
كيفية الإجابة على أسئلة البيانات المعقدة باستخدام بيانات Oncrawl ، خارج Oncrawl
نشرت: 2022-01-04تتمثل إحدى مزايا Oncrawl for enterprise SEO في الوصول الكامل إلى بياناتك الأولية. سواء كنت تقوم بتوصيل بيانات تحسين محركات البحث (SEO) الخاصة بك بذكاء الأعمال أو سير عمل علم البيانات ، أو تنفيذ التحليلات الخاصة بك ، أو العمل ضمن إرشادات أمان البيانات لمؤسستك ، فإن بيانات تدقيق مواقع الويب وتحسين محركات البحث الخام يمكن أن تخدم العديد من الأغراض.
سننظر اليوم في كيفية استخدام بيانات Oncrawl للإجابة على أسئلة البيانات المعقدة.
ما هو سؤال البيانات المعقدة؟
أسئلة البيانات المعقدة هي أسئلة لا يمكن الإجابة عليها من خلال بحث بسيط في قاعدة البيانات ، ولكنها تتطلب معالجة البيانات للحصول على الإجابة.
في ما يلي بعض الأمثلة الشائعة لأسئلة البيانات "المعقدة" التي غالبًا ما تطرحها مُحسّنات محرّكات البحث:
- إنشاء قائمة بجميع الروابط التي تشير إلى الصفحات التي تعيد التوجيه إلى صفحات أخرى بالحالة 404
- إنشاء قائمة بجميع الروابط ونصها الأساسي الذي يشير إلى صفحات في تجزئة بناءً على مقاييس غير عناوين URL
كيف تجيب على أسئلة البيانات المعقدة في Oncrawl
تم إنشاء بنية بيانات Oncrawl للسماح لجميع المواقع تقريبًا بالبحث عن البيانات في الوقت الفعلي تقريبًا. يتضمن ذلك تخزين أنواع مختلفة من البيانات في مجموعات بيانات مختلفة لضمان الاحتفاظ بأوقات البحث عند الحد الأدنى في الواجهة. على سبيل المثال ، نقوم بتخزين جميع البيانات المرتبطة بعناوين URL في مجموعة بيانات واحدة: كود الاستجابة ، وعدد الروابط الصادرة ، ونوع البيانات المنظمة الحالية ، وعدد الكلمات ، وعدد الزيارات العضوية ... ونخزن جميع البيانات المتعلقة بالروابط في مجموعة بيانات منفصلة: هدف الارتباط ، أصل الرابط ، نص الرابط ...
يعد الانضمام إلى مجموعات البيانات هذه أمرًا معقدًا من الناحية الحسابية ، ولا يتم دعمه دائمًا في واجهة تطبيق Oncrawl. عندما تكون مهتمًا بالبحث عن شيء ما يتطلب تصفية مجموعة بيانات واحدة للبحث عن شيء ما في مجموعة أخرى ، فإننا نوصي بمعالجة البيانات الأولية بنفسك.
نظرًا لأن جميع بيانات Oncrawl متاحة لك ، فهناك العديد من الطرق للانضمام إلى مجموعات البيانات والتعبير عن الاستعلامات المعقدة.
في هذه المقالة ، سنلقي نظرة على أحدها ، باستخدام Google Cloud و BigQuery ، وهو مناسب لمجموعات البيانات الكبيرة جدًا مثل العديد من عملائنا عند فحص البيانات للمواقع التي تحتوي على عدد كبير من الصفحات.
ماذا ستحتاج
لاتباع الطريقة التي سنناقشها في هذه المقالة ، ستحتاج إلى الوصول إلى الأدوات التالية:
- أونكراول
- واجهة برمجة تطبيقات Oncrawl مع تصدير البيانات الضخمة
- جوجل كلاود التخزين
- BigQuery
- نص برمجي Python لنقل البيانات من Oncrawl إلى BigQuery (سنقوم ببناء هذا أثناء المقالة.)
قبل أن تبدأ ، ستحتاج إلى الوصول إلى تقرير الزحف المكتمل في Oncrawl.
كيفية الاستفادة من بيانات Oncrawl في Google BigQuery
خطة مقال اليوم هي كما يلي:
- أولاً ، سنتأكد من إعداد Google Cloud Storage لتلقي البيانات من Oncrawl.
- بعد ذلك ، سنستخدم برنامج Python النصي لتشغيل عمليات تصدير البيانات الكبيرة من Oncrawl لتصدير البيانات من زحف معين إلى حاوية تخزين Google Cloud Storage. سنقوم بتصدير مجموعتي بيانات: الصفحات والروابط.
- عندما يتم ذلك ، سننشئ مجموعة بيانات في Google BigQuery. سننشئ بعد ذلك جدولاً من كل من المصدرين ضمن مجموعة بيانات BigQuery.
- أخيرًا ، سنقوم بتجربة الاستعلام عن مجموعات البيانات الفردية ، ثم كلتا مجموعتي البيانات معًا للعثور على إجابة لسؤال معقد.
الإعداد داخل Google Cloud لتلقي بيانات Oncrawl
لتشغيل هذا الدليل في بيئة وضع حماية مخصصة ، نوصيك بإنشاء مشروع Google Cloud جديد لعزل ذلك عن مشاريعك الجارية الحالية.
لنبدأ في منزل Google Cloud.
من صفحة Google Cloud الرئيسية ، يمكنك الوصول إلى العديد من الأشياء بالإضافة إلى التخزين السحابي. نحن مهتمون بحاويات التخزين السحابي ، والمتوفرة ضمن طبقة التخزين السحابي في Google Cloud Platform: 
يمكنك أيضًا الوصول إلى متصفح Cloud Storage مباشرة على https://console.cloud.google.com/storage/browser.
ستحتاج بعد ذلك إلى إنشاء حاوية التخزين السحابي ، ومنح الأذونات الصحيحة حتى يُسمح لحساب خدمة Oncrawl بالكتابة فيه ، تحت البادئة التي تختارها.
ستعمل حاوية Google Cloud Storage كتخزين مؤقت للاحتفاظ بصادرات البيانات الضخمة من Oncrawl قبل تحميلها في Google BigQuery.
