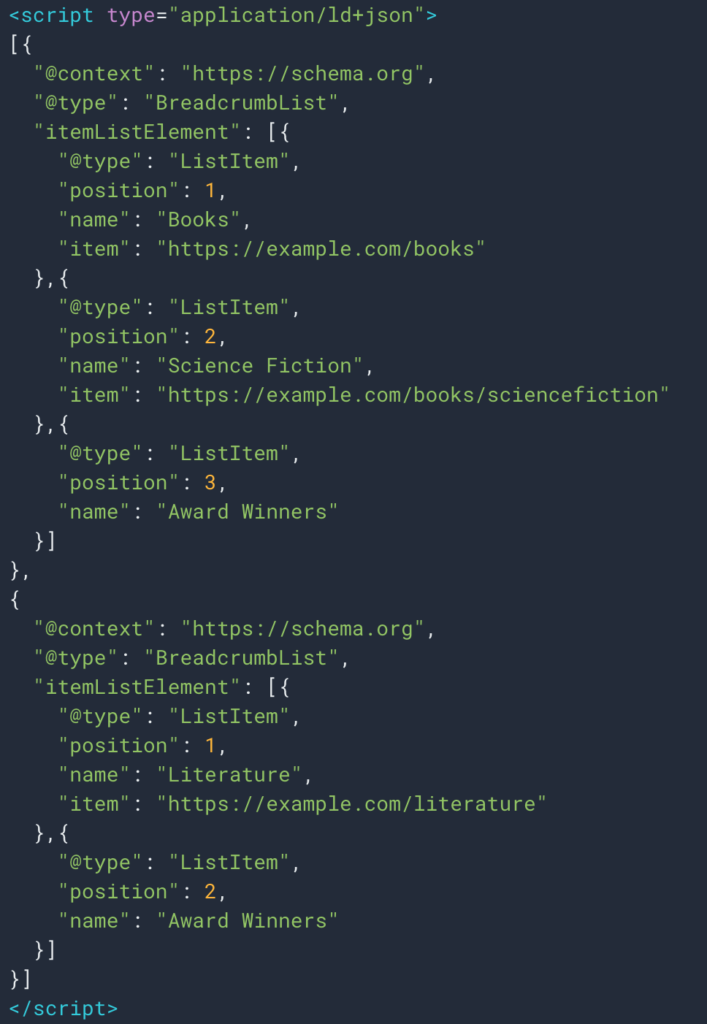
فيما يلي مثال على قاعدة الكشط التي أستخدمها: 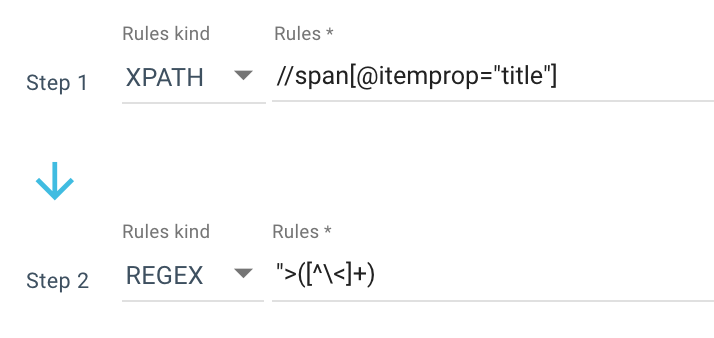
أو هذه القاعدة: //li[contains(@class, "current-menu-ancestor") or contains(@class, "current-menu-parent") or contains(@class, "current-menu-item")]/a/text()

لذا أحصل على span itemprop=”title” > Xpath ، ثم استخدم تعبيرًا عاديًا لاستخراج كل شيء بعد “> هذا ليس حرفًا. إذا كنت تريد معرفة المزيد عن Regex ، أقترح عليك قراءة هذه المقالة حول هذا الموضوع وورقة الغش الخاصة بنا على Regex.
