
الأصالة ، Dalle-2 & Midjourney وسحرنا من الصور والفنون التي تم إنشاؤها بواسطة الذكاء الاصطناعي
نشرت: 2022-08-04تتناول هذه المقالة التكنولوجيا وراء منصات مثل Dalle-2 و Midjourney ، ولماذا من المحتمل أن يدفع لك المبدعون Open AI المال - وليس فرض رسوم عليك ...
يقوم المزيد والمزيد من الأشخاص على الإنترنت بتسمية Dalle-2 و Open AI بأنها عملية احتيال. السبب هو أن Dalle-2 تحولت الآن فجأة إلى خدمة مالية ، حيث تحتاج إلى شراء أرصدة ، إذا كنت تستخدم النظام الأساسي خارج حدود الإصدار التجريبي.
DALLE 2 هي مجرد واحدة من العديد من المنصات الجديدة التي تتيح لك الوصول إلى المحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي ، وتدعي أنه يمكنك استخدامه لأغراض تجارية. تشمل المنصات الأخرى Midjourney و Jasper Art و Nightcafe و Starry AI و Craiyon. سنركز على Dalle 2 في منشور المدونة هذا ، لكنهما متطابقان تقريبًا ، عندما يتعلق الأمر بالتحديات والمشكلات القانونية.
يعتبر الاحتيال بيانًا قاسيًا جدًا في رأينا ، ولكن هناك مشكلة واضحة في استخدام البيانات التي أنشأها أشخاص آخرون (الصور ومقاطع الفيديو والتعليقات التوضيحية والأشخاص على الصور وما إلى ذلك) ثم البدء في بيعها مرة أخرى لنفس الأشخاص.
قد يتجاهل الكثير منا هذه المشكلة ، لأننا ببساطة مفتونون بالتكنولوجيا الجديدة. شيء مفهوم تماما.
ومع ذلك ، على الرغم من أن DALL-E 2 في نهاية اليوم هي مجرد آلة متطورة للتعرف على الأنماط ، إلا أن إخراجها ليس محايدًا ، والأنماط لا تأتي من الهواء النقي.
إنها تستند إلى الكثير من البيانات ، حيث توجد أسئلة قانونية متعددة يجب طرحها. الأسئلة التي تعتبر مهمة بالنسبة لك كمستخدم محتمل للصور التي تقوم بإنشائها.
 تم إنشاء الصورة بواسطة DALLE-2
تم إنشاء الصورة بواسطة DALLE-2
لا يمكن مقارنة نماذج الذكاء الاصطناعي بالبشر
يجب أن تبدأ بقراءة هذه المقالة الرائعة في Engadget ، قبل أن تبدأ في التفكير في استخدام صور DALL-E 2 لأغراض تجارية.
في مقال Engadget أشاروا إلى شيء آخر مهم للغاية. وهي حقيقة أن DALL-E 2 و OpenAI لا يتنازلان عن حقهما في تسويق الصور التي ينشئها المستخدمون باستخدام DALL-E. بمعنى أنه يمكنك إنشاء صور سيتم بيعها تجاريًا للآخرين.
هذا يدل على أن النوايا مختلفة تمامًا عن القياس المستخدم أحيانًا ، حيث سيقارنه مروجو DALLE-2 بطالب يقرأ عمل مؤلف معروف. في هذا المثال ، قد يتعلم الطالب أنماط وأنماط المؤلف ويجدها لاحقًا قابلة للتطبيق في سياقات أخرى ويعيد استخدامها هناك.
ومع ذلك ، لا يتعلق الأمر باستخدام العقل البشري للذاكرة الإبداعية لإنشاء أعمال إبداعية جديدة. يتعلق هذا بإعادة استخدام آلة التعرف على الأنماط وفي بعض الحالات إعادة إنتاج بيانات التدريب في الصور التي يتم استخدامها بعد ذلك أو حتى بيعها تجاريًا. إنه ببساطة عالمان مختلفان - سواء بالمعنى المجازي أو بالمعنى الحرفي.
 صورة حقيقية من العالم الحقيقي
صورة حقيقية من العالم الحقيقي
وعد أصالة JumpStory
هذه المقالة مخصصة للأشخاص الذين يريدون أن يفهموا على مستوى أعمق ، كيف تعمل تقنية إنشاء الصور الجديدة بالذكاء الاصطناعي. ولكن قبل أن نبدأ ببضع كلمات فقط حول سبب عدم قيام JumpStory حاليًا ببناء آلة مماثلة.
بالطبع ، لقد طرح علينا هذا السؤال عدة مرات. ليس أقلها الأخذ في الاعتبار أننا نستخدم بالفعل الذكاء الاصطناعي في شركتنا ، وبما أننا نتمكن من الوصول إلى ملايين الصور الأصلية.