في هذه المجموعة ، قمت أيضًا بإنشاء مجلدين: "روابط" و "صفحات": 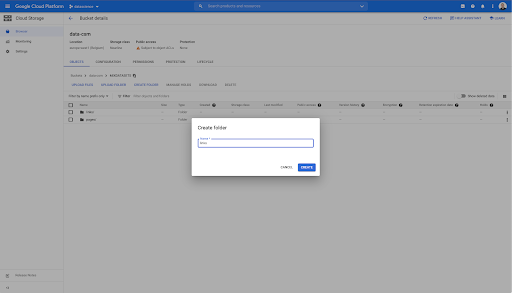
تصدير مجموعات البيانات من Oncrawl
الآن بعد أن قمنا بإعداد المساحة حيث نريد حفظ البيانات ، نحتاج إلى تصديرها من Oncrawl. يعد التصدير إلى حاوية Google Cloud Storage مع Oncrawl أمرًا سهلاً بشكل خاص ، حيث يمكننا تصدير البيانات بالتنسيق الصحيح وحفظها مباشرةً في الحاوية. هذا يلغي أي خطوات إضافية.
إنشاء مفتاح API
سيتطلب تصدير البيانات من Oncrawl بتنسيق Parquet لـ BigQuery استخدام مفتاح واجهة برمجة التطبيقات للعمل على واجهة برمجة التطبيقات برمجيًا ، نيابة عن مالك حساب Oncrawl. يتيح تطبيق Oncrawl للمستخدمين إنشاء مفاتيح API مسماة بحيث يكون حسابك منظمًا ونظيفًا دائمًا. ترتبط مفاتيح API أيضًا بأذونات (نطاقات) مختلفة بحيث يمكنك إدارة المفاتيح وأغراضها.
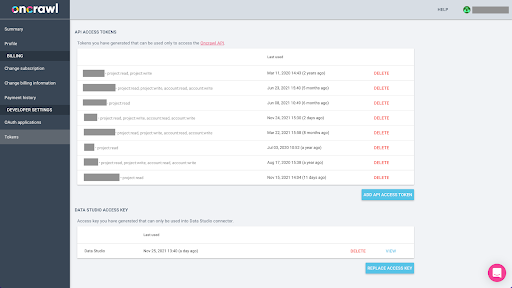
دعونا نسمي مفتاحنا الجديد "مفتاح جلسة المعرفة". تتطلب ميزة تصدير البيانات الضخمة أذونات الكتابة في الحساب ، لأننا نقوم بإنشاء عمليات تصدير البيانات. للقيام بذلك ، نحتاج إلى الوصول للقراءة على المشروع وقراءة وكتابة الوصول على الحساب.
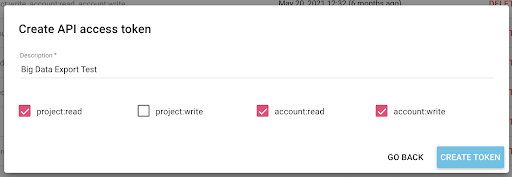
الآن لدينا مفتاح API جديد ، سأقوم بنسخه إلى الحافظة الخاصة بي.
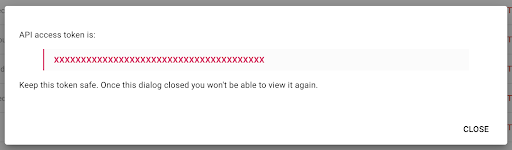
لاحظ أنه لأسباب أمنية ، يمكنك نسخ المفتاح مرة واحدة فقط . إذا نسيت نسخ المفتاح ، فستحتاج إلى حذف المفتاح وإنشاء مفتاح جديد.
إنشاء نص Python الخاص بك
لقد أنشأت دفتر ملاحظات Google Colab لهذا الغرض ، لكنني سأشارك الرمز أدناه حتى تتمكن من إنشاء أدواتك الخاصة أو دفتر ملاحظاتك الخاص.
1. قم بتخزين مفتاح API الخاص بك في متغير عام
أولاً ، نقوم بتمهيد البيئة ونعلن عن مفتاح API في متغير عالمي يسمى "Oncrawl Token". ثم نستعد لبقية التجربة:
# @ title قم بالوصول إلى Oncrawl API
# @ markdown قم بتوفير رمز API المميز الخاص بك أدناه للسماح لهذا الكمبيوتر الدفتري بالوصول إلى بيانات Oncrawl الخاصة بك:
# رمزك المميز لواجهة برمجة تطبيقات ONCRAWL
ONCRAWL_TOKEN = "" # @ param {type: "string"}
! نقطة تثبيت السجن
من IPython.display استيراد clear_output
clear_output ()
طباعة ("تم تحميلها بالكامل.") 
2. قم بإنشاء قائمة منسدلة لاختيار مشروع Oncrawl الذي تريد العمل معه
بعد ذلك ، باستخدام هذا المفتاح ، نريد أن نكون قادرين على اختيار المشروع الذي نريد اللعب به من خلال الحصول على قائمة بالمشاريع وإنشاء عنصر واجهة مستخدم منسدلة من تلك القائمة. من خلال تشغيل كتلة التعليمات البرمجية الثانية ، قم بتنفيذ الخطوات التالية:
- سنقوم باستدعاء Oncrawl API للحصول على قائمة بالمشاريع على الحساب باستخدام مفتاح API الذي تم إرساله للتو.
- بمجرد حصولنا على قائمة المشروع من استجابة API ، نقوم بتنسيقها كقائمة باستخدام اسم المشروع بالإضافة إلى عنوان URL لبدء المشروع.
- نقوم بتخزين معرف المشروع الذي تم توفيره في الرد.
- نبني قائمة منسدلة ونعرضها أسفل كتلة الكود.