أحصل على عدة قيم مثل هذه كناتج: 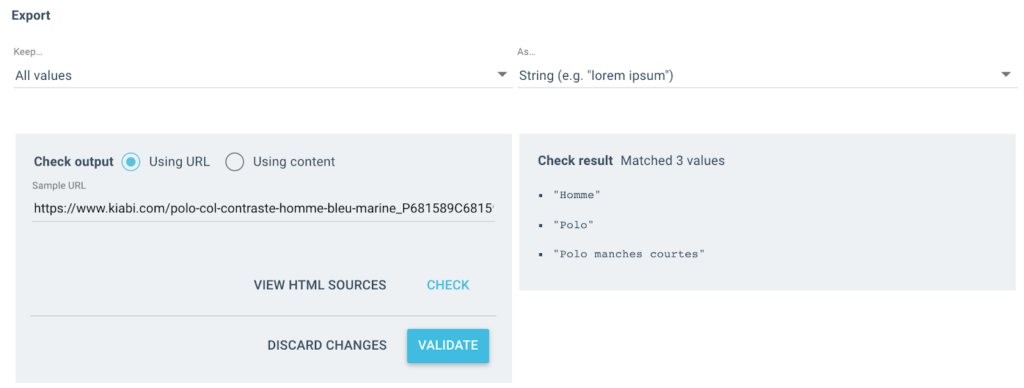
بالنسبة إلى عنوان URL الذي تم اختباره ، سيكون لدي حقل "مسار تنقل" بثلاث قيم:
- رجل
- قميص بولو
- بولو كم قصير
استيراد json
استيراد عشوائي
طلبات الاستيراد
# المصادقة
# طريقتان ، باستخدام x-oncrawl-token مما يمكنك الحصول عليه في رؤوس الطلبات من المتصفح
# أو مع رمز api هنا: https://app.oncrawl.com/account/tokens
API_ACCESS_TOKEN = "
# قم بتعيين معرف الزحف حيث يوجد حقل مخصص لمسار التنقل
زحف_
# قم بتحديث عناصر مسار التنقل المحظورة التي لا تريد تقسيمها
FORBIDDEN_BREADCRUMB_ITEMS = ('Accueil'،)
FORBIDDEN_BREADCRUMB_ITEMS_LIST = [
v.strip ()
لـ v في FORBIDDEN_BREADCRUMB_ITEMS.split ('،')
]
def random_color ():
random_number = random.randint (0، 16777215)
hex_number = str (ست عشري (random_number))
hex_number = hex_number [2:]. ljust (6، '0')
إرجاع "# {hex_number}"
def value_to_group (القيمة):
إرجاع {
"اللون": random_color () ،
"الاسم": القيمة ،
'oql': {'or': [{'field': ['custom_Breadcrumb'، 'equals'، value]}]}
}
def walk_dict (القاموس ، المستوى = 0):
ret = {
"رمز": "لوحة القيادة" ،
"قابل للتبديل": خطأ ،
"الاسم": "مسار التنقل"
}الآن بعد أن تم تحديد القاعدة ، يمكنني تشغيل الزحف الخاص بي وسيقوم Oncrawl تلقائيًا باسترداد قيم مسار التنقل وربطها بكل عنوان URL تم الزحف إليه.
أتمتة إنشاء التجزئة متعددة المستويات باستخدام Python
الآن بعد أن حصلت على جميع قيم مسار تنقل تحسين محركات البحث (SEO) لكل عنوان URL ، سنستخدم برنامج نصي بيثون للتشغيل الآلي للسيو في Google Colab لإنشاء تقسيم متوافق مع Oncrawl تلقائيًا.
بالنسبة للنص البرمجي نفسه ، نستخدم 3 مكتبات هي:
- json (لإنشاء تجزئة مكتوبة بلغة Json)
- csv
- عشوائي (لإنشاء رموز لونية سداسية عشرية لكل مجموعة)
بمجرد إطلاق البرنامج النصي ، فإنه يعتني تلقائيًا بإنشاء التجزئة في مشروعك! 
