
استخراج المفاهيم والكلمات الأساسية تلقائيًا من النص (الجزء الأول: الطرق التقليدية)
نشرت: 2022-02-22في قسم البحث والتطوير في Oncrawl ، نتطلع بشكل متزايد إلى تحسين المحتوى الدلالي لصفحات الويب الخاصة بك. باستخدام نماذج التعلم الآلي لمعالجة اللغة الطبيعية (NLP) ، يمكننا مقارنة محتوى صفحاتك بالتفصيل ، وإنشاء ملخصات تلقائية ، وإكمال علامات مقالاتك أو تصحيحها ، وتحسين المحتوى وفقًا لبيانات Google Search Console ، وما إلى ذلك.
في مقال سابق تحدثنا عن استخراج محتوى نصي من صفحات HTML. هذه المرة ، نود التحدث عن الاستخراج التلقائي للكلمات الرئيسية من النص. سيتم تقسيم هذا الموضوع إلى رسالتين:
- الأول سيغطي السياق وما يسمى بالطرق "التقليدية" مع العديد من الأمثلة الملموسة
- الطريقة الثانية التي ستأتي قريبًا ستتعامل مع المزيد من الأساليب الدلالية القائمة على المحولات وأساليب التقييم من أجل قياس هذه الأساليب المختلفة
سياق
بعيدًا عن العنوان أو الملخص ، ما هي أفضل طريقة لتحديد محتوى نص أو ورقة علمية أو صفحة ويب أفضل من استخدام بضع كلمات رئيسية. إنها طريقة بسيطة وفعالة للغاية لتحديد موضوع ومفاهيم نص أطول بكثير. يمكن أن تكون أيضًا طريقة جيدة لتصنيف سلسلة من النصوص: تحديدها وتجميعها حسب الكلمات الرئيسية. يمكن للمواقع التي تقدم مقالات علمية مثل PubMed أو arxiv.org تقديم فئات وتوصيات بناءً على هذه الكلمات الرئيسية.
تعتبر الكلمات الرئيسية مفيدة جدًا أيضًا لفهرسة المستندات الكبيرة جدًا واسترجاع المعلومات ، وهو مجال خبرة معروف جيدًا بواسطة محركات البحث
يعد نقص الكلمات الرئيسية مشكلة متكررة في التصنيف التلقائي للمقالات العلمية [1]: العديد من المقالات لا تحتوي على كلمات أساسية معينة. لذلك ، يجب العثور على طرق لاستخراج المفاهيم والكلمات الأساسية تلقائيًا من النص. من أجل تقييم مدى ملاءمة مجموعة الكلمات الرئيسية المستخرجة تلقائيًا ، غالبًا ما تقارن مجموعات البيانات الكلمات الرئيسية المستخرجة بواسطة خوارزمية مع الكلمات الرئيسية المستخرجة من قبل العديد من الأشخاص.
كما يمكنك أن تتخيل ، هذه مشكلة تشاركها محركات البحث عند تصنيف صفحات الويب. يسمح الفهم الأفضل للعمليات الآلية لاستخراج الكلمات الرئيسية بفهم أفضل لسبب وضع صفحة الويب لمثل هذه الكلمات الرئيسية أو تلك. يمكن أن يكشف أيضًا عن الفجوات الدلالية التي تمنعه من الترتيب الجيد للكلمة الرئيسية التي استهدفتها.
من الواضح أن هناك عدة طرق لاستخراج الكلمات الرئيسية من نص أو فقرة. في هذا المنشور الأول ، سنصف ما يسمى بالمناهج "الكلاسيكية".
[كتاب إلكتروني] تحسين محركات البحث للبيانات: المغامرة الكبرى التالية
 اقرأ الكتاب الإلكتروني
اقرأ الكتاب الإلكترونيالقيود
ومع ذلك ، لدينا بعض القيود والمتطلبات الأساسية في اختيار الخوارزمية:
- يجب أن تكون الطريقة قادرة على استخراج الكلمات الأساسية من مستند واحد. تتطلب بعض الطرق مجموعة كاملة ، أي عدة مئات أو حتى آلاف المستندات. على الرغم من إمكانية استخدام هذه الأساليب بواسطة محركات البحث ، إلا أنها لن تكون مفيدة لوثيقة واحدة.