# @ title حدد موقع الويب لتحليله باختيار مشروع Oncrawl المقابل
طلبات الاستيراد
سجن الاستيراد
استيراد ipywidgets كأدوات
استيراد json
# احصل على قائمة المشاريع
response = calls.get ("https://app.oncrawl.com/api/v2/projects؟limit={limit}&sort={sort}" .format (
الحد = 1000 ،
الفرز = 'الاسم: تصاعدي'
) ،
headers = {'التفويض': 'Bearer' + ONCRAWL_TOKEN}
)
json_res = response.json ()
#prepare القائمة المنسدلة للسماح للمستخدم بتحديد مشروع
المشاريع = []
للعنصر في json_res ['المشاريع']:
project.append (('{} - {}'. format (item ['name']، item ['start_url'])، item ['id']))
الإخراج = الحاجيات. الإخراج ()
dropdown_purpose = widgets.Dropdown (الخيارات = المشاريع ، الوصف = "المشروع:")
def dropdown_project_eventhandler (تغيير):
الإخراج. clear_output ()
مع الإخراج:
عرض (مشاريع)
dropdown_purpose.observe (dropdown_project_eventhandler ، الأسماء = "القيمة")
عرض (المنسدلة_غرضية) من القائمة المنسدلة التي ينشئها هذا ، يمكنك الاطلاع على القائمة الكاملة للمشروع الذي يمكن لمفتاح API الوصول إليه. 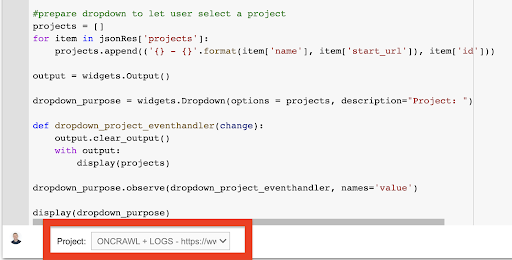
لغرض العرض التوضيحي اليوم ، نستخدم مشروعًا تجريبيًا يعتمد على موقع Oncrawl.
3. قم بإنشاء قائمة منسدلة لاختيار ملف تعريف الزحف داخل المشروع الذي تريد العمل معه
بعد ذلك ، سنقرر ملف تعريف الزحف الذي يجب استخدامه. نريد اختيار ملف تعريف الزحف داخل هذا المشروع. يحتوي المشروع التجريبي على الكثير من تكوينات الزحف المختلفة: 
في هذه الحالة ، نحن نبحث في مشروع تستخدمه فرق Oncrawl غالبًا لإجراء التجارب ، لذلك سأختار ملف تعريف الزحف الذي يستخدمه فريق التسويق لمراقبة أداء موقع Oncrawl على الويب. نظرًا لأنه من المفترض أن يكون ملف تعريف الزحف الأكثر استقرارًا ، فهو اختيار جيد للتجربة اليوم.
للحصول على ملف تعريف الزحف ، سنستخدم Oncrawl API ، لطلب آخر عملية زحف داخل كل ملف تعريف زحف فردي في المشروع:
- نحن نستعد للاستعلام عن Oncrawl API للمشروع المحدد.
- سنطلب جميع عمليات الزحف التي تم إرجاعها بترتيب تنازلي وفقًا لتاريخ "الإنشاء في".
طلبات الاستيراد
استيراد json
استيراد ipywidgets كأدوات
معرف المشروع = dropdown_purpose.value
# الحصول على تفاصيل المشاريع (بما في ذلك جميع عمليات الزحف في المشروع)
project = calls.get ("https://app.oncrawl.com/api/v2/projects/ {}" .format (project_id) ،
بارامس = ديكت (include_nested_resources = صحيح ، نوع = "created_at: desc") ،
headers = {'Authorization': 'Bearer' + ONCRAWL_TOKEN}). json ()
# عمليات الزحف الجماعية حسب ملف تعريف الزحف (اسم الزحف)
crawls_by_config = {}
محاولة:
للزحف في المشروع ["عمليات الزحف"]:
في حالة الزحف إلى ['الحالة'] في ["تم"]:
إذا لم يكن الزحف ['crawl_config'] ['name'] في crawls_by_config.keys ():
crawls_by_config [crawl ['crawl_config'] ['name']] = {'crawl_ids': []، 'is_crawl_archived': False}
if len (crawls_by_config [crawl ['crawl_config'] ['name']] ['crawl_ids']) == 0:
crawls_by_config [crawl ['crawl_config'] ['name']] ['crawl_ids']. إلحاق (تتبع ارتباطات ['id'])
في حالة الزحف إلى ['الحالة'] == "مؤرشف":
crawls_by_config [crawl ['crawl_config'] ['name']] ['is_crawl_archived'] = صحيح
باستثناء الاستثناء كـ e:
رفع استثناء ("خطأ {} ، {}". تنسيق (على سبيل المثال ، مشروع))
# بناء قائمة لاختيار القائمة المنسدلة
list = [("{} ({})". format (k، len (v ['crawl_ids']))، k) لـ k، v في crawls_by_config.items ()]
dropdown_crawl_configs = widgets.Dropdown (options = list، description = "تكوينات الزحف:")
def dropdown_cc_eventhandler (تغيير):
الإخراج. clear_output ()
مع الإخراج:
عرض (crawls_by_config)
إذا كان len (crawls_by_config.values ()) == 0:
طباعة ("لم يتم العثور على زحف مباشر في هذا المشروع")
dropdown_crawl_configs.observe (dropdown_cc_eventhandler ، الأسماء = "القيمة")
عرض (dropdown_crawl_configs)عند تشغيل هذا الرمز ، ستستجيب واجهة برمجة تطبيقات Oncrawl إلينا بقائمة عمليات الزحف عن طريق تنازلي خاصية "الإنشاء في".
بعد ذلك ، نظرًا لأننا نريد التركيز فقط على عمليات الزحف التي تم الانتهاء منها ، فسننتقل إلى قائمة عمليات الزحف. لكل عملية زحف فردية بالحالة "تم" ، سنحفظ اسم ملف تعريف الزحف وسنخزن معرف الزحف.
سنحتفظ بالزحف مرة واحدة على الأكثر عن طريق ملف تعريف الزحف حتى لا نرغب في الكشف عن عدد كبير جدًا من عمليات الزحف.
والنتيجة هي هذه القائمة المنسدلة الجديدة التي تم إنشاؤها من قائمة ملفات تعريف الزحف في المشروع. سنختار الشخص الذي نريده. سيستغرق هذا آخر عملية زحف يقوم بها فريق التسويق: 
4. حدد آخر عملية زحف بالملف الشخصي الذي نريد استخدامه
لدينا بالفعل معرّف الزحف المرتبط بآخر عملية زحف في الملف الشخصي المختار. إنه مخفي في قاموس الكائن "crawl_by_config". 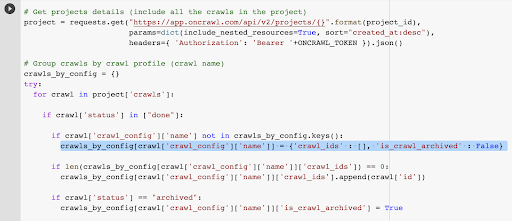
يمكنك التحقق من ذلك بسهولة في الواجهة: ابحث عن آخر عملية زحف مكتملة في تحليل الملف الشخصي هذا. 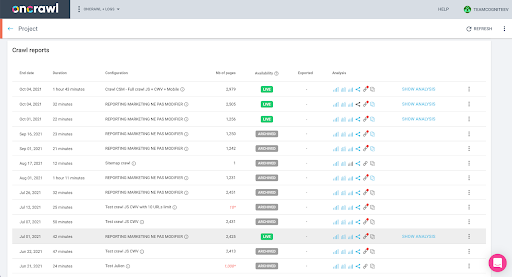
إذا نقرنا لعرض التحليل ، فسنرى أن معرف الزحف ينتهي بـ E617. 