معاينة البيانات في التحليلات
الآن وقد تم إنشاء التجزئة الخاصة بنا ، فمن الممكن الوصول إلى التحليلات المختلفة باستخدام طريقة عرض مجزأة استنادًا إلى مسار التنقل الخاص بي. 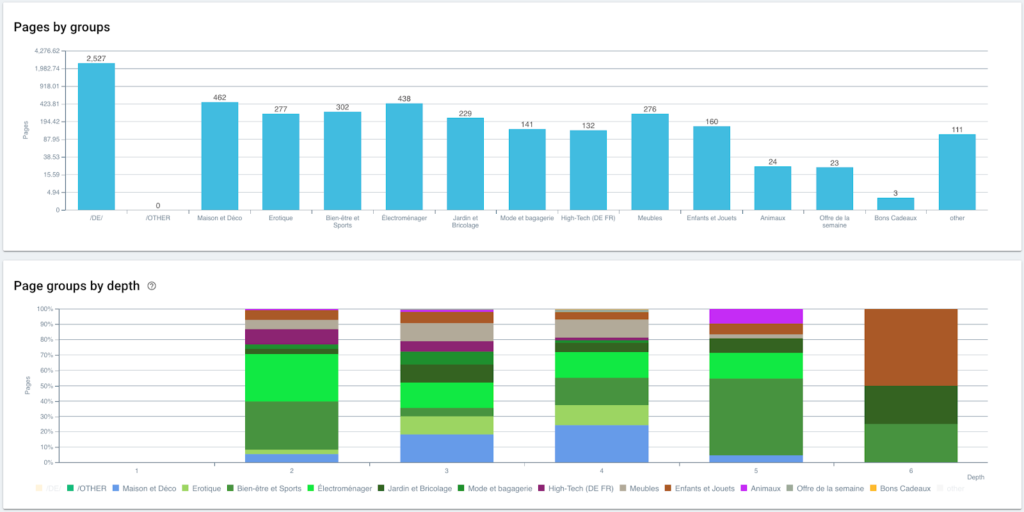
توزيع الصفحات حسب المجموعة والعمق
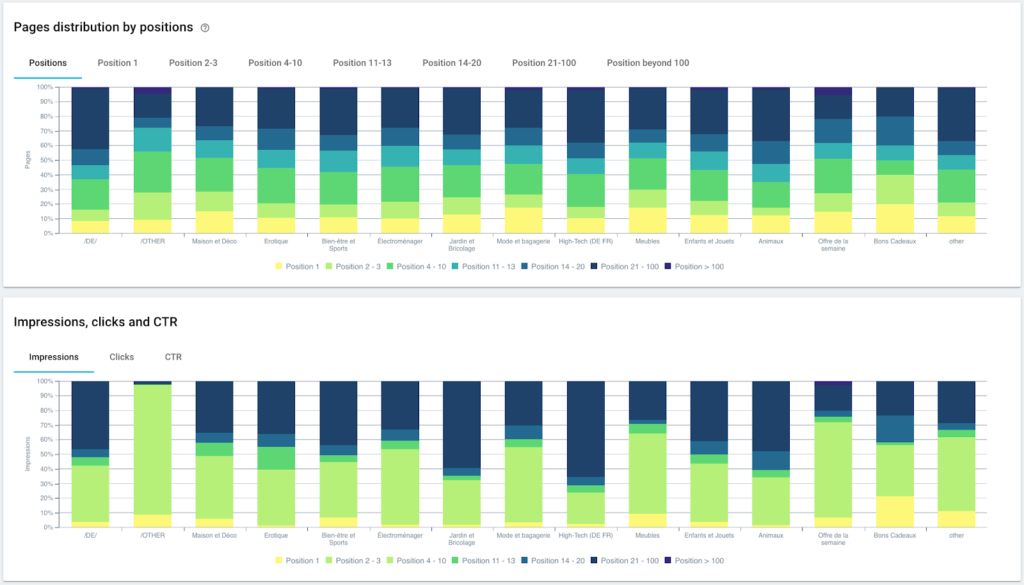
أداء الترتيب (GSC)
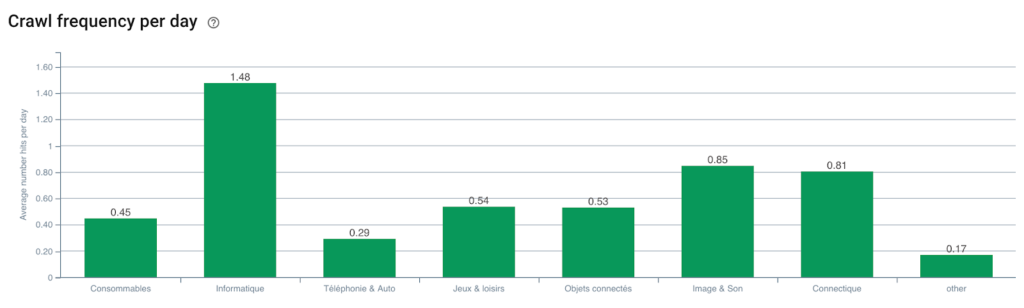
معدل زحف Googlebot
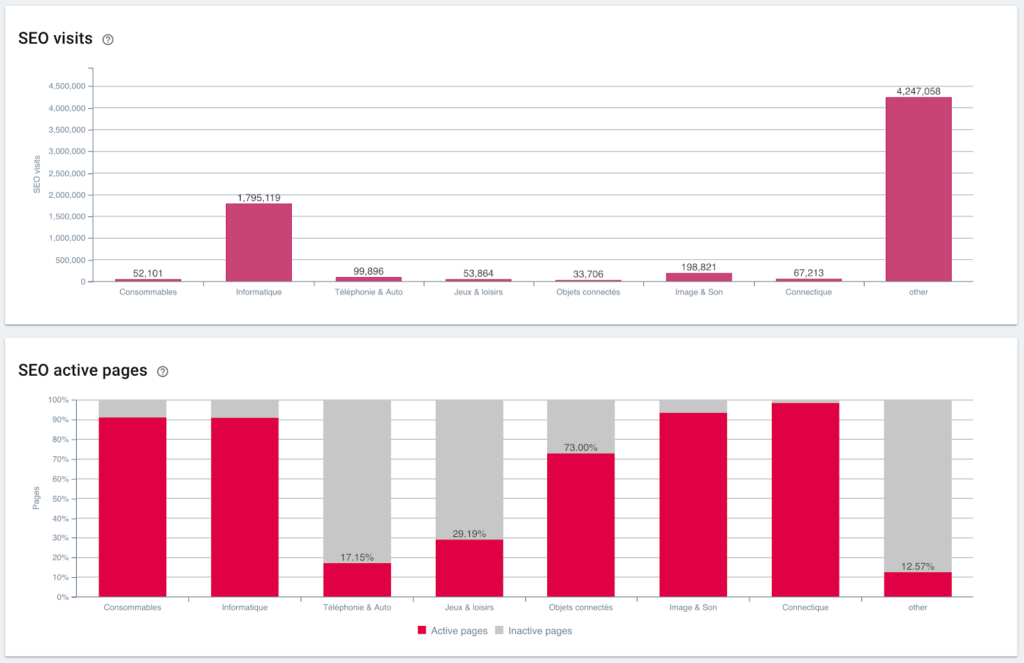
زيارات تحسين محركات البحث ونسبة الصفحة النشطة
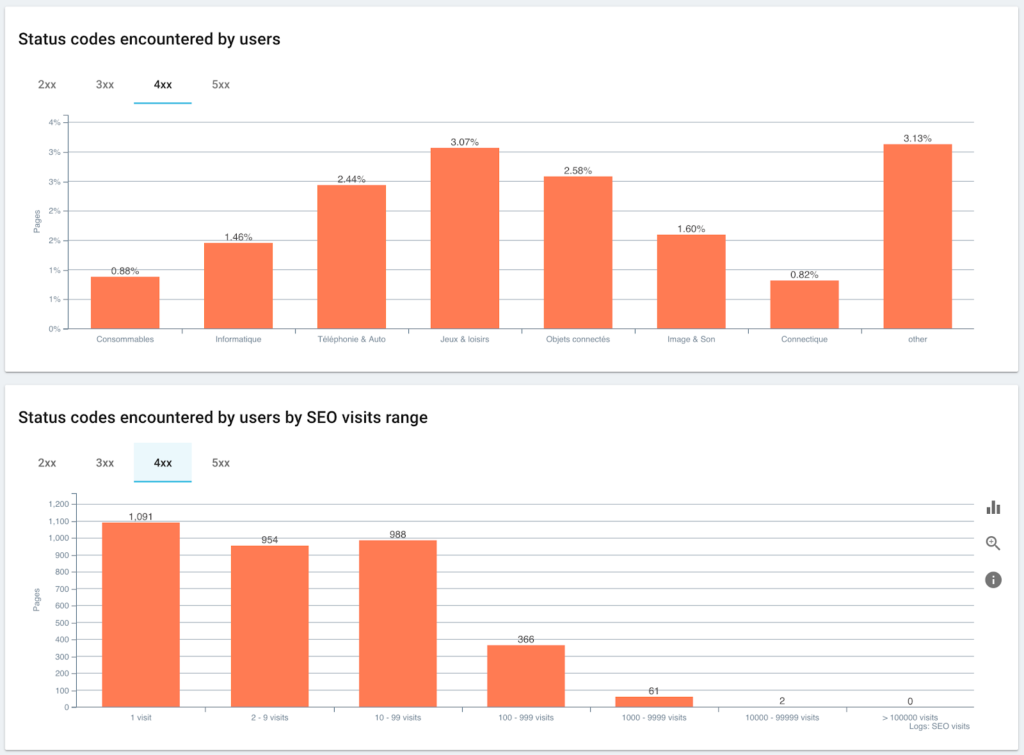
رموز الحالة التي واجهها المستخدمون مقابل جلسات تحسين محركات البحث
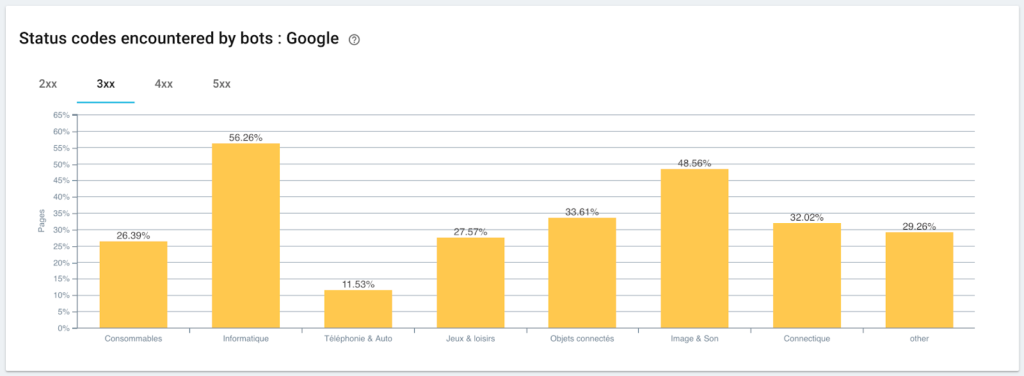