ومع ذلك ، فهذه ليست مناقشة تكنولوجية بالنسبة لنا ، ولكنها مناقشة أخلاقية. مناقشة نتج عنها وعدنا بالأصالة.
نحن في الأساس ضد المستقبل ، حيث تصبح الصور التي يتم إنشاؤها بواسطة الذكاء الاصطناعي هي القاعدة وليس الاستثناء. اتصل بنا على الطراز القديم ، لكننا نعتقد أن العالم الحقيقي جميل.
نحن فخورون بأن صورنا وفيديوهاتنا تصور أناسًا حقيقيين بأشكال وأحجام مختلفة. نحن لسنا ضد استخدام الذكاء الاصطناعي ، لكننا لا نعتقد أنه يجب استخدامه لتوليد أشخاص أو حقائق مزيفة.
قد تكون التقنيات مثل الوسائط الاصطناعية و DALL-E 2 رائعة على السطح ، لكنها تشكل خطرًا حقيقيًا أيضًا. إنهم يخاطرون بتشويش الخطوط الفاصلة بين الحقيقي والمزيف ، مما سيشكل تهديدًا أساسيًا للثقة بين البشر.
هذا هو السبب في أن JumpStory لا يستخدم الذكاء الاصطناعي لإنشاء صور مزيفة ، ولكن بدلاً من ذلك يستخدم الذكاء الاصطناعي لتحديد الصور الأصلية والأصيلة - وبالطبع - قانوني للاستخدام لأغراض تجارية.

هذه هي الصور التي تجدها باستخدام خدمتنا ، وقد أطلقنا على نهجنا اسم "الذكاء الأصيل".
فهم كيفية إنشاء صور AI
يكفي حول JumpStory والمشكلات القانونية المتعلقة بـ DALL-E 2 في الوقت الحالي. دعونا نلقي نظرة على كيفية إنشاء صور الذكاء الاصطناعي على منصات مثل DALLE-2 و Imagen و Crayion (Dall-E Mini سابقًا) و Midjourney وما إلى ذلك ... باستخدام DALLE-2 باعتباره المثال الأكثر رواجًا حاليًا.
لتبدأ بـ DALLE-2 ، يمكنك أداء أنواع مختلفة من المهام ، لكننا سنركز على مهمة إنشاء الصور في هذه المدونة.
كيف يعمل هو أن موجه النص يتم إدخاله في برنامج تشفير النص. تم تدريب هذا المشفر على تعيين الموجه إلى مساحة التمثيل. بعد ذلك ، يقوم ما يسمى بالنموذج السابق بتعيين النص المشفر إلى ترميز صورة مطابق يلتقط المعلومات الدلالية لموجه تشفير النص.
(إذا أصبح هذا بالفعل غريب الأطوار قليلاً ، فأنا آسف جدًا ، لكنه سيزداد سوءًا)
تتمثل الخطوة الأخيرة في برنامج تشفير الصور في إنشاء صورة تصور المعلومات الدلالية التي تلقاها المشفر. هذه هي أساسيات الآلات مثل Open AI.
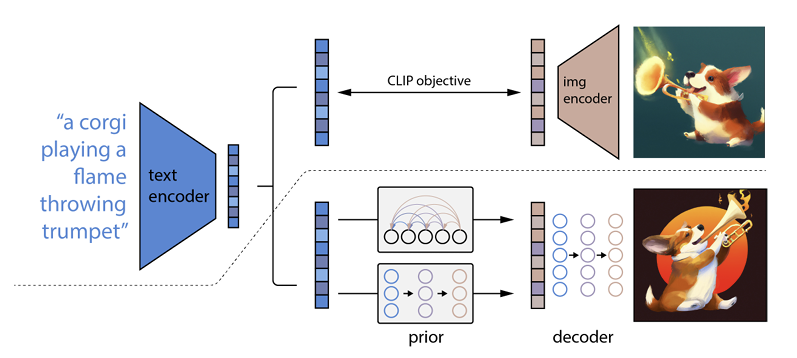
العلاقة بين النص والمرئيات
غالبًا ما يشار إلى DALL-E 2 والتقنيات المماثلة على أنها مولدات تحويل النص إلى صورة. السبب هو قدرتها على تلقي إدخال نصي وتقديم إخراج الصورة.