دعنا فقط نلاحظ معرف الزحف لغرض العرض التوضيحي اليوم.
بالطبع ، إذا كنت تعرف بالفعل ما تفعله ، فيمكنك تخطي الخطوات التي تناولناها للتو للاتصال بواجهة برمجة تطبيقات Oncrawl للحصول على قائمة المشاريع وقائمة عمليات الزحف عن طريق ملف تعريف الزحف: لديك بالفعل معرف الزحف من الواجهة ، وهذا المعرف هو كل ما تحتاجه لتشغيل التصدير.
الخطوات التي نفذناها حتى الآن هي ببساطة لتسهيل عملية الحصول على آخر عملية زحف لملف تعريف الزحف المحدد للمشروع المحدد ، بالنظر إلى ما يمكن لمفتاح واجهة برمجة التطبيقات الوصول إليه. يمكن أن يكون هذا مفيدًا إذا كنت تقدم هذا الحل لمستخدمين آخرين ، أو إذا كنت تبحث عن أتمتة هذا الحل.
5. تصدير نتائج الزحف
الآن ، سنلقي نظرة على أمر التصدير:
# @ عنوان مشغل تصدير bigdata
# @ markdown قدم دلو GCS والبادئة gs: // some-bucket / pages
# بكت GCS الخاص بك
gcs_bucket = # @ param {type: "string"}
gcs_prefix = # @ param {type: "string"}
# احصل على معرف الزحف الأخير من ملف تعريف مشروع / زحف معين
list_crawl_ids = crawls_by_config [dropdown_crawl_configs.value] ['crawl_ids']
last_crawl_id = list_crawl_ids [0]
# حمولة القالب لاستعلام تصدير البيانات
الحمولة = {
"data_export": {
"data_type": "الصفحة"،
"Resource_id": last_crawl_id،
"output_format": "باركيه"،
"الهدف": "gcs"،
"target_parameters": {
"gcs_bucket": gcs_bucket ،
"gcs_prefix": gcs_prefix
}
}
}
# تصدير الزناد
export = request.post ("https://app.oncrawl.com/api/v2/account/data_exports"، json = payload، headers = {'Authorization': 'Bearer' + ONCRAWL_TOKEN}). json ()
# عرض استجابة API
عرض (تصدير)
# معرف تصدير مخزن للاستخدام في المستقبل
export_id = تصدير ['data_export'] ['id']نريد التصدير إلى حاوية التخزين السحابي التي أنشأناها مسبقًا.
ضمن ذلك سنقوم بتصدير الصفحات الخاصة بمعرف الزحف الأخير:
- يتم الحصول على معرف الزحف الأخير من قائمة معرفات الزحف ، والتي يتم تخزينها في مكان ما في قاموس "crawls_by_config" ، الذي تم إنشاؤه في الخطوة 3.
- نريد اختيار الخيار المقابل للقائمة المنسدلة في الخطوة 4 ، لذلك نستخدم سمة القيمة من القائمة المنسدلة.
- ثم نستخرج السمة crawl_ID. هذه قائمة. سنحتفظ بأفضل 50 عنصرًا في القائمة. نحتاج إلى القيام بذلك لأنه في الخطوة 2 ، كما ستتذكر ، عندما أنشأنا قاموس crawls_by_config ، قمنا بتخزين معرّف زحف واحد فقط لكل اسم تكوين.
لقد قمت بإعداد حقول الإدخال لتسهيل توفير حاوية Google Cloud Storage والبادئة أو المجلد الذي نريد إرسال التصدير إليه. 
لغرض العرض التوضيحي ، سنكتب اليوم إلى مجلد "مجموعة البيانات المختلطة" ، في أحد المجلدات التي أعددتها بالفعل. عندما نقوم بإعداد دلونا في Google Cloud Storage ، ستتذكر أنني أعددت مجلدات لتصدير "الروابط" ولتصدير "الصفحات".
بالنسبة للتصدير الأول ، سنرغب في تصدير الصفحات إلى مجلد "الصفحات" لمعرف الزحف الأخير باستخدام تنسيق ملف باركيه. 
في النتائج أدناه ، سترى الحمولة التي سيتم إرسالها إلى نقطة نهاية تصدير البيانات ، وهي نقطة النهاية لطلب تصدير البيانات الضخمة باستخدام مفتاح واجهة برمجة التطبيقات:
# حمولة القالب لاستعلام تصدير البيانات
الحمولة = {
"data_export": {
"data_type": "الصفحة"،
"Resource_id": last_crawl_id،
"output_format": "باركيه"،
"الهدف": "gcs"،
"target_parameters": {
"gcs_bucket": gcs_bucket ،
"gcs_prefix": gcs_prefix
}
}
}
يحتوي هذا على عدة عناصر ، بما في ذلك نوع مجموعة البيانات التي تريد تصديرها. يمكنك تصدير مجموعة بيانات الصفحة أو مجموعة بيانات الرابط أو مجموعة بيانات المجموعات أو مجموعة بيانات البيانات المنظمة. إذا كنت لا تعرف ما يمكن القيام به ، فيمكنك إدخال خطأ هنا ، وعندما تتصل بواجهة برمجة التطبيقات ، ستتلقى رسالة تفيد بأن اختيار نوع البيانات يجب أن يكون إما صفحة أو رابطًا أو مجموعة أو بيانات منظمة. تبدو الرسالة كما يلي:
{'الحقول': [{'message': 'ليس اختيارًا صالحًا. يجب أن تكون إحدى "الصفحة" ، "الرابط" ، "المجموعة" ، "البيانات المهيكلة". '،
"الاسم": "نوع البيانات"،
'type':'alid_choice '}] ،
'type': 'غير صالح_طلب_المعلمات'}
لغرض التجربة اليوم ، سنصدر مجموعة بيانات الصفحة ومجموعة بيانات الارتباط في عمليات تصدير منفصلة.