رصد رموز الحالة التي يواجهها Googlebot
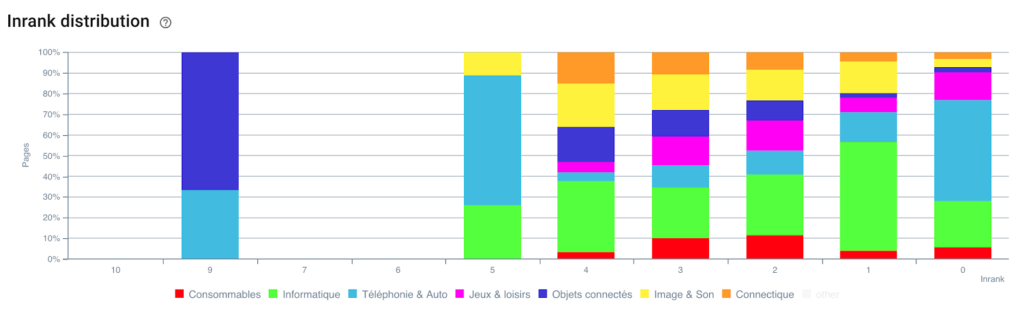
توزيع Inrank
وها نحن هنا ، لقد أنشأنا للتو تقسيمًا تلقائيًا بفضل برنامج نصي يستخدم Python و OnCrawl. يتم الآن تجميع جميع الصفحات وفقًا لمسار مسار التنقل وهذا على 3 مستويات من العمق: 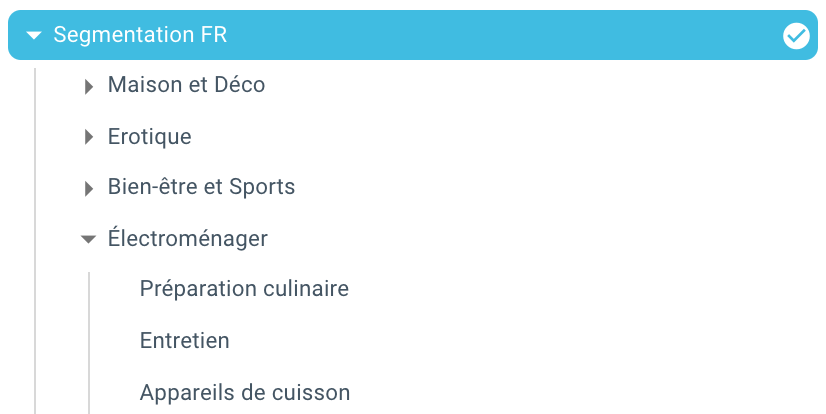
الميزة هي أنه يمكننا الآن مراقبة مؤشرات الأداء الرئيسية المختلفة (الزحف ، والعمق ، والروابط الداخلية ، وميزانية الزحف ، وجلسات تحسين محركات البحث ، وزيارات تحسين محركات البحث ، وأداء الترتيب ، ووقت التحميل) لكل مجموعة ومجموعة فرعية من الصفحات.
مستقبل تحسين محركات البحث مع Oncrawl