- نحن في حالة تعلم الآلة غير الخاضعة للرقابة. ليس لدينا مجموعة بيانات متوفرة باللغة الفرنسية أو الإنجليزية أو لغات أخرى بها بيانات مشروحة. بمعنى آخر ، ليس لدينا آلاف المستندات بكلمات رئيسية مستخرجة بالفعل.
- يجب أن تكون الطريقة مستقلة عن المجال / المجال المعجمي للمستند. نريد أن نكون قادرين على استخراج الكلمات الأساسية من أي نوع من المستندات: المقالات الإخبارية ، وصفحات الويب ، وما إلى ذلك. لاحظ أن بعض مجموعات البيانات التي تحتوي بالفعل على كلمات رئيسية مستخرجة لكل مستند غالبًا ما تكون عبارة عن طب خاص بمجال معين ، وعلوم الكمبيوتر ، وما إلى ذلك.
- تعتمد بعض الطرق على نماذج علامات نقاط البيع ، أي قدرة نموذج البرمجة اللغوية العصبية على تحديد الكلمات في جملة من خلال نوعها النحوي: فعل ، اسم ، محدد. من الواضح أن تحديد أهمية الكلمة الرئيسية التي تكون اسمًا وليس محددًا. ومع ذلك ، اعتمادًا على اللغة ، تكون نماذج علامات نقاط البيع أحيانًا ذات جودة متفاوتة للغاية.
حول الطرق التقليدية
نحن نفرق بين ما يسمى بالطرق "التقليدية" والطرق الأحدث التي تستخدم البرمجة اللغوية العصبية - معالجة اللغة الطبيعية - تقنيات مثل حفلات الزفاف وحفلات الزفاف السياقية. سيتم تغطية هذا الموضوع في وظيفة في المستقبل. لكن أولاً ، دعنا نعود إلى الأساليب الكلاسيكية ، نميز اثنين منها:
- نهج الإحصاء
- نهج الرسم البياني
سيعتمد نهج الإحصاء بشكل أساسي على ترددات الكلمات وتواجدها المشترك. نبدأ بفرضيات بسيطة لبناء الاستدلال واستخراج الكلمات المهمة: كلمة متكررة جدًا ، سلسلة من الكلمات المتتالية التي تظهر عدة مرات ، إلخ. ستنشئ الطرق القائمة على الرسم البياني رسمًا بيانيًا حيث يمكن أن تتوافق كل عقدة مع كلمة أو مجموعة من كلمات أو جملة. ثم يمكن أن يمثل كل قوس احتمال (أو تكرار) ملاحظة هذه الكلمات معًا.
فيما يلي بعض الطرق:
- قائم على الإحصاء
- TF-IDF
- مجرفة
- ثمر
- على أساس الرسم البياني
- TextRank
- الموضوع
- SingleRank
تستخدم جميع الأمثلة الواردة نصًا مأخوذًا من صفحة الويب هذه: Jazz au Tresor: John Coltrane - Impressions Graz 1962.
نهج الإحصاء
سوف نقدم لك طريقتين Rake و Yake. في سياق تحسين محركات البحث ، ربما تكون قد سمعت عن طريقة TF-IDF. ولكن نظرًا لأنه يتطلب مجموعة من الوثائق ، فلن نتعامل معها هنا.