لنبدأ بمجموعة بيانات الصفحة. عندما أقوم بتشغيل كتلة التعليمات البرمجية هذه ، قمت بطباعة إخراج استدعاء API ، والذي يبدو كالتالي:
{'data_export': {'data_type': 'page'،
"export_failure_reason": لا شيء ،
"المعرف": "XXXXXXXXXXXXXX"،
"output_format": "باركيه"،
"output_format_parameters": لا شيء ،
"output_row_count": لا شيء ،
'output_size_in_bytes: 1634460016000 ،
'Resource_id': '60dd4c2b34d08a0f10a5e617'،
"الحالة": "مطلوب"،
"الهدف": "gcs"،
'target_parameters': {'gcs_bucket': 'data-cms'،
'gcs_prefix': 'MIXDATASETS / pages /'}}}
هذا يسمح لي بمعرفة أنه تم طلب التصدير.
إذا أردنا التحقق من حالة التصدير ، فالأمر بسيط للغاية. باستخدام معرف التصدير الذي حفظناه في نهاية كتلة التعليمات البرمجية هذه ، يمكننا طلب حالة التصدير في أي وقت باستخدام استدعاء API التالي:
# حالة التصدير
export_status = request.get ("https://app.oncrawl.com/api/v2/account/data_exports/ {}" .format (export_id)، headers = {'Authorization': 'Bearer' + ONCRAWL_TOKEN}). json ()
عرض (حالة_تصدير)
سيشير هذا إلى حالة كجزء من كائن JSON الذي تم إرجاعه:
{'data_export': {'data_type': 'page'،
"export_failure_reason": لا شيء ،
"المعرف": "XXXXXXXXXXXXXX"،
"output_format": "باركيه"،
"output_format_parameters": لا شيء ،
"output_row_count": لا شيء ،
"output_size_in_bytes": بلا ،
"مطلوب_ت": 1638350549000 ،
'Resource_id': '60dd4c2b34d08a0f10a5e617'،
"الحالة": "تصدير" ،
"الهدف": "gcs"،
'target_parameters': {'gcs_bucket': 'data-csm'،
'gcs_prefix': 'MIXDATASETS / pages /'}}} عند اكتمال التصدير ( 'status': 'DONE' ) ، يمكننا العودة إلى Google Cloud Storage.
إذا نظرنا في المجموعة الخاصة بنا ، وذهبنا إلى مجلد "الروابط" ، فلا يوجد أي شيء هنا حتى الآن لأننا قمنا بتصدير الصفحات. 
ومع ذلك ، عندما ننظر في مجلد "الصفحات" ، يمكننا أن نرى أن التصدير قد نجح. لدينا ملف باركيه: 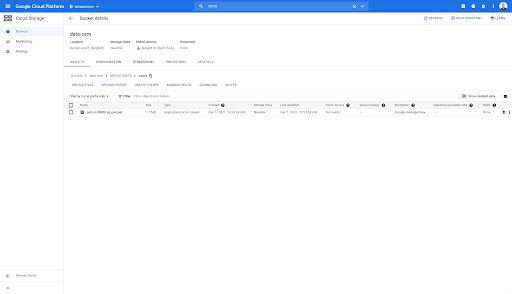
في هذه المرحلة ، تكون مجموعة بيانات الصفحات جاهزة للاستيراد في BigQuery ، ولكن أولاً سنكرر الخطوات المذكورة أعلاه للحصول على ملف باركيه للروابط:
- تأكد من ضبط بادئة الروابط.
- اختر نوع البيانات "ارتباط".
- قم بتشغيل مقطع التعليمات البرمجية هذا مرة أخرى لطلب التصدير الثاني.

سينتج هذا ملف باركيه في مجلد "الروابط".
إنشاء مجموعات بيانات BigQuery
أثناء تشغيل التصدير ، يمكننا المضي قدمًا والبدء في إنشاء مجموعات بيانات في BigQuery واستيراد ملفات باركيه إلى جداول منفصلة. ثم سنضم الجداول معا.
ما نريد فعله الآن هو اللعب باستخدام Google Big Query ، وهو شيء متاح كجزء من Google Cloud Platform. يمكنك استخدام شريط البحث أعلى الشاشة ، أو الانتقال مباشرة إلى https://console.cloud.google.com/bigquery.
إنشاء مجموعة بيانات لعملك
سنحتاج إلى إنشاء مجموعة بيانات داخل Google BigQuery: 
ستحتاج إلى تزويد مجموعة البيانات باسم ، واختيار الموقع حيث سيتم تخزين البيانات. هذا مهم لأنه سيحدد مكان معالجة البيانات ، ولا يمكن تغييره. يمكن أن يكون لذلك تأثير إذا كانت بياناتك تتضمن معلومات يغطيها القانون العام لحماية البيانات (GDPR) أو قوانين الخصوصية الأخرى. 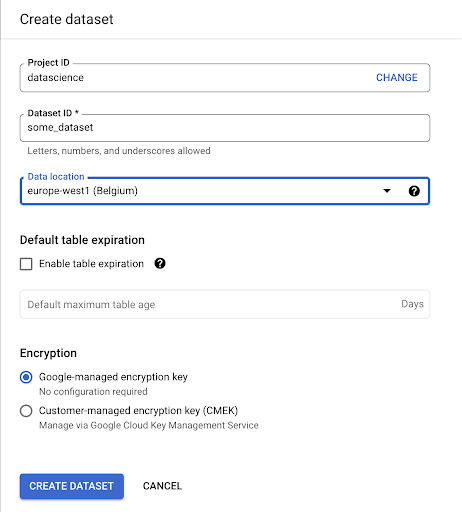
مجموعة البيانات هذه فارغة في البداية. عند فتحه ، ستتمكن من إنشاء جدول ومشاركة مجموعة البيانات والنسخ والحذف وما إلى ذلك.
إنشاء جداول للبيانات الخاصة بك
سنقوم بإنشاء جدول في مجموعة البيانات هذه. 
يمكنك إما إنشاء جدول فارغ ثم توفير المخطط. المخطط هو تعريف الأعمدة في الجدول. يمكنك إما تحديد الخاص بك ، أو يمكنك تصفح Google Cloud Storage لاختيار مخطط من ملف.