ربما تعتقد أنه من الرائع أن تمتلك هذه القدرة "الجاهزة" ولكن ليس بالضرورة أن يكون لديك الوقت للقيام بكل ذلك. الخبر السار هو أننا نعمل على دمج هذه الميزة بشكل مباشر في المستقبل القريب.
هذا يعني أنك ستتمكن قريبًا من إنشاء تجزئة تلقائيًا لأي حقل أو حقل تم إلغاؤه من إدخال البيانات بنقرة بسيطة. وهذا سيوفر لك الكثير من الوقت ، مع السماح لك بإجراء تحليل لا يصدق لتحسين محركات البحث.
تخيل أنك قادر على استخراج أي بيانات من الكود المصدري لصفحاتك أو دمج أي KPI لكل عنوان URL. الحد الوحيد هو خيالك!
على سبيل المثال ، يمكنك استرداد سعر بيع المنتجات ومعرفة العمق ، والروابط الواردة ، وميزانية الزحف وفقًا للسعر.
ولكن يمكننا أيضًا استرداد أسماء مؤلفي مقالاتك الإعلامية ومعرفة من يحقق أفضل أداء وتطبيق أساليب الكتابة التي تعمل بشكل أفضل.
يمكننا استرداد المراجعات والتقييمات الخاصة بمنتجاتك ومعرفة ما إذا كان يمكن الوصول إلى أفضل المنتجات بأقل عدد من النقرات ، أو تلقي روابط كافية ، أو روابط خلفية ، أو تم الزحف إليها جيدًا بواسطة Googlebot ، وما إلى ذلك ...
يمكننا دمج بيانات عملك مثل رقم الأعمال والهامش ومعدل التحويل ونفقات إعلانات Google الخاصة بك.
الآن الأمر متروك لك لتخيل كيف يمكنك الإسناد الترافقي للبيانات لتوسيع تحليلك واتخاذ قرارات تحسين محركات البحث الصحيحة.
هل تريد اختبار التجزئة التلقائية على مسار التنقل؟ تواصل معنا عبر صندوق الدردشة مباشرة من داخل Oncrawl.
استمتع بالزحف الخاص بك!