مجرفة
يرمز RAKE إلى الاستخراج التلقائي السريع للكلمات الرئيسية. هناك العديد من التطبيقات لهذه الطريقة في بايثون ، بما في ذلك rake-nltk. تعتمد درجة كل كلمة رئيسية ، والتي تسمى أيضًا keyphrase لأنها تحتوي على عدة كلمات ، على عنصرين: تكرار الكلمات ومجموع تكراراتها المشتركة. إن تكوين كل عبارة رئيسية بسيط للغاية ، ويتكون من:
- قص النص إلى جمل
- قص كل جملة إلى جمل مفتاحية
في الجملة التالية ، سنأخذ كل مجموعات الكلمات مفصولة بعناصر ترقيم أو كلمات إيقاف:
قبل ذلك بقليل ، كان كولتران يقود خماسيًا ، مع إريك دولفي إلى جانبه وريجى وركمان على صوت جهير مزدوج.
قد ينتج عن هذا العبارات الرئيسية التالية:
"Just before", "Coltrane", "head", "quintet", "Eric Dolphy", "sides", "Reggie Workman", "double bass" .
لاحظ أن كلمات التوقف هي سلسلة من الكلمات المتكررة جدًا مثل " the " و " in " و "and" or " it ". نظرًا لأن الطرق الكلاسيكية غالبًا ما تستند إلى حساب تكرار حدوث الكلمات ، فمن المهم اختيار كلمات التوقف الخاصة بك بعناية. في معظم الأوقات ، لا نريد أن يكون لدينا كلمات مثل >"to" "the" or "من" في مقترحاتنا للعبارات الرئيسية. في الواقع ، لا ترتبط كلمات التوقف هذه بحقل معجمي معين ، وبالتالي فهي أقل صلة بكثير من الكلمات " jazz " أو " saxophone " على سبيل المثال.

بمجرد عزل العديد من عبارات المفاتيح المرشحة ، نمنحهم درجة وفقًا لتكرار الكلمات وتكرارها. كلما زادت النتيجة ، كلما كان من المفترض أن تكون العبارات الرئيسية أكثر صلة.
دعنا نحاول بسرعة مع النص من المقالة حول جون كولتراين.
# مقتطف بيثون لأشعل النار من rake_nltk استيراد الخليع # افترض أنك بالفعل تحتوي على المقالة في متغير "النص" أشعل النار = الخليع (Stopwords = FRENCH_STOPWORDS ، max_length = 4) rake.extract_keywords_from_text (نص) rake_keyphrases = rake.get_ranked_phrases_with_scores () [: TOP]
فيما يلي أول 5 جمل رئيسية:
"الإذاعة العامة النمساوية" ، "القمم الغنائية أكثر سماوية" ، "غراتس لها خاصيتان" ، "جون كولتران تينور الساكسفون" ، "النسخة المسجلة فقط"
هناك بعض العيوب لهذه الطريقة. الأول هو أهمية اختيار كلمات التوقف لأنها تستخدم لتقسيم الجملة إلى عبارات رئيسية مرشحة. والثاني هو أنه عندما تكون العبارات الرئيسية طويلة جدًا ، فغالبًا ما تحصل على درجة أعلى بسبب التواجد المشترك للكلمات الموجودة. للحد من طول عبارات المفاتيح ، قمنا بتعيين الطريقة على max_length=4 .
ثمر
YAKE لتقف على آخر مستخرج الكلمات الرئيسية. تعتمد هذه الطريقة على المقالة التالية YAKE! استخراج الكلمات الرئيسية من مستندات فردية باستخدام ميزات محلية متعددة تعود إلى عام 2020. وهي طريقة أحدث من RAKE التي اقترح مؤلفوها تطبيق Python المتاح على Github.
أما بالنسبة لـ RAKE ، فسوف نعتمد على تكرار الكلمات والتواجد المشترك. سيضيف المؤلفون أيضًا بعض الأساليب البحثية المثيرة للاهتمام:
- سوف نميز بين الكلمات ذات الأحرف الصغيرة والكلمات الكبيرة (إما الحرف الأول أو الكلمة بأكملها). سنفترض هنا أن الكلمات التي تبدأ بحرف كبير (ما عدا في بداية الجملة) أكثر صلة من غيرها: أسماء الأشخاص ، والمدن ، والبلدان ، والعلامات التجارية. هذا هو نفس المبدأ لجميع الكلمات المكتوبة بحروف كبيرة.