سنستخدم هذا الخيار الأخير. سننتقل إلى الحاوية الخاصة بنا ، ثم إلى مجلد "الصفحات". دعنا نختار ملف الصفحات. يوجد ملف واحد فقط ، لذا يمكننا تحديد ملف واحد فقط ، ولكن إذا كان التصدير قد أدى إلى إنشاء عدة ملفات ، فربما اخترناها جميعًا. 
عندما نحدد الملف ، فإنه يكتشف تلقائيًا أنه بتنسيق ملف باركيه. نريد إنشاء جدول باسم "صفحات" ، وسيتم تحديد المخطط بواسطة الملف المصدر. 
عندما نقوم بتحميل ملف باركيه ، فإنه يدمج مخططًا. بمعنى آخر ، سيتم استنتاج تعريف أعمدة الجدول الذي نقوم بإنشائه من المخطط الموجود بالفعل داخل ملف Parquet. هذا هو المكان الذي يحدث فيه جزء من السحر.
دعنا نتحرك للأمام وننشئ الجدول ببساطة من ملف باركيه. 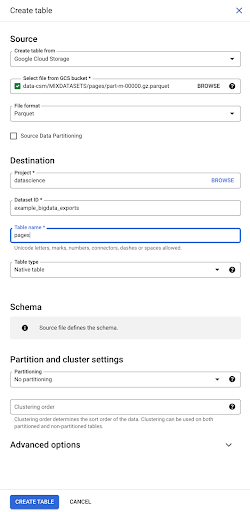
في الشريط الجانبي الأيسر ، يمكننا أن نرى الآن أن الجدول ظهر داخل مجموعة البيانات الخاصة بنا ، وهو بالضبط ما نريده:
لذلك ، لدينا الآن مخطط جدول الصفحات مع جميع الحقول التي تم استنتاجها تلقائيًا من ملف باركيه. لدينا Inrank ، عمق الصفحة ، إذا كانت الصفحة عبارة عن إعادة توجيه وما إلى ذلك: 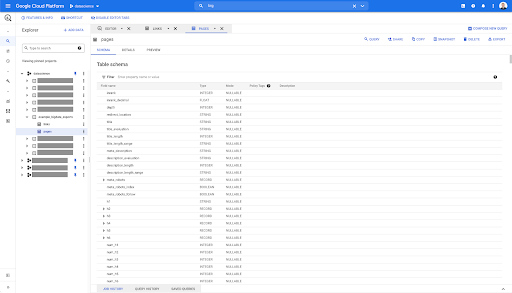
معظم هذه الحقول هي نفس الحقول المتوفرة داخل Data Studio من خلال موصل Oncrawl Data Studio ، وهي نفس الحقول التي تراها في Data Explorer في واجهة Oncrawl. 
ومع ذلك، هناك بعض الاختلافات. عندما نلعب بتصدير البيانات الضخمة الخام ، يكون لديك جميع البيانات الأولية.
- في Data Studio ، تتم إعادة تسمية بعض الحقول وإخفاء بعض الحقول وإضافة بعض الحقول ، مثل الحالة.
- في مستكشف البيانات ، بعض الحقول هي ما نسميه "الحقول الافتراضية" ، مما يعني أنها قد تكون نوعًا من الاختصار إلى حقل أساسي. لن يتم سرد هذه الحقول الافتراضية المتوفرة في Data Explorer في المخطط ، ولكن يمكن إعادة إنشائها بناءً على ما هو متاح في ملف Parquet.
دعنا الآن نغلق هذا الجدول ونفعل ذلك مرة أخرى للروابط.
بالنسبة لجدول الروابط ، يكون المخطط أصغر قليلاً. 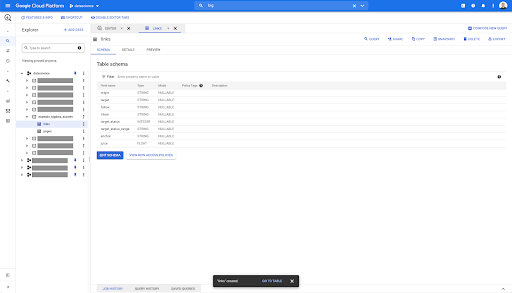
يحتوي فقط على الحقول التالية:
- أصل الرابط ،
- الهدف من الارتباط ،
- خاصية المتابعة ،
- الملكية الداخلية ،
- حالة الهدف ،
- نطاق حالة الهدف ،
- نص الرابط ، و
- العصير أو الأسهم المشتراة عن طريق الرابط.
في أي جدول في BigQuery ، عندما تنقر على علامة تبويب المعاينة ، يكون لديك معاينة للجدول دون الاستعلام عن قاعدة البيانات: 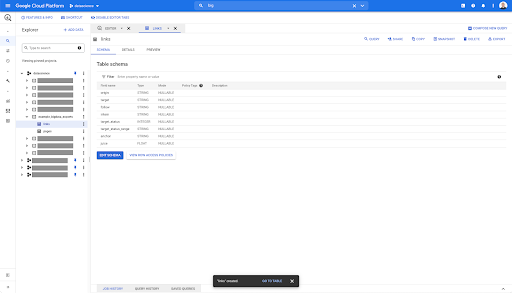
يمنحك هذا عرضًا سريعًا لما هو متاح فيه. في معاينة جدول الروابط أعلاه ، لديك معاينة لكل صف واحد وجميع الأعمدة.
في بعض مجموعات بيانات Oncrawl ، قد ترى بعض الصفوف التي تمتد على عدة صفوف. ليس لدي مثال لك ، ولكن إذا كان هذا هو الحال ، فذلك لأن بعض الحقول تحتوي على قائمة من القيم. على سبيل المثال ، في قائمة عناوين h2 على الصفحة ، سيمتد صف واحد على عدة صفوف في Big Query. سننظر في ذلك لاحقًا إذا رأينا مثالاً.
إنشاء الاستعلام الخاص بك
إذا لم تكن قد أنشأت استعلامًا في BigQuery مطلقًا ، فقد حان الوقت للتلاعب بهذا الأمر للتعرف على كيفية عمله. يستخدم BigQuery SQL للبحث عن البيانات.
كيف تعمل الاستعلامات
كمثال ، دعنا نلقي نظرة على جميع عناوين URL وترتيبها ...
حدد عنوان url ، inrank ...
من مجموعة بيانات الصفحات ...
حدد url ، inrank من `datascience-oncrawl.example_bigdata_exports.pages` ...
حيث رمز حالة الصفحة هو 200…
حدد url ، inrank من `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 ...