لإعطائك مثالاً ، هذا هو "رائد فضاء يمتطي حصانًا بأسلوب آندي وارهول:

المصدر: DALLE-2
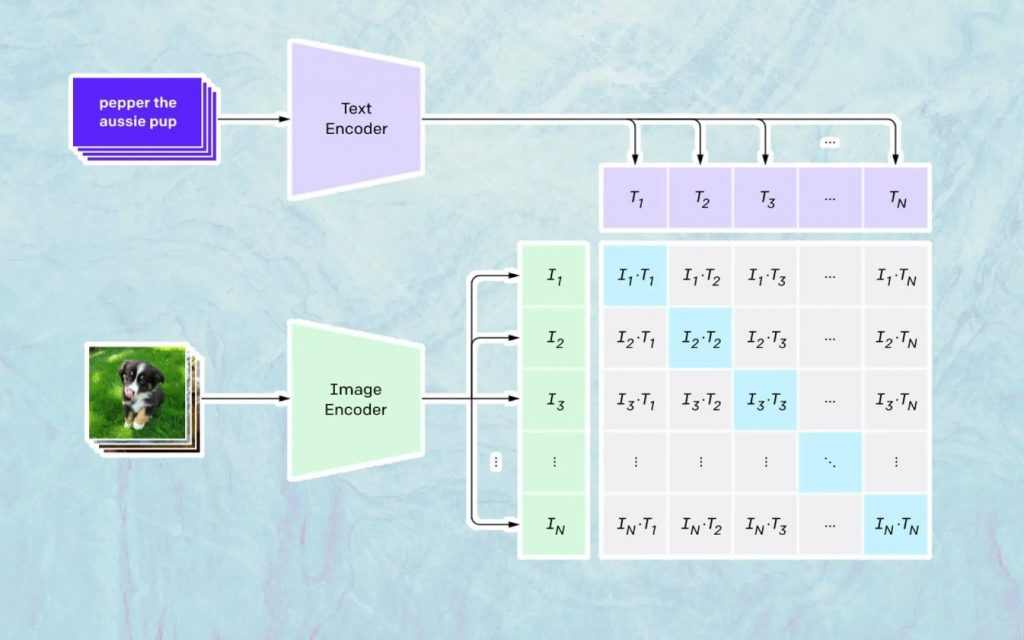
ما يحدث هنا يعتمد على نموذج Open AI المسمى CLIP. CLIP اختصار لعبارة "التدريب المسبق على اللغة المتباينة والصورة" وهو نموذج معقد للغاية تم تدريبه على ملايين الصور والتعليقات التوضيحية.
إن ما يجيده CLIP بشكل خاص هو فهم مدى ارتباط نص معين بصورة معينة. المفتاح هنا ليس التسمية التوضيحية ، ولكن مدى ارتباط تسمية توضيحية معينة بصورة معينة.
يسمى هذا النوع من التكنولوجيا "التباين" ، وما تستطيع CLIP فعله هو تعلم الدلالات من اللغة الطبيعية. الطريقة التي تعلمت بها CLIP ذلك هي من خلال عملية ، حيث الهدف هو (نقتبس الآن الوثائق التكنولوجية): "تعظيم تشابه جيب التمام في نفس الوقت بين أزواج الصور / التسمية التوضيحية المشفرة Ncorrect وتقليل تشابه جيب التمام بين N 2 - N صورة مشفرة غير صحيحة / أزواج التسمية التوضيحية. "
توليد الصور
كما هو موضح أعلاه ، يتعلم نموذج CLIP مساحة تمثيل يمكنه من خلالها تحديد كيفية ارتباط ترميز الصور والنصوص.
المهمة التالية هي استخدام هذه المساحة لتوليد الصور. لهذا الغرض ، طور Open AI نموذجًا آخر يسمى GLIDE ، وهو قادر على استخدام المدخلات من CLIP و - باستخدام نموذج الانتشار - تنفيذ توليد الصور.
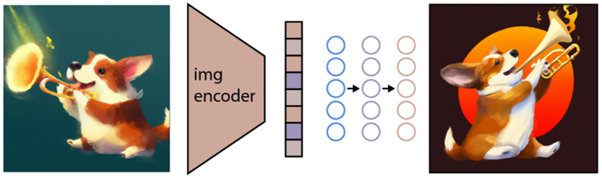
لشرح ما هو نموذج الانتشار بإيجاز ، فهو في الأساس نموذج يتعلم إنشاء البيانات عن طريق عكس عملية التشويش التدريجي. نأسف لأن هذا أصبح الآن تقنيًا للغاية ، لذلك اقتبس وصفًا موجودًا في وثائق Open AI:
"يُنظر إلى عملية التشويش على أنها سلسلة ماركوف ذات معلمات تضيف ضوضاء تدريجيًا إلى الصورة لإفسادها ، مما يؤدي في النهاية (بشكل مقارب) إلى ضوضاء غاوسية نقية. يتعلم نموذج الانتشار التنقل للخلف على طول هذه السلسلة ، ويزيل التشويش تدريجيًا عبر سلسلة من الخطوات الزمنية لعكس هذه العملية ".

إذا كنت تريد التعمق أكثر في التكنولوجيا ، فنحن نوصي بقراءة هذا المقال الممتاز بقلم رايان أوكونور.