- ستعتمد درجة كل عبارة مفتاح مرشح على موقعها في النص. إذا ظهرت عبارات المفاتيح المرشحة في بداية النص ، فستحصل على درجة أعلى مما لو ظهرت في النهاية. على سبيل المثال ، غالبًا ما تذكر المقالات الإخبارية مفاهيم مهمة في بداية المقالة.
# مقتطف الثعبان ل yake من yake استيراد KeywordExtractor مثل Yake yake = Yake (lan = "fr" ، Stopwords = FRENCH_STOPWORDS) yake_keyphrases = yake.extract_keywords (نص)
مثل RAKE ، فيما يلي أهم 5 نتائج:
"Treasure Jazz" ، "John Coltrane" ، "Impressions Graz" ، "Graz" ، "Coltrane"
على الرغم من بعض الازدواجية لبعض الكلمات في بعض العبارات الرئيسية ، تبدو هذه الطريقة ممتعة للغاية.
نهج الرسم البياني
هذا النوع من النهج ليس بعيدًا جدًا عن النهج الإحصائي بمعنى أننا سنحسب أيضًا تكرارات الكلمات. تعتمد لاحقة الترتيب المرتبطة ببعض أسماء الطرق مثل TextRank على مبدأ PageRank algo لحساب شعبية كل صفحة بناءً على روابطها الواردة والصادرة.
[كتاب إلكتروني] أتمتة SEO مع Oncrawl
 اقرأ الكتاب الإلكتروني
اقرأ الكتاب الإلكترونيTextRank
تأتي هذه الخوارزمية من مقالة TextRank: Bringing Order in Texts من عام 2004 وتستند إلى نفس مبادئ خوارزمية PageRank . ومع ذلك ، بدلاً من إنشاء رسم بياني بالصفحات والروابط ، سننشئ رسمًا بيانيًا بالكلمات. سيتم ربط كل كلمة بكلمات أخرى وفقًا لتواجدها المشترك.
هناك العديد من التطبيقات في بايثون. في هذه المقالة ، سوف أقدم pytextrank. سنكسر أحد قيودنا المتعلقة بوضع علامات نقاط البيع. في الواقع ، عند بناء الرسم البياني ، لن نقوم بتضمين جميع الكلمات كعقد. سيتم أخذ الأفعال والأسماء فقط في الاعتبار. مثل الطرق السابقة التي تستخدم كلمات الإيقاف لتصفية المرشحين غير الملائمين ، تستخدم خوارزمية TextRank النوع النحوي للكلمات.
فيما يلي مثال لجزء من الرسم البياني سيتم بناؤه بواسطة algo: 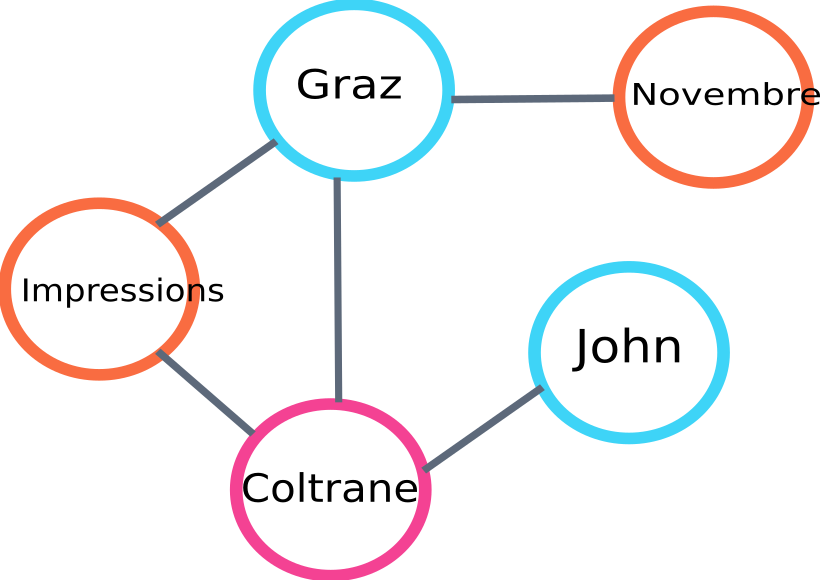
مثال على الرسم البياني لترتيب النص
هنا مثال على الاستخدام في بايثون. لاحظ أن هذا التنفيذ يستخدم آلية خط الأنابيب لمكتبة spaCy. هذه المكتبة قادرة على عمل علامات نقاط البيع.