واحتفظ بالنتائج العشر الأولى فقط:
حدد url ، inrank من `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 10
عند تشغيل هذا الاستعلام ، سنحصل على أول 10 صفوف من قائمة الصفحات حيث يكون رمز الحالة 200.
يمكن تعديل أي من هذه الخصائص. إذا أريد 1000 صف بدلاً من 10 ، يمكنني تعيين 1000 صف:
حدد url ، inrank من `datascience-oncrawl.example_bigdata_exports.pages` WHERE status_code = 200 LIMIT 1000
إذا أردت الفرز ، يمكنني القيام بذلك باستخدام "ترتيب حسب": سيعطيني هذا كل الصفوف مرتبة بترتيب Inrank تنازليًا.
حدد url ، inrank من `datascience-oncrawl.example_bigdata_exports.links` ORDER BY inrank DESC LIMIT 1000
هذا هو استفساري الأول. يمكنني حفظه إذا أردت ، مما يمنحني القدرة على إعادة استخدام هذا الاستعلام لاحقًا إذا أردت: 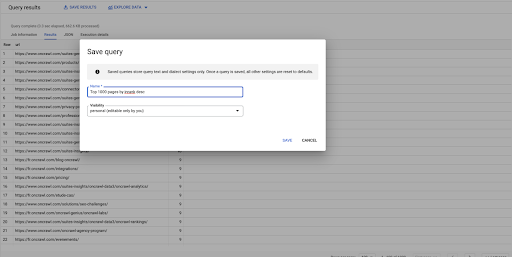
استخدام الاستعلامات للإجابة على أسئلة بسيطة: سرد كافة الروابط الداخلية للصفحات ذات الحالة 301
الآن بعد أن عرفنا كيفية تكوين استعلام ، دعنا نعود إلى مشكلتنا الأصلية.
أردنا الإجابة على أسئلة البيانات ، سواء كانت بسيطة أو معقدة. لنبدأ بسؤال بسيط ، مثل "ما هي جميع الروابط الداخلية التي تشير إلى الصفحات ذات الحالة 301 (تمت إعادة التوجيه) ، وأين يمكنني العثور عليها؟"
إنشاء استعلام جديد
سنبدأ باستكشاف كيفية عمل ذلك.
سأريد أعمدة للعناصر التالية من قاعدة بيانات "الروابط":
- أصل
- استهداف
- رمز الحالة الهدف
حدد الأصل والهدف والحالة_المستهدفة من `datascience-oncrawl.example_bigdata_exports.links`
أريد قصرها على الروابط الداخلية فقط ، لكن دعنا نتخيل أنني لا أتذكر اسم العمود أو القيمة التي تشير إلى ما إذا كان الارتباط داخليًا أم خارجيًا. يمكنني الذهاب إلى المخطط للبحث عنه ، واستخدام المعاينة لعرض القيمة: 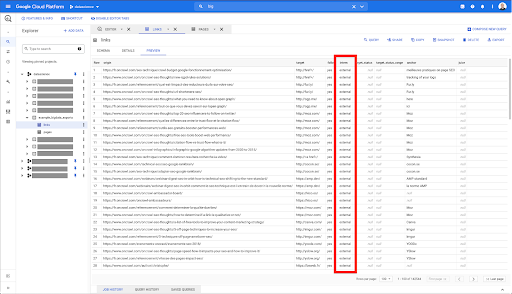
يخبرني هذا أن العمود يسمى "متدرب" ، وأن النطاق المحتمل للقيم هو "خارجي" أو "داخلي".
في طلب البحث الخاص بي ، أريد تحديد "المكان المتدرب داخليًا" ، وقصر النتائج على أول 100 في الوقت الحالي:
حدد الأصل والهدف والهدف_الحالة من `datascience-oncrawl.example_bigdata_exports.links` حيث المتدرب مثل" داخلي "LIMIT 100
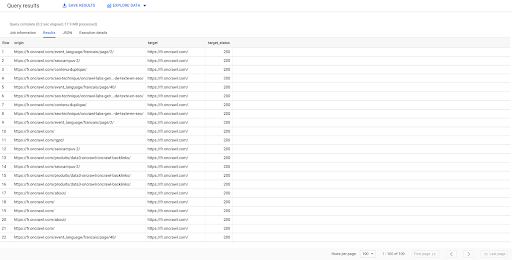
تظهر النتيجة أعلاه قائمة الروابط مع حالة الهدف الخاصة بهم. لدينا روابط داخلية فقط ، ولدينا 100 منها كما هو محدد في الاستعلام.
إذا أردنا الحصول على روابط داخلية فقط لتلك النقطة للصفحات المعاد توجيهها ، فيمكننا القول "حيث المتدرب مثل الحالة الداخلية والحالة المستهدفة تساوي 301":
حدد الأصل والهدف والهدف_الحالة من `datascience-oncrawl.example_bigdata_exports.links` حيث المتدرب مثل" داخلي "AND target_status = 301
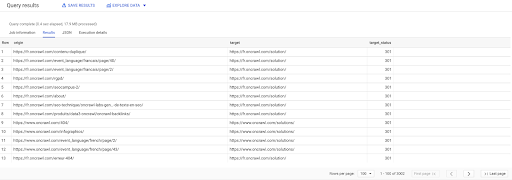
إذا لم نكن نعرف عدد هذه الروابط ، فيمكننا تشغيل هذا الاستعلام الجديد وسنرى أن هناك 3002 رابطًا داخليًا بالحالة المستهدفة 301.
الانضمام إلى الجداول: إيجاد رموز الحالة النهائية للروابط التي تشير إلى الصفحات المعاد توجيهها
على موقع الويب ، غالبًا ما يكون لديك روابط لصفحات تمت إعادة توجيهها. نريد أن نعرف رمز الحالة للصفحة التي تمت إعادة توجيههم إليها (أو عنوان URL الهدف النهائي).
في مجموعة بيانات واحدة ، لديك معلومات عن الروابط: الصفحة الأصلية ، والصفحة الهدف ورمز الحالة الخاص بها (مثل 301) ، ولكن ليس عنوان URL الذي تشير إليه الصفحة المعاد توجيهها. وفي الجانب الآخر ، لديك معلومات حول عمليات إعادة التوجيه وأهدافها النهائية ، ولكن ليس الصفحة الأصلية حيث تم العثور على الرابط المؤدي إليها.
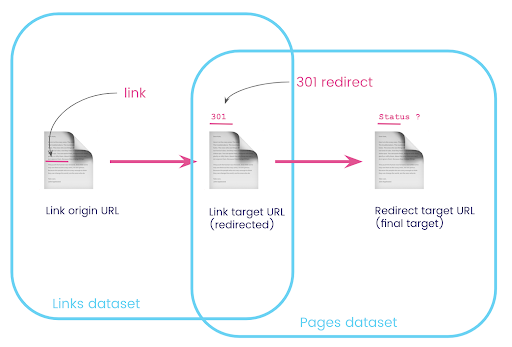
دعنا نقسم هذا:
أولاً ، نريد روابط لعمليات إعادة التوجيه. دعنا نكتب هذا. نحن نريد:
- الأصل.
- الهدف. يجب أن يكون للهدف رمز الحالة 301.
- الهدف النهائي لإعادة التوجيه.
بمعنى آخر ، في مجموعة بيانات الروابط ، نريد:
- أصل الارتباط
- الهدف من الارتباط
في مجموعة بيانات الصفحات ، نريد:
- جميع الأهداف التي تم إعادة توجيهها
- الهدف النهائي لإعادة التوجيه
سيعطينا هذا استعلامًا مثل:
حدد url ، final_redirect_location ، Final_redirect_status من `datascience-oncrawl.example_bigdata_exports.pages` كصفحات حيث status_code = 301 OR status_code = 302
يجب أن يعطيني هذا الجزء الأول من المعادلة.
الآن أحتاج إلى جميع الروابط التي تؤدي إلى الصفحة والتي تمثل نتائج الاستعلام الذي أنشأته للتو ، باستخدام الأسماء المستعارة لمجموعات البيانات الخاصة بي ، والانضمام إليها على عنوان URL الهدف للرابط وعنوان URL للصفحة. يتوافق هذا مع المنطقة المتداخلة لمجموعتي البيانات في الرسم التخطيطي في بداية هذا القسم.
تحديد links.origin ، pages.url ، pages.final_redirect_location، pages.final_redirect_status من صفحات `datascience-oncrawl.example_bigdata_exports.pages` AS انضم روابط `datascience-oncrawl.example_bigdata_exports.links` AS على links.target = pages.url أين pages.status_code = 301 أو pages.status_code = 302 ترتيب حسب الأصل ASC
في نتائج الاستعلام ، يمكنني إعادة تسمية الأعمدة لتوضيح الأمور بشكل أكبر ، ولكن يمكنني بالفعل رؤية أن لدي ارتباطًا من صفحة في العمود الأول ، والذي ينتقل إلى الصفحة في العمود الثاني ، والذي يتم إعادة توجيهه بدوره إلى الصفحة في العمود الثالث. في العمود الرابع ، لدي رمز حالة الهدف النهائي: 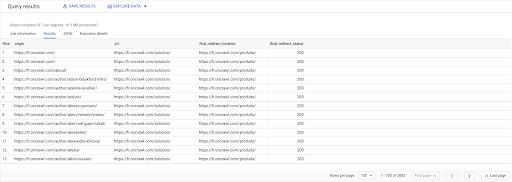
يمكنني الآن تحديد الروابط التي تشير إلى الصفحات المعاد توجيهها والتي لا يتم حلها في 200 صفحة. ربما تكون 404 ، على سبيل المثال ، مما يمنحني قائمة أولويات الروابط لتصحيحها.
رأينا في وقت سابق كيفية حفظ الاستعلام. يمكننا أيضًا حفظ النتائج لما يصل إلى 16000 سطر من النتائج: 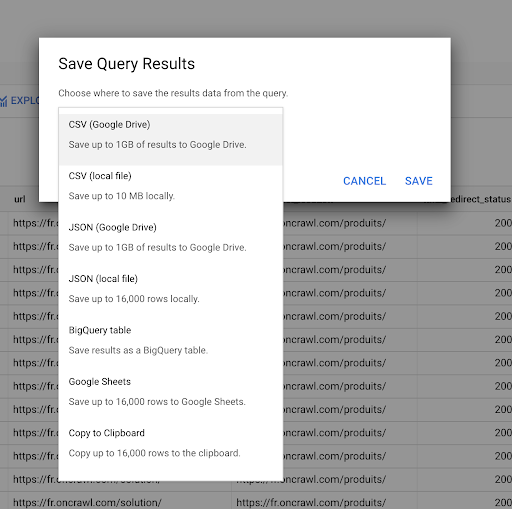
يمكننا بعد ذلك استخدام هذه النتائج بعدة طرق مختلفة. وفيما يلي بعض الأمثلة على ذلك:
- يمكننا حفظ هذا كملف CSV أو JSON محليًا.
- يمكننا حفظه كجدول بيانات Google Sheets ومشاركته مع بقية الفريق.
- يمكننا أيضًا تصديره مباشرةً إلى Data Studio.
البيانات كميزة استراتيجية
مع كل هذه الاحتمالات ، يكون استخدام إجابات أسئلتك المعقدة بشكل استراتيجي أمرًا سهلاً. قد تكون لديك بالفعل خبرة في ربط نتائج BigQuery بـ Data Studio أو أنظمة عرض بيانات أخرى ، أو قد يكون لديك بالفعل عملية تدفع المعلومات إلى فريق هندسي أو حتى في ذكاء الأعمال أو سير عمل تحليل البيانات.
إذا قمت بتضمين الخطوات في هذه المقالة كجزء من عملية ، فتذكر أنه يمكنك أتمتة جميع الخطوات في BigQuery: يمكن أيضًا الوصول إلى جميع الإجراءات التي قمنا بها في هذه المقالة عبر BigQuery API. هذا يعني أنه يمكن تشغيلها برمجيًا كجزء من برنامج نصي أو أداة مخصصة.
مهما كانت خطواتك التالية ، فإن الخطوة الأولى هي الوصول دائمًا إلى بيانات SEO الخام وموقع الويب. نعتقد أن هذا الوصول إلى البيانات هو أحد أهم أجزاء التحليل الفني: مع Oncrawl ، سيكون لديك دائمًا وصول كامل إلى بياناتك الأولية.
يعني الوصول إلى البيانات أيضًا أنه يمكنك تجاوز ما هو ممكن في واجهة Oncrawl ، واستكشاف جميع العلاقات بين بياناتك ، بغض النظر عن مدى تعقيد الأسئلة التي تطرحها.