# مقتطف بيثون لـ pytextrank
استيراد spacy
استيراد pytextrank
# تحميل نموذج فرنسي
nlp = spacy.load ("fr_core_news_sm")
# إضافة pytextrank إلى الأنبوب
nlp.add_pipe ("textrank")
doc = nlp (نص)
textrank_keyphrases = doc ._. عبارات
فيما يلي أهم 5 نتائج:
"Copenhague" و "novembre" و "Impressions Graz" و "Graz" و "John Coltrane"
بالإضافة إلى استخراج عبارات المفاتيح ، يقوم TextRank أيضًا باستخراج الجمل. يمكن أن يكون هذا مفيدًا جدًا لعمل ما يسمى ب "الملخصات الاستخراجية" - لن يتم تناول هذا الجانب في هذه المقالة.
الاستنتاجات
من بين الطرق الثلاث التي تم اختبارها هنا ، يبدو لنا أن الطريقتين الأخيرتين وثيقتي الصلة بموضوع النص. من أجل مقارنة هذه الأساليب بشكل أفضل ، من الواضح أنه سيتعين علينا تقييم هذه النماذج المختلفة على عدد أكبر من الأمثلة. توجد بالفعل مقاييس لقياس مدى ملاءمة نماذج استخراج الكلمات الرئيسية هذه.
توفر قوائم الكلمات الرئيسية التي تنتجها هذه النماذج التقليدية المزعومة أساسًا ممتازًا للتحقق من أن صفحاتك مستهدفة جيدًا. بالإضافة إلى ذلك ، فإنها تعطي أول تقدير تقريبي لكيفية فهم محرك البحث للمحتوى وتصنيفه.
من ناحية أخرى ، يمكن أيضًا استخدام طرق أخرى تستخدم نماذج البرمجة اللغوية العصبية المدربة مسبقًا مثل BERT لاستخراج المفاهيم من المستند. على عكس ما يسمى بالنهج الكلاسيكي ، تسمح هذه الأساليب عادةً بالتقاط الدلالات بشكل أفضل.
سيتم تقديم طرق التقييم المختلفة والزخارف السياقية والمحولات في مقال ثانٍ قادم حول هذا الموضوع!
فيما يلي قائمة بالكلمات الرئيسية المستخرجة من هذه المقالة بإحدى الطرق الثلاث المذكورة:
"الأساليب" ، "الكلمات الرئيسية" ، "الكلمات الرئيسية" ، "النص" ، "الكلمات الرئيسية المستخرجة" ، "معالجة اللغة الطبيعية"
المراجع الببليوغرافية
- [1] تحسين الاستخراج التلقائي للكلمات الرئيسية نظرًا لمزيد من المعرفة اللغوية ، أنيت هولث ، 2003
- [2] الاستخراج التلقائي للكلمات الرئيسية من المستندات الفردية ، Stuart Rose et. آل ، 2010
- [3] أكل! استخراج الكلمات الرئيسية من مستندات فردية باستخدام ميزات محلية متعددة ، Ricardo Campos et. آل ، 2020
- [4] TextRank: إحضار النظام إلى النصوص ، Rada Mihalcea et. آل ، 2004
ابدأ تجربتك المجانية لمدة 14 يومًا
 ابدأ تجربتك
ابدأ تجربتك